
這篇文章介紹的內容是關於php面試的總結,有著一定的參考價值,現在分享給大家,有需要的朋友可以參考一下
##id
select_type
#table
## rows

MySQL版本:

CREATE TABLE people(
id bigint auto_increment primary key,
zipcode char(32) not null default '',
address varchar(128) not null default '',
lastname char(64) not null default '',
firstname char(64) not null default '',
birthdate char(10) not null default '' );
CREATE TABLE people_car(
people_id bigint,
plate_number varchar(16) not null default '',
engine_number varchar(16) not null default '',
lasttime timestamp );

insert into people (zipcode,address,lastname,firstname,birthdate) values ('230031','anhui','zhan','jindong','1989-09-15'), ('100000','beijing','zhang','san','1987-03-11'), ('200000','shanghai','wang','wu','1988-08-25') insert into people_car (people_id,plate_number,engine_number,lasttime) values (1,'A121311','12121313','2013-11-23 :21:12:21'), (2,'B121311','1S121313','2011-11-23 :21:12:21'), (3,'C121311','1211SAS1','2012-11-23 :21:12:21')
#建立索引用來測試
alter table people add key(zipcode,firstname,lastname);
先從一個最簡單的查詢開始:
Query-1 explain select zipcode,firstname,lastname from people;
EXPLAIN輸出結果共有id,select_type,table,type,possible_keys,key,key_len,ref,rows和Extra幾列。
id
Query-2 explain select zipcode from (select * from people a) b;
#id是用來順序標識整個查詢中SELELCT 語句的,透過上面這個簡單的巢狀查詢可以看到id越大的語句越先執行。該值可能為NULL,如果這一行用來說明的是其他行的聯合結果,例如UNION語句:
Query-3 explain select * from people where zipcode = 100000 union select * from people where zipcode = 200000;
select_type
#SELECT語句的型別,可以有以下幾種。
SIMPLE
#最簡單的SELECT查詢,沒有使用UNION或子查詢。見Query-1。
PRIMARY
在巢狀的查詢中是最外層的SELECT語句,在UNION查詢中是最前面的SELECT語句。見Query-2和Query-3
。#########UNION###############UNION第二個以及後面的SELECT語句。見###Query-3###。 ############ ###############DERIVED###############衍生表SELECT語句中FROM子句中的SELECT語句。見###Query-2###。 ############ ###############UNION RESULT#########
一个UNION查询的结果。见Query-3。
DEPENDENT UNION
顾名思义,首先需要满足UNION的条件,及UNION中第二个以及后面的SELECT语句,同时该语句依赖外部的查询。
Query-4 explain select * from people where id in (select id from people where zipcode = 100000 union select id from people where zipcode = 200000 );

Query-4中select id from people where zipcode = 200000的select_type为DEPENDENT UNION。你也许很奇怪这条语句并没有依赖外部的查询啊。
这里顺带说下MySQL优化器对IN操作符的优化,优化器会将IN中的uncorrelated subquery优化成一个correlated subquery(关于correlated subquery参见这里)。
SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
类似这样的语句会被重写成这样:
SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
所以Query-4实际上被重写成这样:
Query-5 explain select * from people o where exists ( select id from people where zipcode = 100000 and id = o.id union select id from people where zipcode = 200000 and id = o.id);

题外话:有时候MySQL优化器这种太过“聪明” 的做法会导致WHERE条件包含IN()的子查询语句性能有很大损失。可以参看《高性能MySQL第三版》6.5.1关联子查询一节。
SUBQUERY
子查询中第一个SELECT语句。
Query-6 explain select * from people where id = (select id from people where zipcode = 100000);

DEPENDENT SUBQUERY
和DEPENDENT UNION相对UNION一样。见Query-5。
除了上述几种常见的select_type之外还有一些其他的这里就不一一介绍了,不同MySQL版本也不尽相同。
显示的这一行信息是关于哪一张表的。有时候并不是真正的表名。
Query-7 explain select * from (select * from (select * from people a) b ) c;

可以看到如果指定了别名就显示的别名。
<strong><em>N</em></strong>>N就是id值,指该id值对应的那一步操作的结果。
还有
注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。
type列很重要,是用来说明表与表之间是如何进行关联操作的,有没有使用索引。MySQL中“关联”一词比一般意义上的要宽泛,MySQL认为任何一次查询都是一次“关联”,并不仅仅是一个查询需要两张表才叫关联,所以也可以理解MySQL是如何访问表的。主要有下面几种类别。
const
当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。const只会用在将常量和主键或唯一索引进行比较时,而且是比较所有的索引字段。people表在id上有一个主键索引,在(zipcode,firstname,lastname)有一个二级索引。因此Query-8的type是const而Query-9并不是:
Query-8 explain select * from people where id=1;

Query-9 explain select * from people where zipcode = 100000;

