var fs = require( 'fs' );
var http = require( 'http' );
var cheerio = require( 'cheerio' );
var jade = require( 'jade' );
var aList = [];
var aUrl = [];
function filterArticle(html) {
var $ = cheerio.load( html );
var arcDetail = {};
var title = $( "#cb_post_title_url" ).text();
var href = $( "#cb_post_title_url" ).attr( "href" );
var re = /\/(\d+)\.html/;
var id = href.match( re )[1];
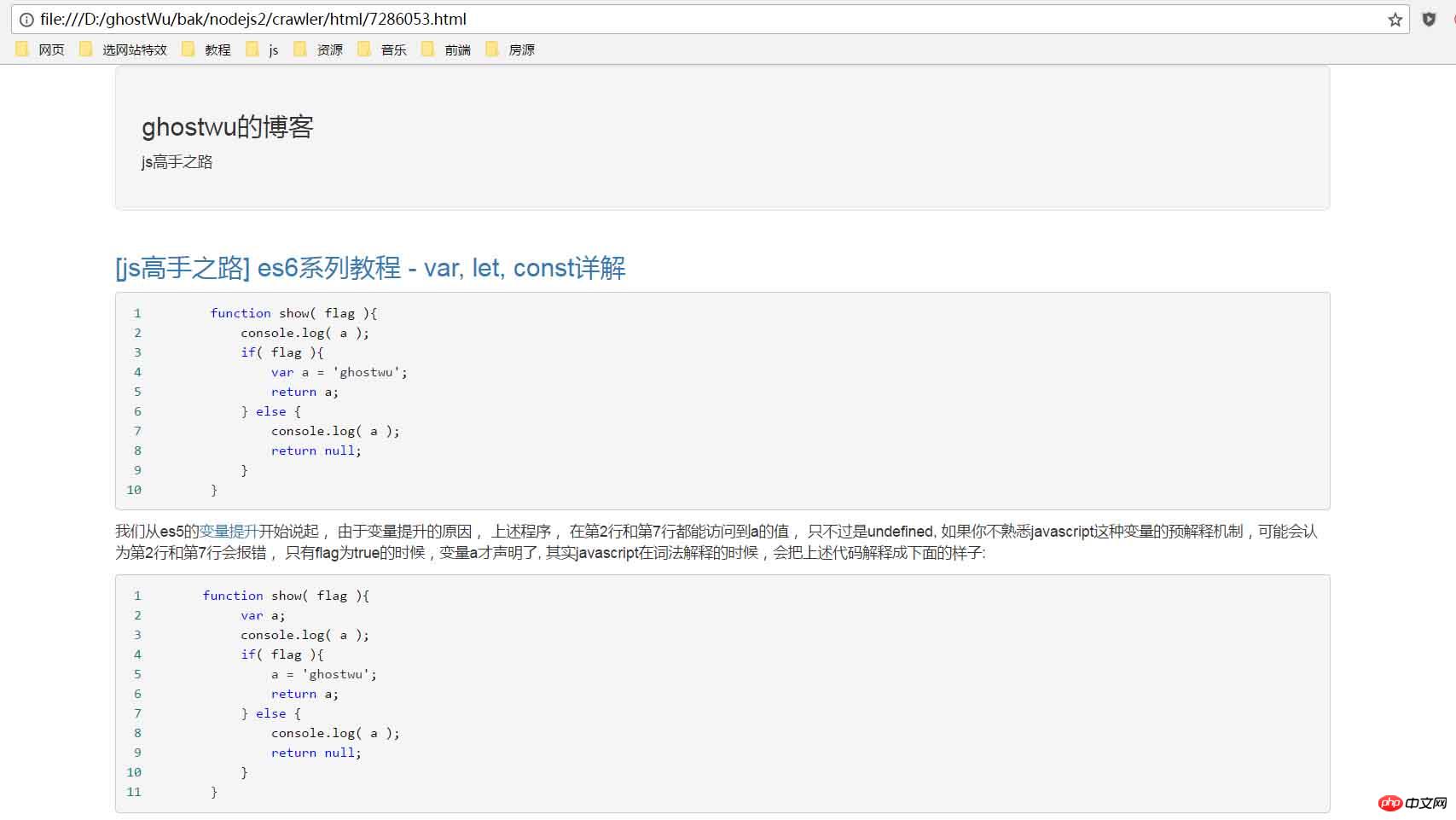
var body = $( "#cnblogs_post_body" ).html();
return {
id : id,
title : title,
href : href,
body : body
};
}
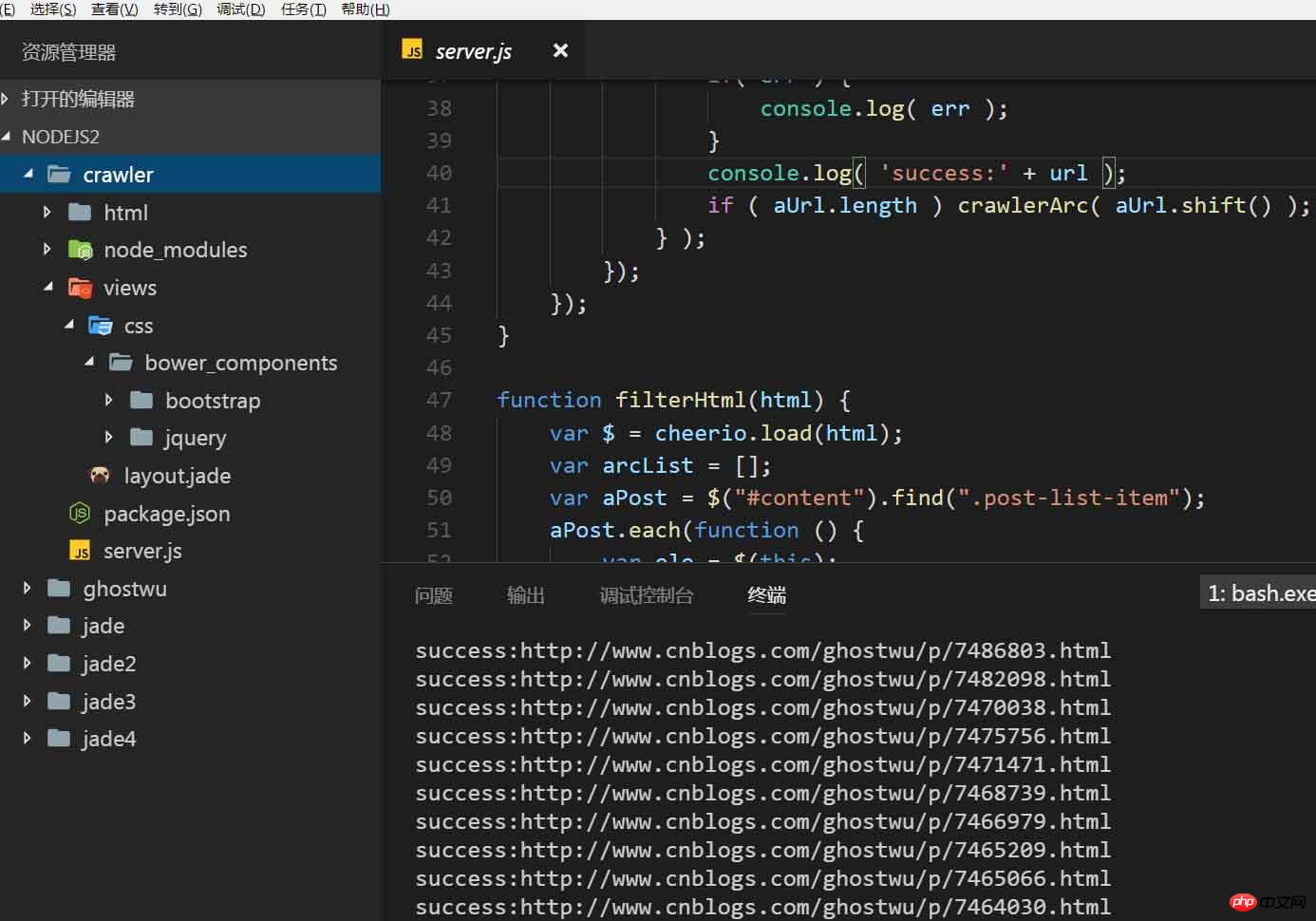
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
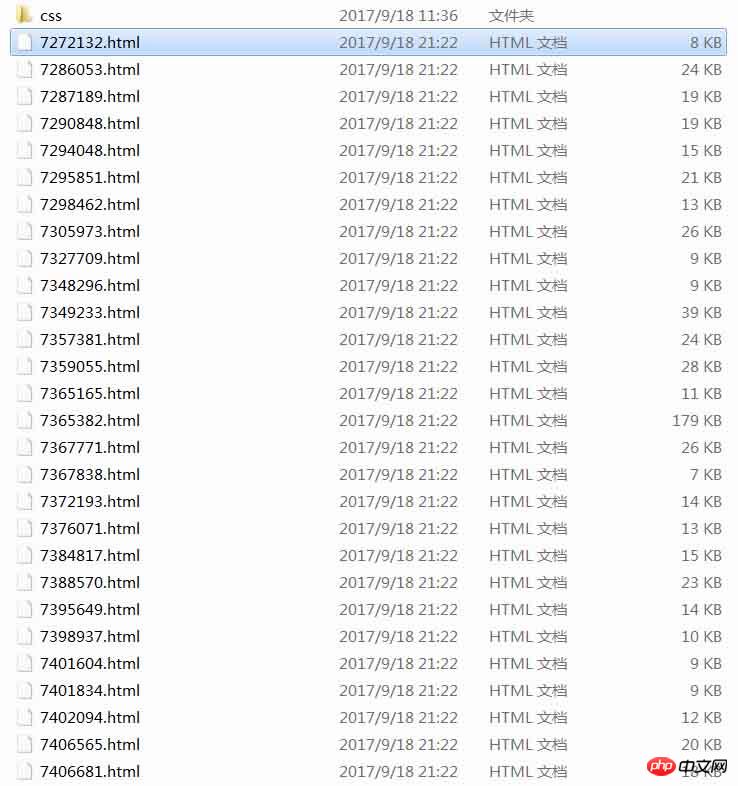
