

SQL Server 磁碟請求逾時的833錯誤原因及解決方法_MsSql

這篇文章主要介紹了SQL Server 磁碟請求逾時的833錯誤原因及解決方法,需要的朋友可以參考下
最近遇到一個SQL Server伺服器回應極度緩慢,並且出現客戶端請求報錯的情況,在資料庫中的errorlog中出現磁碟請求超過15s才完成的error訊息。
對於這類問題,到底是儲存系統或磁碟的故障,還是SQL Server 自己的問題,亦或是應用程式引發的呢?又要如何解決?
本文將對引起此問題的某一方面的因素進行簡單的分析,但是無法涵蓋所有潛在的可能性,因此遇到類似問題還要做具體的分析。
SQL Server中的磁碟請求逾時
# 該錯誤的英文版的錯誤訊息如下:
# SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database id %d. The OS file handle is 0x%p. 0# # The offset of the latest long I/O is: %#016I64x
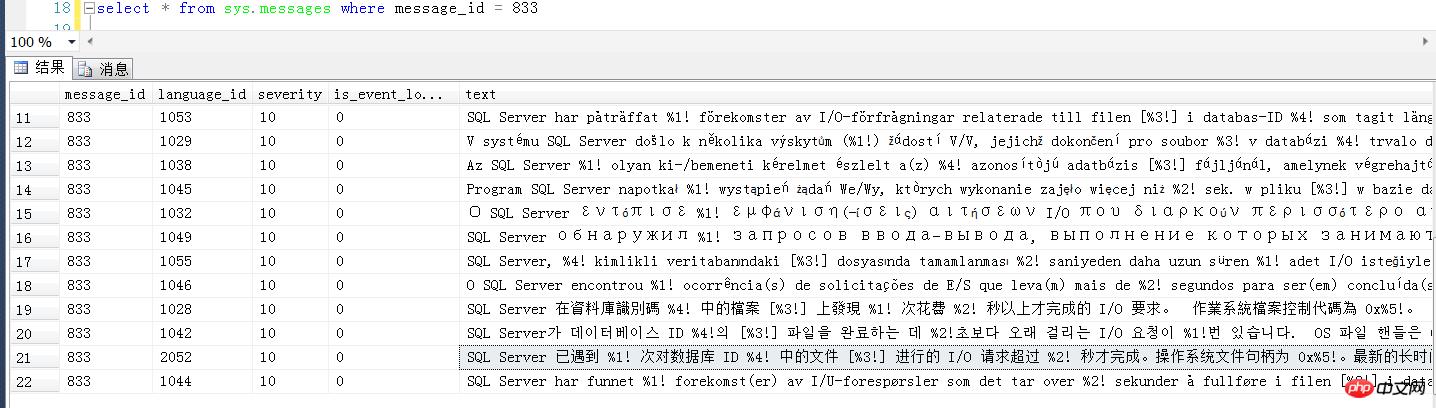
資料庫引擎錯誤833的含義
# 首先來看這個833錯誤的具體含義是什麼,就不自己裝13解釋一通了,那本經典的書上寫的很清楚了。 總之,意思就是,SQL Server在請求磁碟讀寫的時候,遇到磁碟繁忙或其他一些因素,超過了15秒還沒完成 例如資料的讀寫的時候需要向磁碟發起請求,而磁碟正忙或其他問題,來不及或相應的不夠及時,這無疑會嚴重影響SQL Server對外提供伺服器的回應時間。

原因分析
# 因為是專門的SQL Server伺服器,沒有其他應用程式的請求,很有可能跟向sqlserver資料庫發起的請求有關。 其實發生這個問題之前,早就有預兆了,平時還算穩定的伺服器(CPU很少超過60%,記憶體的PLE也可以穩定在20分鐘以上,磁碟IO延遲較低等等),只是偶爾會存在抽風一陣子的情況 抽風的時候表現為CPU狂飆到80%左右,內存的PLE會嚴重下降,IO延遲嚴重增高。 現在只能從SQL Server的Session入手,在觀察SQL Server中的活動Session的時候,發現某一類別的SQL語句的查詢時間非常長, 平時這類SQL在某一個時間段內執行的頻率還算比較高。
但是正常情況下,這類SQL的執行效率還是比較高的,為什麼突然就變的非常之底?
