

Python中關於字元編碼與函數的使用詳解

下面小編就為大家帶來一篇Python字元編碼與函數的基本使用方法。小編覺得蠻不錯的,現在就分享給大家,也給大家做個參考。一起跟著小編過來看看吧
一、Python2中的字元存在的解碼編碼問題
如果是現在正在用Python2的人應該都知道有字元編碼問題,就舉一個最簡單的例子吧:Python2是無法在命令列直接列印中文的,當然他也是不會報錯的,頂多是一堆你看不懂的亂碼。如果想要在直接顯示中文,我們是可以在Python2檔案頭部申明字元編碼的格式。如下圖
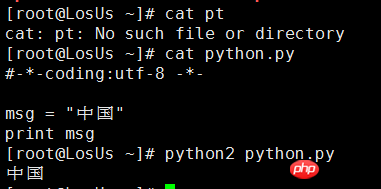
這裡#-*-coding:utf-8 -*- 是用來申明下面的程式碼是用什麼編碼來解釋;
1.1.Python2中的解碼與編碼:
在編碼和解碼的世界中,我們得需要找一個大家都知道的文字。也可以這麼理解。我是一個中國人現在和一個日本人溝通,我肯定是無法理解他說的是什麼,他同樣也無法理解,但是這樣就沒有辦法了嗎?或許我們需要一個國際的語言──英語。這樣來自不同國家的人也可以溝通了(雖然我知道 are you ok 0-0)。在編碼中也是一樣,gbk和utf-8都不知道對方的格式是什麼吊意思。所以如果要上gbk讀懂utf-8的編碼就得將utf-8 decode成Unicode,而Unicode有知道gkb,這裡需要將Unicode在encode成gbk就行了
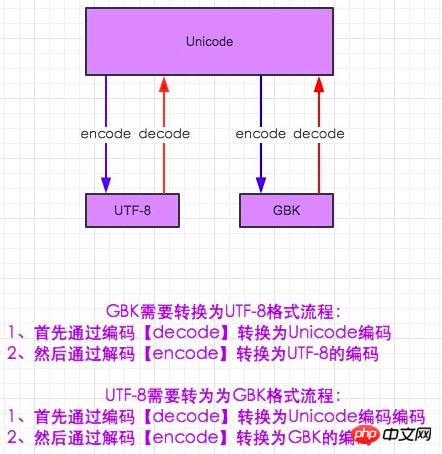
#-*- coding:utf-8 -*- msg = "中国" print msg #解码在编码的过程,encoding是申明用申明这段代码是什么编码 gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk') print gbk_str #其实两种输出的结果是一样的
在Python2中預設是使用gbk來解釋IDE中的程式碼的,所以無法直接在Python命令列中直接輸入中文,所以我們才會使用#-*-coding :utf-8 -*-來申明頭部,我們到底需要用什麼語言來解釋下面程式碼。細心的人一定是發現了一個問題,申明頭部只是用utf-8來解釋下面的話,照理說命令列中雖然不報錯,但是應該也是亂碼才是,這裡為啥會直接輸出中文呢畢竟DOS命令行中預設支援的是gbk格式的字元代碼呀?這裡就牽涉到另外的一個概念了。 Python到記憶體解釋器裡面,預設是用的Unicode,檔案載入到記憶體後自動解碼成Unicode,而Unicode是外國碼,自然也就可以翻譯來自utf-8的編碼,也可以翻譯成gbk的編碼了。顧可以顯示中文了。
