在我們日常上網瀏覽網頁的時候,常常會看到一些好看的圖片,我們就希望把這些圖片保存下載,或者用戶用來做桌面壁紙,或者用來做設計的素材。以下這篇文章就來跟大家介紹了關於利用python實現最簡單的網頁爬蟲的相關資料,需要的朋友可以參考借鑒,下面來一起看看吧。
前言
網路爬蟲(又稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更常的稱為網頁追逐者),是一種依照一定的規則,自動抓取萬維網資訊的程式或腳本。最近對python爬蟲有了強烈興趣,在此分享自己的學習路徑,歡迎大家提出建議。我們相互交流,共同進步。話不多說了,來一起看看詳細的介紹:
1.開發工具
2.爬蟲介紹
3.urllib發展最簡單的爬蟲
(1)urllib簡介
| Introduce | |
|---|---|
| Exception classes raised by urllib.request. | |
| Parse URLs into or assemble them from components. | |
| Extensible library for opening URLs. | |
| Response classes used by urllib. | |
| Load a robots.txt file and answer questions about fetchability of other URLs. |
(2 )開發最簡單的爬蟲
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()
#我們可以透過在百度首頁空白處右鍵,查看審查元素來和我們的運行結果比較。
當然,request也可以產生一個request對象,這個物件可以用urlopen方法開啟。
from urllib import request def vists_baidu(): # create a request obkect req = request.Request('http://www.baidu.com') # open the request object response = request.urlopen(req) # read the response html = response.read() html = html.decode('utf-8') print(html) if __name__ == '__main__': vists_baidu()
(3)錯誤處理
錯誤處理透過urllib模組來處理,主要有URLError和HTTPError錯誤,其中HTTPError錯誤是URLError錯誤的子類,即HTTRPError也可以透過URLError捕獲。
HTTPError可以透過其code屬性來捕獲。
處理HTTPError的程式碼如下:
#
from urllib import request
from urllib import error
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
if __name__ == '__main__':
Err()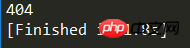

from urllib import request
from urllib import error
def Err():
url = "https://segmentf.com/"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.URLError as e:
print(e.reason)
if __name__ == '__main__':
Err()from urllib import request
from urllib import error
# 第一种方法,URLErroe和HTTPError
def Err():
url = "https://segmentfault.com/zzz"
req = request.Request(url)
try:
response = request.urlopen(req)
html = response.read().decode("utf-8")
print(html)
except error.HTTPError as e:
print(e.code)
except error.URLError as e:
print(e.reason)以上是python之網頁爬蟲教程的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