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
function filterHtml(html) {
var $ = cheerio.load(html);
var arcList = [];
var aPost = $("#content").find(".post-list-item");
aPost.each(function () {
var ele = $(this);
var title = ele.find("h2 a").text();
var url = ele.find("h2 a").attr("href");
ele.find(".c_b_p_desc a").remove();
var entry = ele.find(".c_b_p_desc").text();
ele.find("small a").remove();
var listTime = ele.find("small").text();
var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
listTime = listTime.match(re)[0];
arcList.push({
title: title,
url: url,
entry: entry,
listTime: listTime
});
});
return arcList;
}
function nextPage( html ){
var $ = cheerio.load(html);
var nextUrl = $("#pager a:last-child").attr('href');
if ( !nextUrl ) return getArcUrl( aList );
var curPage = $("#pager .current").text();
if( !curPage ) curPage = 1;
var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
if ( curPage < nextPage ) crawler( nextUrl );
}
function crawler(url) {
http.get(url, function (res) {
var html = '';
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
aList.push( filterHtml(html) );
nextPage( html );
});
});
}
function getArcUrl( arcList ){
for( var key in arcList ){
for( var k in arcList[key] ){
aUrl.push( arcList[key][k]['url'] );
}
}
crawlerArc( aUrl.shift() );
}
var url = 'http://www.cnblogs.com/ghostwu/';
crawler( url );