

JAVA 之ThreadPoolExecutor執行緒池原理及其execute方法實例詳解

下面小編就為大家帶來一篇ThreadPoolExecutor線程池原理及其execute方法(詳解)。小編覺得蠻不錯的,現在就分享給大家,也給大家做個參考。一起跟著小編過來看看吧
jdk1.7.0_79
對於執行緒池大部分人可能會用,也知道為什麼要用。無非就是任務需要非同步執行,再者就是執行緒需要統一管理起來。對於從線程池中獲取線程,大部分人可能只知道,我現在需要一個線程來執行一個任務,那我就把任務丟到線程池裡,線程池裡有空閒的線程就執行,沒有空閒的線程就等待。實際上對於線程池的執行原理遠不止這麼簡單。
在Java並發套件中提供了線程池類別——ThreadPoolExecutor,實際上更多的我們可能用到的是Executors工廠類別為我們提供的線程池:newFixedThreadPool、newSingleThreadPool、newCachedThreadPool,這三個執行緒池並不是ThreadPoolExecutor的子類,關於這幾者之間的關係,我們先來查看ThreadPoolExecutor,查看原始碼發現其一共有4個建構方法。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
首先就從這幾個參數開始來了解線程池ThreadPoolExecutor的執行原理。
corePoolSize:核心執行緒池的執行緒數量
maximumPoolSize:最大的執行緒池執行緒數量
keepAliveTime:執行緒活動維持時間,執行緒池的工作執行緒空閒後,保持存活的時間。
unit:執行緒活動保持時間的單位。
workQueue:指定任務佇列所使用的阻塞佇列
corePoolSize和maximumPoolSize都在指定執行緒池中的執行緒數量,好像平常用到執行緒池的時候最多就只需要傳遞一個執行緒池大小的參數就能創建一個執行緒池啊,Java為我們提供了一些常用的執行緒池類別就是上面提到的newFixedThreadPool 、newSingleThreadExecutor、newCachedThreadPool,當然如果我們想要自己發揮創建自訂的線程池就得自己來「配置」有關線程池的一些參數。
當把一個任務交給執行緒池來處理的時候,執行緒池的執行原理如下圖所示參考自《Java並發程式設計的藝術》
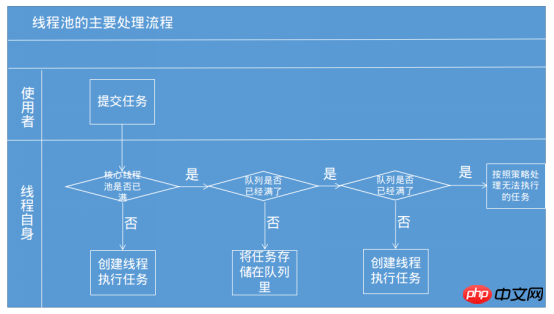
①首先會判斷核心執行緒池裡是否有執行緒可執行,有空閒執行緒則建立一個執行緒來執行任務。
②當核心執行緒池裡已經沒有執行緒可執行的時候,此時將任務丟到任務佇列中去。
③如果任務佇列(有界)也已經滿了的話,但運行的執行緒數小於最大執行緒池的數量的時候,此時將會新建一個執行緒用於執行任務,但如果執行的執行緒數已經達到最大執行緒池的數量的時候,此時將無法建立執行緒執行任務。
所以其實對於執行緒池不僅是單純地將任務丟到執行緒池,執行緒池中有執行緒就執行任務,沒執行緒就等待。
為鞏固一下執行緒池的原理,現在再來了解上面提到的常用的3個執行緒池:
Executors.newFixedThreadPool:建立一個固定數量執行緒的執行緒池。
// Executors#newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}可以看到newFixedThreadPool中呼叫的是ThreadPoolExecutor類,傳遞的參數corePoolSize= maximumPoolSize=nThread。回顧線程池的執行原理,當一個任務提交到線程池中,首先判斷核心線程池裡有沒有空閒線程,有則創建線程,沒有則將任務放到任務隊列(這裡是有界阻塞隊列LinkedBlockingQueue)中,如果任務佇列已經滿了的話,對於newFixedThreadPool來說,它的最大執行緒池數量=核心執行緒池數量,此時任務佇列也滿了,將無法擴充建立新的執行緒來執行任務。
Executors.newSingleThreadExecutor:建立只包含一個執行緒的執行緒池。
//Executors# newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegateExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}只有一个线程的线程池好像有点奇怪,并且并没有直接将返回ThreadPoolExecutor,甚至也没有直接将线程池数量1传递给newFixedThreadPool返回。那就说明这个只含有一个线程的线程池,或许并没有只包含一个线程那么简单。在其源码注释中这么写到:创建只有一个工作线程的线程池用于操作一个无界队列(如果由于前驱节点的执行被终止结束了,一个新的线程将会继续执行后继节点线程)任务得以继续执行,不同于newFixedThreadPool(1)不会有额外的线程来重新继续执行后继节点。也就是说newSingleThreadExecutor自始至终都只有一个线程在执行,这和newFixedThreadPool一样,但如果线程终止结束过后newSingleThreadExecutor则会重新创建一个新的线程来继续执行任务队列中的线程,而newFixedThreaPool则不会。