注意下面的Query-10也不能使用const table,虽然也是主键,也只会返回一条结果。
Query-10 explain select * from people where id >2;

system
这是const连接类型的一种特例,表仅有一行满足条件。
Query-11 explain select * from (select * from people where id = 1 )b;

eq_ref
eq_ref类型是除了const外最好的连接类型,它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。
需要注意InnoDB和MyISAM引擎在这一点上有点差别。InnoDB当数据量比较小的情况type会是All。我们上面创建的people 和 people_car默认都是InnoDB表。
Query-12 explain select * from people a,people_car b where a.id = b.people_id;

我们创建两个MyISAM表people2和people_car2试试:
CREATE TABLE people2( id bigint auto_increment primary key, zipcode char(32) not null default '', address varchar(128) not null default '', lastname char(64) not null default '', firstname char(64) not null default '', birthdate char(10) not null default '' ) ENGINE = MyISAM; CREATE TABLE people_car2( people_id bigint, plate_number varchar(16) not null default '', engine_number varchar(16) not null default '', lasttime timestamp )ENGINE = MyISAM;
Query-13 explain select * from people2 a,people_car2 b where a.id = b.people_id;

我想这是InnoDB对性能权衡的一个结果。
eq_ref可以用于使用 = 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。如果关联所用的索引刚好又是主键,那么就会变成更优的const了:
Query-14 explain select * from people2 a,people_car2 b where a.id = b.people_id and b.people_id = 1;

ref
这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。
为了说明我们重新建立上面的people2和people_car2表,仍然使用MyISAM但是不给id指定primary key。然后我们分别给id和people_id建立非唯一索引。
reate index people_id on people2(id); create index people_id on people_car2(people_id);
然后再执行下面的查询:
Query-15 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id > 2;

Query-16 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id = 2;

Query-17 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-18 explain select * from people2 where id = 1;

看上面的Query-15,Query-16和Query-17,Query-18我们发现MyISAM在ref类型上的处理也是有不同策略的。
对于ref类型,在InnoDB上面执行上面三条语句结果完全一致。
fulltext
链接是使用全文索引进行的。一般我们用到的索引都是B树,这里就不举例说明了。
ref_or_null
该类型和ref类似。但是MySQL会做一个额外的搜索包含NULL列的操作。在解决子查询中经常使用该联接类型的优化。(详见这里)。
Query-19 mysql> explain select * from people2 where id = 2 or id is null;

Query-20 explain select * from people2 where id = 2 or id is not null;

注意Query-20使用的并不是ref_or_null,而且InnnoDB这次表现又不相同(数据量大的情况下有待验证)。
index_merger
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。关于索引合并优化看这里。
unique_subquery
该类型替换了下面形式的IN子查询的ref:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery
该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:<br/>
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range:
Query-21 explain select * from people where id = 1 or id = 2;
 <br/>
<br/>
注意在我的测试中:发现只有id是主键或唯一索引时type才会为range。
这里顺便挑剔下MySQL使用相同的range来表示范围查询和列表查询。
explain select * from people where id >1;

explain select * from people where id in (1,2);

但事实上这两种情况下MySQL如何使用索引是有很大差别的:
我们不是挑剔:这两种访问效率是不同的。对于范围条件查询,MySQL无法使用范围列后面的其他索引列了,但是对于“多个等值条件查询”则没有这个限制了。
——出自《高性能MySQL第三版》
index
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。这个类型通常的作用是告诉我们查询是否使用索引进行排序操作。
Query-22 explain select * from people order by id;

