
在學習python的時候,一定會遇到網站內容是透過ajax動態請求、非同步刷新產生的json資料的情況,並且透過python使用之前爬取靜態網頁內容的方式是不可以實現的,所以這篇文章將要講述如果在python中爬取ajax動態產生的資料。
在學習python的時候,一定會遇到網站內容是透過ajax動態請求、非同步刷新產生的json資料的情況,並且透過python使用之前爬取靜態網頁內容的方式是不可以實現的,所以這篇文章將要講述如果在python中爬取ajax動態產生的資料。
至於讀取靜態網頁內容的方式,有興趣的可以查看本文內容。
這裡我們以爬取淘寶評論為例子講解如何去做到的。
這裡主要分為了四個步驟:
一獲取淘寶評論時,ajax請求連結(url)
##二取得該ajax請求傳回的json資料
#三使用python解析json資料


 ##四儲存解析的結果
##四儲存解析的結果

 取得淘寶註解時,ajax請求連結(url)這裡我使用的是Chrome瀏覽器來完成的。打開淘寶鏈接,在搜尋框中搜尋一個商品,例如“鞋子”,這裡我們選擇第一個商品。
取得淘寶註解時,ajax請求連結(url)這裡我使用的是Chrome瀏覽器來完成的。打開淘寶鏈接,在搜尋框中搜尋一個商品,例如“鞋子”,這裡我們選擇第一個商品。
 然後跳到了一個新的網頁。這裡由於我們需要爬取用戶的評論,所以我們點擊累計評價。
然後跳到了一個新的網頁。這裡由於我們需要爬取用戶的評論,所以我們點擊累計評價。
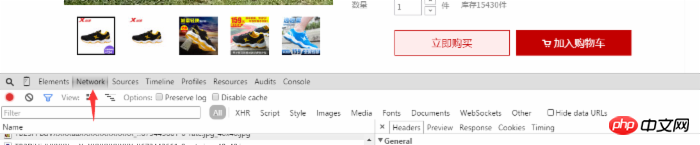
然後我們就可以看到使用者對該商品的評價了,這時我們在網頁中右鍵選擇審查元素(或直接使用F12開啟)並且選取Network選項,如圖所示:
我們在用戶評論中,翻到底部點擊下一頁或第二頁,我們在Network中看到動態添加了幾項,我們選擇開頭為list_detail_rate.htm?itemId=35648967399的一項。
然後點擊該選項,我們可以在右邊選項框中看到有關該連結的信息,我們要複製Request URL中的連結內容。我們在瀏覽器的地址欄中輸入剛才我們獲得url鏈接,打開後我們會發現頁面返回的是我們所需要的數據,不過顯得很亂,因為這是json數據。
二取得該ajax請求回傳的json資料
下一步,我們就要取得url中的json數據了。我所使用的python編輯器是pycharm,下面看python程式碼:
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import requests url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143' #这里的url比较长 content=requests.get(url).content
print content #列印出來的內容就是我們之前在網頁中取得到的json數據。包括用戶的評論。
這裡的content就是我們所需要的json數據,下一步就需要我們解析這些個json數據了。
三使用python解析json資料
## -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import re
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143'
cont=requests.get(url).content
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}')
content=rex.findall(cont)[0]
con=json.loads(content,"gbk")
count=len(con['rateDetail']['rateList'])
for i in xrange(count):
print con['rateDetail']['rateList'][i]['appendComment']['content']四 儲存解析的結果
這裡使用者可以將使用者的評論資訊儲存到本機,例如儲存為csv格式。
以上就是本文的全部所述,希望大家喜歡。
以上是透過抓取淘寶評論為例講解Python爬取ajax動態產生的資料(經典)的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















