

NodeJS糗事百科爬蟲實例教程

本文主要跟大家講解了一下用NodeJS學習爬蟲,並透過爬糗事百科來講解用法和效果,一起學習下吧,希望能幫助到大家。
1.前言分析
平常都是利用 Python/.NET 語言實作爬蟲,然現在作為前端開發人員,自然需要熟練 NodeJS。下面利用 NodeJS 語言實作一個糗事百科的爬蟲。另外,本文使用的部分程式碼是 es6 語法。
實作該爬蟲所需的依賴函式庫如下。
request: 利用 get 或 post 等方法取得網頁的原始碼。 cheerio: 網頁原始碼解析,以取得所需資料。
本文首先對爬蟲所需依賴函式庫及其使用進行介紹,然後利用這些依賴函式庫,實作一個針對糗事百科的網路爬蟲。
2. request 函式庫
request 是一個輕量級的 http 函式庫,功能十分強大且使用簡單。可以使用它實作 Http 的請求,並且支援 HTTP 認證, 自定請求頭等。以下對 request 庫中一部分功能進行介紹。
安裝 request 模組如下:
npm install request
在安裝好 request 後,即可進行使用,下面利用 request 請求一下百度的網頁。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})在沒有設定 options 參數時,request 方法預設是 get 請求。而我喜歡利用 request 物件的具體方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});然而很多時候,直接去請求一個網址所獲取的 html 源碼,往往得不到我們需要的資訊。一般情況下,需要考慮到請求頭和網頁編碼。
網頁的請求頭網頁的編碼
下面介紹在請求的時候如何添加網頁請求頭以及設定正確的編碼。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})設定 options 參數, 新增 headers 屬性即可實現請求頭的設定;新增 encoding 屬性即可設定網頁的編碼。需要注意的是,若 encoding:null ,那麼 get 請求所取得的內容則是一個 Buffer 對象,即 body 是一個 Buffer 物件。
上面介紹的功能足矣滿足後面的所需了
3. cheerio 庫
cheerio 是一款伺服器端的Jquery,以輕、快、簡單易學等特點被開發者喜愛。有 Jquery 的基礎後再來學習 cheerio 函式庫非常輕鬆。它能夠快速定位到網頁中的元素,其規則和 Jquery 定位元素的方法是一樣的;它也能以一種非常方便的形式修改 html 中的元素內容,以及獲取它們的資料。以下主要針對 cheerio 快速定位網頁中的元素,以及取得它們的內容進行介紹。
先安裝 cheerio 函式庫
npm install cheerio
下面先給一段程式碼,再對程式碼進行解釋 cheerio 函式庫的用法。對部落格園首頁進行分析,然後提取每一頁中文章的標題。
首先對部落格園區首頁進行分析。如下圖:
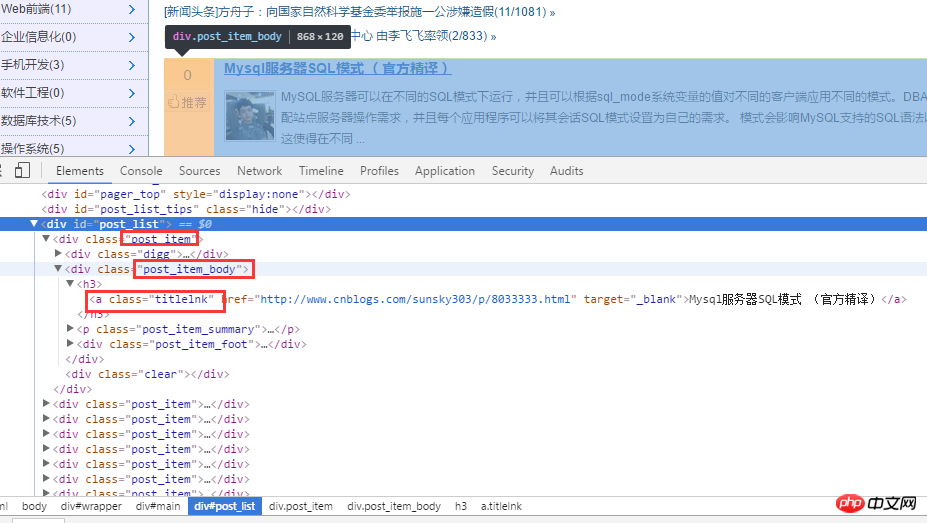
對html 原始碼進行分析後,先透過.post_item 取得所有標題,接著對每一個.post_item 進行分析,使用a.titlelnk 即可匹配每個標題的a 標籤。下面透過程式碼進行實作。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});當然,cheerio 函式庫也支援鍊式調用,上面的程式碼也可改寫成:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);上面的程式碼非常簡單,就不再用文字進行贅述了。以下總結一點自己認為比較重要的幾點。
使用find() 方法取得的節點集合A,若再次以A 集合中的元素為根節點定位它的子節點以及取得子元素的內容與屬性,需對A 集合中的子元素進行$(A[i]) 包裝,如上面的$(ele) 一樣。在上面程式碼中使用$(ele) ,其實還可以使用$(this) 但是由於我使用的是es6 的箭頭函數,因此改變了each 方法中回調函數的this 指針,因此,我使用$(ele); cheerio 函式庫也支援鍊式調用,如上面的$('.post_item').find('a.titlelnk') ,需要注意的是,cheerio 物件A 調用方法find(),如果A 是集合,那麼A集合中的每一個子元素都呼叫find() 方法,並放回一個結果結合。如果 A 呼叫 text() ,那麼 A 集合中的每一個子元素都會呼叫 text() 並傳回字串,該字串是所有子元素內容的合併(直接合併,沒有分隔符號)。
最後在總結一些我比較常用的方法。
first() last() children([selector]): 這個方法和 find 類似,只不過此方法只搜尋子節點,而 find 搜尋整個後代節點。
4. 糗事百科爬蟲
透過上面對 request 和 cheerio 類別庫的介紹,下面利用這兩個類別庫對糗事百科的頁面進行爬取。
1、在專案目錄中,新httpHelper.js 文件,透過url 取得糗事百科的網頁原始碼,程式碼如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;2、在專案目錄中,新建一個Splider.js文件,分析糗事百科的網頁程式碼,提取自己需要的信息,並且建立一個邏輯透過更改url 的id 來爬取不同頁面的資料。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
以上是NodeJS糗事百科爬蟲實例教程的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)