至于什么情况下MySQL会利用索引进行排序,等有时间再仔细研究。最典型的就是order by后面跟的是主键。
ALL
最慢的一種方式,即全表掃描。
總的來說:上面幾個連接類型的效能是依序遞減的(system>const),不同的MySQL版本、不同的儲存引擎甚至不同的資料量表現都可能不一樣。
possible_keys欄位指出MySQL能使用哪個索引在該表中找到行。
#key欄位顯示MySQL實際決定使用的鍵(索引)。如果沒有選擇索引,鍵是NULL。若要強制MySQL使用或忽略possible_keys欄位中的索引,在查詢中使用FORCE INDEX、USE INDEX或IGNORE INDEX。
key_len列顯示MySQL決定使用的鍵長度。如果鍵是NULL,則長度為NULL。使用的索引的長度。在不損失精確性的情況下,長度越短越好 。
#ref列顯示使用哪個欄位或常數與key一起從表中選擇行。 <br/>
rows
rows欄位顯示MySQL認為它執行查詢時必須檢查的行數。注意這是一個預估值。
Extra
#Extra是EXPLAIN輸出中另一個很重要的列,該列顯示MySQL在查詢過程中的一些詳細信息,包含的資訊很多,只選擇幾個重點的介紹下。
Using filesort
#MySQL有兩種方式可以產生有序的結果,透過排序作業或使用索引,當Extra中出現了Using filesort 說明MySQL使用了後者,但注意雖然叫filesort但並不是說明就是用了文件來進行排序,只要可能排序都是在內存裡完成的。大部分情況下利用索引排序比較快,所以一般這時也要考慮優化查詢了。
Using temporary
說明使用了暫存資料表,一般看到它說明查詢需要優化了,就算避免不了臨時表的使用也要盡量避免硬碟臨時表的使用。
Not exists
MYSQL優化了LEFT JOIN,一旦它找到了匹配LEFT JOIN標準的行, 就不再搜尋了。
Using index
說明查詢是覆寫了索引的,這是好事情。 MySQL直接從索引中過濾不需要的記錄並傳回命中的結果。這是MySQL服務層完成的,但無需再回表查詢記錄。
Using index condition
這是MySQL 5.6出來的新特性,叫做「索引條件推送」。簡單說一點就是MySQL原來在索引上是不能執行如like這樣的操作的,但是現在可以了,這樣減少了不必要的IO操作,但是只能用在二級索引上,詳情點這裡。
Using where
使用了WHERE從句來限制哪些行將與下一張表相符或是回傳給使用者。
注意
:Extra列出現Using where表示MySQL伺服器將儲存引擎傳回服務層以後再套用WHERE條件過濾。
EXPLAIN的輸出內容基本上介紹完了,它還有一個擴充的指令叫做EXPLAIN EXTENDED,主要是結合SHOW WARNINGS指令可以看到一些更多的資訊。一個比較有用的是可以看到MySQL優化器重構後的SQL。 ############ ######
Ok,EXPLAIN了解就到這裡,其實這些內容網路都有,只是自己實際操練下會印象更深刻。下一節會介紹SHOW PROFILE、慢查詢日誌以及一些第三方工具。
<br/>
OAuth是一個關於授權(authorization)的開放網路標準,在全世界廣泛應用,目前的版本是2.0版。
本文對OAuth 2.0的設計思路和運作流程,做一個簡明通俗的解釋,主要參考材料為RFC 6749。

為了理解OAuth的適用場合,讓我舉一個假設的例子。
有一個"雲端沖印"的網站,可以將使用者儲存在Google的照片,沖印出來。使用者為了使用該服務,必須讓"雲端沖印"讀取自己儲存在Google上的照片。

問題是只有得到使用者的授權,Google才會同意"雲端沖印"讀取這些照片。那麼,"雲端沖印"怎樣獲得使用者的授權呢?
傳統方法是,使用者將自己的Google使用者名稱和密碼,告訴"雲端沖印",後者就可以讀取使用者的照片了。這樣的做法有以下幾個嚴重的缺點。
(1)"雲端沖印"為了後續的服務,會保存使用者的密碼,這樣很不安全。
(2)Google不得不部署密碼登錄,而我們知道,單純的密碼登入並不安全。
(3)"雲端沖印"擁有了取得使用者儲存在Google所有資料的權力,使用者沒法限制"雲端沖印"授權的範圍和有效期限。
(4)使用者只有修改密碼,才能收回賦予"雲端沖印"的權力。但是這樣做,會使得其他所有獲得使用者授權的第三方應用程式全部失效。
(5)只要有一個第三方應用程式被破解,就會導致使用者密碼洩漏,以及所有被密碼保護的資料外洩。
OAuth就是為了解決上面這些問題而誕生的。
在詳細講解OAuth 2.0之前,需要先了解幾個專用名詞。它們對讀懂後面的講解,尤其是幾張圖,至關重要。
(1) Third-party application:第三方應用程序,本文中又稱"客戶端"(client),即上一節例子中的"雲沖印"。
(2)HTTP service:HTTP服務提供者,本文簡稱"服務提供者",即上一節範例中的Google。
(3)Resource Owner:資源擁有者,本文又稱為「使用者」(user)。
(4)User Agent:使用者代理,本文就是指瀏覽器。
(5)Authorization server:認證伺服器,即服務供應商專門用來處理認證的伺服器。
(6)Resource server:資源伺服器,也就是服務提供者存放使用者產生的資源的伺服器。它與認證伺服器,可以是同一台伺服器,也可以是不同的伺服器。
知道了上面這些名詞,就不難理解,OAuth的作用就是讓"客戶端"安全可控地獲取"用戶"的授權,與"服務商提供者"進行互動。
OAuth在"客戶端"與"服務提供者"之間,設定了一個授權層(authorization layer)。 "客戶端"不能直接登入"服務提供者",只能登入授權層,以此將使用者與客戶端區分開來。 "客戶端"登入授權層所用的令牌(token),與使用者的密碼不同。使用者可以在登入的時候,指定授權層令牌的權限範圍和有效期限。
"客戶端"登入授權層以後,"服務提供者"根據令牌的權限範圍和有效期,向"客戶端"開放使用者儲存的資料。
OAuth 2.0的運作流程如下圖,摘自RFC 6749。

