

php並發之關於查詢MySQL的範例(圖)

這篇文章主要介紹了PHP並發查詢MySQL的實例程式碼,小編覺得蠻不錯的,現在分享給大家,也給大家做個參考。一起跟著小編過來看看吧
最近在研究PHP,很喜歡,碰到PHP並發查詢MySQL的問題,研究了一下,順便留個筆記:
同步查詢
這是我們最常的呼叫模式,客戶端呼叫Query[函數],發起查詢命令,等待結果返回,讀取結果;再發送第二個查詢命令,等待結果返回,讀取結果。總耗時,會是兩次查詢的時間總和。簡化一下過程,例如下圖:
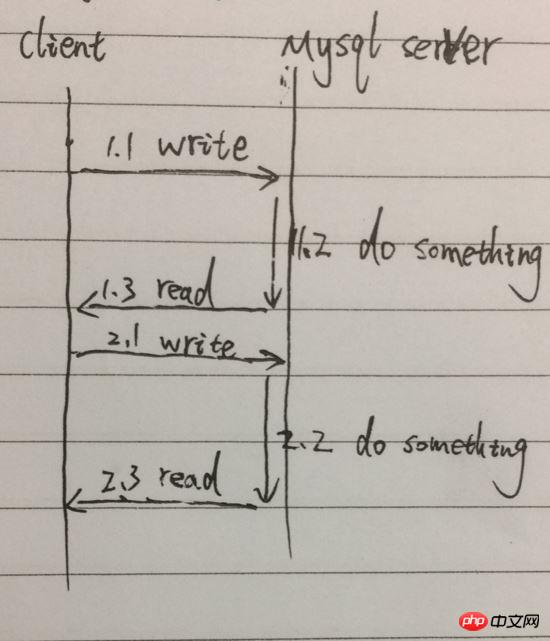
例圖,由1.1到1.3為一個Query[函數]的調用,兩次查詢,就要串行經歷1.1、1.2、1.3、2.1、2.2、2.3,尤其在1.2和2.2會阻塞等待,進程沒辦法做其他事。
同步調用的好處是,符合我們的直覺思維,調用和處理都簡單。缺點是進程阻塞在等待結果返回,增加額外的運行時間。
如果,有多條查詢請求,或者進程還有其他的事情處理,那麼能否把等待的時間也合理利用起來,提高進程的處理能力呢,顯然是可以的。
拆分
現在,我們把Query[函數]打碎,客戶端在1.1後,馬上返回,客戶端跳過1.2,在1.3有資料達到後再去讀取資料。這樣進程在原來的1.2階段就解放了,可以做更多的事情,例如…再發起一條sql查詢[2.1],是否看到了並發查詢的雛形了。
並發查詢
相對於同步查詢的下一條查詢的發起都在上一條完成後,並發查詢,可以在上一條查詢請求發起後,立刻發起下一條查詢請求。簡化一下過程,下圖:
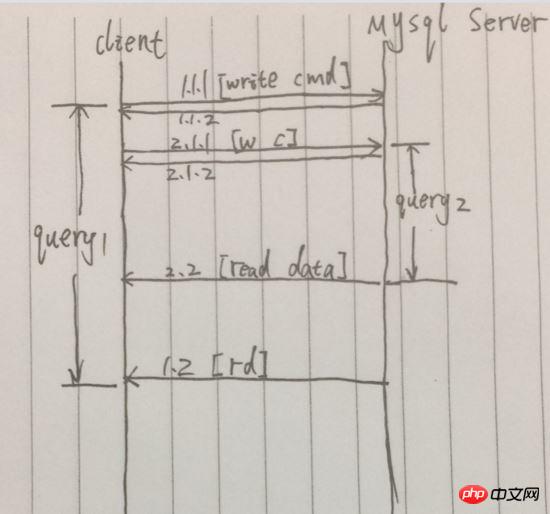
例圖,在1.1.1成功發送完請求後,立刻返回[1.1.2],最終查詢結果的返回時在遙遠的1.2 。但在,1.1.1到1.2中間,還發起了另一個查詢請求,這時間段內,就同時發起了兩條查詢請求,2.2先於1.2到達,那麼兩條查詢的總耗時,只相當於第一條查詢的時間。
並發查詢的優點是,可以提高進程的使用率,避免阻塞等待伺服器處理查詢,縮短了多個查詢的耗時。但缺點也很明顯,發起N條並發查詢,就需要建立N條資料庫鏈接,對於有資料庫連接池的應用程式來說,可以避免這種情況。
退化
理想情況下,我們希望並發N條查詢,總耗時等於查詢時間最長的一條查詢。但也有可能並發查詢會[退化]為[同步查詢]。 What?例圖中,如果1.2在2.1.1前就回傳了,那麼並發查詢就[退化]為[同步查詢]了,但付出的代價卻比同步查詢要高。
多路復用
發起query1
發起query2
-
query3
發起query2 - 2、query3
- 讀query2結果
- 讀取query1結果
- 讀取query3結果
- 那麼,怎麼等待知道什麼時候查詢結果回傳了,又是哪個的查詢結果回傳呢? 對每個查詢IO調用read?如果是遇上阻塞IO,這樣就會阻塞在一個IO上,其他IO有結果回來了,也沒辦法處理。那麼,如果是非阻塞IO,那不用怕會阻塞在其中一個IO上了,確實是,但又會造成不斷地輪詢判斷,浪費CPU資源。
對於這種情況可以使用多路復用輪詢多個IO。
PHP實作並發查詢MySQL
<?php
$sqls = array(
'SELECT * FROM `mz_table_1` LIMIT 1000,10',
'SELECT * FROM `mz_table_1` LIMIT 1010,10',
'SELECT * FROM `mz_table_1` LIMIT 1020,10',
'SELECT * FROM `mz_table_1` LIMIT 10000,10',
'SELECT * FROM `mz_table_2` LIMIT 1',
'SELECT * FROM `mz_table_2` LIMIT 5,1'
);
$links = [];
$tvs = microtime();
