

ext檔案系統機制
本文目錄:
#4.1 檔案系統的組成部分
4.2 檔案系統的完整架構
4.3 Data Block
4.4 inode基礎知識
#4.5 inode深入
#4.6 單一檔案系統中檔案操作的原理
4.7 多重檔案系統關聯
4.8 ext3檔案系統的日誌功能
另外,每個檔案都有屬性(如權限、大小、時間戳記等),這些屬性類別的元資料儲存在哪裡呢?難道也和文件的資料部分儲存在區塊中嗎?如果一個檔案佔用多個block那是不是每個屬於該檔案的block都要儲存一份文件元資料?但是如果不在每個block中儲存元資料檔案系統又怎麼知道某一個block是不是屬於該檔案呢?但是顯然,每個資料block中都儲存一份元資料太浪費空間。
檔案系統設計者當然知道這樣的儲存方式很不理想,所以需要優化儲存方式。如何優化?對於這種類似的問題的解決方法是使用索引,透過掃描索引找到對應的數據,而且索引可以儲存部分數據。
在檔案系統上索引技術具體化為索引節點(index node),在索引節點上儲存的部分資料即為檔案的屬性元資料及其他少量資訊。一般來說索引所佔用的空間相比其索引的檔案資料而言所佔用的空間就小得多,掃描它比掃描整個資料快得多,否則索引就沒有存在的意義。這樣一來就解決了前面所有的問題。
在檔案系統上的術語中,索引節點稱為inode。在inode中儲存了inode號、檔案類型、權限、檔案擁有者、大小、時間戳等元資料訊息,最重要的是還儲存了指向屬於該檔案block的指針,這樣讀取inode就可以找到屬於該文件的block,進而讀取這些block並獲得該檔案的資料。由於後面還會介紹一種指針,為了方便稱呼和區分,暫且將這個inode記錄中指向文件data block的指針稱之為block指針,。
一般inode大小為128位元組或256字節,相較於那些MB或GB計算的檔案資料而言小得多的多,但也要知道可能一個檔案大小小於inode大小,例如只佔用1個位元組的檔案。
4.1.3 bmap出現
在儲存資料到硬碟時,檔案系統需要知道哪些區塊是空閒的,哪些區塊是已經佔用了的。最笨的方法當然是從前向後掃描,遇到空閒區塊就儲存一部分,繼續掃描直到儲存完所有資料。
優化的方法當然也可以考慮使用索引,但是僅僅1G的檔案系統就有1KB的block共1024*1024=1048576個,這僅僅只是1G,如果是100G、500G甚至更大呢,僅使用索引索引的數量和空間佔用也將極大,這時就出現更高一級的最佳化方法:使用區塊位圖(bitmap簡稱bmap)。
點陣圖只使用0和1標識對應block是空閒還是被佔用,0和1在位圖中的位置和block的位置一一對應,第一位標識第一個區塊,第二個位元標識第二個區塊,依序下去直到標記完所有的block。
考慮下為什麼區塊位圖更優化。在點陣圖中1個位元組8個位,可以標識8個block。對於一個block大小為1KB、容量為1G的檔案系統而言,block數量有1024*1024個,所以在位圖中使用1024*1024個位元共1024*1024/8=131072位元組=128K,即1G的檔案只需要128個block做點陣圖就能完成一一對應。透過掃描這100多個block就能知道哪些block是空閒的,速度提高了非常多。
但要注意,bmap的最佳化針對的是寫入最佳化,因為只有寫入才需要找到空閒block並指派空閒block。對於讀取而言,只要透過inode找到了block的位置,cpu就能迅速計算出block在實體磁碟上的位址,cpu的運算速度是極快的,計算block位址的時間幾乎可以忽略,那麼讀取速度基本認為是受硬碟本身效能的影響而與檔案系統無關了。
雖然bmap已經極大的優化了掃描,但是仍有其瓶頸:如果檔案系統是100G呢? 100G的檔案系統要使用128*100=12800個1KB大小的block,這就佔用了12.5M的空間了。試想完全掃描12800個很可能不連續的block這也是需要佔用一些時間的,雖然快但是扛不住每次存儲文件都要掃描帶來的巨大開銷。
所以需要再優化,如何優化?簡而言之就是將檔案系統劃分開形成塊組,至於塊組的介紹放在後文。
4.1.4 inode表的出現
回顧下inode相關資訊:inode儲存了inode號、檔案屬性元資料、指向檔案所佔用的block的指標;每一個inode佔用128字節或256位元組。
現在又出現問題了,一個檔案系統中可以說有無數多個文件,每個檔案都對應一個inode,難道每一個僅128位元組的inode都要單獨佔用一個block進行儲存嗎?這太浪費空間了。
所以更優的方法是將多個inode合併儲存在block中,對於128位元組的inode,一個block儲存8個inode,對於256位元組的inode,一個block儲存4個inode。這就使得每個儲存inode的區塊都不浪費。
在ext檔案系統上,將這些物理上儲存inode的block組合起來,在邏輯上形成一張inode表(inode table)來記錄所有的inode。
舉個例子,每個家庭都要向派出所登記戶口信息,透過戶口本可以知道家庭住址,而每個鎮或街道的派出所將本鎮或本街道的所有戶口整合在一起,要找某一戶地址時,在派出所就能快速查找到。 inode table就是這裡的派出所。它的內容如下圖所示。
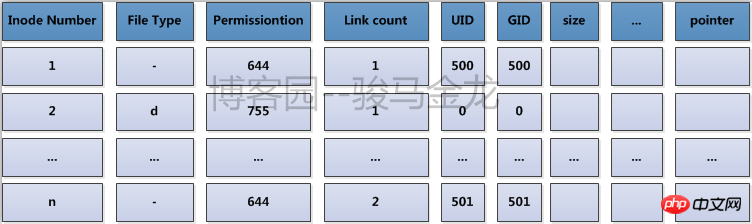
實際上,在檔案系統建立完成後所有的inode號都已經分配好並記錄到inode table中了,只不過被使用的inode號所在的行還有檔案屬性的元資料資訊和block位置訊息,而未被使用的inode號只有一個inode號而已而沒有其他資訊而已。
再細細一思考,就能發現一個大的檔案系統仍將佔用大量的區塊來儲存inode,想要找到其中的一個inode記錄也需要不小的開銷,儘管它們已經形成了一張邏輯上的表,但扛不住表太大記錄太多。那麼如何快速找到inode,這同樣是需要優化的,優化的方法是將檔案系統的block進行分組劃分,每個群組中都存有本組inode table範圍、bmap等。
4.1.5 imap的出現
前面說bmap是區塊位圖,用來識別檔案系統中哪些block是空閒哪些block是佔用的。
對於inode也是一樣,在儲存檔案(Linux中一切皆檔案)時需要為其指派一個inode號碼。但是在格式化建立檔案系統後所有的inode號碼都是事先設定好存放在inode table中的,因此產生了問題:要為檔案指派哪一個inode號碼呢?又如何知道某一個inode號是否已經被分配了呢?
既然是"是否被佔用"的問題,使用點陣圖是最佳方案,像bmap記錄block的佔用情況一樣。標識inode號是否被指派的位圖稱為inodemap簡稱為imap。這時要為一個檔案指派inode號只需掃描imap即可知道哪一個inode號是空閒的。
imap存在著和bmap和inode table一樣需要解決的問題:如果檔案系統比較大,imap本身就會很大,每次儲存檔案都要掃描,回導致效率不夠高。同樣,優化的方式是將檔案系統佔用的block劃分成區塊組,每個區塊組都有自己的imap範圍。
4.1.6 區塊群組的出現
前面一直提到的最佳化方法是將檔案系統佔用的block分割成區塊群組(block group),解決bmap、inode table和imap太大的問題。
在物理層面上的劃分是將磁碟按柱面劃分為多個分區,即多個檔案系統;在邏輯層面上的劃分是將檔案系統劃分成區塊組。每個檔案系統包含多個區塊組,每個區塊組包含多個元資料區和資料區:元資料區就是儲存bmap、inode table、imap等的資料;資料區就是儲存檔案資料的區域。注意塊組是邏輯層面的概念,所以並不會真的在磁碟上按柱、按扇區、按磁軌等概念劃分。
4.1.7 區塊群組的分割
區塊群組在檔案系統建立完成後就已經分割完成了,也就是說元資料區bmap、inode table和imap等資訊佔用的block而資料區佔用的block都已經劃分好了。那麼檔案系統如何知道一個區塊組元資料區包含多少個block,而資料區又包含多少block呢?
