

Node模組系統及其模式詳解

本文主要介紹了淺談Node模組系統及其模式,小編覺得蠻不錯的,現在分享給大家,也給大家做個參考。一起跟著小編過來看看吧,希望能幫助大家。
模組是建立應用程式的基礎,也讓函數和變數私有化,不直接對外暴露出來,接下來我們就要介紹Node的模組化系統和它最常用的模式
#為了讓Node.js的檔案可以互相調用,Node.js提供了一個簡單的模組系統。
模組是Node.js 應用程式的基本組成部分,檔案和模組是一一對應的。換言之,一個 Node.js 檔案就是一個模組,而這個檔案可能是JavaScript 程式碼、JSON 或編譯過的C/C++ 擴充功能。
module的本質
我們都知道,JavaScript有一個很大的缺陷就是缺少namespacing的概念,程式運行在全域作用域下,很容易被內部應用程式的程式碼或第三方依賴程式的資料所污染,一個很典型的解決方案就使透過IIFE來解決,本質上是利用閉包來解決
const module = (() => {
const privateOne = () => {
// ...
}
const privateTwo = () => {
// ...
}
const exported = {
publicOne: () => {
// ...
},
publicTwo: []
}
return exported;
})()
console.log(module);透過上面的程式碼,我們可以看出,module變數包含的只有對外暴露的API,然而剩下的module內容是對外不可見的,而這個也是Node module system最核心的想法。
Node modules 說明
CommonJS是一個致力於將JavaScript生態系統標準化的一個組織,它最出名的一個提議就是我們眾所周知的CommonJS modules,Node在本規範的基礎上建構了他自己的模組系統,並且添加了一些自訂擴展,為了描述它是怎麼工作的,我們可以使用上面所提到的module的本質的思想,自己做一個類似的實現。
自製一個module loader
下面的程式碼主要是模仿Node原始的require()函數的功能
首先,我們建立一個函數用來載入一個module的內容,將它包裹在一個私有的作用域中
function loadModule(filename, module, require) {
const warppedSrc = `(function(module, mexports, require) {
${fs.readFileSync(filename, 'utf-8')}
})(module, module.exports, require)`
eval(warppedSrc);
}module的源代碼被包裝到一個函數中,如同IIFE那樣,這裡的差異在於我們傳遞了一些變數給module,特別指module、module.exports和require,注意的是我們的exports變數實質上是又module.exports初始化的,我們接下來會繼續討論這個
*在這個例子中,需要注意的是,我們使用了類似eval()或是node的vm模組,它們可能會導致一些程式碼注入攻擊的安全性問題,所以我們需要特別注意並避免
接下來,讓我們透過實作我們的require()函數,來看看這些變數怎麼被引入的
#const require = (moduleName) => {
console.log(`Required invoked for module: ${moduleName}`);
const id = require.resolve(moduleName);
if(require.cache[id]) {
return require.cache[id].exports;
}
// module structure data
const module = {
exports: {},
id: id
}
// uodate cache
require.cache[id] = module;
// load the module
loadModule(id, module, require);
// return exported variables
return module.exports;
}
require.cache = {};
require.resolve = (moduleName) => {
// resolve a full module id from the moduleName
}- #模組名被當作參數傳入,首先要做的事情時呼叫require.resolve方法根據傳入的模組名稱產生module id(透過指定的resolve演算法來產生)
- 如果該模組已經載入過了,那麼直接會從快取中獲得
- 如果該模組還沒有被載入過,我們會初始化一個module對象,其中包含兩個屬性,一個是module id,另外一個屬性是exports,它的初始值為一個空對象,這個屬性會被用來保存模組的export的公共的API程式碼
- 將該module進行cache
- 呼叫我們上面定義的loadModule函數來取得模組的原始碼,將初始化的module物件作為參數傳入,因為module是對象,引用類型,所以模組可以利用module.exports或替換module.exports來暴露它的公共API
- #最後,回傳給呼叫者module.exports的內容,也就是該模組的公共API
定義一個模組
透過觀察我們自製的require()函數的工作機制,我們應該很清楚的知道如何定義一個模組const dependency = require('./anotherModule');