(A)使用者開啟客戶端以後,客戶端要求使用者給予授權。
(B)使用者同意給予客戶端授權。
(C)客戶端使用上一個步驟所取得的授權,向認證伺服器申請令牌。
(D)認證伺服器對客戶端進行認證以後,確認無誤,同意發放令牌。
(E)客戶端使用令牌,向資源伺服器申請取得資源。
(F)资源服务器确认令牌无误,同意向客户端开放资源。
不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。
下面一一讲解客户端获取授权的四种模式。
客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。
授权码模式(authorization code)
简化模式(implicit)
密码模式(resource owner password credentials)
客户端模式(client credentials)
授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。

它的步骤如下:
(A)用户访问客户端,后者将前者导向认证服务器。
(B)用户选择是否给予客户端授权。
(C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。
(D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。
(E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。
下面是上面这些步骤所需要的参数。
A步骤中,客户端申请认证的URI,包含以下参数:
response_type:表示授权类型,必选项,此处的值固定为"code"
client_id:表示客户端的ID,必选项
redirect_uri:表示重定向URI,可选项
scope:表示申请的权限范围,可选项
state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。
下面是一个例子。
GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com登入後複製
C步骤中,服务器回应客户端的URI,包含以下参数:
code:表示授权码,必选项。该码的有效期应该很短,通常设为10分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端ID和重定向URI,是一一对应关系。
state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。
下面是一个例子。
HTTP/1.1 302 Found Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA &state=xyz登入後複製
D步骤中,客户端向认证服务器申请令牌的HTTP请求,包含以下参数:
grant_type:表示使用的授权模式,必选项,此处的值固定为"authorization_code"。
code:表示上一步获得的授权码,必选项。
redirect_uri:表示重定向URI,必选项,且必须与A步骤中的该参数值保持一致。
client_id:表示客户端ID,必选项。
下面是一个例子。
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb登入後複製
E步骤中,认证服务器发送的HTTP回复,包含以下参数:
access_token:表示访问令牌,必选项。
token_type:表示令牌类型,该值大小写不敏感,必选项,可以是bearer类型或mac类型。
expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。
refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。
scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。
下面是一个例子。
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }登入後複製登入後複製
从上面代码可以看到,相关参数使用JSON格式发送(Content-Type: application/json)。此外,HTTP头信息中明确指定不得缓存。
简化模式(implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。

它的步骤如下:
(A)客户端将用户导向认证服务器。
(B)用户决定是否给于客户端授权。
(C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。
(D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。
(E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。
(F)浏览器执行上一步获得的脚本,提取出令牌。
(G)浏览器将令牌发给客户端。
下面是上面这些步骤所需要的参数。
A步骤中,客户端发出的HTTP请求,包含以下参数:
response_type:表示授权类型,此处的值固定为"token",必选项。
client_id:表示客户端的ID,必选项。
redirect_uri:表示重定向的URI,可选项。
scope:表示权限范围,可选项。
state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。
下面是一个例子。
GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com登入後複製
C步骤中,认证服务器回应客户端的URI,包含以下参数:
access_token:表示访问令牌,必选项。
token_type:表示令牌类型,该值大小写不敏感,必选项。
expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。
scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。
state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。
下面是一个例子。
HTTP/1.1 302 Found Location: http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA &state=xyz&token_type=example&expires_in=3600登入後複製
在上面的例子中,认证服务器用HTTP头信息的Location栏,指定浏览器重定向的网址。注意,在这个网址的Hash部分包含了令牌。
根据上面的D步骤,下一步浏览器会访问Location指定的网址,但是Hash部分不会发送。接下来的E步骤,服务提供商的资源服务器发送过来的代码,会提取出Hash中的令牌。
密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。
在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。

它的步骤如下:
(A)用户向客户端提供用户名和密码。
(B)客户端将用户名和密码发给认证服务器,向后者请求令牌。
(C)认证服务器确认无误后,向客户端提供访问令牌。
B步骤中,客户端发出的HTTP请求,包含以下参数:
grant_type:表示授权类型,此处的值固定为"password",必选项。
username:表示用户名,必选项。
password:表示用户的密码,必选项。
scope:表示权限范围,可选项。
下面是一个例子。
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=password&username=johndoe&password=A3ddj3w登入後複製
C步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }登入後複製登入後複製
上面代码中,各个参数的含义参见《授权码模式》一节。
整个过程中,客户端不得保存用户的密码。
客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。