$tv = explode(' ', $tvs);
$start = $tv[1] * 1000 + (int)($tv[0] * 1000);
// 链接数据库,并发起异步查询
foreach ($sqls as $sql) {
$link = mysqli_connect('127.0.0.1', 'root', 'root', 'dbname', '3306');
$link->query($sql, MYSQLI_ASYNC); // 发起异步查询,立即返回
$links[$link->thread_id] = $link;
}
$llen = count($links);
$process = 0;
do {
$r_array = $e_array = $reject = $links;
// 多路复用轮询IO
if(!($ret = mysqli_poll($r_array, $e_array, $reject, 2))) {
continue;
}
// 读取有结果返回的查询,处理结果
foreach ($r_array as $link) {
if ($result = $link->reap_async_query()) {
print_r($result->fetch_row());
if (is_object($result))
mysqli_free_result($result);
} else {
}
// 操作完后,把当前数据链接从待轮询集合中删除
unset($links[$link->thread_id]);
$link->close();
$process++;
}
foreach ($e_array as $link) {
die;
}
foreach ($reject as $link) {
die;
}
}while($process < $llen);
$tvs = microtime();
$tv = explode(' ', $tvs);
$end = $tv[1] * 1000 + (int)($tv[0] * 1000);
echo $end - $start,PHP_EOL;#ifndef PHP_WIN32
#define php_select(m, r, w, e, t) select(m, r, w, e, t)
#else
#include "win32/select.h"
#endif
/* {{{ mysqlnd_poll */
PHPAPI enum_func_status
mysqlnd_poll(MYSQLND **r_array, MYSQLND **e_array, MYSQLND ***dont_poll, long sec, long usec, int * desc_num)
{
struct timeval tv;
struct timeval *tv_p = NULL;
fd_set rfds, wfds, efds;
php_socket_t max_fd = 0;
int retval, sets = 0;
int set_count, max_set_count = 0;
DBG_ENTER("_mysqlnd_poll");
if (sec < 0 || usec < 0) {
php_error_docref(NULL, E_WARNING, "Negative values passed for sec and/or usec");
DBG_RETURN(FAIL);
}
FD_ZERO(&rfds);
FD_ZERO(&wfds);
FD_ZERO(&efds);
// 从所有mysqli链接中获取socket链接描述符
if (r_array != NULL) {
*dont_poll = mysqlnd_stream_array_check_for_readiness(r_array);
