這次帶給大家javascript trie前綴樹使用詳解,使用javascript trie前綴樹的注意事項有哪些,以下是實戰案例,一起來看一下。
引子
Trie樹(來自單字retrieval),又稱前綴字,單字尋找樹,字典樹,是一種樹形結構,是一種哈希樹的變種,是一種用於快速檢索的多叉樹結構。
它的優點是:最大限度地減少無謂的字串比較,查詢效率比哈希表高。
Trie的核心思想是空間換時間。利用字串的公共前綴來降低查詢時間的開銷以達到提高效率的目的。
Trie樹也有它的缺點, 假定我們只對字母與數字進行處理,那麼每個節點至少有52+10個子節點。為了節省內存,我們可以用鍊錶或數組。在JS中我們直接用數組,因為JS的數組是動態的,自帶優化。
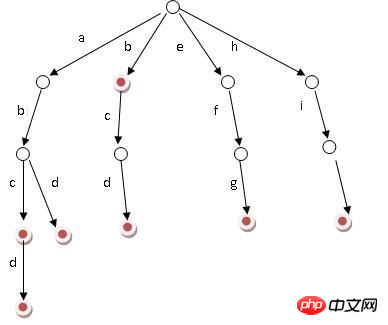
基本性質
#根節點不包含字符,除根節點外的每一個子節點都包含一個字元
從根節點到某一節點。路徑上經過的字元連接起來,就是該節點對應的字串
每個節點的所有子節點所包含的字元都不相同
程式實作
// by 司徒正美
class Trie {
constructor() {
this.root = new TrieNode();
}
isValid(str) {
return /^[a-z1-9]+$/i.test(str);
}
insert(word) {
// addWord
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
var node = cur.son[c];
if (node == null) {
var node = (cur.son[c] = new TrieNode());
node.value = word.charAt(i);
node.numPass = 1; //有N个字符串经过它
} else {
node.numPass++;
}
cur = node;
}
cur.isEnd = true; //樯记有字符串到此节点已经结束
cur.numEnd++; //这个字符串重复次数
return true;
} else {
return false;
}
}
remove(word){
if (this.isValid(word)) {
var cur = this.root;
var array = [], n = word.length
for (var i = 0; i < n; i++) {
var c = word.charCodeAt(i);
c = this.getIndex(c)
var node = cur.son[c];
if(node){
array.push(node)
cur = node
}else{
return false
}
}
if(array.length === n){
array.forEach(function(){
el.numPass--
})
cur.numEnd --
if( cur.numEnd == 0){
cur.isEnd = false
}
}
}else{
return false
}
}
preTraversal(cb){//先序遍历
function preTraversalImpl(root, str, cb){
cb(root, str);
for(let i = 0,n = root.son.length; i < n; i ++){
let node = root.son[i];
if(node){
preTraversalImpl(node, str + node.value, cb);
}
}
}
preTraversalImpl(this.root, "", cb);
}
// 在字典树中查找是否存在某字符串为前缀开头的字符串(包括前缀字符串本身)
isContainPrefix(word) {
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return false;
}
}
return true;
} else {
return false;
}
}
isContainWord(str) {
// 在字典树中查找是否存在某字符串(不为前缀)
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return false;
}
}
return cur.isEnd;
} else {
return false;
}
}
countPrefix(word) {
// 统计以指定字符串为前缀的字符串数量
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return 0;
}
}
return cur.numPass;
} else {
return 0;
}
}
countWord(word) {
// 统计某字符串出现的次数方法
if (this.isValid(word)) {
var cur = this.root;
for (var i = 0; i < word.length; i++) {
var c = word.charCodeAt(i);
c -= 48; //减少”0“的charCode
if (cur.son[c]) {
cur = cur.son[c];
} else {
return 0;
}
}
return cur.numEnd;
} else {
return 0;
}
}
}
class TrieNode {
constructor() {
this.numPass = 0;//有多少个单词经过这节点
this.numEnd = 0; //有多少个单词就此结束
this.son = [];
this.value = ""; //value为单个字符
this.isEnd = false;
}
}我們將重點來看TrieNode與Trie的insert方法。 由於字典樹是主要用在詞頻統計,因此它的節點屬性比較多, 包含了numPass, numEnd但非常重要的屬性。
insert方法是用來插入重詞,在開始之前,我們必須判定單字是否合法,不能出現 特殊字元與空白。插入時是打散了一個個字元放入每個節點。每經過一個節點都要修改numPass。
優化