它的步骤如下:
(A)客户端向认证服务器进行身份认证,并要求一个访问令牌。
(B)认证服务器确认无误后,向客户端提供访问令牌。
A步骤中,客户端发出的HTTP请求,包含以下参数:
granttype:表示授权类型,此处的值固定为"clientcredentials",必选项。
scope:表示权限范围,可选项。
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=client_credentials登入後複製
认证服务器必须以某种方式,验证客户端身份。
B步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "example_parameter":"example_value" }登入後複製
上面代码中,各个参数的含义参见《授权码模式》一节。
如果用户访问的时候,客户端的"访问令牌"已经过期,则需要使用"更新令牌"申请一个新的访问令牌。
客户端发出更新令牌的HTTP请求,包含以下参数:
granttype:表示使用的授权模式,此处的值固定为"refreshtoken",必选项。
refresh_token:表示早前收到的更新令牌,必选项。
scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。
下面是一个例子。
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=refresh_token&refresh_token=tGzv3JOkF0XG5Qx2TlKWIA登入後複製
(完)
<br/>
yii2框架的安装我们在之前文章中已经提到下面我们开始了解YII2框架
强大的YII2框架网上指南:http://www.yii-china.com/doc/detail/1.html?postid=278或者<br/>
http://www.yiichina.com/doc/guide/2.0<br/>
Yii2的应用结构:<br/> <br/>
<br/>
目录篇:<br/>