 夏天,一定要試試拍攝彩虹
Jul 21, 2024 pm 05:16 PM
夏天,一定要試試拍攝彩虹
Jul 21, 2024 pm 05:16 PM
夏天雨後,常常能見到美麗又神奇的特殊天氣景象-彩虹。這也是攝影中可遇而不可求的難得景象,非常出片。彩虹出現有這樣幾個條件:一是空氣中有充足的水滴,二是太陽以較低的角度照射。所以下午雨過天晴後的一段時間內,是最容易看到彩虹的時候。不過彩虹的形成受天氣、光線等條件的影響較大,因此一般只會持續一小段時間,而最佳觀賞、拍攝時間更為短暫。那麼遇到彩虹,怎樣才能合理地記錄下來並拍出質感呢? 1.尋找彩虹除了上面提到的條件外,彩虹通常出現在陽光照射的方向,即如果太陽由西向東照射,彩虹更有可能出現在東
 nodejs怎麼連接mysql資料庫
Apr 21, 2024 am 06:13 AM
nodejs怎麼連接mysql資料庫
Apr 21, 2024 am 06:13 AM
要連接 MySQL 資料庫,需要遵循以下步驟:安裝 mysql2 驅動程式。使用 mysql2.createConnection() 建立連接對象,其中包含主機位址、連接埠、使用者名稱、密碼和資料庫名稱。使用 connection.query() 執行查詢。最後使用 connection.end() 結束連線。
 nodejs安裝目錄裡的npm與npm.cmd檔有什麼差別
Apr 21, 2024 am 05:18 AM
nodejs安裝目錄裡的npm與npm.cmd檔有什麼差別
Apr 21, 2024 am 05:18 AM
Node.js 安裝目錄中有兩個與 npm 相關的文件:npm 和 npm.cmd,區別如下:擴展名不同:npm 是可執行文件,npm.cmd 是命令視窗快捷方式。 Windows 使用者:npm.cmd 可以在命令提示字元中使用,npm 只能從命令列執行。相容性:npm.cmd 特定於 Windows 系統,npm 跨平台可用。使用建議:Windows 使用者使用 npm.cmd,其他作業系統使用 npm。

 nodejs可以寫前端嗎
Apr 21, 2024 am 05:00 AM
nodejs可以寫前端嗎
Apr 21, 2024 am 05:00 AM
是的,Node.js可用於前端開發,主要優勢包括高效能、豐富的生態系統和跨平台相容性。需要考慮的注意事項有學習曲線、工具支援和社群規模較小。
 nodejs和java的差別大嗎
Apr 21, 2024 am 06:12 AM
nodejs和java的差別大嗎
Apr 21, 2024 am 06:12 AM
Node.js 和 Java 的主要差異在於設計和特性:事件驅動與執行緒驅動:Node.js 基於事件驅動,Java 基於執行緒驅動。單執行緒與多執行緒:Node.js 使用單執行緒事件循環,Java 使用多執行緒架構。執行時間環境:Node.js 在 V8 JavaScript 引擎上運行,而 Java 在 JVM 上運行。語法:Node.js 使用 JavaScript 語法,而 Java 使用 Java 語法。用途:Node.js 適用於 I/O 密集型任務,而 Java 適用於大型企業應用程式。
 nodejs適合什麼項目
Apr 21, 2024 am 05:45 AM
nodejs適合什麼項目
Apr 21, 2024 am 05:45 AM
Node.js 適用於以下專案類型:網頁和伺服器應用程式事件驅動應用程式即時應用程式資料密集型應用程式命令列工具和腳本輕量級微服務
