

造成網頁亂碼的根本原因是什麼
先看段代码:
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>网页编码</title> </head> <body> </body> </html>
HTML代码中的 指定了网页的编码为utf-8。
网页编码涉及的知识点比较多,总的说来它也是一个历史遗留问题。
第一台计算机(ENIAC)于1946年2月诞生于美国,当时美国只考虑自己使用,并在计算机诞生后的几年里制定了一套ASCII码标准(American Standard Code for Information Interchange,美国信息交换标准代码),它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用8位二进制数组合来表示256种可能的字符(2的8次方=256),包含了大小写字母,数字0到9,标点符号,以及在美式英语中使用的特殊控制字符。一个字符占1个字节。ASCII码表部分编码如下:
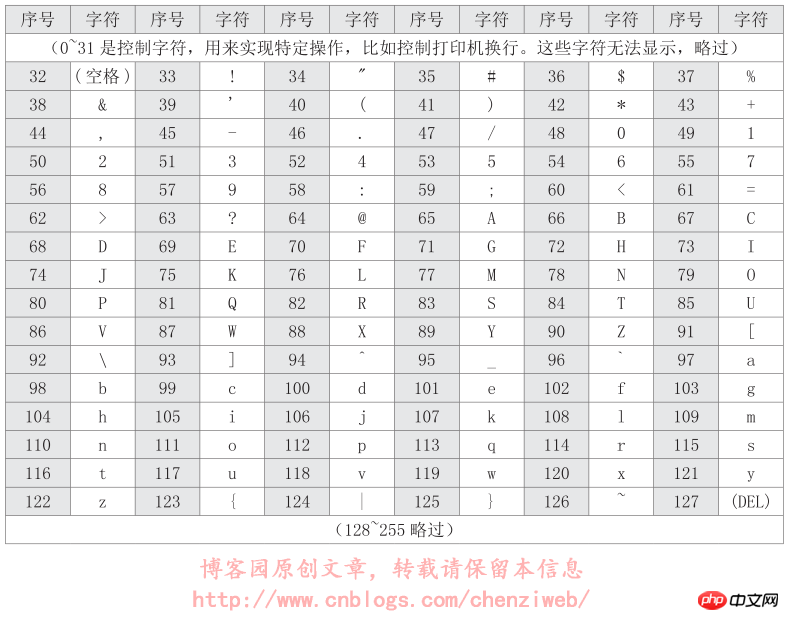
HTML的转义符(字符实体),比如符号“<”的转义符为“<”或“<”,其中的数字编号“60”即是ASCII码表的第60序号。类似的,大写字母“K”也可以转义为“K”。
我们使用转义符做个试验: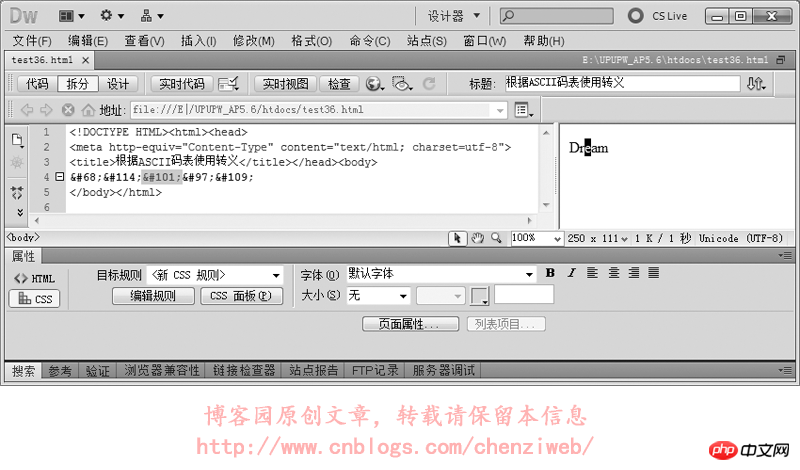
美国制定ASCII码的意思是:ASCII码可以满足在计算机领域所有字符和表示上的需要。不过这只是美国自己的意思,毕竟所有的英文单词都可以拆分来自26个英文字母,ASCII码表能表达256个字符,确实足够美国使用。
后来世界各地也都开始使用计算机,很多国家的语言文字并不是英文,这些国家的文字都没被包含在ASCII码表里。以我们中国为例,汉字近10万个,根本无法排进ASCII码表。于是我们国家对ASCII码表进行拓展并形成自己的的一套标准,在标准中一个汉字占2个字节,新的码表可以表达65536个汉字。但一开始并没有将码表全部填充使用完,只收录了常用的6000多个汉字、英文及其它符号,这套标准称为GB2312(信息交换用汉字编码字符集,GB是“国家标准”的简化词“国标”的拼音首字母缩写,2312是国标序号)。后来又制定了一套收录更多汉字的标准(收录的汉字有2万多个),称为GBK(汉字编码扩展规范,K是“扩”的拼音首字母)。
在GB2312或GBK里,许多标点符号都使用2个字节进行了重新编码,这类占2个字节的标点符号称为“全角”字符(“全角”也称“全形”或“全宽”或“全码”),原来ASCII码表中占1个字节的标点符号则称为“半角”字符(“半角”也称“半形”或“半宽”或“半码”)。全角的逗号、括号、句号等与半角是不一样的:
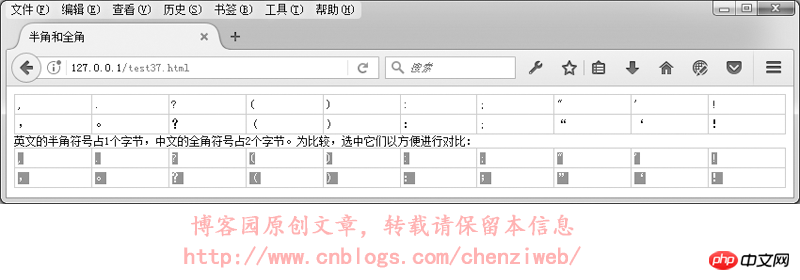
