

K-means演算法在Python中的實現

K-means是機器學習中一個比較常用的演算法,屬於無監督學習演算法,其常被用於資料的聚類,只需為它指定簇的數量即可自動將資料聚合到多類中,相同簇中的數據相似度較高,不同簇中數據相似度較低。
K-MEANS演算法是輸入聚類個數k,以及包含 n個資料物件的資料庫,輸出滿足方差最小標準k個聚類的一種演算法。 k-means 演算法接受輸入量k ;然後將n個資料物件劃分為k個聚類以便使得所獲得的聚類滿足:同一聚類中的對象相似度較高;而不同聚類中的對象相似度較小。本文將和大家介紹K-means演算法在Python中的實作。
核心思想
透過迭代尋找k個類別簇的一種分割方案,使得用這k個類別簇的平均值來代表對應各類別樣本時所得的總體誤差最小。
k個聚類具有以下特點:各聚類本身盡可能的緊湊,而各聚類之間盡可能的分開。
k-means演算法的基礎是最小誤差平方和準則,K-menas的優缺點:
##優點:
原理簡單速度快
對大資料集有比較好的伸縮性
#缺點:
需要指定聚類數量K對異常值敏感
對初始值敏感
K-means的聚類過程
##其聚類過程類似於梯度下降演算法,建立代價函數並透過迭代使得代價函數值越來越小
適當選擇c個類別的初始中心;
在第k次迭代中,對任意一個樣本,求其到c個中心的距離,將該樣本歸到距離最短的中心所在的類別;利用均值等方法更新該類別的中心值;
對於所有的c個聚類中心,如果利用(2)(3)的迭代法更新後,值保持不變,則迭代結束,否則繼續迭代。
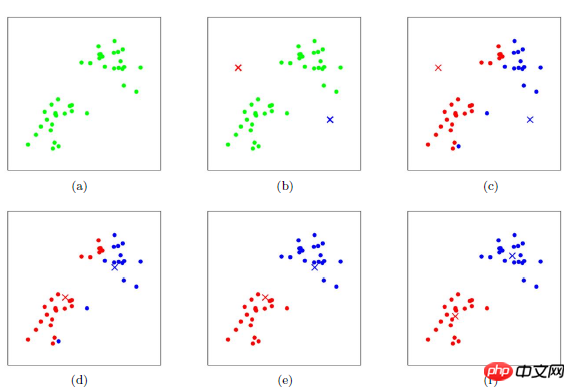 該演算法的最大優勢在於簡潔快速。演算法的關鍵在於初始中心的選擇和距離公式。
該演算法的最大優勢在於簡潔快速。演算法的關鍵在於初始中心的選擇和距離公式。
python中km的一些參數:
sklearn.cluster.KMeans( n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto' ) n_clusters: 簇的个数,即你想聚成几类 init: 初始簇中心的获取方法 n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10个质心,实现算法,然后返回最好的结果。 max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代) tol: 容忍度,即kmeans运行准则收敛的条件 precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的 verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值) random_state: 随机生成簇中心的状态条件。 copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。 n_jobs: 并行设置 algorithm: kmeans的实现算法,有:'auto', ‘full', ‘elkan', 其中 ‘full'表示用EM方式实现 虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
#下面展示一個程式碼範例
from sklearn.cluster import KMeans from sklearn.externals import joblib from sklearn import cluster import numpy as np # 生成10*3的矩阵 data = np.random.rand(10,3) print data # 聚类为4类 estimator=KMeans(n_clusters=4) # fit_predict表示拟合+预测,也可以分开写 res=estimator.fit_predict(data) # 预测类别标签结果 lable_pred=estimator.labels_ # 各个类别的聚类中心值 centroids=estimator.cluster_centers_ # 聚类中心均值向量的总和 inertia=estimator.inertia_ print lable_pred print centroids print inertia 代码执行结果 [0 2 1 0 2 2 0 3 2 0] [[ 0.3028348 0.25183096 0.62493622] [ 0.88481287 0.70891813 0.79463764] [ 0.66821961 0.54817207 0.30197415] [ 0.11629904 0.85684903 0.7088385 ]] 0.570794546829
#為了更直覺的描述,這次在圖上做一個展示,由於圖像上繪製二維比較直觀,所以資料調整到了二維,選取100個點繪製,聚類類別為3類
from sklearn.cluster import KMeans
from sklearn.externals import joblib
from sklearn import cluster
import numpy as np
import matplotlib.pyplot as plt
data = np.random.rand(100,2)
estimator=KMeans(n_clusters=3)
res=estimator.fit_predict(data)
lable_pred=estimator.labels_
centroids=estimator.cluster_centers_
inertia=estimator.inertia_
#print res
print lable_pred
print centroids
print inertia
for i in range(len(data)):
if int(lable_pred[i])==0:
plt.scatter(data[i][0],data[i][1],color='red')
if int(lable_pred[i])==1:
plt.scatter(data[i][0],data[i][1],color='black')
if int(lable_pred[i])==2:
plt.scatter(data[i][0],data[i][1],color='blue')
plt.show()#可以看到聚類效果還是不錯的,對k-means的聚類效率進行了一個測試,將維度擴寬到50維
| 資料維度 | ||
|---|---|---|
| 50維度 | #100000條 | |
| 50維 | 1000000條 | |
| 50維 |
from sklearn.externals import joblib joblib.dump(km,"model/km_model.m")
以上內容就是K -means演算法在Python中的實現,希望能幫助大家。
利用k-means聚類演算法辨識圖片主色調
#
以上是K-means演算法在Python中的實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸縮性
Apr 19, 2025 am 12:18 AM
Golang在性能和可擴展性方面優於Python。 1)Golang的編譯型特性和高效並發模型使其在高並發場景下表現出色。 2)Python作為解釋型語言,執行速度較慢,但通過工具如Cython可優化性能。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
