
設定變數length()函數char_length() replace() 函數max() 函數
1.1、設定變數set @變數名稱=值
set @address='中国-山东省-聊城市-莘县';select @address
1.2 、length()函數char_length()函數區別
select length('a') ,char_length('a') ,length('中') ,char_length('中')
1.3、 replace() 函數和length()函數組合
set @address='中国-山东省-聊城市-莘县';select @address ,replace(@address,'-','') as address_1 ,length(@address) as len_add1 ,length(replace(@address,'-','')) as len_add2 ,length(@address)-length(replace(@address,'-','')) as _count
etl清洗字段時候有明顯分割符的字段如何確定新的資料表增加幾個分割出的字段
計算出com_industry中最多有幾個- 符以便確定增加幾個字段最大值+1 為可以拆分成的字段數此表為3 因此可以拆分出4個產業欄位也就是4個產業等級
select max(length(com_industry)-length(replace(com_industry,'-',''))) as _max_count from etl1_socom_data
1.4、設定變數substring_index()字串截取函數用法
set @address='中国-山东省-聊城市-莘县'; select substring_index(@address,'-',1) as china, substring_index(substring_index(@address,'-',2),'-',-1) as province, substring_index(substring_index(@address,'-',3),'-',-1) as city, substring_index(@address,'-',-1) as district
1.5、條件判斷函數case when
case when then when then else 值end as 字段名
select case when 89>101 then '大于' else '小于' end as betl1_socom_data
首先建表步驟在影片裡
字段索引沒有提索引演算法建議用BTREE演算法增強查詢效率
2.1.kettle檔名:trans_etl1_socom_data
2.2.包含控制項:表輸入>>>表輸出
2.3.資料流方向:s_socom_data>>> ;>etl1_socom_data
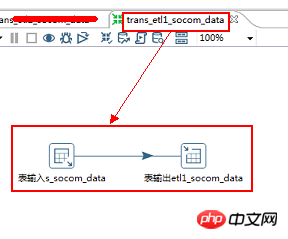
2.4、表格輸入2.4、SQL腳本初步清洗com_district和com_industry欄位
<code class="sql"><span class="hljs-keyword">select a.*,<span class="hljs-keyword">case <span class="hljs-keyword">when com_district <span class="hljs-keyword">like <span class="hljs-string">'%业' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%织' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%育' <span class="hljs-keyword">then <span class="hljs-literal">null <span class="hljs-keyword">else com_district <span class="hljs-keyword">end <span class="hljs-keyword">as com_district1 ,<span class="hljs-keyword">case <span class="hljs-keyword">when com_district <span class="hljs-keyword">like <span class="hljs-string">'%业' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%织' <span class="hljs-keyword">or com_district <span class="hljs-keyword">like <span class="hljs-string">'%育' <span class="hljs-keyword">then <span class="hljs-keyword">concat(com_district,<span class="hljs-string">'-',com_industry) <span