在中文輸入法下,預設的標點符號是全角字元;在英文輸入法下,標點符號則是半角字元。
我們接著說故事:隨著使用電腦的國家越來越多,各國製定自己的電腦編碼標準的情況也越來越多,導致的結果是:各國電腦的編碼互不支持、認識。例如在美國的電腦裡要顯示漢字,就必須安裝漢字系統才可以,否則中文檔案在美國系統的電腦中開啟便是亂碼。
就這樣,在這個時期催生出了一個叫ISO的國際組織(International Organization for Standardization,國際標準化組織),著手解決各國的程式設計問題。 ISO統一製作了一個稱為UNICODE(統一碼、萬國碼、單一碼,Universal Multiple-Octet Coded Character Set,又簡稱為UCS)的編碼方案,用於收錄地球上所有文字和符號。 UNICODE字符分為17組編排,每組編排稱為平面(Plane),每個平面擁有65536個碼位,共計可以收錄1114112個字符(111萬個字符,足夠大的容量)。 UNICODE編碼統一一個字元佔2個位元組。
但UNICODE在很長一段時間內無法推廣,直到網路的出現,資料的傳輸與交換使各國之間的編碼進行統一化成為迫切的需要。但早期的硬碟和網路流量都非常昂貴,UNICODE編碼裡的每個字元卻佔用了2個位元組的容量,於是為了節省檔案儲存時所佔的硬碟空間,也為了節省字元在網路傳輸過程中所佔用的網路流量,也制定了基於UNICODE、面向傳輸的眾多標準,這些面向傳輸的標準統稱為UTF(UCS Transfer Format)。 UNICODE編碼與UTF編碼並不是直接的一一對應,而是要透過一些演算法和規則來轉換。 UNICODE與UTF的關係有:UNICODE是根本、基礎、目的,而UTF只是實現UNICODE的手段、方法、過程。
常見的UTF格式有:UTF-8,UTF-16,UTF-32。其中UTF-8是網路上使用最廣的一種UNICODE的實作方式,它是專為傳輸而設計。正因為UTF-8是基於UNICODE而設計的傳輸實作方式,所以它能讓編碼無國界,任意國家的文字都能在任意國家的電腦瀏覽器中正常顯示。 UTF-8最大的一個特點是:它是一種變長的編碼方式,它可以使用1~4個位元組表示一個符號,根據不同的符號而變化位元組長度,當能夠使用1位元組表示一個符號時,便使用1個位元組來表示,如果需要2位元組才能表示的符號,便使用2個位元組來表示,類推,直到4個位元組,從而節省硬碟儲存空間和網路流量。
所以我們的網站在開發時如果使用GB2312或GBK編碼,當別的國家的電腦不支援漢字編碼,那麼看到的將是亂碼,顯示出來類似這樣:口口口口。而網站如果使用UTF-8編碼,則任意國家的電腦在開啟網站時其內容會自動轉換成UNICODE編碼,並且由於現在的電腦都支援UNICODE編碼,從而能正常顯示任意文字!