function log() {
console.log(`get another ${dependency.username}`);
}
module.exports.run = () => {
log();
}
// anotherModule.js
module.exports = {
username: 'wingerwang'
}定義全域變數
即使所有的變數和函數都在模組本身的作用域內宣告的,但是仍然可以定義全域變數,事實上,模組系統暴露一個用來定義全域變數的特殊變數global,任何分配到這個變數的變數都會自動的變成全域變數需要注意的是,污染全局作用域是一个很不好的事情,甚至使得让模块系统的优点消失,所以只有当你自己知道你要做什么时候,才去使用它
module.exports VS exports
很多不熟悉Node的开发同学,会对于module.exports和exports非常的困惑,通过上面的代码我们很直观的明白,exports只是module.exports的一个引用,而且在模块加载之前它本质上只是一个简单的对象
这意味着我们可以将新属性挂载到exports引用上
exports.hello = () => {
console.log('hello');
}如果是对exports重新赋值,也不会有影响,因为这个时候exports是一个新的对象,而不再是module.exports的引用,所以不会改变module.exports的内容。所以下面的代码是错误的
exports = () => {
console.log('hello');
}如果你想暴露的不是一个对象,或者是函数、实例或者是一个字符串,那可以通过module.exports来做
module.exports = () => {
console.log('hello');
}require函数是同步的
另外一个重要的我们需要注意的细节是,我们自建的require函数是同步的,事实上,它返回模块内容的方法很简单,并且不需要回调函数。Node内置的require()函数也是如此。因此,对于module.exports内容必须是同步的
// incorret code
setTimeout(() => {
module.exports = function(){}
}, 100)这个性质对于我们定义模块的方法十分重要,使得限制我们在定义模块的时候使用同步的代码。这也是为什么Node提供了很多同步API给我们的最重要的原因之一
如果我们需要定义一个异步操作来进行初始化的模块,我们也可以这么做,但是这种方法的问题是,我们不能保证require进来的模块能够准备好,后续我们会讨论这个问题的解决方案
其实,在早期的Node版本里,是有异步的require方法的,但是因为它的初始化时间和异步I/O所带来的性能消耗而废除了
resolving 算法
相依性地狱(dependency hell)描述的是由于软件之间的依赖性不能被满足从而导致的问题,软件的依赖反过来取决于其他的依赖,但是需要不同的兼容版本。Node很好的解决了这个问题通过加载不同版本的模块,具体取决于该模块从哪里被加载。这个特性的所有优点都能在npm上体现,并且也在require函数的resolving 算法中使用
然我们来快速连接下这个算法,我们都知道,resolve()函数获取模块名作为输入,然后返回一个模块的全路径,该路金用于加载它的代码也作为该模块唯一的标识。resolcing算法可以分为以下三个主要分支
文件模块(File modules),如果模块名是以"/"开始,则被认为是绝对路径开始,如果是以"./"开始,则表示为相对路径,它从使用该模块的位置开始计算加载模块的位置
核心模块(core modules),如果模块名不是"/"、"./"开始的话,该算法会首先去搜索Node的核心模块
包模块(package modules),如果通过模块名没有在核心模块中找到,那么就会继续在当前目录下的node_modules文件夹下寻找匹配的模块,如果没有,则一级一级往上照,直到到达文件系统的根目录
对于文件和包模块,单个文件和文件夹可以匹配到模块名,特别的,算法将尝试匹配一下内容
.js /index.js 在
/package main中指定的目录/文件
算法文档
每个包通过npm安装的依赖会放在node_modules文件夹下,这就意味着,按照我们刚刚算法的描述,每个包都会有它自己私有的依赖。
myApp
├── foo.js
└── node_modules
├── depA
│ └── index.js
└── depB
│
├── bar.js
├── node_modules
├── depA
│ └── index.js
└── depC
├── foobar.js
└── node_modules
└── depA
└── index.js通过看上面的文件夹结构,myApp、depb和depC都依赖depA,但是他们都有自己私有的依赖版本,根据上面所说的算法的规则,当使用require('depA')会根据加载的模块的位置加载不同的文件
myApp/foo.js 加载的是 /myApp/node_modules/depA/index.js
myApp/node_modules/depB/bar.js 加载的是 /myApp/node_modules/depB/node_modules/depA/index.js
myApp/node_modules/depB/depC/foobar.js 加载的是 /myApp/node_modules/depB/depC/node_modules/depA/index.js
resolving算法是保证Node依赖管理的核心部分,它的存在使得即便应用程序拥有成百上千个包的情况下也不会出现冲突和版本不兼容的问题