class="hljs-keyword">else com_industry <span class="hljs-keyword">end <span class="hljs-keyword">as com_industry_total ,<span class="hljs-keyword">replace(com_addr,<span class="hljs-string">'地 址:',<span class="hljs-string">'') <span class="hljs-keyword">as com_addr1 ,<span class="hljs-keyword">replace(com_phone,<span class="hljs-string">'电 话:',<span class="hljs-string">'') <span class="hljs-keyword">as com_phone1 ,<span class="hljs-keyword">replace(com_fax,<span class="hljs-string">'传 真:',<span class="hljs-string">'') <span class="hljs-keyword">as com_fax1 ,<span class="hljs-keyword">replace(com_mobile,<span class="hljs-string">'手机:',<span class="hljs-string">'') <span class="hljs-keyword">as com_mobile1 ,<span class="hljs-keyword">replace(com_url,<span class="hljs-string">'网址:',<span class="hljs-string">'') <span class="hljs-keyword">as com_url1 ,<span class="hljs-keyword">replace(com_email,<span class="hljs-string">'邮箱:',<span class="hljs-string">'') <span class="hljs-keyword">as com_email1 ,<span class="hljs-keyword">replace(com_contactor,<span class="hljs-string">'联系人:',<span class="hljs-string">'') <span class="hljs-keyword">as com_contactor1 ,<span class="hljs-keyword">replace(com_emploies_nums,<span class="hljs-string">'公司人数:',<span class="hljs-string">'') <span class="hljs-keyword">as com_emploies_nums1 ,<span class="hljs-keyword">replace(com_reg_capital,<span class="hljs-string">'注册资金:万',<span class="hljs-string">'') <span class="hljs-keyword">as com_reg_capital1 ,<span class="hljs-keyword">replace(com_type,<span class="hljs-string">'经济类型:',<span class="hljs-string">'') <span class="hljs-keyword">as com_type1 ,<span class="hljs-keyword">replace(com_product,<span class="hljs-string">'公司产品:',<span class="hljs-string">'') <span class="hljs-keyword">as com_product1 ,<span class="hljs-keyword">replace(com_desc,<span class="hljs-string">'公司简介:',<span class="hljs-string">'') <span class="hljs-keyword">as com_desc1<span class="hljs-keyword">from s_socom_data <span class="hljs-keyword">as a</span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></code><br/><br/><br/>
2.5、表輸出
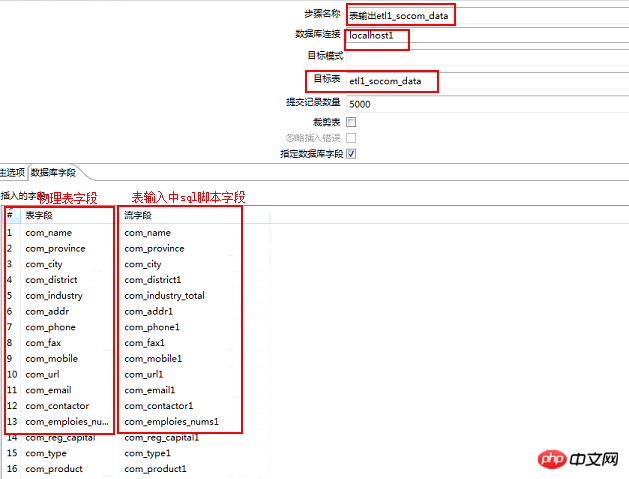
#注意事項:
① 涉及爬蟲增量操作不要勾選裁剪表選項
②資料連接問題選擇表輸出中表所在的資料庫
③字段映射問題確保資料流中的字段和物理表的字段數量一致對應一致
首先建表增加了4個字段演示步驟在影片裡