但是國內許多的網站仍然使用GB2312或GBK編碼,這類網站通常只面對國內用戶提供服務,面對國內用戶不會有顯示上的問題。只是如果面對其他國家的瀏覽者,這類網站被打開時很大程度上將呈現亂碼。
為了網站的高相容性與國際化,建議網站使用UTF-8編碼,而不是使用GB2312或GBK編碼。
指定網頁為UTF-8、GB2312和GBK的標籤分別為:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <meta http-equiv="Content-Type" content="text/html; charset=gbk">
那么有一个问题出现了:网页各种编码的区别,仅仅是在于这一行meta标签的设置差别吗?仅仅是“utf-8”这5个字符换成“gb2312”这6个字符之类的这种“小差别”吗?
不是的,差别不仅仅是这几个字符的差别。当网页指定meta标签中的编码为utf-8后,DreamWeaver在保存网页时会自动将网页文件保存为utf-8的编码格式(二进制码使用utf-8的编码格式),meta标签中的utf-8编码是为了告诉浏览器:这个网页用的是utf-8编码,请在显示时使用utf-8编码的格式解析并呈现出来;而如果meta标签中指定编码为gb2312,DreamWeaver在保存网页时会自动将网页文件保存为gb2312的编码格式(二进制码使用gb2312的编码格式),同样,meta标签中的gb2312编码只是为了告诉浏览器:这个网页用的是gb2312编码,请在显示时使用gb2312编码的格式解析并呈现出来。我们做个试验,将一个文本文件分别保存为utf-8格式(打开记事本新建文本文件,输入内容后,选择菜单:文件→另存为,编码选择为UTF-8)和gb2312格式(另存时编码选择为ANSI,ANSI代表当前操作系统的默认编码,在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,类推),对比其二进制数据。这里使用UltraEdit-32文件编辑器对文本文件进行16进制查看,即使用16进制查看文件的二进制数据: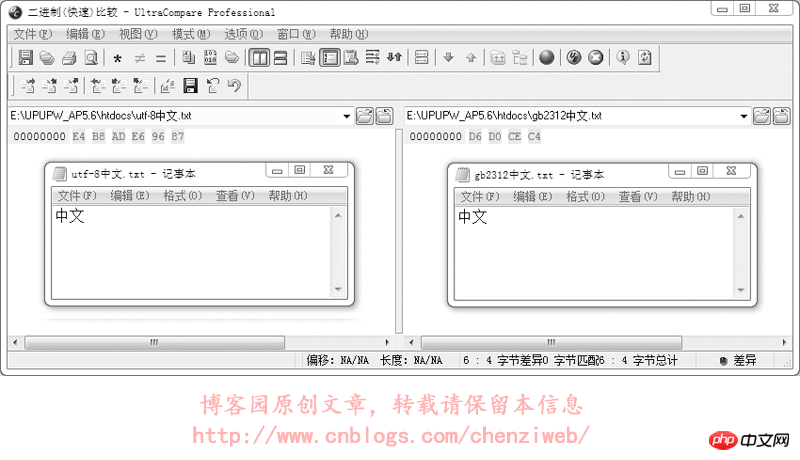
从上图中可以看到,使用utf-8编码和使用gb2312编码保存的文件,其二进制数据是不一样的,即这两个文件的二进制数据内容是不一样的。记事本软件在打开文本文件时,会尝试识别文件的编码并进行解析和显示,即文字保存在记事本里,无论保存成utf-8编码还是gb2312编码,通常情况下记事本都能正常识别和显示,不需要在文件里额外记录数据以告知记事本该文件是什么编码。但很多软件却无法做到智能识别文本文件的编码,这就要求文本文件在保存时,必须附带一些特殊的内容(额外的数据)以告知该文件是什么编码。UNICODE规范中有一个BOM(Byte Order Mark)的概念,就是字节序标记,在文件头部开始位置写入三个字节(EF BB BF)以告知该文件是utf-8编码格式。