Executors.newCachedThreadPool:根据需要创建新线程的线程池。
//Executors#newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPooExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}可以看到newCachedThread返回的是ThreadPoolExecutor,其参数核心线程池corePoolSize = 0, maximumPoolSize = Integer.MAX_VALUE,这也就是说当任务被提交到newCachedThread线程池时,将会直接把任务放到SynchronousQueue任务队列中,maximumPool从任务队列中获取任务。注意SynchronousQueue是一个没有容量的队列,也就是说每个入队操作必须等待另一个线程的对应出队操作,如果主线程提交任务的速度高于maximumPool中线程处理任务的速度时,newCachedThreadPool会不断创建线程,线程多并不是一件好事,严重会耗尽CPU和内存资源。
题外话:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,这三者都直接或间接调用了ThreadPoolExecutor,为什么它们三者没有直接是其子类,而是通过Executors来实例化呢?这是所采用的静态工厂方法,在java.util.Connections接口中同样也是采用的静态工厂方法来创建相关的类。这样有很多好处,静态工厂方法是用来产生对象的,产生什么对象没关系,只要返回原返回类型或原返回类型的子类型都可以,降低API数目和使用难度,在《Effective Java》中的第1条就是静态工厂方法。
回到ThreadPoolExecutor,首先来看它的继承关系:
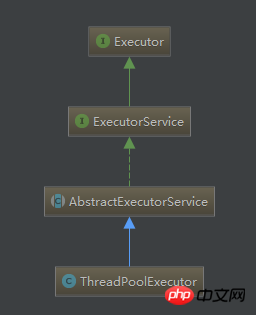
ThreadPoolExecutor它的顶级父类是Executor接口,只包含了一个方法——execute,这个方法也就是线程池的“执行”。
//Executor#execute
public interface Executor {
void execute(Runnable command);
}Executor#execute的实现则是在ThreadPoolExecutor中实现的:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
…
}一来就碰到个不知所云的ctl变量它的定义:
private final AtomicInteger ctl = new AtlmicInteger(ctlOf(RUNNING, 0));
这个变量使用来干嘛的呢?它的作用有点类似我们在《ReadWriteLock接口及其实现ReentrantReadWriteLock》中提到的读写锁有读、写两个同步状态,而AQS则只提供了state一个int型变量,此时将state高16位表示为读状态,低16位表示为写状态。这里的clt同样也是,它表示了两个概念:
workerCount:当前有效的线程数
runState:当前线程池的五种状态,Running、Shutdown、Stop、Tidying、Terminate。
int型变量一共有32位,线程池的五种状态runState至少需要3位来表示,故workCount只能有29位,所以代码中规定线程池的有效线程数最多为229-1。
//ThreadPoolExecutor private static final int COUNT_BITS = Integer.SIZE – 3; //32-3=29,线程数量所占位数 private static final int CAPACITY = (1 << COUNT_BITS) – 1; //低29位表示最大线程数,229-1 //五种线程池状态 private static final int RUNNING = -1 << COUNT_BITS; /int型变量高3位(含符号位)101表RUNING private static final int SHUTDOWN = 0 << COUNT_BITS; //高3位000 private static final int STOP = 1 << COUNT_BITS; //高3位001 private static final int TIDYING = 2 << COUNT_BITS; //高3位010 private static final int TERMINATED = 3 << COUNT_BITS; //高3位011
再次回到ThreadPoolExecutor#execute方法:
//ThreadPoolExecutor#execute
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); //由它可以获取到当前有效的线程数和线程池的状态