它只要決定一個資料-每個block的大小,再根據bmap至多只能佔用一個完整的block的標準就能計算出區塊組如何分割。如果檔案系統非常小,所有的bmap總共不能佔用完一個block,那麼也只能空閒bmap的block了。
每個block的大小在建立檔案系統時可以人為指定,不指定也有預設值。
假如現在block的大小是1KB,一個bmap完整佔用一個block能標識1024*8= 8192個block(當然這8192個block是資料區和元資料區共8192個,因為元資料區分配的block也需要透過bmap來識別)。每個block是1K,每個區塊組是8192K即8M,建立1G的檔案系統需要分割1024/8=128個區塊組,如果是1.1G的檔案系統呢? 128+12.8=128+13=141個塊組。
每個群組的block數量是分割好了,但是每組設定多少個inode號碼呢? inode table佔用多少block呢?這需要由系統決定了,因為描述"每多少個資料區的block就為其分配一個inode號"的指標預設是我們不知道的,當然創建文件系統時也可以人為指定這個指標或者百分比例。見後文"inode深入"。
使用dumpe2fs可以將ext類別的檔案系統資訊全部顯示出來,當然bmap是每個區塊組固定一個block的不用顯示,imap比bmap更小所以也只佔用1個block不用顯示。
下圖是一個檔案系統的部分訊息,在這些資訊的後面還有每個區塊組的資訊。
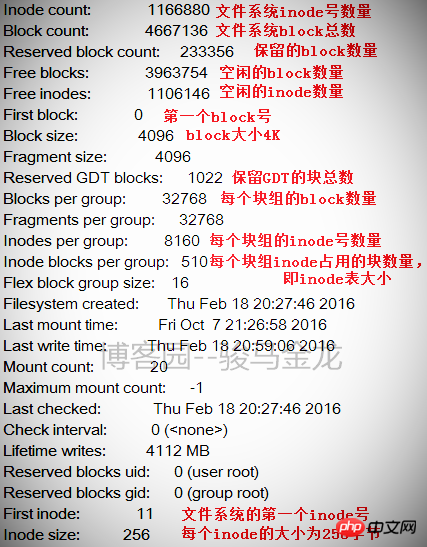
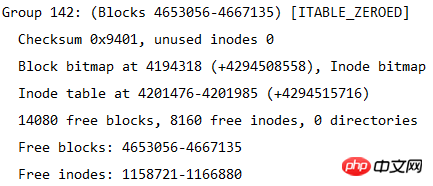
從這張表中能計算出檔案系統的大小,該檔案系統共4667136個blocks,每個block大小為4K,所以檔案系統大小為4667136*4/ 1024/1024=17.8GB。
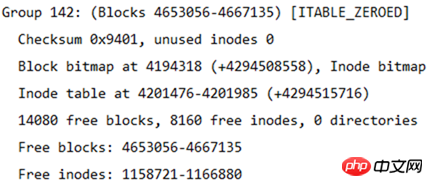
也能計算出分了多少個區塊組,因為每個區塊組的block數量為32768,所以區塊組的數量為4667136/32768=142.4即143個區塊組。由於區塊組從0開始編號,所以最後一個區塊組編號為Group 142。如下圖所示是最後一個區塊組的資訊。
4.2 檔案系統的完整結構
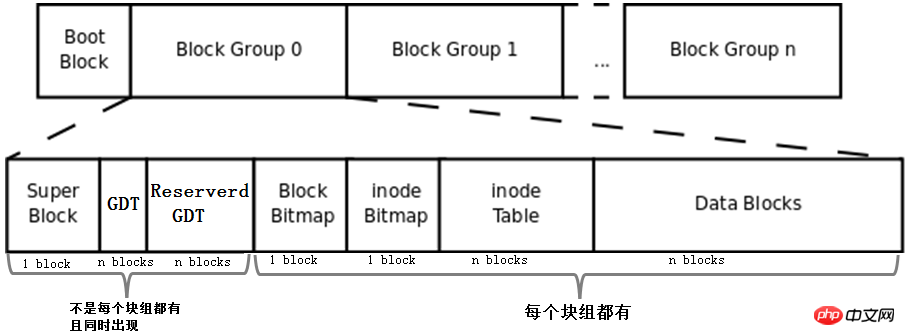
將上文描述的bmap、inode table、imap、資料區的blocks和區塊組的概念組合起來就形成了一個檔案系統,當然這還不是完整的檔案系統。完整的檔案系統如下圖。
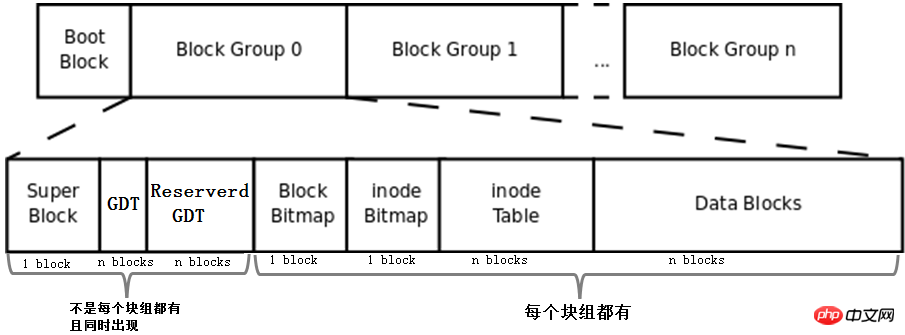
首先,該圖中多了Boot Block、Super Block、GDT、Reserver GDT這幾個概念。下面會分別介紹它們。
然後,圖中指明了區塊組中每個部分佔用的block數量,除了superblock、bmap、imap能確定佔用1個block,其他的部分都無法確定佔用幾個block。
最後,圖中指明了Superblock、GDT和Reserved GDT是同時出現且不一定存在於每一個區塊組中的,也指明了bmap、imap、inode table和data blocks是每個區塊組都有的。
4.2.1 引導區塊
即上圖中的Boot Block部分,也稱為boot sector。它位於分區上的第一個區塊,佔用1024字節,並非所有分區都有這個boot sector。裡面存放的也是boot loader,這段boot loader成為VBR,這裡的Boot loader和mbr上的boot loader是存在交錯關係的。開機啟動的時候,先載入mbr中的bootloader,然後定位到作業系統所在分割區的boot serctor上載入此處的boot loader。如果是多系統,載入mbr中的bootloader後會列出作業系統選單,選單上的各作業系統指向它們所在分割的boot sector上。它們之間的關係如下圖所示。
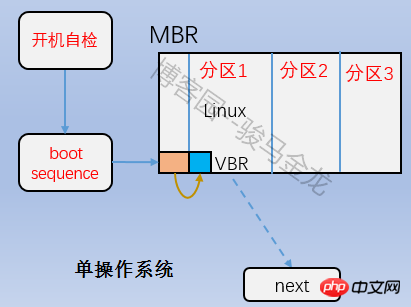
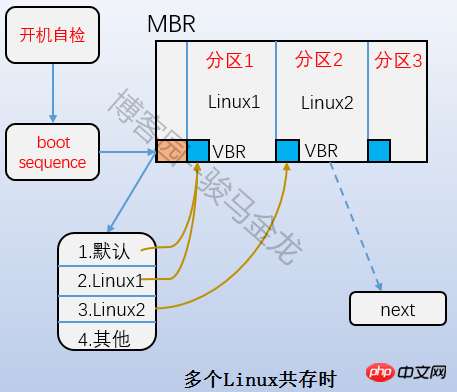
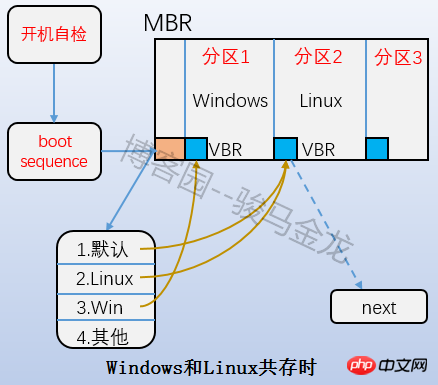
4.2.2 超級區塊(superblock)
既然一個檔案系統會分成多個區塊組,那麼檔案系統怎麼知道分了多少個塊組呢?每個區塊組又有多少block多少inode號等等資訊呢?還有,檔案系統本身的屬性資訊如各種時間戳記、block總數量和空閒數量、inode總數和空閒數量、當前檔案系統是否正常、何時需要自檢等等,它們又儲存在哪裡呢?
毫無疑問,這些資訊必須要儲存在block。儲存這些資訊佔用1024KB,所以也要一個block,這個block稱為超級區塊(superblock),它的block號可能為0也可能為1。 如果block大小為1024K,則引導區塊正好佔用一個block,這個block號為0,所以superblock的號為1;如果block大小大於1024K,則引導區塊和超級區塊同置在一個block中,這個block號為0。總之superblock的起止位置是第二個1024(1024-2047)位元組。
使用df指令讀取的就是每個檔案系統的superblock,所以它的統計速度非常快。相反,用du指令查看一個較大目錄的已使用空間就非常慢,因為不可避免地要遍歷整個目錄的所有檔案。
[root@xuexi ~]# df -hT Filesystem Type Size Used Avail Use% Mounted on/dev/sda3 ext4 18G 1.7G 15G 11% /tmpfs tmpfs 491M 0 491M 0% /dev/shm/dev/sda1 ext4 190M 32M 149M 18% /boot
superblock對於檔案系統而言是至關重要的,超級區塊遺失或損壞必將導致檔案系統的損壞。所以舊式的檔案系統將超級區塊備份到每一個區塊組中,但這又有空間浪費,所以ext2檔案系統只在區塊組0、1和3、5、7冪次方的區塊組中保存超級區塊的訊息,如Group9、Group25等。儘管保存了這麼多的superblock,但檔案系統只使用第一個區塊組即Group0中超級區塊資訊來取得檔案系統屬性,只有當Group0上的superblock損壞或遺失才會找下一個備份超級區塊複製到Group0中來恢復檔案系統。
下圖是一個ext4檔案系統的superblock的訊息,ext家族的檔案系統都能使用dumpe2fs -h取得。

4.2.3 區塊組描述符表(GDT)
既然檔案系統分割了區塊組,那麼每個區塊組的資訊和屬性元資料又保存在哪裡呢?