但这个BOM又带出了新的问题:不是所有的软件或处理程序都支持BOM,即不是所有的软件或处理程序都能识别文件开头的(EF BB BF)这三个字节。当不支持识别时,这三个字节又会被当成文件的实际数据内容。早期的火狐不支持对BOM的识别,当遇到BOM时会对这三个字节显示出特殊的乱码符号;而到目前为止,PHP处理程序仍然不支持BOM,即当一个PHP文件保存为utf-8时,如果附带了BOM,那么PHP处理程序会将BOM解析为PHP文件的实际数据内容而导致出错!在DreamWeaver中,选择软件头部菜单:修改→页面属性(也可以直接按快捷键ctrl+j),在弹出的页面属性面板中点选“标题/编码”,即可看到可供选择的编码。通常在改变网页的编码时,使用这种方式改变。如下图: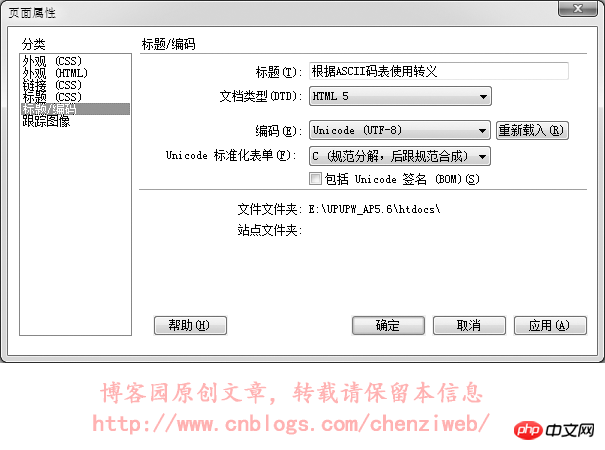
所以:当我们在meta标签中设置为utf-8编码格式时,网页文件就必须要存储为utf-8格式,这样浏览器才能正常显示网页而不是显示乱码。如果在meta标签中设置utf-8编码格式,网页文件却保存为gbk或其它格式,那么在打开网页时浏览器会接到网页meta标签中格式的通知:使用utf-8编码格式来解析和显示网页,而网页的二进制码(数据内容)却为gbk编码或其它格式,显示出来就会是乱码!这好比相亲时,红娘手里的资料有误,错误的告知男方:女方讲英语(meta标签中设置为utf-8编码)。结果女方却不懂英语(文件却不是utf-8编码)。男方开口一句“Hello”就让女方不知所谓了(乱码)。
我们来实验一下,网页指定meta标签中的编码为utf-8,文件却保存为gbk格式:我们先用DreamWeaver编辑一个utf-8格式的网页并保存,然后再用记事本打开该网页,另存为,编码选择为ANSI。
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>中文</title> </head> <body> 本文件使用dreamweaver保存后,再使用记事本打开,并另存为ANSI编码。 </body> </html>
在浏览器中的执行结果如下:
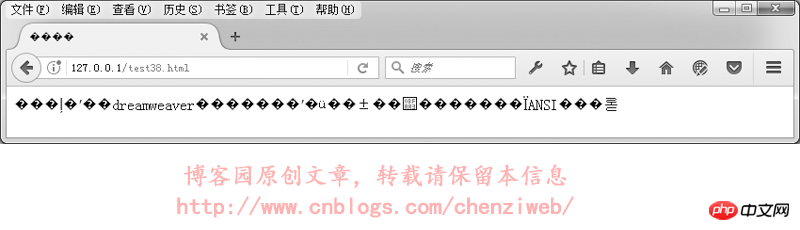
綜上所述:網頁開發時,盡量使用utf-8編碼格式,並且在儲存檔案時,儲存為utf-8編碼。 (dreamweaver在儲存網頁檔案時,會根據所指定的編碼自動儲存為正確的對應編碼,但如果使用其它網站代碼編輯器,例如記事本、Editplus等,就需要注意,在儲存檔案時要選擇為正確的編碼)。
以上是造成網頁亂碼的根本原因是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Linux中文亂碼怎麼解決