PS:這裡我們得出一個結論:python2 中解碼動作是必須的,但是編碼可以不用,因為記憶體就是Unicode
##1.2、Python3中字編碼的問題:
額,這還有什麼好說的呢? Python3預設就是使用utf-8解釋程式碼的。也就是行首自備 #-*-coding:utf-8 -*-(GBM),所以也就不存在解碼的問題。但我在這裡提上一嘴(其實就是怕自己以後也忘了,嘿嘿),如果我們將utf-8的字符編碼的格式給編碼成gbk。這裡會輸出bytes格式的東西。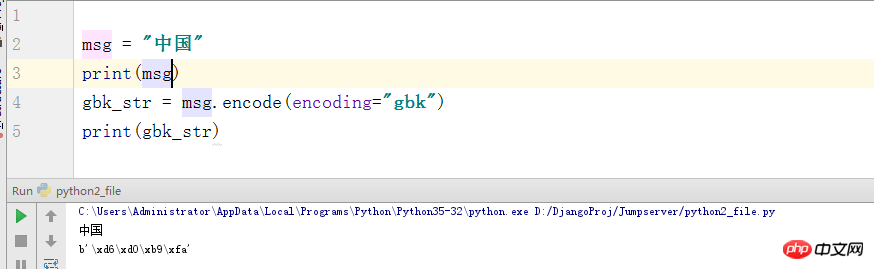
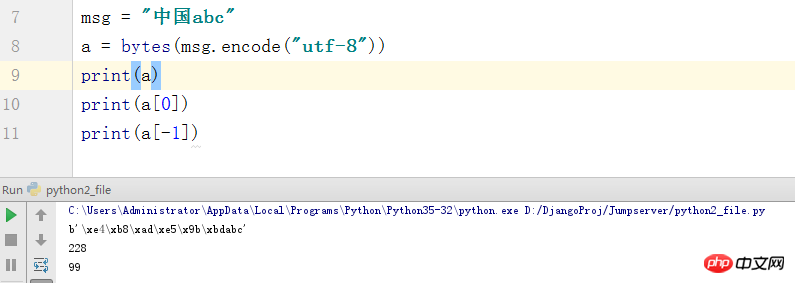
Python2 裡面的str 就是Python3中的bytes格式,而Python2中的str其實就是Unicode
#二、Python3對檔案操作補充
2.1、有「+」的檔案操作:
在這裡我會說三個,但是其實這些東西都沒有什麼鳥用,只是這算上一個知識點r+: 可讀,可以追加w+:清空源文件,再寫入新內容
a+:追加,可以讀
f = open('lyrics','r+',encoding='utf-8') #这里的lyrics是文件名字
f.read() #我先读取
f.write("Leon Have Dream") #在后面追加
f.close()f = open('lyricsback','w+',encoding='utf-8')
f.read()
f.write("Leon Have Dream")
f.read()
f.close()
#
f = open('lyricsback','a+',encoding='utf-8')
f.read()
f.write("Leon Have A Draem")
f.read()
f.close()PS:这里的补充一下,为什么在使用r+的时候先执行f.read()再执行f.write()就会在文件的结尾追加和直接使用f.write()直接就替换文件最前边的内容呢?这是因为Python在读文件的时候自己维护这一个“指针”,如果我们使用f.read()就相当于读完了这个文件,这时候指针也就会在最后面了。下面我在补充“f”这个对象的几个用法来证明Python文件指针。
f = open('lyricsback','r+' ,encoding='utf-8')
print(f.tell()) #this number is 0
f.seek(12) # 将指针向后面移动几个字节,一个汉字是三个字节