当我们使用require()时,resolving算法对于我们是透明的,然后,如果需要的话,也可以在模块中直接通过调用require.resolve()来使用
模块缓存(module cache)
每个模块都会在它第一次被require的时候加载和计算,然后随后的require会返回缓存的版本,这一点通过看我们自制的require函数会非常清楚,缓存是提高性能的重要手段,而且他也带来了一些其他的好处
使得在模块依赖关系中,循环依赖变得可行
它保证了在给定的包中,require相同的模块总是会返回相同的实例
模块的缓存通过变量require.cache暴露出来,所以如果需要的话,可以直接获取,一个很常见的使用场景是通过删除require.cache的key值使得某个模块的缓存失效,但是不建议在非测试环境下去使用这个功能
循环依赖
很多人会认为循环依赖是自身设计的问题,但是这确实是在真实的项目中会发生的问题,所以我们很有必要去弄清楚在Node内部是怎么工作的。然我们通过我们自制的require函数来看看有没有什么问题
定义两个模块
// a.js
exports.loaded = false;
const b = require('./b.js');
module.exports = {
bWasLoaded: b.loaded,
loaded: true
}
// b.js
exports.loaded = false;
const a = require('./a.js');
module.exports = {
aWasLoaded: a.loaded,
loaded: true
}在main.js中调用
const a = require('./a'); const b = require('./b'); console.log(a); console.log(b);
最后的结果是
{ bWasLoaded: true, loaded: true }
{ aWasLoaded: false, loaded: true }
这个结果揭示了循环依赖的注意事项,虽然在main主模块require两个模块的时候,它们已经完成了初始化,但是a.js模块是没有完成的,这种状态将会持续到它把模块b.js加载完,这种情况需要我们值得注意
其实造成这个的原因主要是因为缓存的原因,当我们先引入a.js的时候,到达去引入b.js的时候,这个时候require.cache已经有了关于a.js的缓存,所以在b.js模块中,去引入a.js的时候,直接返回的是require.cache中关于a.js的缓存,也就是不完全的a.js模块,对于b.js也是一样的操作,才会得出上面的结果
模块定义技巧
模块系统除了成为一个加载依赖的机制意外,也是一个很好的工具去定义API,对于API设计的主要问题,是去考虑私有和公有功能的平衡,最大的隐藏内部实现细节,对外暴露出API的可用性,而且还需要对软件的扩展性和可用性等的平衡
接下来来介绍几种在Node中常见的定义模块的方法
命名导出
这也是最常见的一种方法,通过将值挂载到exports或者是module.exports上,通过这种方法,对外暴露的对象成为了一个容器或者是命名空间
// logger.js
exports.info = function(message) {
console.log('info:' + message);
}
exports.verbose = function(message) {
console.log('verbose:' + message)
}// main.js const logger = require('./logger.js'); logger.info('hello'); logger.verbose('world');
很多Node的核心模块都使用的这种模式
其实在CommonJS规范中,只允许使用exports对外暴露公共成员,因此该方法是唯一的真的符合CommmonJS规范的,对于通过module.exports去暴露的,都是Node的一个扩展功能
函数导出
另一个很常见的就是将整个module.exports作为一个函数对外暴露,它主要的优点在于只暴露了一个函数,使得提供了一个很清晰的模块的入口,易于理解和使用,这种模式也被社区称为substack pattern
// logger.js
module.exports = function(message) {
// ...
}该模式的的一个扩展就是将上面提到的命名导出组合起来,虽然它仍然只是提供了一个入口点,但是可以使用次要的功能
module.exports.verbose = function(message) {
// ...
}虽然看起来暴露一个函数是一个限制,但是它是一个很完美的方式,把重点放在一个函数中,代表该函数是这个模块最重要的功能,而且使得内部私有变量属性变的更透明
Node的模块化也鼓励我们使用单一职责原则,每个模块应该对单个功能负责,从而保证模块的复用性
构造函数导出
将构造函数导出,是一个函数导出的特例,但是区别在于它可以使得用户通过它区创建一个实例,但是我们仍然继承了它的prototype属性,类似于类的概念
class Logger {
constructor(name) {
this.name = name;
}
log(message) {
// ...
}
info(message) {
// ...
}
verbose(message) {
// ...
}
}const Logger = require('./logger'); const dbLogger = new Logger('DB'); // ...