ext檔案系統每個區塊組資訊使用32位元組描述,這32個位元組稱為區塊組描述符,所有區塊組的區塊組描述符組成區塊組描述符表GDT(group descriptor table)。
雖然每個塊組都需要塊組描述符來記錄塊組的資訊和屬性元數據,但是不是每個塊組中都存放了塊組描述符。 ext檔案系統的儲存方式是:將它們組成一個GDT,並將該GDT存放於某些區塊組中,存放GDT的區塊組和存放superblock和備份superblock的區塊相同,也就是說它們是同時出現在某一個塊組中的。
假如block大小為4KB的檔案系統劃分了143個區塊組,每個區塊組描述符32字節,那麼GDT就需要143*32=4576位元組即兩個block來存放。這兩個GDT block中記錄了所有塊組的塊組信息,且存放GDT的塊組中的GDT都是完全相同的。
下圖是一個區塊組描述符的資訊(透過dumpe2fs取得)。
4.2.4 保留GDT(Reserved GDT)
保留GDT用於以後擴容檔案系統使用,防止擴容後區塊組太多,使得區塊群組描述符超出目前儲存GDT的blocks。保留GDT和GDT總是同時出現,當然也就和superblock同時出現了。
例如前面143個區塊組使用了2個block來存放GDT,但是此時第二個block還空餘很多空間,當擴容到一定程度時2個block已經無法再記錄區塊組描述符了,這時就需要分配一個或多個Reserverd GDT的block來存放超出的區塊組描述符。
由於新增加了GDT block,所以應該讓每一個保存GDT的區塊組都同時增加這一個GDT block,所以將保留GDT和GDT存放在同一個區塊組中可以直接將保留GDT變換為GDT而無需使用低效率的複製手段備份到每個存放GDT的區塊組。
同理,新增加了GDT需要修改每個區塊組中superblock中的檔案系統屬性,所以將superblock和Reserverd GDT/GDT放在一起又能提升效率。
4.3 Data Block
#如上圖,除了Data Blocks其他的部分都解釋過了。 data block是直接儲存資料的block,但事實上並非如此簡單。
資料所佔用的block由檔案對應inode記錄中的block指標找到,不同的檔案類型,資料block中儲存的內容是不一樣的。以下是Linux中不同類型檔案的儲存方式。
對於常規文件,文件的資料正常儲存在資料區塊中。
對於目錄,該目錄下的所有檔案和一級子目錄的目錄名稱儲存在資料區塊中。
檔案名稱不是儲存在其自身的inode中,而是儲存在其所在目錄的data block中。
對於符號鏈接,如果目標路徑名較短則直接保存在inode中以便更快地查找,如果目標路徑名較長則分配一個資料塊來保存。
裝置檔案、FIFO和socket等特殊檔案沒有資料區塊,裝置檔案的主裝置號碼和次裝置號碼保存在inode。
常規檔案的儲存就不解釋了,以下分別解釋特殊檔案的儲存方式。
4.3.1 目錄文件的data block
對於目錄文件,其inode記錄中儲存的是目錄的inode號、目錄的屬性元資料和目錄文件的block指針,這裡面沒有儲存目錄自身檔案名稱的資訊。
而其data block的儲存方式則如下圖所示。
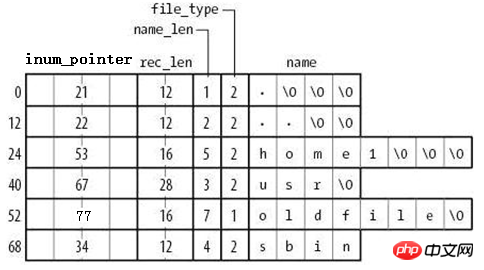
由图可知,在目录文件的数据块中存储了其下的文件名、目录名、目录本身的相对名称"."和上级目录的相对名称"..",还存储了指向inode table中这些文件名对应的inode号的指针(并非直接存储inode号码)、目录项长度rec_len、文件名长度name_len和文件类型file_type。注意到除了文件本身的inode记录了文件类型,其所在的目录的数据块也记录了文件类型。由于rec_len只能是4的倍数,所以需要使用"\0"来填充name_len不够凑满4倍数的部分。至于rec_len具体是什么,只需知道它是一种偏移即可。
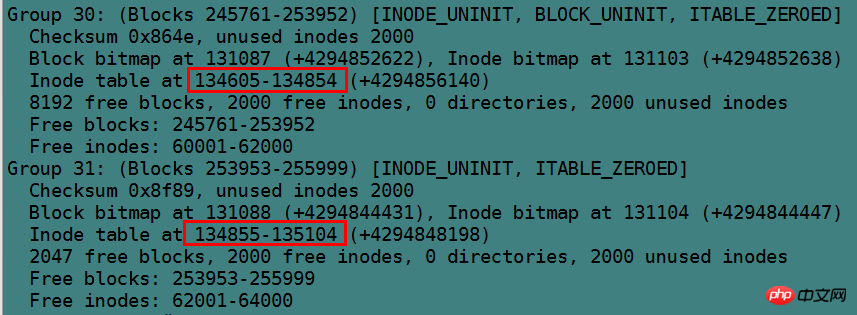
目录的data block中并没有直接存储目录中文件的inode号,它存储的是指向inode table中对应文件inode号的指针,暂且称之为inode指针(至此,已经知道了两种指针:一种是inode table中每个inode记录指向其对应data block的block指针,一个此处的inode指针)。一个很有说服力的例子,在目录只有读而没有执行权限的时候,使用"ls -l"是无法获取到其内文件inode号的,这就表明没有直接存储inode号。实际上,因为在创建文件系统的时候,inode号就已经全部划分好并在每个块组的inode table中存放好,inode table在块组中是有具体位置的,如果使用dumpe2fs查看文件系统,会发现每个块组的inode table占用的block数量是完全相同的,如下图是某分区上其中两个块组的信息,它们都占用249个block。
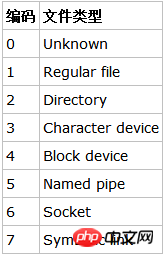
除了inode指针,目录的data block中还使用数字格式记录了文件类型,数字格式和文件类型的对应关系如下图。
注意到目录的data block中前两行存储的是目录本身的相对名称"."和上级目录的相对名称"..",它们实际上是目录本身的硬链接和上级目录的硬链接。硬链接的本质后面说明。
由此也就容易理解目录权限的特殊之处了。目录文件的读权限(r)和写权限(w),都是针对目录文件的数据块本身。由于目录文件内只有文件名、文件类型和inode指针,所以如果只有读权限,只能获取文件名和文件类型信息,无法获取其他信息,尽管目录的data block中也记录着文件的inode指针,但定位指针是需要x权限的,因为其它信息都储存在文件自身对应的inode中,而要读取文件inode信息需要有目录文件的执行权限通过inode指针定位到文件对应的inode记录上。以下是没有目录x权限时的查询状态,可以看到除了文件名和文件类型,其余的全是"?"。
[lisi4@xuexi tmp]$ ll -i d ls: cannot access d/hehe: Permission denied ls: cannot access d/haha: Permission denied total 0? d????????? ? ? ? ? ? haha? -????????? ? ? ? ? ? hehe
注意,xfs文件系统和ext文件系统不一样,它连文件类型都无法获取。
4.3.2 符号链接存储方式
符号链接即为软链接,类似于Windows操作系统中的快捷方式,它的作用是指向原文件或目录。
软链接之所以也被称为特殊文件的原因是:它一般情况下不占用data block,仅仅通过它对应的inode记录就能将其信息描述完成;符号链接的大小是其指向目标路径占用的字符个数,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",则其文件大小为11字节;只有当符号链接指向的目标的路径名较长(60个字节)时文件系统才会划分一个data block给它;它的权限如何也不重要,因它只是一个指向原文件的"工具",最终决定是否能读写执行的权限由原文件决定,所以很可能ls -l查看到的符号链接权限为777。
注意,软链接的block指针存储的是目标文件名。也就是说,链接文件的一切都依赖于其目标文件名。这就解释了为什么/mnt的软链接/tmp/mnt在/mnt挂载文件系统后,通过软链接就能进入/mnt所挂载的文件系统。究其原因,还是因为其目标文件名"/mnt"并没有改变。
例如以下筛选出了/etc/下的符号链接,注意观察它们的权限和它们占用的空间大小。
[root@xuexi ~]# ll /etc/ | grep '^l'lrwxrwxrwx. 1 root root 56 Feb 18 2016 favicon.png -> /usr/share/icons/hicolor/16x16/apps/system-logo-icon.png lrwxrwxrwx. 1 root root 22 Feb 18 2016 grub.conf -> ../boot/grub/grub.conf lrwxrwxrwx. 1 root root 11 Feb 18 2016 init.d -> rc.d/init.d lrwxrwxrwx. 1 root root 7 Feb 18 2016 rc -> rc.d/rc lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc0.d -> rc.d/rc0.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc1.d -> rc.d/rc1.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc2.d -> rc.d/rc2.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc3.d -> rc.d/rc3.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc4.d -> rc.d/rc4.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc5.d -> rc.d/rc5.d lrwxrwxrwx. 1 root root 10 Feb 18 2016 rc6.d -> rc.d/rc6.d lrwxrwxrwx. 1 root root 13 Feb 18 2016 rc.local -> rc.d/rc.local lrwxrwxrwx. 1 root root 15 Feb 18 2016 rc.sysinit -> rc.d/rc.sysinit lrwxrwxrwx. 1 root root 14 Feb 18 2016 redhat-release -> centos-release lrwxrwxrwx. 1 root root 11 Apr 10 2016 rmt -> ../sbin/rmt lrwxrwxrwx. 1 root root 14 Feb 18 2016 system-release -> centos-release