/*1.获取当前正在运行线程数是否小于核心线程池,是则新创建一个线程执行任务,否则将任务放到任务队列中*/
if (workerCountOf(c) < corePoolSize){
if (addWorker(command, tre)) //在addWorker中创建工作线程执行任务
return ;
c = ctl.get();
}
/*2.当前核心线程池中全部线程都在运行workerCountOf(c) >= corePoolSize,所以此时将线程放到任务队列中*/
if (isRunning(c) && workQueue.offer(command)) { //线程池是否处于运行状态,且是否任务插入任务队列成功
int recheck = ctl.get();
if (!isRunning(recheck) && remove(command)) //线程池是否处于运行状态,如果不是则使刚刚的任务出队
reject(command); //抛出RejectedExceptionException异常
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*3.插入队列不成功,且当前线程数数量小于最大线程池数量,此时则创建新线程执行任务,创建失败抛出异常*/
else if (!addWorker(command, false)){
reject(command); //抛出RejectedExceptionException异常
}
}上面代码注释第7行的即判断当前核心线程池里是否有空闲线程,有则通过addWorker方法创建工作线程执行任务。addWorker方法较长,筛选出重要的代码来解析。
//ThreadPoolExecutor#addWorker
private boolean addWorker(Runnable firstTask, boolean core) {
/*首先会再次检查线程池是否处于运行状态,核心线程池中是否还有空闲线程,都满足条件过后则会调用compareAndIncrementWorkerCount先将正在运行的线程数+1,数量自增成功则跳出循环,自增失败则继续从头继续循环*/
...
if (compareAndIncrementWorkerCount(c))
break retry;
...
/*正在运行的线程数自增成功后则将线程封装成工作线程Worker*/
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock; //全局锁
w = new Woker(firstTask); //将线程封装为Worker工作线程
final Thread t = w.thread;
if (t != null) {
mainLock.lock(); //获取全局锁
/*当持有了全局锁的时候,还需要再次检查线程池的运行状态等*/
try {
int c = clt.get();
int rs = runStateOf(c); //线程池运行状态
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)){ //线程池处于运行状态,或者线程池关闭且任务线程为空
if (t.isAlive()) //线程处于活跃状态,即线程已经开始执行或者还未死亡,正确的应线程在这里应该是还未开始执行的
throw new IllegalThreadStateException();
workers.add(w); //private final HashSet<Worker> wokers = new HashSet<Worker>();包含线程池中所有的工作线程,只有在获取了全局的时候才能访问它。将新构造的工作线程加入到工作线程集合中
int s = worker.size(); //工作线程数量
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //新构造的工作线程加入成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); //在被构造为Worker工作线程,且被加入到工作线程集合中后,执行线程任务,注意这里的start实际上执行Worker中run方法,所以接下来分析Worker的run方法
workerStarted = true;
}
}
} finally {
if (!workerStarted) //未能成功创建执行工作线程
addWorkerFailed(w); //在启动工作线程失败后,将工作线程从集合中移除
}
return workerStarted;
}在上面第35代码中,工作线程被成功添加到工作线程集合中后,则开始start执行,这里start执行的是Worker工作线程中的run方法。
//ThreadPoolExecutor$Worker,它继承了AQS,同时实现了Runnable,所以它具备了这两者的所有特性
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
public Worker(Runnable firstTask) {