实例导出
我们可以利用require的缓存机制轻松的定义从构造函数或者是工厂实例化的实例,可以在不同的模块中共享
// count.js
function Count() {
this.count = 0;
}
Count.prototype.add = function() {
this.count++;
}
module.exports = new Count();
// a.js
const count = require('./count');
count.add();
console.log(count.count)
// b.js
const count = require('./count');
count.add();
console.log(count.count)
// main.js
const a = require('./a');
const b = require('./b');输出的结果是
1
2
该模式很像单例模式,它并不保证整个应用程序的实例的唯一性,因为一个模块很可能存在一个依赖树,所以可能会有多个依赖,但是不是在同一个package中
修改其他的模块或者全局作用域
一个模块甚至可以导出任何东西这可以看起来有点不合适;但是,我们不应该忘记一个模块可以修改全局范围和其中的任何对象,包括缓存中的其他模块。请注意,这些通常被认为是不好的做法,但是由于这种模式在某些情况下(例如测试)可能是有用和安全的,有时确实可以利用这一特性,这是值得了解和理解的。我们说一个模块可以修改全局范围内的其他模块或对象。它通常是指在运行时修改现有对象以更改或扩展其行为或应用的临时更改。
以下示例显示了我们如何向另一个模块添加新函数
// file patcher.js // ./logger is another module require('./logger').customMessage = () => console.log('This is a new functionality');
// file main.js require('./patcher'); const logger = require('./logger'); logger.customMessage();
在上述代码中,必须首先引入patcher程序才能使用logger模块。
上面的写法是很危险的。主要考虑的是拥有修改全局命名空间或其他模块的模块是具有副作用的操作。换句话说,它会影响其范围之外的实体的状态,这可能导致不可预测的后果,特别是当多个模块与相同的实体进行交互时。想象一下,有两个不同的模块尝试设置相同的全局变量,或者修改同一个模块的相同属性,效果可能是不可预测的(哪个模块胜出?),但最重要的是它会对在整个应用程序产生影响。
相关推荐:
以上是Node模組系統及其模式詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 微信的免打擾模式有什麼作用
Feb 23, 2024 pm 10:48 PM
微信的免打擾模式有什麼作用
Feb 23, 2024 pm 10:48 PM
微信勿擾模式什麼意思如今,隨著智慧型手機的普及和行動網路的快速發展,社群媒體平台已成為人們日常生活中不可或缺的一部分。而微信作為國內最受歡迎的社群媒體平台之一,幾乎每個人都有一個微信帳號。我們可以透過微信與朋友、家人、同事進行即時溝通,分享生活中的點滴,了解彼此的近況。然而,在這個時代,我們也不可避免地面臨資訊過載和隱私洩漏的問題,特別是對於那些需要專注或
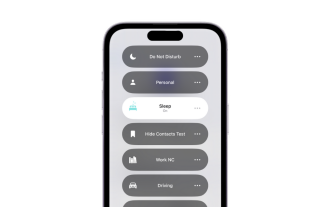 iPhone上的睡眠模式有何用途?
Nov 04, 2023 am 11:13 AM
iPhone上的睡眠模式有何用途?
Nov 04, 2023 am 11:13 AM
長期以來,iOS設備一直能夠使用「健康」應用程式追蹤您的睡眠模式等。但是,當您在睡覺時被通知打擾時,這不是很煩人嗎?這些通知可能無關緊要,因此在此過程中會擾亂您的睡眠模式。雖然免打擾模式是避免睡覺時分心的好方法,但它可能會導致您錯過夜間收到的重要電話和訊息。值得慶幸的是,這就是睡眠模式的用武之地。讓我們了解更多關於它以及如何在iPhone上使用它的資訊。睡眠模式在iPhone上有什麼作用睡眠模式是iOS中專用的專注模式,會根據你在「健康」App中的睡眠定時自動啟動。它可以幫助您設定鬧鐘,然後可以
 node專案中如何使用express來處理檔案的上傳
Mar 28, 2023 pm 07:28 PM
node專案中如何使用express來處理檔案的上傳
Mar 28, 2023 pm 07:28 PM
怎麼處理文件上傳?以下這篇文章為大家介紹一下node專案中如何使用express來處理文件的上傳,希望對大家有幫助!