set_count = mysqlnd_stream_array_to_fd_set(r_array, &rfds, &max_fd);
if (set_count > max_set_count) {
max_set_count = set_count;
}
sets += set_count;
}
// 从所有mysqli链接中获取socket链接描述符
if (e_array != NULL) {
set_count = mysqlnd_stream_array_to_fd_set(e_array, &efds, &max_fd);
if (set_count > max_set_count) {
max_set_count = set_count;
}
sets += set_count;
}
if (!sets) {
php_error_docref(NULL, E_WARNING, *dont_poll ? "All arrays passed are clear":"No stream arrays were passed");
DBG_ERR_FMT(*dont_poll ? "All arrays passed are clear":"No stream arrays were passed");
DBG_RETURN(FAIL);
}
PHP_SAFE_MAX_FD(max_fd, max_set_count);
// select轮询阻塞时间
if (usec > 999999) {
tv.tv_sec = sec + (usec / 1000000);
tv.tv_usec = usec % 1000000;
} else {
tv.tv_sec = sec;
tv.tv_usec = usec;
}
tv_p = &tv;
// 轮询,等待多个IO可读,php_select是select的宏定义
retval = php_select(max_fd + 1, &rfds, &wfds, &efds, tv_p);
if (retval == -1) {
php_error_docref(NULL, E_WARNING, "unable to select [%d]: %s (max_fd=%d)",
errno, strerror(errno), max_fd);
DBG_RETURN(FAIL);
}
if (r_array != NULL) {
mysqlnd_stream_array_from_fd_set(r_array, &rfds);
}
if (e_array != NULL) {
mysqlnd_stream_array_from_fd_set(e_array, &efds);
}
// 返回可操作的IO数量
*desc_num = retval;
DBG_RETURN(PASS);
}並發查詢操作結果
為了更直觀地看效果,我找了一個1.3億數據量並且沒有優化過的表進行操作。並發查詢的結果:
同步查詢的結果:

從結果來看,同步查詢的總耗時是所有查詢的時間的累加查詢;這裡其實是查詢時間最長的那一條(同步查詢的第四條,耗時是10幾秒,符合並發查詢的總耗時),而且並發查詢的查詢順序和結果到達的順序是不一樣的。
多條耗時較短的查詢比較
使用多條查詢時間較短的sql進行比較一下
並發查詢的測試1結果(資料庫連結時間也統計進去):
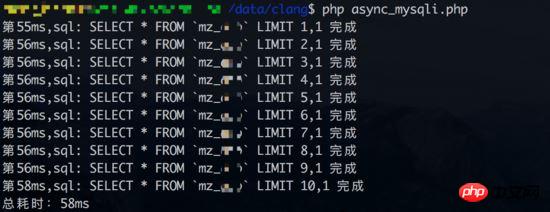 查詢的結果(資料庫連結時間也統計進去):
查詢的結果(資料庫連結時間也統計進去):
 並發查詢的測試2結果(不統計資料庫連結時間):
並發查詢的測試2結果(不統計資料庫連結時間):
 從結果上看,並發查詢測試1並沒有討到好處。從同步查詢來看,每個查詢耗時大概3-4ms左右。但如果不把資料庫連結時間統計進去(同步查詢只有一次資料庫連結),並發查詢的優勢又能體現出來了。