Feb 21, 2024 am 10:48 AM
Linux中文亂碼怎麼解決
Feb 21, 2024 am 10:48 AM
Linux中文亂碼問題是使用中文字元集和編碼時常見的一個問題。出現亂碼的原因可能是檔案編碼設定不正確,系統語言環境未安裝或未設置,以及終端顯示設定錯誤等。本文將介紹幾種常見的解決方法,並提供具體的程式碼範例。一、檢查檔案編碼設定使用file指令查看檔案編碼在終端機中使用file指令,可以檢視檔案的編碼:file-ifilename如果輸出中有"charset
 投影機失敗的原因是什麼「新手必看:無線投影機連線不成功的方法」
Feb 07, 2024 pm 05:03 PM
投影機失敗的原因是什麼「新手必看:無線投影機連線不成功的方法」
Feb 07, 2024 pm 05:03 PM
無線投影螢幕為什麼會連線不成功呢?有些小夥伴反映在使用無線投影螢幕的時候,會出現連線失敗的狀況,這是怎麼回事呢?無線投影機連線失敗怎麼辦?請確認您的電腦、電視和手機是否連接在同一個WiFi網路上。投影機軟體要求設備在同一網路下才能正常使用,而快點投影螢幕也不例外。因此,請您迅速檢查您的網路設定。確定是否支援投影功能很重要。智慧型電視和手機通常都支援DLNA或AirPlay功能。如果不支援投影機功能,就無法傳屏。確認設備是否正確連接:在同一WiFi下的設備可能有多個,確保連接的是想要實現同螢幕的設備。 4、確保網路的
 什麼原因導致wps office無法啟動列印作業
Mar 20, 2024 am 09:52 AM
什麼原因導致wps office無法啟動列印作業
Mar 20, 2024 am 09:52 AM
在區域網路內連接印表機啟動列印作業時會出現一些小狀況,例如偶爾會出現「wpsoffice無法啟動列印作業…」的問題,造成無法列印出文件等,耽誤我們的工作和學習,造成不好的影響,下面就告訴大家,怎麼解決wpsoffice無法啟動列印作業的問題?當然你可以升級軟體或是升級驅動等方案解決,但是這樣花費你好長的時間,下面我就給大家較少一種分分鐘可以搞定的方案。首先註意到wpsoffice無法啟動列印作業,導致無法進行列印。要解決這個問題,就需要逐一檢查。另外,確認印表機已開啟並連接。一般連接不正常會造
 PHP 500錯誤全面指南:原因、診斷與修復
Mar 22, 2024 pm 12:45 PM
PHP 500錯誤全面指南:原因、診斷與修復
Mar 22, 2024 pm 12:45 PM
PHP500錯誤全面指南:原因、診斷與修復在PHP開發過程中,我們常會遇到HTTP狀態碼為500的錯誤。這種錯誤通常被稱為"500InternalServerError",它是指在伺服器端處理請求時發生了一些未知的錯誤。在本文中,我們將探討PHP500錯誤的常見原因、診斷方法以及修復方法,並提供具體的程式碼範例供參考。 1.500錯誤的常見原因1.