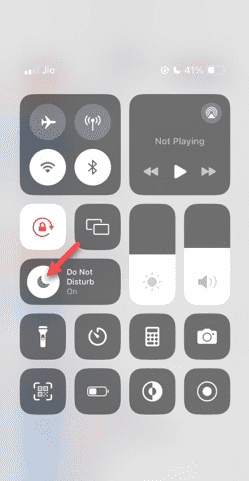 請勿打擾模式在iPhone中不起作用:修復
Apr 24, 2024 pm 04:50 PM
請勿打擾模式在iPhone中不起作用:修復
Apr 24, 2024 pm 04:50 PM
即使在「請勿打擾」模式下接聽電話也可能是一種非常煩人的體驗。顧名思義,請勿打擾模式可關閉來自郵件、訊息等的所有來電通知和警報。您可以按照這些解決方案集進行修復。修復1–啟用對焦模式在手機上啟用對焦模式。步驟1–從頂部向下滑動以存取控制中心。步驟2–接下來,在手機上啟用「對焦模式」。專注模式可在手機上啟用「請勿打擾」模式。它不會讓您的手機上出現任何來電提醒。修復2–更改對焦模式設定如果對焦模式設定中存在一些問題,則應進行修復。步驟1–打開您的iPhone設定視窗。步驟2–接下來,開啟「對焦」模式設
 深入淺析Node的進程管理工具'pm2”
Apr 03, 2023 pm 06:02 PM
深入淺析Node的進程管理工具'pm2”
Apr 03, 2023 pm 06:02 PM
這篇文章跟大家分享Node的進程管理工具“pm2”,聊聊為什麼需要pm2、安裝和使用pm2的方法,希望對大家有幫助!
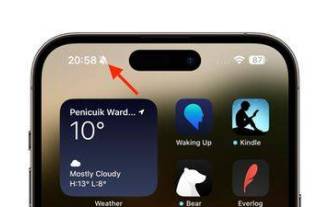 iPhone 15 Pro:如何擺脫狀態列中的靜音模式符號
Sep 24, 2023 pm 10:01 PM
iPhone 15 Pro:如何擺脫狀態列中的靜音模式符號
Sep 24, 2023 pm 10:01 PM
在iPhone15Pro和iPhone15ProMax型號上,Apple推出了一個實體可編程的動作按鈕,取代了音量按鈕上方的傳統響鈴/靜音開關。可以對操作按鈕進行編程以執行幾種不同的功能,但是在靜音和響鈴模式之間切換的能力並沒有消失。預設情況下,長按一次操作按鈕將使裝置靜音,按鈕的觸覺回饋將發出三個脈衝。兩款iPhone15Pro機型在狀態欄中的時間旁邊都會顯示一個劃掉的鈴鐺符號,表示靜音/靜音模式已激活,並且它將一直保持到您再次長按“操作”按鈕取消設備靜音。如果您傾向於將iPhone置於靜音模
 Pi Node教學:什麼是Pi節點?如何安裝和設定Pi Node?
Mar 05, 2025 pm 05:57 PM
Pi Node教學:什麼是Pi節點?如何安裝和設定Pi Node?
Mar 05, 2025 pm 05:57 PM
PiNetwork節點詳解及安裝指南本文將詳細介紹PiNetwork生態系統中的關鍵角色——Pi節點,並提供安裝和配置的完整步驟。 Pi節點在PiNetwork區塊鏈測試網推出後,成為眾多先鋒積極參與測試的重要環節,為即將到來的主網發布做準備。如果您還不了解PiNetwork,請參考Pi幣是什麼?上市價格多少? Pi用途、挖礦及安全性分析。什麼是PiNetwork? PiNetwork項目始於2019年,擁有其專屬加密貨幣Pi幣。該項目旨在創建一個人人可參與
 如何啟用「記事本++深色模式」和「記事本++深色主題」?
Oct 27, 2023 pm 11:17 PM
如何啟用「記事本++深色模式」和「記事本++深色主題」?
Oct 27, 2023 pm 11:17 PM
記事本++暗模式v8.0沒有參數,Notepad++是最有用的文字編輯器。在Windows10上執行的每個應用程式都支援暗模式。您可以命名網頁瀏覽器,例如Chrome、Firefox和MicrosoftEdge。如果您在記事本++上工作,預設的白色背景可能會傷害您的眼睛。開發人員已將暗模式加入到版本8的Notepad++中,這是開啟它的方法。為Windows11/10啟用記事本++暗模式啟動記事本++點選「設定」>「首選項」>「暗模式」選擇「啟用深色模式」重新啟動記