4.3.3 设备文件、FIFO、套接字文件
关于这3种文件类型的文件只需要通过inode就能完全保存它们的信息,它们不占用任何数据块,所以它们是特殊文件。
设备文件的主设备号和次设备号也保存在inode中。以下是/dev/下的部分设备信息。注意到它们的第5列和第6列信息,它们分别是主设备号和次设备号,主设备号标识每一种设备的类型,次设备号标识同种设备类型的不同编号;也注意到这些信息中没有大小的信息,因为设备文件不占用数据块所以没有大小的概念。
[root@xuexi ~]# ll /dev | tailcrw-rw---- 1 vcsa tty 7, 129 Oct 7 21:26 vcsa1 crw-rw---- 1 vcsa tty 7, 130 Oct 7 21:27 vcsa2 crw-rw---- 1 vcsa tty 7, 131 Oct 7 21:27 vcsa3 crw-rw---- 1 vcsa tty 7, 132 Oct 7 21:27 vcsa4 crw-rw---- 1 vcsa tty 7, 133 Oct 7 21:27 vcsa5 crw-rw---- 1 vcsa tty 7, 134 Oct 7 21:27 vcsa6 crw-rw---- 1 root root 10, 63 Oct 7 21:26 vga_arbiter crw------- 1 root root 10, 57 Oct 7 21:26 vmci crw-rw-rw- 1 root root 10, 56 Oct 7 21:27 vsock crw-rw-rw- 1 root root 1, 5 Oct 7 21:26 zero
4.4 inode基础知识
每个文件都有一个inode,在将inode关联到文件后系统将通过inode号来识别文件,而不是文件名。并且访问文件时将先找到inode,通过inode中记录的block位置找到该文件。
4.4.1 硬链接
虽然每个文件都有一个inode,但是存在一种可能:多个文件的inode相同,也就即inode号、元数据、block位置都相同,这是一种什么样的情况呢?能够想象这些inode相同的文件使用的都是同一条inode记录,所以代表的都是同一个文件,这些文件所在目录的data block中的inode指针目的地都是一样的,只不过各指针对应的文件名互不相同而已。这种inode相同的文件在Linux中被称为"硬链接"。
硬链接文件的inode都相同,每个文件都有一个"硬链接数"的属性,使用ls -l的第二列就是被硬链接数,它表示的就是该文件有几个硬链接。
[root@xuexi ~]# ls -l total 48drwxr-xr-x 5 root root 4096 Oct 15 18:07 700-rw-------. 1 root root 1082 Feb 18 2016 anaconda-ks.cfg-rw-r--r-- 1 root root 399 Apr 29 2016 Identity.pub-rw-r--r--. 1 root root 21783 Feb 18 2016 install.log-rw-r--r--. 1 root root 6240 Feb 18 2016 install.log.syslog
例如下图描述的是dir1目录中的文件name1及其硬链接dir2/name2,右边分别是它们的inode和datablock。这里也看出了硬链接文件之间唯一不同的就是其所在目录中的记录不同。注意下图中有一列Link Count就是标记硬链接数的属性。

每创建一个文件的硬链接,实质上是多一个指向该inode记录的inode指针,并且硬链接数加1。
删除文件的实质是删除该文件所在目录data block中的对应的inode指针,所以也是减少硬链接次数,由于block指针是存储在inode中的,所以不是真的删除数据,如果仍有其他指针指向该inode,那么该文件的block指针仍然是可用的。当硬链接次数为1时再删除文件就是真的删除文件了,此时inode记录中block指针也将被删除。
不能跨分区创建硬链接,因为不同文件系统的inode号可能会相同,如果允许创建硬链接,复制到另一个分区时inode可能会和此分区已使用的inode号冲突。
硬链接只能对文件创建,无法对目录创建硬链接。之所以无法对目录创建硬链接,是因为文件系统已经把每个目录的硬链接创建好了,它们就是相对路径中的"."和"..",分别标识当前目录的硬链接和上级目录的硬链接。每一个目录中都会包含这两个硬链接,它包含了两个信息:(1)一个没有子目录的目录文件的硬链接数是2,其一是目录本身,其二是".";(2)一个包含子目录的目录文件,其硬链接数是2+子目录数,因为每个子目录都关联一个父目录的硬链接".."。很多人在计算目录的硬链接数时认为由于包含了"."和"..",所以空目录的硬链接数是2,这是错误的,因为".."不是本目录的硬链接。另外,还有一个特殊的目录应该纳入考虑,即"/"目录,它自身是一个文件系统的入口,是自引用(下文中会解释自引用)的,所以"/"目录下的"."和".."的inode号相同,硬链接数除去其内的子目录后应该为3,但结果是2,不知为何?
[root@xuexi ~]# ln /tmp /mydataln: `/tmp': hard link not allowed for directory
为什么文件系统自己创建好了目录的硬链接就不允许人为创建呢?从"."和".."的用法上考虑,如果当前目录为/usr,我们可以使用"./local"来表示/usr/local,但是如果我们人为创建了/usr目录的硬链接/tmp/husr,难道我们也要使用"/tmp/husr/local"来表示/usr/local吗?这其实已经是软链接的作用了。若要将其认为是硬链接的功能,这必将导致硬链接维护的混乱。
不过,通过mount工具的"--bind"选项,可以将一个目录挂载到另一个目录下,实现伪"硬链接",它们的内容和inode号是完全相同的。
硬链接的创建方法:ln file_target link_name。
4.4.2 软链接
软链接就是字符链接,链接文件默认指的就是字符文件,使用"l"表示其类型。
软链接在功能上等价与Windows系统中的快捷方式,它指向原文件,原文件损坏或消失,软链接文件就损坏。可以认为软链接inode记录中的指针内容是目标路径的字符串。
创建方式:ln –s file_target softlink_name
查看软链接的值:readlink softlink_name
在设置软链接的时候,target虽然不要求是绝对路径,但建议给绝对路径。是否还记得软链接文件的大小?它是根据软链接所指向路径的字符数计算的,例如某个符号链接的指向方式为"rmt --> ../sbin/rmt",它的文件大小为11字节,也就是说只要建立了软链接后,软链接的指向路径是不会改变的,仍然是"../sbin/rmt"。如果此时移动软链接文件本身,它的指向是不会改变的,仍然是11个字符的"../sbin/rmt",但此时该软链接父目录下可能根本就不存在/sbin/rmt,也就是说此时该软链接是一个被破坏的软链接。
4.5 inode深入
4.5.1 inode大小和划分
inode大小为128字节的倍数,最小为128字节。它有默认值大小,它的默认值由/etc/mke2fs.conf文件中指定。不同的文件系统默认值可能不同。
[root@xuexi ~]# cat /etc/mke2fs.conf
[defaults]
base_features = sparse_super,filetype,resize_inode,dir_index,ext_attr
enable_periodic_fsck = 1blocksize = 4096inode_size = 256inode_ratio = 16384[fs_types]
ext3 = {
features = has_journal
}
ext4 = {
features = has_journal,extent,huge_file,flex_bg,uninit_bg,dir_nlink,extra_isize
inode_size = 256}同样观察到这个文件中还记录了blocksize的默认值和inode分配比率inode_ratio。inode_ratio=16384表示每16384个字节即16KB就分配一个inode号,由于默认blocksize=4KB,所以每4个block就分配一个inode号。当然分配的这些inode号只是预分配,并不真的代表会全部使用,毕竟每个文件才会分配一个inode号。但是分配的inode自身会占用block,而且其自身大小256字节还不算小,所以inode号的浪费代表着空间的浪费。