從結果上看,並發查詢測試1並沒有討到好處。從同步查詢來看,每個查詢耗時大概3-4ms左右。但如果不把資料庫連結時間統計進去(同步查詢只有一次資料庫連結),並發查詢的優勢又能體現出來了。
這裡探討了一下PHP實現並發查詢MySQL,從實驗上結果直觀地認識了並發查詢的優缺點。建立資料庫連線的時間在一條優化了的sql查詢上,佔比重還是很大。 #沒有連接池,要你何用
以上是php並發之關於查詢MySQL的範例(圖)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:比較兩種流行的編程語言
Apr 14, 2025 am 12:13 AM
PHP和Python:比較兩種流行的編程語言
Apr 14, 2025 am 12:13 AM
PHP和Python各有優勢,選擇依據項目需求。 1.PHP適合web開發,尤其快速開發和維護網站。 2.Python適用於數據科學、機器學習和人工智能,語法簡潔,適合初學者。
 PHP行動:現實世界中的示例和應用程序
Apr 14, 2025 am 12:19 AM
PHP行動:現實世界中的示例和應用程序
Apr 14, 2025 am 12:19 AM
PHP在電子商務、內容管理系統和API開發中廣泛應用。 1)電子商務:用於購物車功能和支付處理。 2)內容管理系統:用於動態內容生成和用戶管理。 3)API開發:用於RESTfulAPI開發和API安全性。通過性能優化和最佳實踐,PHP應用的效率和可維護性得以提升。
 PHP的目的:構建動態網站
Apr 15, 2025 am 12:18 AM
PHP的目的:構建動態網站
Apr 15, 2025 am 12:18 AM
PHP用於構建動態網站,其核心功能包括:1.生成動態內容,通過與數據庫對接實時生成網頁;2.處理用戶交互和表單提交,驗證輸入並響應操作;3.管理會話和用戶認證,提供個性化體驗;4.優化性能和遵循最佳實踐,提升網站效率和安全性。
 PHP的持久相關性:它還活著嗎?
Apr 14, 2025 am 12:12 AM
PHP的持久相關性:它還活著嗎?
Apr 14, 2025 am 12:12 AM
PHP仍然具有活力,其在現代編程領域中依然佔據重要地位。 1)PHP的簡單易學和強大社區支持使其在Web開發中廣泛應用;2)其靈活性和穩定性使其在處理Web表單、數據庫操作和文件處理等方面表現出色;3)PHP不斷進化和優化,適用於初學者和經驗豐富的開發者。
 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 為什麼要使用PHP?解釋的優點和好處
Apr 16, 2025 am 12:16 AM
為什麼要使用PHP?解釋的優點和好處
Apr 16, 2025 am 12:16 AM
PHP的核心優勢包括易於學習、強大的web開發支持、豐富的庫和框架、高性能和可擴展性、跨平台兼容性以及成本效益高。 1)易於學習和使用,適合初學者;2)與web服務器集成好,支持多種數據庫;3)擁有如Laravel等強大框架;4)通過優化可實現高性能;5)支持多種操作系統;6)開源,降低開發成本。
 PHP:處理數據庫和服務器端邏輯
Apr 15, 2025 am 12:15 AM
PHP:處理數據庫和服務器端邏輯
Apr 15, 2025 am 12:15 AM
PHP在數據庫操作和服務器端邏輯處理中使用MySQLi和PDO擴展進行數據庫交互,並通過會話管理等功能處理服務器端邏輯。 1)使用MySQLi或PDO連接數據庫,執行SQL查詢。 2)通過會話管理等功能處理HTTP請求和用戶狀態。 3)使用事務確保數據庫操作的原子性。 4)防止SQL注入,使用異常處理和關閉連接來調試。 5)通過索引和緩存優化性能,編寫可讀性高的代碼並進行錯誤處理。