在檢查活動Session的對應的執行計劃的時候,發現這類活動Session的等待狀態都是IO等待(PAGEIOLATCH_SH),同時SQL的執行完全是意料之外的執行方式。
因為類似查詢還是執行的比較頻繁的,此類Session會從不同的客戶端發起,一旦SQL的執行效率降下來,伺服器上會積壓大量的活動Session
# 為什麼平常執行的好好的SQL語句突然就變的很慢很慢,
原因就在於在某一點,SQL Server自動觸發了統計資訊的更新,但是這是一個比較大的表,但是預設統計資訊更新的取樣比例是不夠的,如果取樣百分比不夠,這個統計資料完全是不可用的。
一旦自動收集統計信息完成之後,會根據當前收集到的統計信息,向之前的SQL語句發出一種它認為高效的方式(table scan而不是index seek),其實這種方式並非是合理的,
由此引發對應的SQL利用一種並非合理的執行計劃來實現查詢,同時會引發Session的擁堵,客戶端發過來大量的Session同時在利用一種低效的方式緩慢執行。
所以CPU會飆升,IO延遲增加,記憶體的PLE嚴重下降。
由此也不難理解,數十個查詢的Session正在以一種不合理的方式瘋狂地想磁碟發出請求,磁碟正在忙於活動Session的資料請求,出現無法回應因為資料或索引檔案的自動成長請求,造成一開始說的問題。
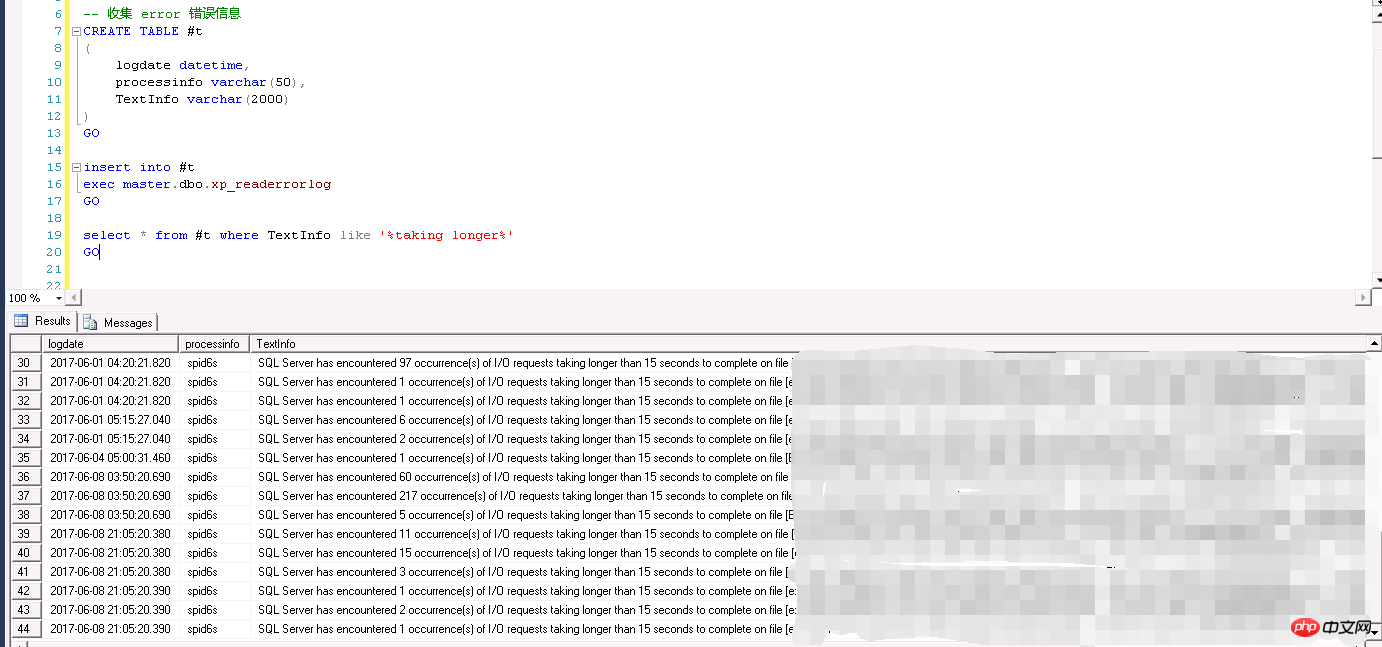
最後經過索引重建(促使統計資訊更新,當然純粹的統計資訊更新也可以)解決,長期預防的話,需要安排job人為地定義統計資訊更新的閾值以及取樣百分比。
總結:
資料庫伺服器上的問題,很多問題都是一個連鎖反應的過程,對應觀察到的部分現象,很有可能並不是表面上的反應的那樣(磁碟請求超時,問題出在存儲上?)