既然知道了inode分配比率,就能计算出每个块组分配多少个inode号,也就能计算出inode table占用多少个block。
如果文件系统中大量存储电影等大文件,inode号就浪费很多,inode占用的空间也浪费很多。但是没办法,文件系统又不知道你这个文件系统是用来存什么样的数据,多大的数据,多少数据。
当然inodesize、inode分配比例、blocksize都可以在创建文件系统的时候人为指定。
4.5.2 ext文件系统预留的inode号
Ext预留了一些inode做特殊特性使用,如下:某些可能并非总是准确,具体的inode号对应什么文件可以使用"find / -inum NUM"查看。
Ext4的特殊inode
Inode号 用途
0 不存在0号inode
1 虚拟文件系统,如/proc和/sys
2 根目录
3 ACL索引
4 ACL数据
5 Boot loader
6 未删除的目录
7 预留的块组描述符inode
8 日志inode
11 第一个非预留的inode,通常是lost+found目录
所以在ext4文件系统的dumpe2fs信息中,能观察到fisrt inode号可能为11也可能为12。
并且注意到"/"的inode号为2,这个特性在文件访问时会用上。
需要注意的是,每个文件系统都会分配自己的inode号,不同文件系统之间是可能会出现使用相同inode号文件的。例如:
[root@xuexi ~]# find / -ignore_readdir_race -inum 2 -ls 2 4 dr-xr-xr-x 22 root root 4096 Jun 9 09:56 / 2 2 dr-xr-xr-x 5 root root 1024 Feb 25 11:53 /boot 2 0 c--------- 1 root root Jun 7 02:13 /dev/pts/ptmx 2 0 -rw-r--r-- 1 root root 0 Jun 6 18:13 /proc/sys/fs/binfmt_misc/status 2 0 drwxr-xr-x 3 root root 0 Jun 6 18:13 /sys/fs
從結果可見,除了根的Inode號為2,還有幾個檔案的inode號也是 2,它們都屬於獨立的檔案系統,有些是虛擬檔案系統,如/proc和/sys。
4.5.3 ext2/3的inode直接、間接尋址
前文說過,inode中保存了blocks指針,但是一條inode記錄中能保存的指針數量是有限的,否則就會超出inode大小(128位元組或256位元組)。
在ext2和ext3檔案系統中,一個inode中最多只能有15個指針,每個指針使用i_block[n]表示。
前12個指標i_block[0]到i_block[11]是直接定址指針,每個指標指向一個資料區的block。如下圖所示。
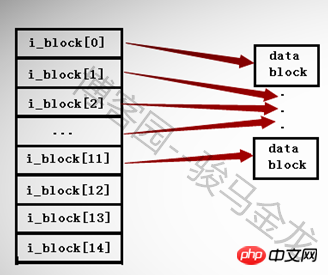
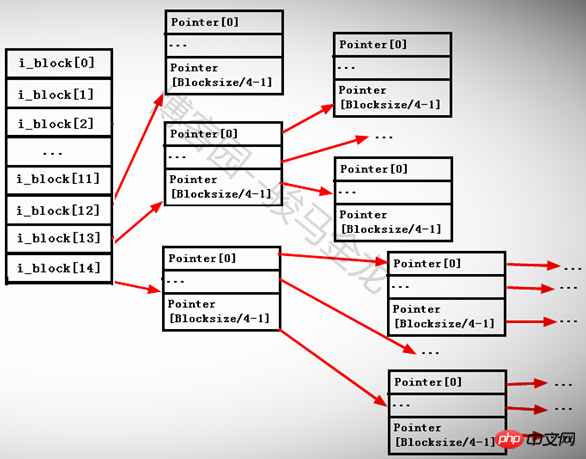
第13個指標i_block[12]是一級間接定址指針,它指向一個仍儲存了指標的block即i_block[13] --> Pointerblock --> datablock。
第14個指針i_block[13]是二級間接尋址指針,它指向一個仍然存儲了指針的block,但是這個block中的指針還繼續指向其他存儲指針的block,即i_block[ 13] --> Pointerblock1 --> PointerBlock2 --> datablock。
第15個指針i_block[14]是三級間接尋址指針,它指向一個任然儲存了指針的block,這個指針block下還有兩次指針指向。即i_block[13] --> Pointerblock1 --> PointerBlock2 --> PointerBlock3 --> datablock。
其中由於每個指標大小為4字節,所以每個指標block能存放的指標數量為BlockSize/4byte。例如blocksize為4KB,那麼一個Block可以存放4096/4=1024個指標。
如下圖。
為什麼要分間接和直接指標呢?如果一個inode中15個指針全是直接指針,假如每個block的大小為1KB,那麼15個指針只能指向15個block即15KB的大小,由於每個檔案對應一個inode號,所以就限制了每個檔案最大為15*1=15KB,這顯然是不合理的。
如果儲存大於15KB的檔案而又不太大的時候,就佔用一級間接指標i_block[12],這時可以存放指標數量為1024/4+12=268,所以能存放268KB的文件。
如果儲存大於268K 的檔案而又不太大的時候,就繼續佔用二級指標i_block[13],這時可以存放指標數量為[1024/4]^2+1024/4+ 12=65804,所以能存放65804KB=64M左右的文件。
如果存放的檔案大於64M,那麼就繼續使用三級間接指標i_block[14],存放的指標數量為[1024/4]^3+[1024/4]^2+[1024/ 4]+12=16843020個指針,所以能存放16843020KB=16GB左右的檔案。
如果blocksize=4KB呢?那麼最大能存放的文件大小為([4096/4]^3+[4096/4]^2+[4096/4]+12)*4/1024/1024/1024=4T左右。
當然這樣計算出來的不一定就是最大能存放的檔案大小,它還受到另一個條件的限制。這裡的計算只是顯示一個大檔案是如何尋址和分配的。
其實看到這裡的計算數值,就知道ext2和ext3對超大檔案的存取效率是低的,它要核對太多的指針,特別是4KB大小的blocksize時。而ext4針對這一點就進行了最佳化,ext4使用extent的管理方式取代ext2和ext3的區塊映射,大大提高了效率也降低了碎片。
4.6 單一檔案系統中檔案操作的原理
#在Linux上執行刪除、複製、重新命名、移動等操作時,它們是怎麼進行的呢?還有訪問文件時是如何找到它的呢?其實只要理解了前文介紹的幾個術語以及它們的作用就很容易知道文件操作的原理了。
註:在這一小節所解釋的都是在單一檔案系統下的行為,在多個檔案系統中如何請看下一個小節:多檔案系統關聯。
4.6.1 讀取檔案
當執行"cat /var/log/messages"指令在系統內部進行了什麼樣的步驟呢?這個指令能被成功執行涉及了cat指令的尋找、權限判斷以及messages檔案的尋找和權限判斷等等複雜的過程。這裡只解釋和本節內容相關的如何尋找到被cat的/var/log/messages檔案。
找到根檔案系統的區塊組描述表所在的blocks,讀取GDT(已在記憶體中)找到inode table的block號碼。
因為GDT總是和superblock在同一個區塊組,而superblock總是在分割的第1024-2047個字節,所以很容易就知道第一個GDT所在的區塊組以及GDT在這個區塊組中佔用了哪些block。
其實GDT早已經在記憶體中了,在系統開機的時候會掛在根檔案系統,掛載的時候就已經將所有的GDT放進記憶體中。
在inode table的block中定位到根"/"的inode,找出"/"指向的data block。
前文說過,ext檔案系統預留了一些inode號,其中"/"的inode號為2,所以可以根據inode號直接定位根目錄檔案的data block。
在"/"的datablock中記錄了var目錄名稱和指向var目錄檔案inode的指針,並找到該inode記錄,inode記錄中儲存了指向var的block指針,所以也找到了var目錄檔的data block。
透過var目錄的inode指針,可以尋找到var目錄的inode記錄,但是指針定位的過程中,還需要知道該inode記錄所在的塊組以及所在的inode table,所以需要讀取GDT,同樣,GDT已經快取到了記憶體中。
在var的data block中記錄了log目錄名和其inode指針,透過該指針定位到該inode所在的區塊組及所在的inode table,並根據該inode記錄找到log的data block。
在log目錄檔案的data block中記錄了messages檔案名稱和對應的inode指針,透過該指針定位到該inode所在的區塊組及所在的inode table,並根據該inode記錄找到messages的data block。
最後讀取messages對應的datablock。
將上述步驟中GDT部分的步驟簡化後比較容易理解。如下:找到GDT-->找到"/"的inode-->找到/的資料塊讀取var的inode-->找到var的資料區塊讀取log的inode-->找到log的數據區塊讀取messages的inode-->找到messages的資料區塊並讀取它們。
4.6.2 刪除、重新命名和移動檔案
注意這裡是不跨越檔案系統的操作行為。
刪除文件分為普通文件和目錄文件,知道了這兩種類型的文件的刪除原理,就知道了其他類型特殊文件的刪除方法。
對於刪除普通檔案:找到檔案的inode和data block(根據前一個小節中的方法尋找);在imap中將該檔案的inode號標記為未使用;將bmap中data block對應的block號標記為未使用;在其所在目錄的data block中將該檔案名稱所在的記錄行刪除,刪除了記錄就遺失了指向Inode的指標。
