
#設定python 2.7
bs4
requests安裝用pip進行安裝sudo pip install bs4
sudo pip install requests
簡要說明一下bs4的使用因為是爬取網頁所以就介紹find 跟find_all
find跟find_all的不同在於返回的東西不同find返回的是符合到的第一個標籤及標籤裡的內容
find_all回傳的是一個列表
例如我們寫一個test.html 用來測試find跟find_all的差別。內容為:
<html> <head> </head> <body> <div id="one"><a></a></div> <div id="two"><a href="#">abc</a></div> <div id="three"><a href="#">three a</a><a href="#">three a</a><a href="#">three a</a></div> <div id="four"><a href="#">four<p>four p</p><p>four p</p><p>four p</p> a</a></div> </body> </html>
<br/>
然後test.py的程式碼為:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"
#
<br/>
運行以後我們可以看到結果當取得指定標籤時候兩者差異不大當取得一組標籤的時候兩者的差異就會顯示出來

所以我們在使用時候要注意到底要的是什麼,否則會出現報錯
接下來就是透過requests 取得網頁資訊了,我不太懂別人為什麼要寫heard跟其他的東西
我直接進行網頁訪問,通過get方式獲取散文網幾個分類的二級網頁然後通過一個組的測試,把所有的網頁爬取一遍
def get_html():
url = ""
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel'] for doc in two_html:
i=1 if doc=='sanwen':print "running sanwen -----------------------------" if doc=='shige':print "running shige ------------------------------" if doc=='zawen':print 'running zawen -------------------------------' if doc=='suibi':print 'running suibi -------------------------------' if doc=='rizhi':print 'running ruzhi -------------------------------' if doc=='nove':print 'running xiaoxiaoshuo -------------------------' while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)if res.status_code==200:
soup(res.text)
i+=i
<br/>
這部分的程式碼中我沒有對res.status_code不是200的進行處理,導致的問題是會不顯示錯誤,爬取的內容會有遺失。然後分析散文網的網頁,發現是www.sanwen.net/rizhi/&p=1
p最大值是10這個不太懂,上次爬盤多多是100頁,算了算了以後再分析。然後就透過get方法取得每頁的內容。 <br/>取得每頁內容以後就是分析作者跟題目了代碼是這樣的
def soup(html_text):
s = BeautifulSoup(html_text,'lxml')
link = s.find('div',class_='categorylist').find_all('li') for i in link:if i!=s.find('li',class_='page'):
title = i.find_all('a')[1]
author = i.find_all('a')[2].text
url = title.attrs['href']
sign = re.compile(r'(//)|/')
match = sign.search(title.text)
file_name = title.text if match:
file_name = sign.sub('a',str(title.text))
<br/>
取得標題的時候出現坑爹的事,請問大佬們寫散文你標題加斜杠幹嘛,不光加一個還有加兩個的,這個問題直接導致我後面寫入文件的時候文件名出現錯誤,於是寫正則表達式,我給你改行了吧。 <br/>最後就是取得散文內容了,透過每頁的分析,取得文章地址,然後直接取得內容,本來還想直接透過改網頁地址一個一個的取得呢,這樣也省事了。
def get_content(url):
res = requests.get(''+url) if res.status_code==200:
soup = BeautifulSoup(res.text,'lxml')
contents = soup.find('div',class_='content').find_all('p')
content = ''for i in contents:
content+=i.text+'\n'return content
<br/>
最後就是寫入檔案保存ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
三個函數取得散文網的散文,不過有問題,問題在於不知道為什麼有些散文丟失了我只能獲取到大概400多篇文章,這跟散文網的文章是差很多很多的,但是確實是一頁一頁的獲取來的,這個問題希望大佬幫忙看看。可能應該要做網頁無法存取的處理,當然我覺得跟我宿舍這個破網有關係
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
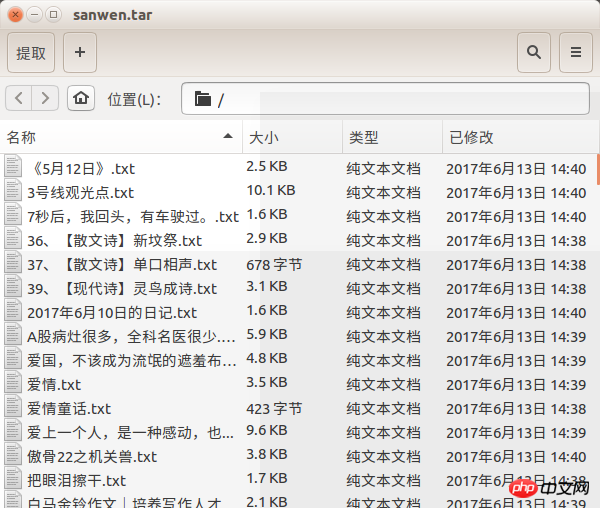
差點忘了效果圖

以上是python是如何爬取散文網的文章的?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