現在我們每個方法中,都有一個c=-48的操作,其實數字與大寫字母與小寫字母間其實還有其他字符的,這樣會造成無謂的空間的浪費
// by 司徒正美
getIndex(c){
if(c < 58){//48-57
return c - 48
}else if(c < 91){//65-90
return c - 65 + 11
}else {//> 97
return c - 97 + 26+ 11
}
}然後相關方法將c-= 48改成c = this.getIndex(c)即可
##測試
var trie = new Trie();
trie.insert("I");
trie.insert("Love");
trie.insert("China");
trie.insert("China");
trie.insert("China");
trie.insert("China");
trie.insert("China");
trie.insert("xiaoliang");
trie.insert("xiaoliang");
trie.insert("man");
trie.insert("handsome");
trie.insert("love");
trie.insert("Chinaha");
trie.insert("her");
trie.insert("know");
var map = {}
trie.preTraversal(function(node, str){
if(node.isEnd){
map[str] = node.numEnd
}
})
for(var i in map){
console.log(i+" 出现了"+ map[i]+" 次")
}
console.log("包含Chin(包括本身)前缀的单词及出现次数:");
//console.log("China")
var map = {}
trie.preTraversal(function(node, str){
if(str.indexOf("Chin") === 0 && node.isEnd){
map[str] = node.numEnd
}
})
for(var i in map){
console.log(i+" 出现了"+ map[i]+" 次")
}
Trie樹及其它資料結構的比較
Trie樹與二元搜尋樹
二元搜尋樹應該是我們最早接觸的樹結構了,我們知道,當資料規模為n時,二元搜尋樹插入、尋找、刪除操作的時間複雜度通常只有O(log n),最壞情況下整棵樹所有的節點都只有一個子節點,退變成一個線性表,此時插入、查找、刪除操作的時間複雜度是O(n)。 通常情況下,Trie樹的高度n要遠大於搜尋字串的長度m,故查找操作的時間複雜度通常為O(m),最壞情況下的時間複雜度才為O (n)。很容易看出,Trie樹最壞情況下的查找也快過二元搜尋樹。 文中Trie樹都是拿字符串舉例的,其實它本身對key的適宜性是有嚴格要求的,如果key是浮點數的話,就可能導致整個Trie樹巨長無比,節點可讀性也非常差,這種情況下是不適宜用Trie樹來保存資料的;而二元搜尋樹就不存在這個問題。Trie樹與Hash表#
考慮一下Hash衝突的問題。 Hash表通常我們說它的複雜度是O(1),其實嚴格說起來這是接近完美的Hash表的複雜度,另外還需要考慮到hash函數本身需要遍歷搜尋字串,複雜度是O(m )。在不同鍵被映射到「同一個位置」(考慮closed hashing,這「同一個位置」可以由一個普通鍊錶來取代)的時候,需要進行查找的複雜度取決於這「同一個位置」下節點的數目,因此,在最壞情況下,Hash表也是可以成為一張單向鍊錶的。
Trie樹可以比較方便地按照key的字母序來排序(整棵樹先序遍歷一次就好了),這跟絕大多數Hash表是不同的(Hash表一般對於不同的key來說是無序的)。
在較理想的情況下,Hash表可以以O(1)的速度迅速命中目標,如果這張表非常大,需要放到磁碟上的話,Hash表的查找訪問在理想情況下只需要一次即可;但是Trie樹存取磁碟的數目需要等於節點深度。
很多時候Trie樹比Hash表需要更多的空間,我們考慮這種一個節點存放一個字元的情況的話,在保存一個字串的時候,沒有辦法把它保存成一個單獨的區塊。 Trie樹的節點壓縮可以明顯緩解這個問題,後面會講到。
Trie樹的改良
#位元Trie樹(Bitwise Trie)
原理上和普通Trie樹差不多,只不過普通Trie樹儲存的最小單位是字符,但是Bitwise Trie存放的是位而已。位元資料的存取由CPU指令一次直接實現,對於二進位數據,它理論上要比普通Trie樹快。
節點壓縮。
分支壓縮:對於穩定的Trie樹,基本上都是尋找和讀取操作,完全可以把一些分支進行壓縮。例如,前圖中最右側分支的inn可以直接壓縮成一個節點“inn”,而不需要作為一棵常規的子樹存在。 Radix樹就是根據這個原理來解決Trie樹過深的問題。
節點映射表:這種方式也是在Trie樹的節點可能已經幾乎完全確定的情況下採用的,針對Trie樹中節點的每一個狀態,如果狀態總數重複很多的話,透過一個元素為數字的多維數組(例如Triple Array Trie)來表示,這樣儲存Trie樹本身的空間開銷會小一些,雖說引入了一張額外的映射表。
前綴樹的應用
前綴樹還是很好理解,它的應用也是非常廣泛的。
(1)字串的快速檢索
字典樹的查詢時間複雜度是O(logL),L是字串的長度。所以效率還是比較高的。字典樹的效率比hash表高。
(2)字串排序
從上圖我們很容易看出單字是排序的,先遍歷字母序在前面。減少了沒必要的公共子字串。
(3)最長公共前綴
inn和int的最長公共前綴是in,遍歷字典樹到字母n時,此時這些單字的公共前綴是in。
(4)自動比對前綴顯示字尾
我們使用字典或是搜尋引擎的時候,輸入appl,後面會自動顯示一堆前綴是appl的東東吧。那麼有可能是透過字典樹實現的,前面也說了字典樹可以找到公共前綴,我們只需要把剩餘的後綴遍歷顯示出來即可。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持腳本之家。
相信看了本文案例你已經掌握了方法,更多精彩請關注php中文網其它相關文章!
推薦閱讀:
#以上是javascript trie前綴樹使用詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