專業的位置上必須要有專業的素養,比如一開始DBA誤以為是存儲問題,存儲工程師認為服務器內存用滿了是不正常的等,其實都不是問題的根本原因。
面對問題,要追本溯源,找出來最根本的原因,才是解決問題的關鍵。
以上是SQL Server 磁碟請求逾時的833錯誤原因及解決方法_MsSql的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 無法完成操作(錯誤0x0000771)印表機錯誤
Mar 16, 2024 pm 03:50 PM
無法完成操作(錯誤0x0000771)印表機錯誤
Mar 16, 2024 pm 03:50 PM
如果您在使用印表機時遇到錯誤訊息,例如操作無法完成(錯誤0x00000771),可能是因為印表機已中斷連線。在這種情況下,您可以透過以下方法解決問題。在本文中,我們將討論如何在Windows11/10PC上修復此問題。整個錯誤訊息說:操作無法完成(錯誤0x0000771)。指定的印表機已被刪除。修正WindowsPC上的0x00000771印表機錯誤若要修復印表機錯誤操作無法完成(錯誤0x0000771),指定的印表機已在Windows11/10PC上刪除,請遵循下列解決方案:重新啟動列印假脫機
 揭秘HTTP狀態碼460的出現原因
Feb 19, 2024 pm 08:30 PM
揭秘HTTP狀態碼460的出現原因
Feb 19, 2024 pm 08:30 PM
解密HTTP狀態碼460:為什麼會出現這個錯誤?引言:在日常的網路使用中,常常會遇到各種各樣的錯誤提示,其中包括HTTP狀態碼。這些狀態碼是HTTP協定定義的一種機制,用來指示請求的處理。在這些狀態碼中,有一種比較罕見的錯誤碼,即460。本文將深入探討這個錯誤碼,並解釋為什麼會出現這個錯誤。 HTTP狀態碼460的定義:首先,我們要先了解HTTP狀態碼的基
 Windows沙盒啟動失敗-存取被拒絕
Feb 19, 2024 pm 01:00 PM
Windows沙盒啟動失敗-存取被拒絕
Feb 19, 2024 pm 01:00 PM
Windows沙盒是否終止,並顯示Windows沙盒無法啟動,錯誤0x80070005,拒絕存取訊息?一些用戶報告說,Windows沙盒無法開啟。如果您也遇到此錯誤,您可以按照本指南進行修復。 Windows沙盒啟動失敗-存取被拒絕如果Windows沙盒終止,並顯示Windows沙盒無法啟動,錯誤0x80070005,拒絕存取訊息,請確保您以管理員身分登入。此類錯誤通常是由於權限不足引起的。因此,請嘗試以管理員身份登入並查看是否解決問題。如果問題仍然存在,可以嘗試以下解決方案:以管理員身分執行Wi
 Windows Update 更新提示Error 0x8024401c錯誤的解決方法
Jun 08, 2024 pm 12:18 PM
Windows Update 更新提示Error 0x8024401c錯誤的解決方法
Jun 08, 2024 pm 12:18 PM
目錄解決方法一解決方法二一、刪除Windows更新的臨時檔案二、修復受損的系統檔案三、檢視並修改登錄項目四、關閉網卡IPv6五、執行WindowsUpdateTroubleshootor工具進行修復六、關閉防火牆和其它相關的防毒軟體。七、關閉WidowsUpdate服務。解決方法三解決方法四華為電腦Windows更新出現「0x8024401c」報錯問題現象問題原因解決方案仍未解決?最近web伺服器因為系統漏洞需要更新,登入伺服器之後,更新提示錯誤碼0x8024401c解決方法一