 解決Windows10中文亂碼問題的方法
Jan 16, 2024 pm 02:21 PM
解決Windows10中文亂碼問題的方法
Jan 16, 2024 pm 02:21 PM
在Windows10系統中,出現亂碼現象可謂司空見慣。這背後的原因往往在於該作業系統並未對部分字元集提供預設的支持,抑或是設定的字元集選項有錯誤。為了對症下藥,以下我們將為您詳細解析實際的操作規程。 windows10亂碼怎麼解決1、開啟設置,找到「時間和語言」2、再找到「語言」3、找到「管理語言設定」4、點選這裡的「更改系統區域設定」5、如圖勾選上然後點擊確定就可以了。
 蘋果手機充電很慢是什麼原因
Mar 08, 2024 pm 06:28 PM
蘋果手機充電很慢是什麼原因
Mar 08, 2024 pm 06:28 PM
使用蘋果手機時,一些用戶可能會遇到充電速度緩慢的問題。造成這種問題的原因有很多種,可能是因為充電設備功率過低,設備故障,或是手機的USB介面出現問題,甚至是電池老化等因素導致的。蘋果手機充電很慢是什麼原因答:充電設備問題,手機硬體問題,手機系統問題。 1.用戶在使用功率比較低的充電設備時,手機的充電速度就會很慢。 2.使用第三方的劣質充電器或是充電線也會導致充電速度很慢。 3.推薦用戶使用官方的原廠充電器,或是更換正規的有認證的高功率充電器。 4.用戶的手機硬體出現問題,比如說手機的usb介面接觸不
 揭秘win11藍色畫面導致的根本原因
Jan 04, 2024 pm 05:32 PM
揭秘win11藍色畫面導致的根本原因
Jan 04, 2024 pm 05:32 PM
相信不少朋友都遇過系統藍屏的問題,不過不知道win11藍屏原因是什麼,其實導致系統藍屏的原因是有很多的,我們可以依序排查進行解決。 win11藍色畫面原因:一、記憶體不足1、運行太多軟體或遊戲消耗記憶體太大的時候可能發生。 2.尤其是現在win11存在記憶體溢出的bug,所以很有可能會遇到。 3.這時候可以嘗試設定虛擬記憶體來解決,不過最好的方法還是升級記憶體條。二、CPU超頻過熱1、CPU的問題原因其實跟記憶體差不多。 2.一般會發生在使用後期、建模等軟體,或在玩大型遊戲時發生。 3.CPU的消耗過大就會出現藍屏
 解決dll檔案開啟亂碼問題的編輯方式
Jan 06, 2024 pm 07:53 PM
解決dll檔案開啟亂碼問題的編輯方式
Jan 06, 2024 pm 07:53 PM
有很多的用戶在使用電腦的時候,會發現有很多的文件的尾綴是dll,但是很多的用戶們都不知道這種文件需要怎麼打開,想要知道的用戶們快來看看以下詳細教程吧~dll檔案怎麼打開編輯:1、下載一個叫做「exescope」的軟體,並下載安裝。 2、然後右鍵dll文件,選擇「用exescope編輯資源」。 3、然後在彈出的錯誤提示框中,點選「確定」。 4、然後在右邊的面板上,點擊每個組前面的「+」號可以查看到它所包含的內容。 5.點選需要檢視的dll文件,就能夠看到了,然後點選“文件”,選擇“匯出”。 6、然後就能夠