print(f.tell()) # this is seek number
f.write("Love Girl") #这里就从seek到地方替换
print(f.tell()) # tell()用法就是文件的指针位置
f.close()2.2、加b的方式对文件进行操作
rb:将文件以二进制的方式从硬盘中读取出来,这里得记住在open()函数中不要加encoding= 这个参数因为二进制不存在编码上的问题
wb:将文件以二进制的方式写入内容,不过在f.write()中加上encode="utf-8",意思就是申明编码的格式,并且会清楚原来文件内容
ab:只能以二进制方式追加。
三、函数
什么是函数?函数可以简单理解一段命令的集合。为什么需要用函数?这里有一个非常简单的原因,比如说你需要对一段代码反复进行操作,这里你当然可以一直复制再粘贴,但是这样灵活性和日后的维护成本将会变大。
#比方说现在需要写一个报警(调用接口)的程序,这里就用监控做比喻 if cpu > 80%: 连接邮箱服务器 发送消息 关闭连接 if memery > 80%: 连接邮箱服务器 发送消息 关闭连接 if disk > 80% 连接邮箱服务器 发送消息 关闭连接 #通过写这样的一个程序我们发现我们一直在重复调用发送邮箱的这一套接口。这样我们是否能想出一个办法解决这样的重复操作呢?请看下一个版本 发送邮件(): l连接邮箱服务器 发送连接 关闭连接 if cpu > 80% 发送邮件() if memery > 80%: 发送邮件() ....... # 这样以此类推,我们只需要挑用发送邮件的这个接口就可以节省代码的发送邮件了
通过上面的代码我们发现,我们只需要将报警的这一套流程放到一个公共的地方,等下面触发报警的条件的时候调用报警的函数,这样我们就可以省去当每次触发报警的时候我们自己在写报警的步骤了。但是函数是怎么定义呢?又有什么语法和定义呢?请看下面的一段代码,其中代码输出的是“Leon Have A Dream”
def leon(): #leon是函数名字
print("Leon Have A Dream")
leon() #调用函数带参数的函数:
a = 10 b = 5 def calc(a,b): print(a ** b) c = calc(a,b) print(c)
首先上面这些代码执行完会输出两个字符,一个是10000,一个是None,为什么会这样呢?首先c是等于执行了一遍calc这个函数,所以输出10000这个数字是肯定的,但是为什么还会输出一个None呢?原来我们的“c”执行了仪表calc函数,而calc函数中没有任何的返回值,所以c == None 。