<br/>
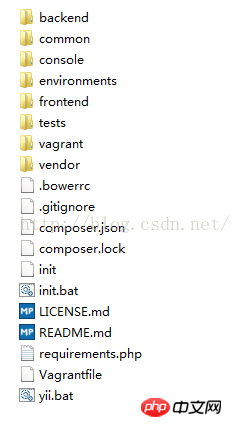 <br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/>
<br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/>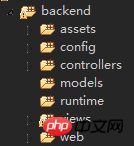 <br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend
<br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend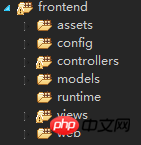 <br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/>
<br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/>
<br/> | <?phpdefined('YII_DEBUG') or define('YII_DEBUG', true); 登入後複製 defined('YII_ENV') or define('YII_ENV', 'dev'); 登入後複製 require(__DIR__ . '/../../vendor/autoload.php'); 登入後複製 require(__DIR__ . '/../../vendor/yiisoft/yii2/Yii.php'); 登入後複製 require(__DIR__ . '/../../common/config/bootstrap.php'); 登入後複製 require(__DIR__ . '/../config/bootstrap.php'); 登入後複製 $config = yii\helpers\ArrayHelper::merge( 登入後複製 require(__DIR__ . '/../../common/config/main.php'), 登入後複製 require(__DIR__ . '/../../common/config/main-local.php'), 登入後複製 require(__DIR__ . '/../config/main.php'), 登入後複製 require(__DIR__ . '/../config/main-local.php')); 登入後複製 $application = new yii\web\Application($config);$application->run(); 登入後複製 |
<br/>3.console控制台應用程式包含系統所需的控制台命令的。 <br/> 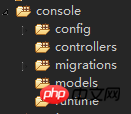 <br/><br/><br/>下面是全域公用資料夾4.common
<br/><br/><br/>下面是全域公用資料夾4.common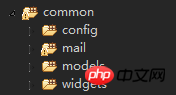 <br/>
<br/>
其中:
config 就是通用的配置,這些配置將作用於前後台和命令列。
mail 就是應用的前後台和命令列的與郵件相關的佈局檔案等。
models 就是前後台和命令列都可能用到的資料模型。這也是 common 中最主要的部分。
<br/> 公共的目錄(Common)中包含的檔案用於其它應用程式之間共用。例如,每一個應用程式可能需要存取該資料庫的使用 ActiveRecord。因此,我們可以將AR模型類別放置在公共(common)的目錄下。同樣,如果在多個應用程式中使用了一些輔助(helper )或零件類別(widget ),我們也應該把這些放置在公共目錄(common)下,以避免重複的程式碼。 正如我們很快就會解釋,應用程式也可以共享一部分的共用設定。因此,我們也可以儲存config目錄下共同的常見配置。 <br/>當開發一個大型專案開發週期長,我們需要不斷調整資料庫結構。基於這個原因,我們也可以使用資料庫遷移(DB migrations )功能來保持追蹤資料庫的變化。我們將所有 DB migrations(資料庫遷移)目錄同樣都放在公共(common)目錄下面。 <br/><br/>5.environment每個Yii環境就是一組設定文件, 包含了入口腳本 index.php和各類別設定檔。其實他們都放在/environments 目錄下面.<br/>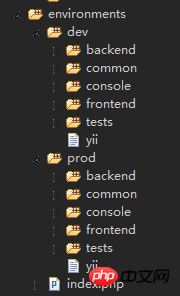 <br/> 從上面的目錄結構圖中,可以看到,環境目錄下有3個東東:
<br/> 從上面的目錄結構圖中,可以看到,環境目錄下有3個東東:
目錄 dev
#目錄 prod
#檔案 index.php
#其中, dev 和 prod 結構相同,分別又包含了4個目錄和1個檔案:
frontend 目錄,用於前台的應用,包含了存放檔案的 config目錄與存放web入口腳本的web 目錄
backend 目錄,用於後台應用,內容與 frontend 相同
#console 目錄,用於命令列應用,僅包含了 config 目錄,因為命令列應用不需要web入口腳本, 因此沒有 web 目錄。
