

詳解分類評估指標與迴歸評估指標以及Python程式碼實現

這篇文章介紹的內容是詳解分類評價指標和回歸評價指標以及Python代碼實現,有著一定的參考價值,現在分享給大家,有需要的朋友可以參考一下。
1、概念
效能衡量(評估)指標,主分為兩大類:
1)分類評估指標(classification),主要分析,離散的,整數的。其具體指標包括accuracy(準確率),precision(精確率),recall(召回率),F值,P-R曲線,ROC曲線和AUC。
2)回歸評估指標(regression),主要分析整數和實數之間的關係。其特定指標包括可釋方差分數(explianed_variance_score),平均絕對誤差MAE(mean_absolute_error),均方誤差MSE(mean-squared_error),均方根差RMSE,交叉熵lloss(Log loss,cross-entropy loss),R方值(確定係數,r2_score)。
1.1、前提
假設只有兩類-正類(positive)和負類(negative),通常以關注的類為正類,其他類為負類(故多類問題亦可歸納為兩類)
混淆矩陣(Confusion matrix)如下
| 實際類別 | 預測類別 | |||
| 負 | 總結 | |||
| #TP | FN | P(實際上為正) | ||
| ##FP | TN | N(實際為負數) | ||
2、評估指標(效能衡量)
2.1、分類評估指標
2.1.1 值指標-Accuracy、Precision、Recall、F值
| Accuracy(準確率) | #Precision(精確率) | Recall(召回率) | F值 | |
| 正確分類的樣本數與總樣本數之比(預測為垃圾簡訊中真正的垃圾簡訊的比例) | 判定為正例中真正正例數與判定為正例數之比(所有真的垃圾簡訊被分類求正確找出來的比例) | 被正確判定為正例數與總正例數之比 | 準確率與召回率的調和平均F | -score |
| accuracy= |
#precision= |
#recall= |
|
#F - score =
|
1.precision也常稱為查準率,recall稱為查全率
2.比較常用的是F1,
#python3.6程式碼實作:
#调用sklearn库中的指标求解from sklearn import metricsfrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import average_precision_scorefrom sklearn.metrics import accuracy_score#给出分类结果y_pred = [0, 1, 0, 0]
y_true = [0, 1, 1, 1]
print("accuracy_score:", accuracy_score(y_true, y_pred))
print("precision_score:", metrics.precision_score(y_true, y_pred))
print("recall_score:", metrics.recall_score(y_true, y_pred))
print("f1_score:", metrics.f1_score(y_true, y_pred))
print("f0.5_score:", metrics.fbeta_score(y_true, y_pred, beta=0.5))
print("f2_score:", metrics.fbeta_score(y_true, y_pred, beta=2.0))2.1.2 相關曲線-P-R曲線、ROC曲線及AUC值
1)P-R曲線
步驟:
1、從高到低將」score」值排序並依序作為閾值threshold;
2、對於每個閾值,」score」值大於或等於這個threshold的測試樣本被認為正例,其他為負例。從而形成一組預測數。
eg. 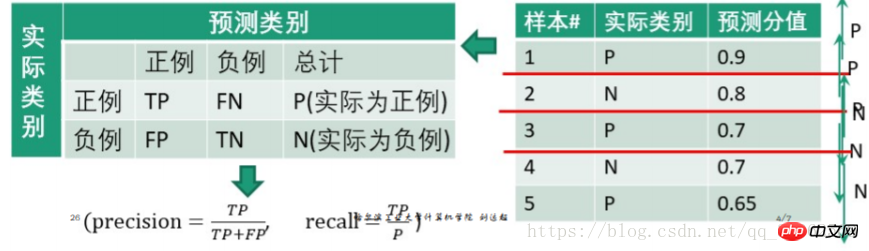
以0.9為閾值,則第1個測試樣本為正例,2、3、4、5為負例
得到
| 預測為正例 | 預測為負例 | 總計 | |
| ##正例(score大於閾值) | 0.9 | 0.1 | 1 |
| 負例(score小於閾值) 0.2 0.3 0.3 0.35 = 1.15 0.8 0.7 0.7 0.65 = 2.85#4 #4##precision= | |||
recall=
 在閾值以下的部分,當作負例,則預測為負例的取值情況是正確預測值,即如果本身是正例,則取TP;如果本身是負例,則取TN,其都為預測分值。
在閾值以下的部分,當作負例,則預測為負例的取值情況是正確預測值,即如果本身是正例,則取TP;如果本身是負例,則取TN,其都為預測分值。
python實作偽代碼
#precision和recall的求法如上
#主要介绍一下python画图的库
import matplotlib.pyplot ad plt
#主要用于矩阵运算的库
import numpy as np#导入iris数据及训练见前一博文
...
#加入800个噪声特征,增加图像的复杂度
#将150*800的噪声特征矩阵与150*4的鸢尾花数据集列合并
X = np.c_[X, np.random.RandomState(0).randn(n_samples, 200*n_features)]
#计算precision,recall得到数组
for i in range(n_classes):
#计算三类鸢尾花的评价指标, _作为临时的名称使用
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:,i])#plot作图plt.clf()
for i in range(n_classes):
plt.plot(recall[i], precision[i])
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("Recall")
plt.ylabel("Precision")
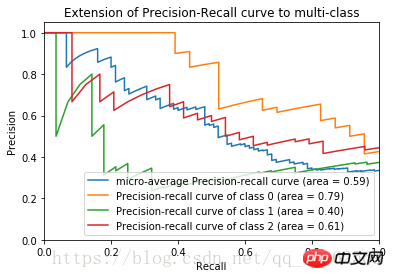
plt.show()將上述程式碼補充完整後得到鳶尾花資料集的P-R曲線

