

python學習之抓取部落格園新聞

前言
说到python,对它有点耳闻的人,第一反应可能都是爬虫~
这两天看了点python的皮毛知识,忍不住想写一个简单的爬虫练练手,JUST DO IT
准备工作
要制作数据抓取的爬虫,对请求的源页面结构需要有特定分析,只有分析正确了,才能更好更快的爬到我们想要的内容。
浏览器访问570973/,右键“查看源代码”,初步只想取一些简单的数据(文章标题、作者、发布时间等),在HTML源码中找到相关数据的部分:
1)标题(url):
2)作者:
投遞人 itwriter
# 3)發佈時間:發佈於 2017-06-06 14:53# #4)目前新聞ID :

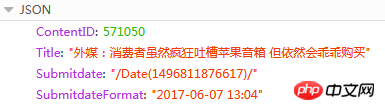
#當然了,要想“順藤摸瓜”,“上一篇”和“下一篇”鏈接的結構非常重要;但發現一個問題,頁面中的這兩個標籤,它的鏈接和文本內容,是透過js渲染的,這可如何是好?嘗試尋找資料(python執行js之類的),可對於python菜鳥來說,可能有點超前了,打算另找方案。
雖然這兩個連結是透過js渲染的,但是理論上,js之所以能渲染該內容,應該也是透過發起請求,得到回應後執行的渲染吧;那麼是否可以透過監視網頁加載過程看看有什麼有用資訊?在此要為chrome/firefox這些瀏覽器點個讚了,開發者工具/網絡,可以清清楚楚的看到所有資源的請求和響應情況。 它們的請求地址分別為:
1)上一篇新聞ID: 2)下一篇新聞ID:
回應的內容為JSON
此處ContentID就是我們需要的,可以根據這個值,知道當前新聞的上一篇或下一篇新聞URL,因為新聞發佈的頁面地址是有固定格式的:
#/ (紅色內容就是可替換的ID)
工具
1)python 3.6(安裝的時候同時安裝pip,並且加入環境變數)
2)PyCharm 2017.1.3## 3)第三方python函式庫(安裝:cmd -> pip install name)
b)requests : 基於urllib,採用Apache2 Licensed 開源協定的HTTP 庫。它比urllib 更方便,可以節省我們大量的工作
#! python3
# coding = utf-8
# get_cnblogs_news.py
# 根据博客园内的任意一篇新闻,获取所有新闻(标题、发布时间、发布人)
#
# 这是标题格式 :<div id="news_title"><a href="//news.cnblogs.com/n/570973/">SpaceX重复使用的“龙”飞船成功与国际空间站对接</a></div>
# 这是发布人格式 :<span class="news_poster">投递人 <a href="//home.cnblogs.com/u/34358/">itwriter</a></span>
# 这是发布时间格式 :<span class="time">发布于 2017-06-06 14:53</span>
# 当前新闻ID :<input type="hidden" value="570981" id="lbContentID">
# html中获取不到上一篇和下一篇的直接链接,因为它是使用ajax请求后期渲染的
# 需要另外请求地址,获取结果,JSON
# 上一篇
# 下一篇
# 响应内容
# ContentID : 570971
# Title : "Mac支持外部GPU VR开发套件售599美元"
# Submitdate : "/Date(1425445514)"
# SubmitdateFormat : "2017-06-06 14:47"
import sys, pyperclip
import requests, bs4
import json
# 解析并打印(标题、作者、发布时间、当前ID)
# soup : 响应的HTML内容经过bs4转化的对象
def get_info(soup):
dict_info = {'curr_id': '', 'author': '', 'time': '', 'title': '', 'url': ''}
titles = soup.select('div#news_title > a')
if len(titles) > 0:
dict_info['title'] = titles[0].getText()
dict_info['url'] = titles[0].get('href')
authors = soup.select('span.news_poster > a')
if len(authors) > 0:
dict_info['author'] = authors[0].getText()
times = soup.select('span.time')
if len(times) > 0:
dict_info['time'] = times[0].getText()
content_ids = soup.select('input#lbContentID')
if len(content_ids) > 0:
dict_info['curr_id'] = content_ids[0].get('value')
# 写文件
with open('D:/cnblognews.csv', 'a') as f:
text = '%s,%s,%s,%s\n' % (dict_info['curr_id'], (dict_info['author'] + dict_info['time']), dict_info['url'], dict_info['title'])