common 目錄,用於各web應用程式和命令列應用通用的環境配置,僅包含了 config 目錄, 因為不同應用不可能共用相同的入口腳本。注意這個 common 的層級低於環境的層級,也就是說,他的通用,僅是某一環境下通用,並非所有環境下通用。
yii 文件,是命令列應用的入口腳本檔案。
對於分散於各處的 web 和 config 目錄而言,它們也是共通性的。
凡是 web 目錄,存放的都是web應用的入口腳本,一個 index.php 和一個測試版本的index-test.php
######## ##凡是 config 目錄,存放的,都是本地設定資訊 main-local.php 和 params-local.php#####<br/>6.vendor 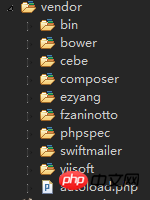 vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant
vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant  8.tests
8.tests  <br/>
<br/>
入口文件篇:
1、入口文件路径:<br/>
http://127.0.0.1/yii2/advanced/frontend/web/index.php
每个应用都有一个入口脚本 web/index.PHP,这是整个应用中唯一可以访问的 PHP 脚本。一个应用处理请求的过程如下:
1.用户向入口脚本 web/index.php 发起请求。 <br/>2.入口脚本加载应用配置并创建一个应用实例去处理请求。 <br/>3.应用通过请求组件解析请求的路由。 <br/>4.应用创建一个控制器实例去处理请求。 <br/>5.控制器创建一个操作实例并针对操作执行过滤器。 <br/>6.如果任何一个过滤器返回失败,则操作退出。 <br/>7.如果所有过滤器都通过,操作将被执行。 <br/>8.操作会加载一个数据模型,或许是来自数据库。<br/>9.操作会渲染一个视图,把数据模型提供给它。 <br/>10.渲染结果返回给响应组件。 <br/>11.响应组件发送渲染结果给用户浏览器
可以看到中间有模型-视图-控制器 ,即常说的MVC。入口脚本并不会处理请求,而是把请求交给了应用主体,在处理请求时,会用到控制器,如果用到数据库中的东西,就会去访问模型,如果处理请求完成,要返回给用户信息,则会在视图中回馈要返回给用户的内容。<br/>
2、为什么我们访问方法会出现url加密呢?
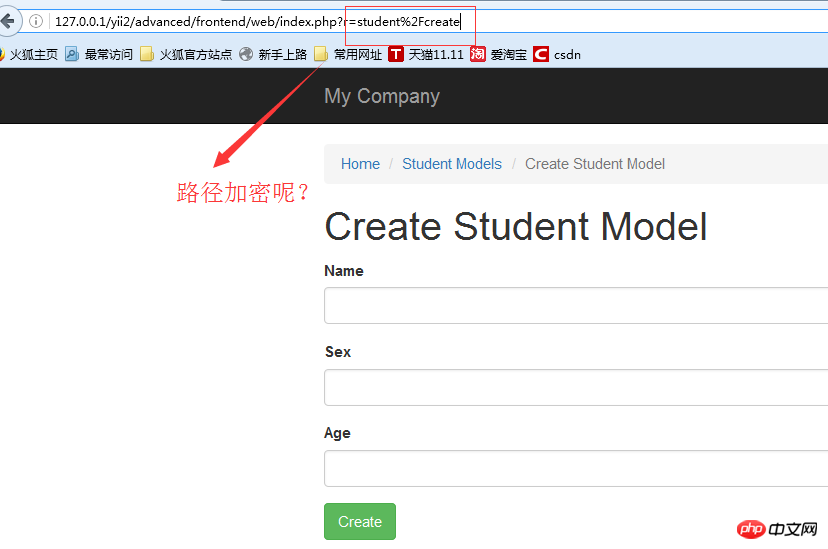 <br/>
<br/>
我们找到文件:vendor/yiisoft/yii2/web/UrlManager.php
return "$baseUrl/{$route}{$anchor}"; } else { $url = "$baseUrl?{$this->routeParam}=" . urlencode($route); if (!empty($params) && ($query = http_build_query($params)) !== '') { $url .= '&' . $query; } 将urlencode去掉就可以了 3、入口文件内容 入口文件流程如下:<br/>
MVC篇:
 <br/>
<br/>
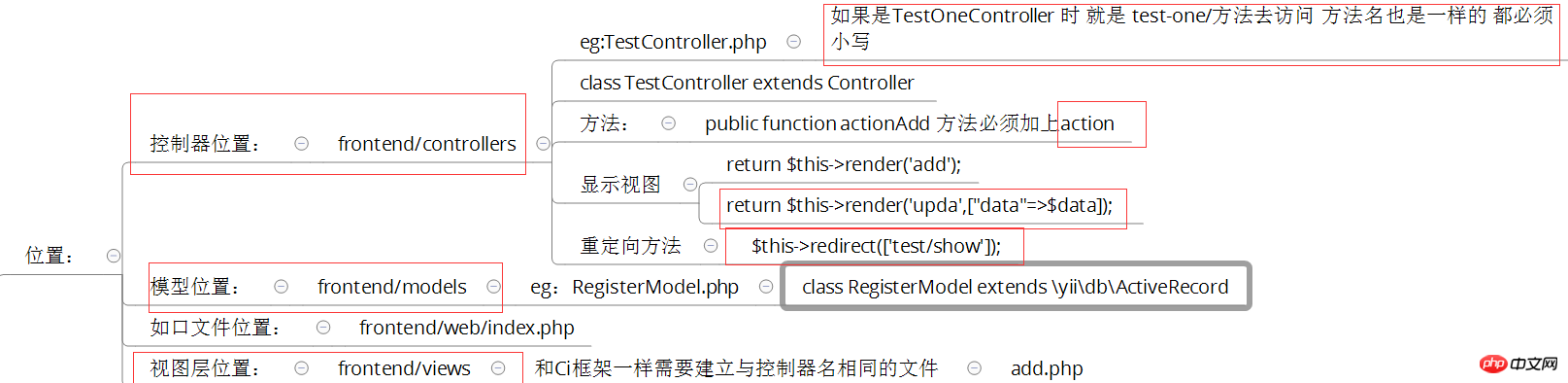
一、控制器详解:
1、修改默认控制器和方法
修改全局控制器:打开vendor/yiisoft/yii2/web/Application.php
eg:
public $defaultRoute = 'student/show'; 修改前台或者后台控制器: eg :打开 frontend/config/main.php 中
'params' => $params, 'defaultRoute' => 'login/show',
2、建立控制器示例:StudentController.php
//命名空间<br/>
namespace frontend\controllers;
<br/>
use Yii;
use yii\web\Controller; vendor/yiisoft/yii2/web/Controller.php (该控制器继承的是\yii\base\Controller) \web\Controller.php中干了些什么 1、默认开启了 授权防止csrf攻击 2、响应Ajax请求的视图渲染 3、将参数绑定到动作(就是看是不是属于框架自己定义的方法,如果没有定义就走run方法解析) 4、检测方法(beforeAction)beforeAction() 方法会触发一个 beforeAction 事件,在事件中你可以追加事件处理操作; 5、重定向路径 以及一些http Response(响应) 的设置
<br/>
use yii\db\Query; //使用query查询 use yii\data\Pagination;//分页 use yii\data\ActiveDataProvider;//活动记录 use frontend\models\ZsDynasty;//自定义数据模型
<br/><br/>
class StudentController extends Controller {