2)ROC曲線
 橫軸:假正例率fp rate = FP / N
橫軸:假正例率fp rate = FP / N 縱軸:真正例率tp rate = TP / N
步驟:
 1、從高到低將」score」值排序並依序作為閾值threshold;
1、從高到低將」score」值排序並依序作為閾值threshold; 2、對於每個閾值,」score」值大於或等於這個threshold的測試樣本被認為是正例,其他為負例。從而形成一組預測數。

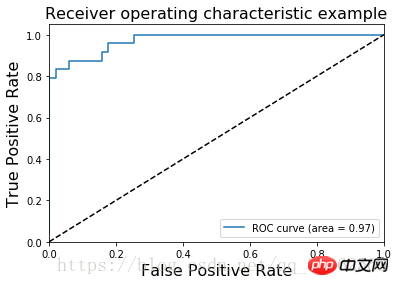
同P-R曲線計算類似,不再贅述 鳶尾花資料集的ROC圖像為 ########## AUC(Area Under Curve)定義為ROC曲線下的面積 ### AUC值提供了分類器的一個整體數值。通常AUC越大,分類器更好,取值為[0, 1]#########2.2、回歸評價指標######1)可釋方差分數###### ###2)平均絕對誤差MAE (Mean absolute error) #########3)均方差MSE(Mean squared error) ################4) logistics回歸損失#########5)一致性評估- pearson相關係數法##########python程式碼實作###
from sklearn.metrics import log_loss log_loss(y_true, y_pred)from scipy.stats import pearsonr pearsonr(rater1, rater2)from sklearn.metrics import cohen_kappa_score cohen_kappa_score(rater1, rater2)
以上是詳解分類評估指標與迴歸評估指標以及Python程式碼實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
VS Code 擴展存在惡意風險,例如隱藏惡意代碼、利用漏洞、偽裝成合法擴展。識別惡意擴展的方法包括:檢查發布者、閱讀評論、檢查代碼、謹慎安裝。安全措施還包括:安全意識、良好習慣、定期更新和殺毒軟件。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