字段索引沒有提索引演算法建議用BTREE演算法增強查詢效率
主要針對etl1產生的新的com_industry進行字段拆分清洗
3.1.kettle檔名:trans_etl2_socom_data
3.2.包括控制項:表輸入>>>表輸出
3.3.資料流方向:etl1_socom_data>>表輸出
3.3.資料流方向:etl1_socom_data>>表輸出
3.3.資料流方向:etl1_socom_data>>表輸出
3.3.資料流方向:etl1_socom_data>> ;>>etl2_socom_data
注意事項:
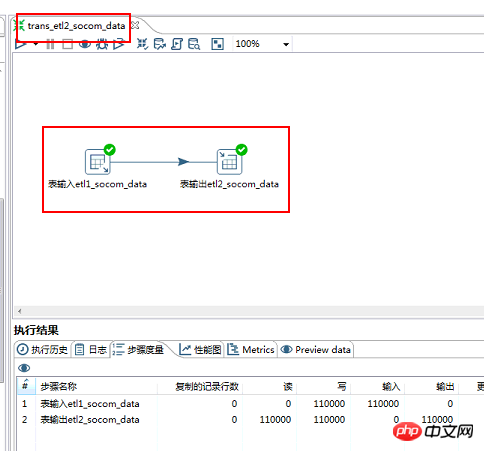 ③字段映射問題確保資料流中的欄位和實體表的欄位數量一致對應一致
③字段映射問題確保資料流中的欄位和實體表的欄位數量一致對應一致kettle轉換2截圖
3.4、SQL腳本對com_industry進行拆分完成所有欄位清洗註冊資金欄位時間關係沒有進行細緻拆解調整程式碼即可select a.*,case #行业为''的值 置为空when length(com_industry)=0 then null #其他的取第一个-分隔符之前else substring_index(com_industry,'-',1) end as com_industry1,case when length(com_industry)-length(replace(com_industry,'-',''))=0 then null #'交通运输、仓储和邮政业-' 这种值 行业2 也置为nullwhen length(com_industry)-length(replace(com_industry,'-',''))=1 and length(substring_index(com_industry,'-',-1))=0 then nullwhen length(com_industry)-length(replace(com_industry,'-',''))=1 then substring_index(com_industry,'-',-1)else substring_index(substring_index(com_industry,'-',2),'-',-1)end as com_industry2,case when length(com_industry)-length(replace(com_industry,'-',''))<=1 then nullwhen length(com_industry)-length(replace(com_industry,'-',''))=2 then substring_index(com_industry,'-',-1)else substring_index(substring_index(com_industry,'-',3),'-',-1)end as com_industry3,case when length(com_industry)-length(replace(com_industry,'-',''))<=2 then nullelse substring_index(com_industry,'-',-1)end as com_industry4from etl1_socom_data as a
註:SQL腳本中沒有經過聚合過濾3個表格資料量應相等
4.2.1、sql查詢下面表我是在同一資料庫中如果不在同一資料庫from 後面應加上表格所在的資料庫名稱
不建議資料量大的時候使用select count(1) from s_socom_dataunion all select count(1) from etl1_socom_dataunion all select count(1) from etl2_socom_data
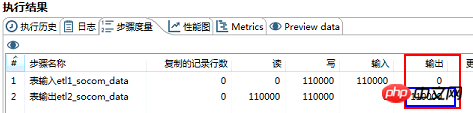 4.2.2 根據kettle轉換執行完畢以後表輸出總量比較
4.2.2 根據kettle轉換執行完畢以後表輸出總量比較
4.3查看etl清洗品質
確保前兩個步驟已經無誤,資料處理負責的etl清洗工作自查開始針對資料來源清洗的字段寫腳本檢查socom網站主要是對地區和行業進行了清洗對其他字段做了替換多餘欄位處理,因此採取腳本檢查,
找到page_url和網站資料進行核查where裡面這樣寫便於查看某個欄位的清洗情況select * from etl2_socom_data where com_district is null and length(com_industry)-length(replace(com_industry,'-',''))=3
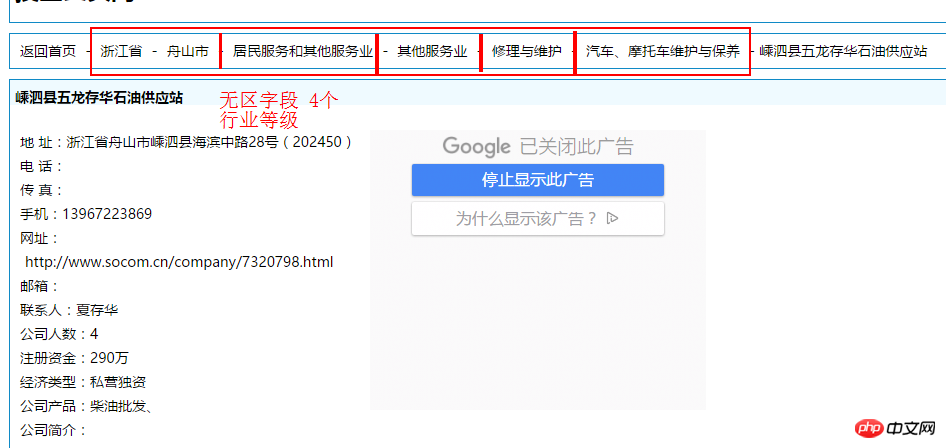 此頁面數據和etl2_socom_data表最終清洗資料比較
此頁面數據和etl2_socom_data表最終清洗資料比較
etl2_socom_data表資料
清洗工作完成。
以上是Python爬蟲資料該怎麼處理?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