 伺服器在建立新的虛擬機器時遇到錯誤,0x80070003
Feb 19, 2024 pm 02:30 PM
伺服器在建立新的虛擬機器時遇到錯誤,0x80070003
Feb 19, 2024 pm 02:30 PM
使用Hyper-V建立或啟動虛擬機器時,如果遇到錯誤代碼0x80070003,可能是因為權限問題、檔案損壞或設定錯誤造成的。解決方法包括檢查檔案權限、修復損壞檔案、確保正確配置等。可透過逐一排除不同可能性來解決此問題。整個錯誤訊息如下所示:伺服器在建立[虛擬機名]時遇到錯誤。無法建立新的虛擬機器。無法存取配置儲存:系統找不到指定的路徑。 (0x80070003)。導致此錯誤的一些可能原因包括:虛擬機器檔案已損壞。這可能是由於惡意軟體、病毒或廣告軟體攻擊而發生的。雖然發生這種情況的可能性很低,但你不能完
 解讀Oracle錯誤3114:原因及解決方法
Mar 08, 2024 pm 03:42 PM
解讀Oracle錯誤3114:原因及解決方法
Mar 08, 2024 pm 03:42 PM
標題:分析Oracle錯誤3114:原因及解決方法在使用Oracle資料庫時,常常會遇到各種錯誤代碼,其中錯誤3114是比較常見的一個。此錯誤一般涉及資料庫連結的問題,可能導致存取資料庫時出現異常狀況。本文將對Oracle錯誤3114進行解讀,探討其造成的原因,並給出解決該錯誤的具體方法以及相關的程式碼範例。 1.錯誤3114的定義Oracle錯誤3114通
 修復先鋒錯誤代碼Kadena-Keesler
Feb 19, 2024 pm 02:20 PM
修復先鋒錯誤代碼Kadena-Keesler
Feb 19, 2024 pm 02:20 PM
如果你在玩《決勝時刻:先鋒》時遇到了Kadena-Keesler錯誤,這篇文章可能會對你有所幫助。根據一些玩家的回饋,遊戲在WindowsPC、Xbox和PlayStation等平台上都存在這個問題。觸發後,您可能會收到以下錯誤訊息:連線失敗沒有網路連線失敗。您必須有活動的網路連線才能在線上或透過本地網路進行遊戲。 [原因:Kadena-Keesler]您也可能收到以下錯誤訊息:連線失敗無法存取線上服務。 [原因:Kadena-Keesler]此錯誤在Xbox上的另一個實例如下:您必須有活動的網路連接
 香香腐宅app為什麼顯示錯誤
Mar 19, 2024 am 08:04 AM
香香腐宅app為什麼顯示錯誤
Mar 19, 2024 am 08:04 AM
顯示錯誤是在香香腐宅app中可能會出現的問題,有些用戶還不太清楚香香腐宅app為什麼顯示錯誤,可能是網絡連接問題、後台程序過多、註冊信息錯誤等問題,接下來就是小編為使用者帶來的app顯示錯誤解決方法的介紹,有興趣的使用者快來一起看看吧!香香腐宅app為何顯示錯誤答案:網路連線問題、後台程式過多、註冊資訊錯誤等詳情介紹:1、【網路問題】解決方法:檢視裝置連線網路狀態,重新連線或選擇其他網路連線使用即可。 2.【後台程式過多】解決方法:關閉正在運作的其他程序,釋放系統,可以加快軟體的運作。 3、【註冊資訊錯