對於刪除目錄檔案:找到目錄和目錄下所有檔案、子目錄、子檔案的inode和data block;在imap中將這些inode號標記為未使用;將bmap中將這些檔案佔用的block號標記為未使用;在該目錄的父目錄的data block中將該目錄名稱所在的記錄行刪除。需要注意的是,刪除父目錄data block中的記錄是最後一步,如果該步驟提前,將報目錄非空的錯誤,因為在該目錄中還有文件佔用。
重新命名檔案分為同目錄內重新命名和非同目錄內重新命名。非同目錄內重命名其實是移動檔案的過程,請參見下文。
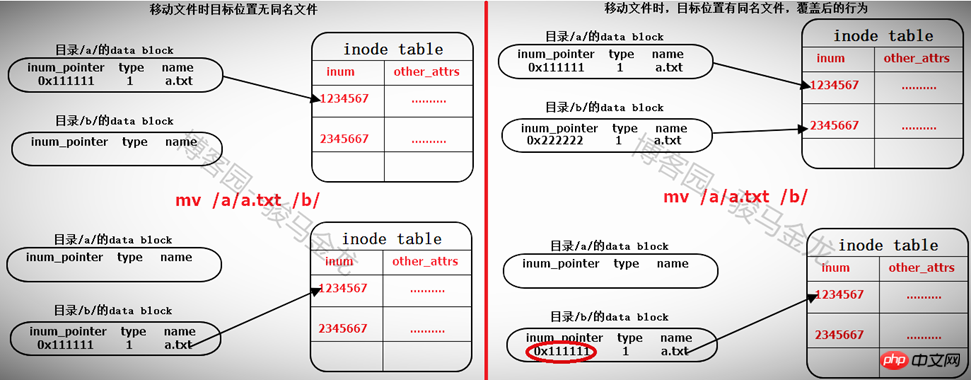
同目錄內重新命名檔案的動作只是修改所在目錄data block中該檔案記錄的檔案名稱部分,不是刪除再重建的過程。
如果重新命名時有檔案名稱衝突(該目錄內已經存在該檔案名稱),則提示是否覆蓋。覆蓋的過程是覆蓋目錄data block中衝突檔案的記錄。例如/tmp/下有a.txt和a.log,若將a.txt重新命名為a.log,則提示覆蓋,若選擇覆蓋,則/tmp的data block中關於a.log的記錄被覆蓋,此時它的指標是指向a.txt的inode。
移動檔案
同檔案系統下移動檔案其實是修改目標檔案所在目錄的data block,在其中新增一行指向inode table中待移動文件的inode指針,如果目標路徑下有同名文件,則會提示是否覆蓋,實際上是覆蓋目錄data block中衝突文件的記錄,由於同名文件的inode記錄指針被覆蓋,所以無法再找到該檔案的data block,也就是說該檔案被標記為刪除(如果多個硬連結數,則另當別論)。
所以在同檔系統內移動檔案相當快,僅在所在目錄data block中新增或覆寫了一筆記錄而已。也因此,移動檔案時,檔案的inode號是不會改變的。
對於不同檔案系統內的移動,相當於先複製再刪除的動作。見後文。
4.6.1 存储和复制文件
对于文件存储
(1).读取GDT,找到各个(或部分)块组imap中未使用的inode号,并为待存储文件分配inode号;
(2).在inode table中完善该inode号所在行的记录;
(3).在目录的data block中添加一条该文件的相关记录;
(4).将数据填充到data block中。
注意,填充到data block中的时候会调用block分配器:一次分配4KB大小的block数量,当填充完4KB的data block后会继续调用block分配器分配4KB的block,然后循环直到填充完所有数据。也就是说,如果存储一个100M的文件需要调用block分配器100*1024/4=25600次。
另一方面,在block分配器分配block时,block分配器并不知道真正有多少block要分配,只是每次需要分配时就分配,在每存储一个data block前,就去bmap中标记一次该block已使用,它无法实现一次标记多个bmap位。这一点在ext4中进行了优化。
(5)填充完之后,去inode table中更新该文件inode记录中指向data block的寻址指针。
对于复制,完全就是另一种方式的存储文件。步骤和存储文件的步骤一样。
4.7 多文件系统关联
在单个文件系统中的文件操作和多文件系统中的操作有所不同。本文将对此做出非常详细的说明。
4.7.1 根文件系统的特殊性
这里要明确的是,任何一个文件系统要在Linux上能正常使用,必须挂载在某个已经挂载好的文件系统中的某个目录下,例如/dev/cdrom挂载在/mnt上,/mnt目录本身是在"/"文件系统下的。而且任意文件系统的一级挂载点必须是在根文件系统的某个目录下,因为只有"/"是自引用的。这里要说明挂载点的级别和自引用的概念。
假如/dev/sdb1挂载在/mydata上,/dev/cdrom挂载在/mydata/cdrom上,那么/mydata就是一级挂载点,此时/mydata已经是文件系统/dev/sdb1的入口了,而/dev/cdrom所挂载的目录/mydata/cdrom是文件系统/dev/sdb1中的某个目录,那么/mydata/cdrom就是二级挂载点。一级挂载点必须在根文件系统下,所以可简述为:文件系统2挂载在文件系统1中的某个目录下,而文件系统1又挂载在根文件系统中的某个目录下。
再解释自引用。首先要说的是,自引用的只能是文件系统,而文件系统表现形式是一个目录,所以自引用是指该目录的data block中,"."和".."的记录中的inode指针都指向inode table中同一个inode记录,所以它们inode号是相同的,即互为硬链接。而根文件系统是唯一可以自引用的文件系统。
[root@xuexi /]# ll -ai /total 102 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 . 2 dr-xr-xr-x. 22 root root 4096 Jun 6 18:13 ..
由此也能解释cd /.和cd /..的结果都还是在根下,这是自引用最直接的表现形式。
[root@xuexi tmp]# cd /. [root@xuexi /]# [root@xuexi tmp]# cd /.. [root@xuexi /]#
但是有一个疑问,根目录下的"."和".."都是"/"目录的硬链接,所以除去根目录下目录数后的硬链接数位3,但实际却为2,不知道这是为何?
[root@server2 tmp]# a=$(ls -al / | grep "^d" |wc -l) [root@server2 tmp]# b=$(ls -l / | grep "^d" |wc -l) [root@server2 tmp]# echo $((a - b))2
4.7.2 挂载文件系统的细节
挂载文件系统到某个目录下,例如"mount /dev/cdrom /mnt",挂载成功后/mnt目录中的文件全都暂时不可见了,且挂载后权限和所有者(如果指定允许普通用户挂载)等的都改变了,知道为什么吗?
下面就以通过"mount /dev/cdrom /mnt"为例,详细说明挂载过程中涉及的细节。
在将文件系统/dev/cdrom(此处暂且认为它是文件系统)挂载到挂载点/mnt之前,挂载点/mnt是根文件系统中的一个目录,"/"的data block中记录了/mnt的一些信息,其中包括inode指针inode_n,而在inode table中,/mnt对应的inode记录中又存储了block指针block_n,此时这两个指针还是普通的指针。
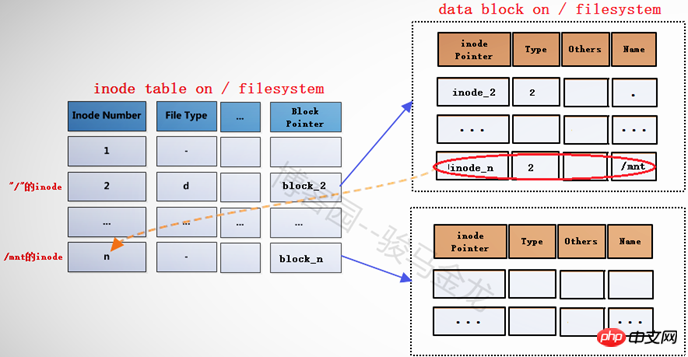
当文件系统/dev/cdrom挂载到/mnt上后,/mnt此时就已经成为另一个文件系统的入口了,因此它需要连接两边文件系统的inode和data block。但是如何连接呢?如下图。
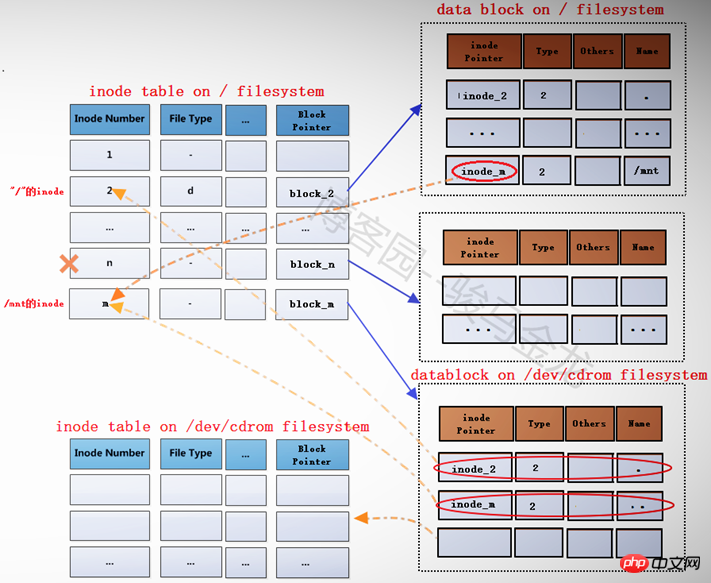
在根文件系统的inode table中,为/mnt重新分配一个inode记录m,该记录的block指针block_m指向文件系统/dev/cdrom中的data block。既然为/mnt分配了新的inode记录m,那么在"/"目录的data block中,也需要修改其inode指针为inode_m以指向m记录。同时,原来inode table中的inode记录n就被标记为暂时不可用。
block_m指向的是文件系统/dev/cdrom的data block,所以严格说起来,除了/mnt的元数据信息即inode记录m还在根文件系统上,/mnt的data block已经是在/dev/cdrom中的了。这就是挂载新文件系统后实现的跨文件系统,它将挂载点的元数据信息和数据信息分别存储在不同的文件系统上。
挂载完成后,将在/proc/self/{mounts,mountstats,mountinfo}这三个文件中写入挂载记录和相关的挂载信息,并会将/proc/self/mounts中的信息同步到/etc/mtab文件中,当然,如果挂载时加了-n参数,将不会同步到/etc/mtab。
而卸载文件系统,其实质是移除临时新建的inode记录(当然,在移除前会检查是否正在使用)及其指针,并将指针指回原来的inode记录,这样inode记录中的block指针也就同时生效而找回对应的data block了。由于卸载只是移除inode记录,所以使用挂载点和文件系统都可以实现卸载,因为它们是联系在一起的。
下面是分析或结论。
(1).挂载点挂载时的inode记录是新分配的。
# 挂载前挂载点/mnt的inode号
[root@server2 tmp]# ll -id /mnt100663447 drwxr-xr-x. 2 root root 6 Aug 12 2015 /mnt [root@server2 tmp]# mount /dev/cdrom /mnt
# 挂载后挂载点的inode号 [root@server2 tmp]# ll -id /mnt 1856 dr-xr-xr-x 8 root root 2048 Dec 10 2015 mnt
由此可以验证,inode号确实是重新分配的。
(2).挂载后,挂载点的内容将暂时不可见、不可用,卸载后文件又再次可见、可用。