PS:函数的返回结果就是return,其中return的含义就是:把函数的执行结果返回给外面,从而让挑用函数的“对象”得到执行结果
下面我们在看与之相似的列子
a = 10 b = 5 def calc(a,b): print(a ** b) return a + b c = calc(a,b) c = calc(10,6) print(c)
首先会输出的有三个值,分别是100000,1000000,16,为什么会是这三个呢,下面用一副图来说一下

PS:
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
Python中的全局变量和局部变量

PS:函数内部是可以修改列表,字典,集合,实例(class),我们通过下面一个图来说明
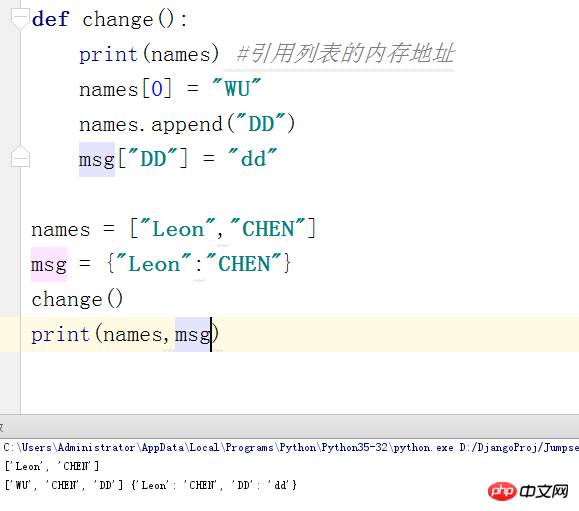
为什么列表和字典等会被添加和修改呢,原来函数内部知识引用了字典和列表的内存地址,而内存地址无法修改(可以重新开辟一块内存地址),而每个字典和列表中的每一个值都有对应的内存地址,但是记住我们函数是引用的列表或者字典本身的内存地址,所以这样打印到出来的也就会跟着改变了。
全局与局部变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
位置参数:
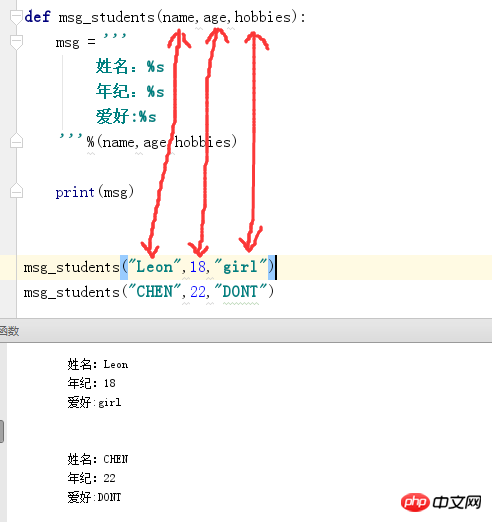
像上面这样实参和形参一一对应的上就是就是位置参数
默认参数:
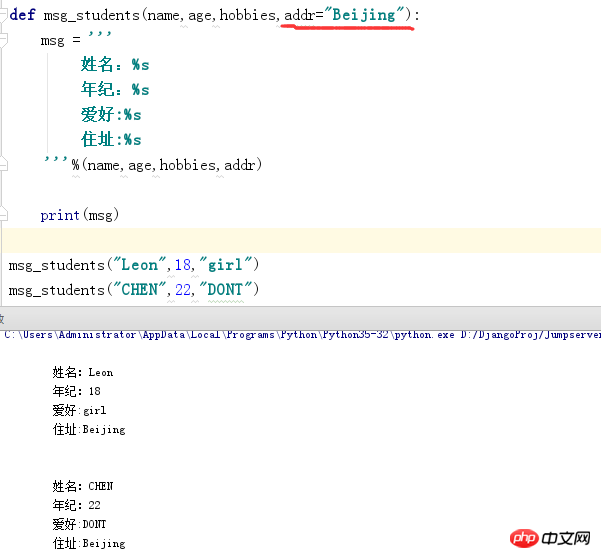
在函数将一个位置参数设置成一个默认的值的那一个变量就是默认参数,记住默认参数得在位置参数得后面
关键参数:
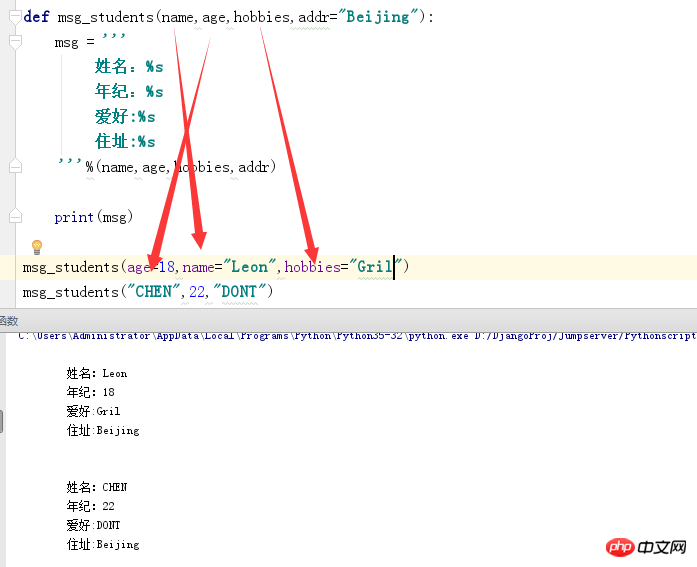
像上面这样实参和形参不一一对应,并且在调用函数的时候给参数赋值的叫做关键参数
非固定函数:
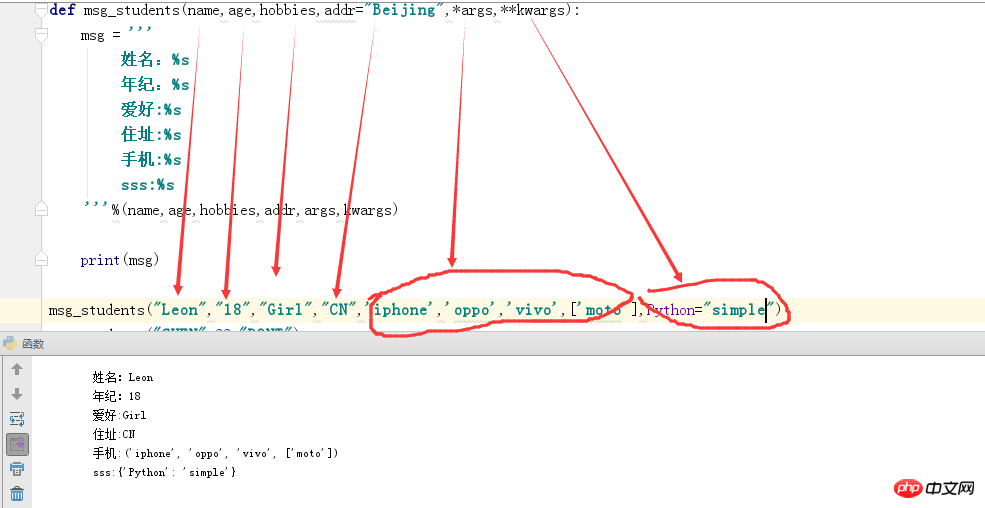
通过输出结果我们发现*args是接收多余的字符串类型的参数,而想Python="simple"(字典)类型的会传入给**kwargs,这就是非固定参数;当你不知道这个参数需要多少个参数时可以使用该函数类型
递归函数——二分查找
a = [1,2,3,4,5,7,9,10,11,12,14,15,16,17,19,21]
def calc(num,find_num):
print(num)
mid = int(len(num) / 2)
if mid == 0:
if num[mid] == find_num:
print("find it %s"%find_num)
else:
print("cannt find num")
if num[mid] == find_num:
print("find_num %s"%find_num)
elif num[mid] > find_num:
calc(num[0:mid],find_num)
elif num[mid] < find_num:
calc(num[mid+1:],find_num)
calc(a,12)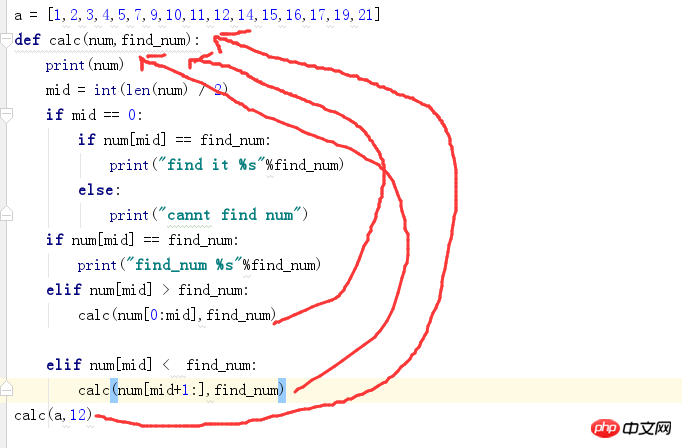
递归的特性
函数必须有明确的结束(判断)条件,也就是上图一开始的mid[0] 不能等于0,因为这样就会没有意义了
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归函数每次向下递归一次,上次的函数占用的内存地址不会被释放,而是一直会被阻塞主,等待函数全部执行完毕后释放,所以也可以说递归是相当消耗内存空间的,对此Python有递归的深度,如果超过该深度函数将会被推出(栈溢出)
匿名函数:
calc = lambda x:x+2 # x是形参,冒号后的内容是该匿名函数执行的动作 print(calc(5)) #匿名函数意识需要通过调用来执行的 calc = lambda x,y,z:x*y*z #匿名函数可以传入多个形参,各个参数之间用逗号隔开 print(calc(2,4,6)) c = map(lambda x:x*2,[2,5,4,6]) #map方法需要 传入两个参数一个是function(函数),itrables(可迭代)的数据类型 for i in c: print(i) #三元运算 for i in map(lambda x:x**2 if x >5 else x - 1,[1,2,3,5,7,8,9]): #lambda最多支持三元运算,map是直接调用匿名函数,但是如果想打印map的内容,需要循环 print(i)
高阶函数:
def calc(x,y,f): print(f(x) + f(y)) calc(10,-10,abs)
高阶函数的特性
把一个函数的内存地址传给另外一个函数,当做参数
一个函数把另外一个函数的当做返回值返回
满足上面的这个两个特性中的一个就可以称为高阶函数,这里因为偷懒,就是直接调用了Python中的内置函数
以上是Python中關於字元編碼與函數的使用詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