setState(-1); //设置AQS的同步状态为-1,禁止中断,直到调用runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //通过线程工厂来创建一个线程,将自身作为Runnable传递传递
}
public void run() {
runWorker(this); //运行工作线程
}
}ThreadPoolExecutor#runWorker,在此方法中,Worker在执行完任务后,还会循环获取任务队列里的任务执行(其中的getTask方法),也就是说Worker不仅仅是在执行完给它的任务就释放或者结束,它不会闲着,而是继续从任务队列中获取任务,直到任务队列中没有任务可执行时,它才退出循环完成任务。理解了以上的源码过后,往后线程池执行原理的第二步、第三步的理解实则水到渠成。
以上是JAVA 之ThreadPoolExecutor執行緒池原理及其execute方法實例詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一種強大且表達力豐富的處理數據集合的方式。然而,使用Stream時,一個常見問題是:如何從forEach操作中中斷或返回? 傳統循環允許提前中斷或返回,但Stream的forEach方法並不直接支持這種方式。本文將解釋原因,並探討在Stream處理系統中實現提前終止的替代方法。 延伸閱讀: Java Stream API改進 理解Stream forEach forEach方法是一個終端操作,它對Stream中的每個元素執行一個操作。它的設計意圖是處
 PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP是一種廣泛應用於服務器端的腳本語言,特別適合web開發。 1.PHP可以嵌入HTML,處理HTTP請求和響應,支持多種數據庫。 2.PHP用於生成動態網頁內容,處理表單數據,訪問數據庫等,具有強大的社區支持和開源資源。 3.PHP是解釋型語言,執行過程包括詞法分析、語法分析、編譯和執行。 4.PHP可以與MySQL結合用於用戶註冊系統等高級應用。 5.調試PHP時,可使用error_reporting()和var_dump()等函數。 6.優化PHP代碼可通過緩存機制、優化數據庫查詢和使用內置函數。 7
 PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP和Python各有優勢,選擇應基於項目需求。 1.PHP適合web開發,語法簡單,執行效率高。 2.Python適用於數據科學和機器學習,語法簡潔,庫豐富。
 PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP適合web開發,特別是在快速開發和處理動態內容方面表現出色,但不擅長數據科學和企業級應用。與Python相比,PHP在web開發中更具優勢,但在數據科學領域不如Python;與Java相比,PHP在企業級應用中表現較差,但在web開發中更靈活;與JavaScript相比,PHP在後端開發中更簡潔,但在前端開發中不如JavaScript。
 Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
膠囊是一種三維幾何圖形,由一個圓柱體和兩端各一個半球體組成。膠囊的體積可以通過將圓柱體的體積和兩端半球體的體積相加來計算。本教程將討論如何使用不同的方法在Java中計算給定膠囊的體積。 膠囊體積公式 膠囊體積的公式如下: 膠囊體積 = 圓柱體體積 兩個半球體體積 其中, r: 半球體的半徑。 h: 圓柱體的高度(不包括半球體)。 例子 1 輸入 半徑 = 5 單位 高度 = 10 單位 輸出 體積 = 1570.8 立方單位 解釋 使用公式計算體積: 體積 = π × r2 × h (4
 PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP和Python各有優勢,適合不同場景。 1.PHP適用於web開發,提供內置web服務器和豐富函數庫。 2.Python適合數據科學和機器學習,語法簡潔且有強大標準庫。選擇時應根據項目需求決定。
 創造未來:零基礎的 Java 編程
Oct 13, 2024 pm 01:32 PM
創造未來:零基礎的 Java 編程
Oct 13, 2024 pm 01:32 PM
Java是熱門程式語言,適合初學者和經驗豐富的開發者學習。本教學從基礎概念出發,逐步深入解說進階主題。安裝Java開發工具包後,可透過建立簡單的「Hello,World!」程式來實踐程式設計。理解程式碼後,使用命令提示字元編譯並執行程序,控制台上將輸出「Hello,World!」。學習Java開啟了程式設計之旅,隨著掌握程度加深,可創建更複雜的應用程式。
 PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP成為許多網站首選技術棧的原因包括其易用性、強大社區支持和廣泛應用。 1)易於學習和使用,適合初學者。 2)擁有龐大的開發者社區,資源豐富。 3)廣泛應用於WordPress、Drupal等平台。 4)與Web服務器緊密集成,簡化開發部署。