# 在挂载前,向挂载点中创建几个文件 [root@server2 tmp]# touch /mnt/a.txt [root@server2 tmp]# mkdir /mnt/abcdir
# 挂载 [root@server2 tmp]# mount /dev/cdrom /mnt # 挂载后,挂载点中将找不到刚创建的文件 [root@server2 tmp]# ll /mnt total 636-r--r--r-- 1 root root 14 Dec 10 2015 CentOS_BuildTag dr-xr-xr-x 3 root root 2048 Dec 10 2015 EFI-r--r--r-- 1 root root 215 Dec 10 2015 EULA-r--r--r-- 1 root root 18009 Dec 10 2015 GPL dr-xr-xr-x 3 root root 2048 Dec 10 2015 images dr-xr-xr-x 2 root root 2048 Dec 10 2015 isolinux dr-xr-xr-x 2 root root 2048 Dec 10 2015 LiveOS dr-xr-xr-x 2 root root 612352 Dec 10 2015 Packages dr-xr-xr-x 2 root root 4096 Dec 10 2015 repodata-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-7-r--r--r-- 1 root root 1690 Dec 10 2015 RPM-GPG-KEY-CentOS-Testing-7-r--r--r-- 1 root root 2883 Dec 10 2015 TRANS.TBL # 卸载后,挂载点/mnt中的文件将再次可见 [root@server2 tmp]# umount /mnt [root@server2 tmp]# ll /mnt total 0drwxr-xr-x 2 root root 6 Jun 9 08:18 abcdir-rw-r--r-- 1 root root 0 Jun 9 08:18 a.txt
之所以會這樣,是因為掛載檔案系統後,掛載點原來的inode記錄暫時被標記為不可用,關鍵是沒有指向該inode記錄的inode指標了。在卸載檔案系統後,又重新啟用掛載點原來的inode記錄,"/"目錄下的mnt的inode指標又重新指向該inode記錄。
(3).掛載後,掛載點的元資料和data block是分別存放在不同檔案系統上的。
(4).掛載點即使在掛載後,也還是屬於原始檔案系統的檔案。
4.7.3 多重檔案系統操作關聯
假如下圖中的圓代表一塊硬碟,其中分割了3個區即3個檔案系統。其中根是根檔案系統,/mnt是另一個檔案系統A的入口,A檔案系統掛載在/mnt上,/mnt/cdrom也是一個檔案系統B的入口,B檔案系統掛載在/mnt/cdrom上。每個檔案系統都維護了一些inode table,這裡假設圖中的inode table是每個檔案系統所有區塊組中的inode table的集合表。

如何讀取/var/log/messages呢?這是和"/"在同一個檔案系統的檔案讀取,在前面單檔案系統中已經詳細說明了。
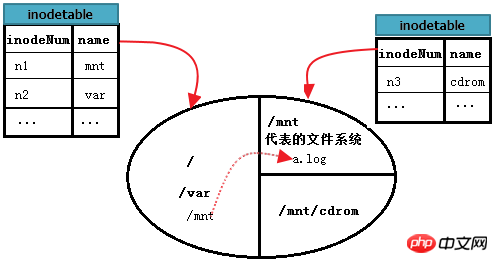
但要如何讀取A檔案系統中的/mnt/a.log呢?首先,從根檔案系統找到/mnt的inode記錄,這是單一檔案系統內的查找;然後根據此inode記錄的block指針,定位到/mnt的data block中,這些block是A檔案系統的data block;然後從/mnt的data block中讀取a.log記錄,並根據a.log的inode指標定位到A檔案系統的inode table中對應a.log的inode記錄;最後從此inode記錄的block指標找到a. log的data block。至此,就能讀取到/mnt/a.log檔案的內容。
下圖能更完整的描述上述過程。
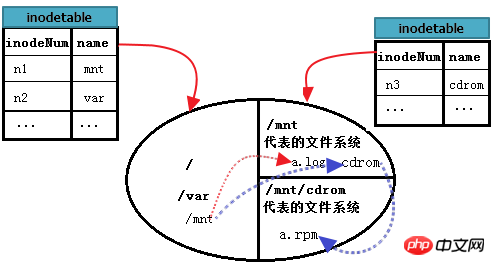
那麼又要如何讀取/mnt/cdrom中的/mnt/cdrom/a.rpm呢?這裡cdrom代表的檔案系統B掛載點位於/mnt下,所以又多了一個步驟。先找到"/",再找到根中的mnt,進入到mnt檔案系統中,找到cdrom的data block,再進入到cdrom找到a.rpm。也就是說,mnt目錄檔案存放位置是根,cdrom目錄檔案存放位置是mnt,最後a.rpm存放的位置才是cdrom。
繼續完善上圖。如下。
4.8 ext3檔案系統的日誌功能
比起ext2檔案系統,ext3多了一個日誌功能。
在ext2檔案系統中,只有兩個區:資料區和元資料區。如果正在向data block中填充資料時突然斷電,那麼下一次啟動時就會檢查檔案系統中資料和狀態的一致性,這段檢查和修復可能會消耗大量時間,甚至檢查後無法修復。之所以會這樣是因為檔案系統在突然斷電後,它不知道上次正在儲存的檔案的block從哪裡開始、哪裡結束,所以它會掃描整個檔案系統進行排除(也許是這樣檢查的吧)。
而在建立ext3檔案系統時會劃分三個區:資料區、日誌區和元資料區。每次儲存資料時,先在日誌區中進行ext2中元資料區的活動,直到檔案儲存完成後標記上commit才將日誌區中的資料轉存到元資料區。當儲存檔案時突然斷電,下次檢查修復檔案系統時,只需要檢查日誌區的記錄,將bmap對應的data block標記為未使用,並把inode號標記未使用,這樣就不需要掃描整個文件系統而耗費大量時間。
雖然說ext3相比ext2多了一個日誌區轉寫元資料區的動作而導致ext3相比ext2效能要差一點,特別是寫眾多小檔案時。但是由於ext3其他方面的最佳化使得ext3和ext2效能幾乎沒有差距。
4.9 ext4檔案系統
回顧前面關於ext2和ext3檔案系統的儲存格式,它使用block為儲存單元,每個block使用bmap中的位元來標記是否空閒,儘管使用分割塊組的方法優化提高了效率,但是一個塊組內部仍然使用bmap來標記該塊組內的block。對於一個龐大的文件,掃描整個bmap將是一件浩大的工程。另外在inode尋址方面,ext2/3使用直接和間接的尋址方式,對於三級間接指針,可能要遍歷的指針數量是非常非常巨大的。
ext4檔案系統的最大特點是在ext3的基礎上使用區(extent,或稱為段)的概念來管理。一個extent盡可能的包含物理上連續的一堆block。 inode尋址方面也一樣使用區段樹的方式進行了改進。
預設情況下,EXT4不再使用EXT3的block mapping分配方式 ,而改為Extent方式分配。
(1). 關於EXT4的結構特徵
EXT4在總體結構上與EXT3相似,大的分配方向都是基於相同大小的區塊組,每個區塊組內分配固定數量的inode、可能的superblock(或備份)及GDT。
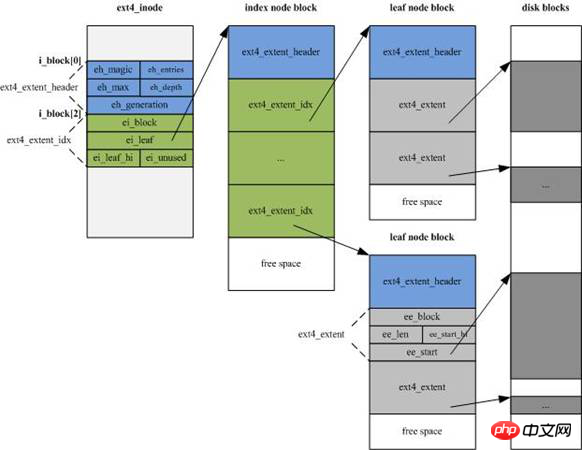
EXT4的inode 結構做了重大改變,為增加新的信息,大小由EXT3的128字節增加到預設的256字節,同時inode尋址索引不再使用EXT3的"12個直接尋址區塊+1個一級間接尋址區塊+1個二級間接尋址區塊+1個三級間接尋址區塊"的索引模式,而改為4個Extent片斷流,每個片斷流設定片段的起始block號及連續的block數量(有可能直接指向資料區,也有可能指向索引區塊區)。
片段流即下圖中索引節點(inde node block)部分的綠色區域,每個15位元組,共60位元組。
(2). EXT4刪除資料的結構變更。
EXT4刪除資料後,會依序釋放檔案系統bitmap空間位元、更新目錄結構、釋放inode空間位。
(3). ext4使用多block分配方式。
在儲存資料時,ext3中的block分配器一次只能分配4KB大小的Block數量,而且每儲存一個block前就標記一次bmap。假如儲存1G的文件,blocksize是4KB,那麼每儲存完一個Block就會呼叫一次block分配器,也就是呼叫的次數為1024*1024/4KB=262144次,標記bmap的次數也為1024*1024/4= 262144次。
而在ext4中根據區段來分配,可以實現調用一次block分配器就分配一堆連續的block,並在儲存這一堆block前一次性標記對應的bmap。這對於大檔案來說極大的提升了儲存效率。
4.10 ext類別的檔案系統的缺點
#最大的缺點是它在建立檔案系統的時候就分割好一切需要分割的東西,以後用到的時候可以直接進行分配,也就是說它不支援動態劃分和動態分配。對於較小的分割區來說速度還好,但是對於一個超大的磁碟,速度是極慢極慢的。例如將幾十T的磁碟陣列格式化為ext4檔案系統,可能你會因此失去一切耐心。
除了格式化速度超慢以外,ext4檔案系統還是非常可取的。當然,不同公司開發的文件系統都各有特色,最主要的還是依需求選擇合適的文件系統類型。
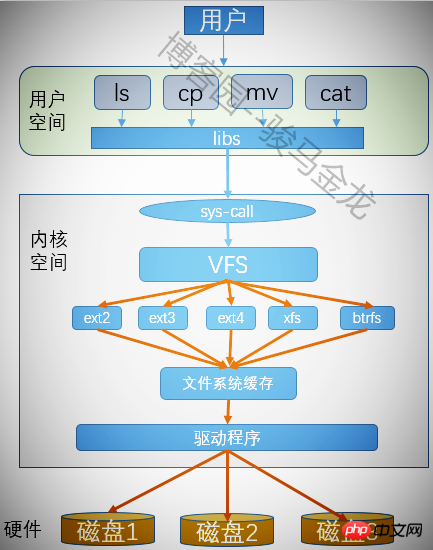
4.11 虛擬檔案系統VFS
每個分割區格式化後都可以建立一個檔案系統,Linux上可以辨識很多種檔案系統,那麼它是如何識別的呢?另外,在我們操作分區中的檔案時,並沒有指定過它是哪個檔案系統的,各種不同的檔案系統如何被我們使用者以無差別的方式操作呢?這就是虛擬檔案系統的作用。
虛擬檔案系統為使用者操作各種檔案系統提供了通用接口,使得使用者執行程式時不需要考慮檔案是在哪種類型的檔案系統上,應該使用什麼樣的系統呼叫什麼樣的系統函數來操作該檔案。有了虛擬檔案系統,只要將所有需要執行的程式呼叫VFS的系統呼叫就可以了,剩下的動作由VFS來幫忙完成。
轉載請註明出處:
以上是ext檔案系統機制的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 CUDA之通用矩陣乘法:從入門到熟練!