print(text)
f.write(text)
return dict_info['curr_id']
# 获取前一篇文章信息
# curr_id : 新闻ID
# loop_count : 向上多少条,如果为0,则无限向上,直至结束
def get_prev_info(curr_id, loop_count = 0):
private_loop_count = 0
try:
while loop_count == 0 or private_loop_count < loop_count:
res_prev = requests.get('https://news.cnblogs.com/NewsAjax/GetPreNewsById?contentId=' + curr_id)
res_prev.raise_for_status()
res_prev_dict = json.loads(res_prev.text)
prev_id = res_prev_dict['ContentID']
res_prev = requests.get('https://news.cnblogs.com/n/%s/' % prev_id)
res_prev.raise_for_status()
soup_prev = bs4.BeautifulSoup(res_prev.text, 'html.parser')
curr_id = get_info(soup_prev)
private_loop_count += 1
except:
pass
# 获取下一篇文章信息
# curr_id : 新闻ID
# loop_count : 向下多少条,如果为0,则无限向下,直至结束
def get_next_info(curr_id, loop_count = 0):
private_loop_count = 0
try:
while loop_count == 0 or private_loop_count < loop_count:
res_next = requests.get('https://news.cnblogs.com/NewsAjax/GetNextNewsById?contentId=' + curr_id)
res_next.raise_for_status()
res_next_dict = json.loads(res_next.text)
next_id = res_next_dict['ContentID']
res_next = requests.get('https://news.cnblogs.com/n/%s/' % next_id)
res_next.raise_for_status()
soup_next = bs4.BeautifulSoup(res_next.text, 'html.parser')
curr_id = get_info(soup_next)
private_loop_count += 1
except:
pass
# 参数从优先从命令行获取,如果无,则从剪切板获取
# url是博客园新闻版块下,任何一篇新闻
if len(sys.argv) > 1:
url = sys.argv[1]
else:
url = pyperclip.paste()
# 没有获取到有地址,则抛出异常
if not url:
raise ValueError
# 开始从源地址中获取新闻内容
res = requests.get(url)
res.raise_for_status()
if not res.text:
raise ValueError
#解析Html
soup = bs4.BeautifulSoup(res.text, 'html.parser')
curr_id = get_info(soup)
print('backward...')
get_prev_info(curr_id)
print('forward...')
get_next_info(curr_id)
print('done')
運行
將以上原始碼儲存至D:/get_cnblogs_news.py ,windows平台下開啟命令列工具cmd:
輸入指令:py.exe D:/get_cnblogs_news.py 回車
解析:py.exe就不用解釋了,第二個參數為python腳本檔案,第三個參數為需要爬的來源頁面(程式碼裡有另一個考慮,如果你將這個url拷貝在系統剪貼簿的時候,可以直接運行:py.exe D:/get_cnblogs_news.py
# 命令列輸出介面(print)
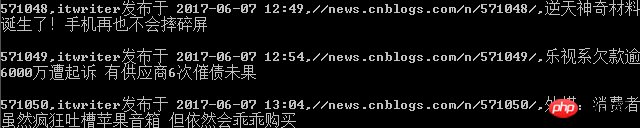
# 儲存到csv檔案的內容

#
#o
#o
####################### ####推薦菜鳥python學習書箱或資料:############ 1)廖雪峰的Python教程,很基礎易懂:############ 2 )Python程式設計快速上手 讓繁瑣工作自動化.pdf############ #########文章僅是給自己學習python的日記,如有誤導請批評指正(不喜勿噴),如對您有幫助,榮幸之至。 ###### ###### #####
以上是python學習之抓取部落格園新聞的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