Mar 25, 2024 pm 12:30 PM
CUDA之通用矩陣乘法:從入門到熟練!
Mar 25, 2024 pm 12:30 PM
通用矩陣乘法(GeneralMatrixMultiplication,GEMM)是許多應用程式和演算法中至關重要的一部分,也是評估電腦硬體效能的重要指標之一。透過深入研究和優化GEMM的實現,可以幫助我們更好地理解高效能運算以及軟硬體系統之間的關係。在電腦科學中,對GEMM進行有效的最佳化可以提高運算速度並節省資源,這對於提高電腦系統的整體效能至關重要。深入了解GEMM的工作原理和最佳化方法,有助於我們更好地利用現代計算硬體的潛力,並為各種複雜計算任務提供更有效率的解決方案。透過對GEMM性能的優
 出現0x80004005錯誤代碼怎麼辦 小編教你0x80004005錯誤代碼解決方法
Mar 21, 2024 pm 09:17 PM
出現0x80004005錯誤代碼怎麼辦 小編教你0x80004005錯誤代碼解決方法
Mar 21, 2024 pm 09:17 PM
在電腦中刪除或解壓縮資料夾,時有時會彈出提示對話框“錯誤0x80004005:未指定錯誤”,如果遇到這中情況應該怎麼解決呢?提示錯誤碼0x80004005的原因其實很多,但大部分因為病毒導致,我們可以重新註冊dll來解決問題,下面,小編給大夥講解0x80004005錯誤代碼處理經驗。有使用者在使用電腦時出現錯誤代碼0X80004005的提示,0x80004005錯誤主要是由於電腦沒有正確註冊某些動態連結庫文件,或電腦與Internet之間存在不允許的HTTPS連接防火牆所引起。那麼如何
 华为乾崑 ADS3.0 智驾系统 8 月上市 享界 S9 首发搭载
Jul 30, 2024 pm 02:17 PM
华为乾崑 ADS3.0 智驾系统 8 月上市 享界 S9 首发搭载
Jul 30, 2024 pm 02:17 PM
7月29日,在AITO问界第四十万台新车下线仪式上,华为常务董事、终端BG董事长、智能汽车解决方案BU董事长余承东出席发表演讲并宣布,问界系列车型将于今年8月迎来华为乾崑ADS3.0版本的上市,并计划在8月至9月间陆续推送升级。8月6日即将发布的享界S9将首发华为ADS3.0智能驾驶系统。华为乾崑ADS3.0版本在激光雷达的辅助下,将大幅提升智驾能力,具备融合端到端的能力,并采用GOD(通用障碍物识别)/PDP(预测决策规控)全新端到端架构,提供车位到车位智驾领航NCA功能,并升级CAS3.0全
 夸克網盤的檔案怎麼轉移到百度網盤?
Mar 14, 2024 pm 02:07 PM
夸克網盤的檔案怎麼轉移到百度網盤?
Mar 14, 2024 pm 02:07 PM
夸克網盤和百度網盤都是現在最常用的儲存文件的網盤軟體,如果想要將夸克網盤內的文件保存到百度網盤,要怎麼操作呢?本期小編整理了夸克網盤電腦端的檔案轉移到百度網盤的教學步驟,一起來看看是怎麼操作吧。 夸克網盤的檔案怎麼存到百度網盤?要將夸克網盤的文件轉移到百度網盤,首先需在夸克網盤下載所需文件,然後在百度網盤用戶端中選擇目標資料夾並開啟。接著,將夸克網盤中下載的檔案拖放到百度網盤用戶端開啟的資料夾中,或使用上傳功能將檔案新增至百度網盤。確保上傳完成後在百度網盤中查看檔案是否已成功轉移。這樣就
 hiberfil.sys是什麼檔案? hiberfil.sys可以刪除嗎?
Mar 15, 2024 am 09:49 AM
hiberfil.sys是什麼檔案? hiberfil.sys可以刪除嗎?
Mar 15, 2024 am 09:49 AM
最近有很多網友問小編,hiberfil.sys是什麼文件? hiberfil.sys佔用了大量的C碟空間可以刪除嗎?小編可以告訴大家hiberfil.sys檔是可以刪除的。下面就來看看詳細的內容。 hiberfil.sys是Windows系統中的隱藏文件,也是系統休眠文件。通常儲存在C盤根目錄下,其大小與系統安裝記憶體大小相當。這個檔案在電腦休眠時被使用,其中包含了當前系統的記憶體數據,以便在恢復時快速恢復到先前的狀態。由於其大小與記憶體容量相等,因此它可能會佔用較大的硬碟空間。 hiber
 蘋果16系統哪個版本最好
Mar 08, 2024 pm 05:16 PM
蘋果16系統哪個版本最好
Mar 08, 2024 pm 05:16 PM
蘋果16系統中版本最好的是iOS16.1.4,iOS16系統的最佳版本可能因人而異添加和日常使用體驗的提升也受到了很多用戶的好評。蘋果16系統哪個版本最好答:iOS16.1.4iOS16系統的最佳版本可能因人而異。根據公開的消息,2022年推出的iOS16被認為是一個非常穩定且性能優越的版本,用戶對其整體體驗也相當滿意。此外,iOS16中新功能的新增和日常使用體驗的提升也受到了許多用戶的好評。特別是在更新後的電池續航力、訊號表現和發熱控制方面,使用者的回饋都比較正面。然而,考慮到iPhone14
 常用常新!華為Mate60系列升級HarmonyOS 4.2:AI雲端增強、小藝方言太好用了
Jun 02, 2024 pm 02:58 PM
常用常新!華為Mate60系列升級HarmonyOS 4.2:AI雲端增強、小藝方言太好用了
Jun 02, 2024 pm 02:58 PM
4月11日,華為官方首次宣布HarmonyOS4.2百機升級計劃,此次共有180餘款設備參與升級,品類覆蓋手機、平板、手錶、耳機、智慧螢幕等設備。過去一個月,隨著HarmonyOS4.2百機升級計畫的穩定推進,包括華為Pocket2、華為MateX5系列、nova12系列、華為Pura系列等多款熱門機型也已紛紛展開升級適配,這意味著會有更多華為機型用戶享受到HarmonyOS帶來的常用常新體驗。從使用者回饋來看,華為Mate60系列機種在升級HarmonyOS4.2之後,體驗全方位躍升。尤其是華為M
 MySQL中.ibd檔的作用詳解及相關注意事項
Mar 15, 2024 am 08:00 AM
MySQL中.ibd檔的作用詳解及相關注意事項
Mar 15, 2024 am 08:00 AM
MySQL中.ibd檔案的作用詳解及相關注意事項MySQL是一種流行的關聯式資料庫管理系統,資料庫中的資料儲存在不同的檔案中。其中,.ibd檔案是InnoDB儲存引擎中的資料文件,用於儲存表格中的資料和索引。本文將對MySQL中.ibd檔案的作用進行詳細解析,並提供相關程式碼範例以幫助讀者更好地理解。一、.ibd檔的作用:儲存資料:.ibd檔是InnoDB存