$request = YII::$app->request;//获取请求组件
$request->get('id');//获取get方法数据
$request->post('id');//获取post方法数据
$request->isGet;//判断是不是get请求
$request->isPost;//判断是不是post请求
$request->userIp;//获取用户IP地址
$res = YII::$app->response;//获取响应组件
$res->statusCode = '404';//设置状态码
$this->redirect('http://baodu.com');//页面跳转
$res->sendFile('./b.jpg');//文件下载
$session = YII::$app->session;
$session->isActive;//判断session是否开启
$session->open();//开启session
//设置session值
$session->set('user','zhangsan');//第一个参数为键,第二个为值
$session['user']='zhangsan';
//获取session值
$session->get('user');
$session['user'];
//删除session值
$session-remove('user');
unset($session['user']);
$cookies = Yii::$app->response->cookies;//获取cookie对象
$cookie_data = array('name'=>'user','value'=>'zhangsan')//新建cookie数据
$cookies->add(new Cookie($cookie_data));
$cookies->remove('id');//删除cookie
$cookies->getValue('user');//获取cookie//显示视图<br/> return $this->render('add'); 默认.php<br/> return $this->render('upda',["data"=>$data]); <br/><br/> } <br/>}<br/><br/>
二、模型层详解
简单模型建立:
<?php
namespace frontend\models;
class ListtModel extends \yii\db\ActiveRecord {
public static function tableName()
{
return 'listt';
}
public function one(){
return $this->find()->asArray()->one();
}
}<br/>
控制器引用
<?php namespace frontend\controllers; use Yii; use yii\web\controller; use frontend\models\ListtModel; class ListtController extends Controller{ public function actionAdd(){ $model=new ListtModel; $list=$model->one(); $data=$model->find()->asArray()->where("id=1")->all(); print_r($data); } } ?><br/><br/>
三、视图层详解首先在frontend下建立与控制器名一致的文件(小写)eg:student 在文件下建立文件<br/>
eg:index.php<br/>每一个controller对应一个view的文件夹,但是视图文件yii不要求是HTML,而是php,所以每个视图文件php里面都是视图片段: <br/>
<br/>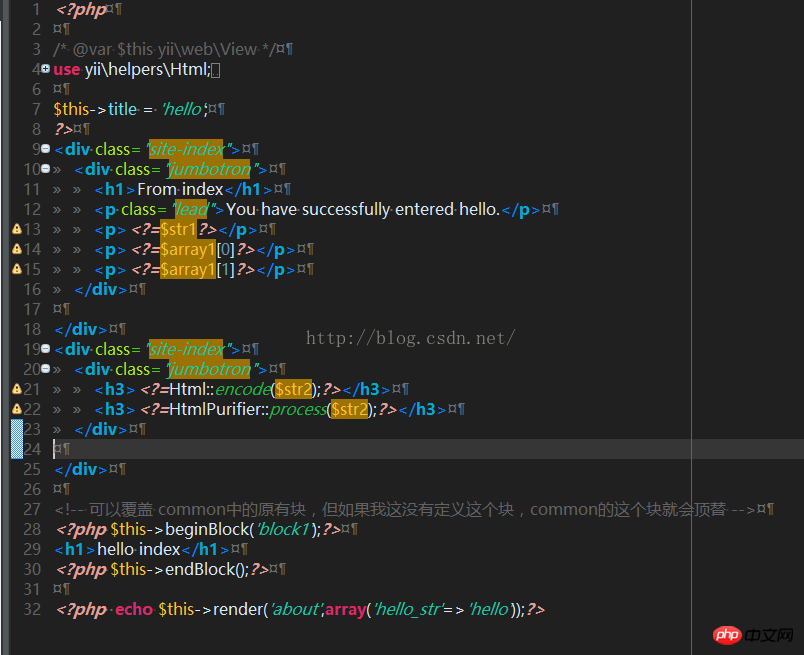 <br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器:
<br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器: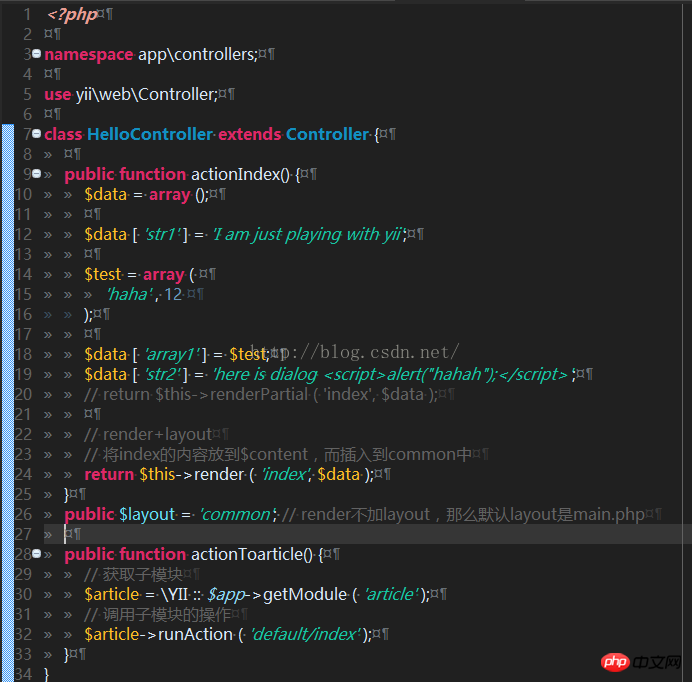 <br/>common.php:
<br/>common.php: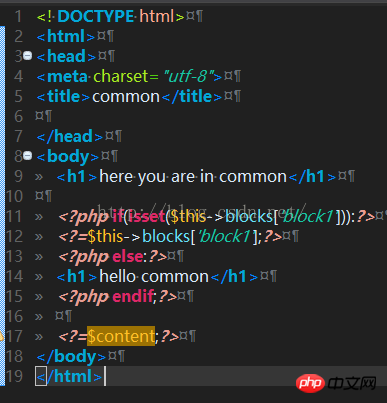 <br/><br/>layouts
<br/><br/>layouts 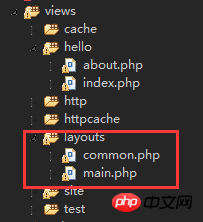 <br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>
<br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>
//$layout="main" 系统默认文件
//$layout=null 会找父类中默认定义的main public $layout="common";
public function actionIndex(){
return $this->render('index');
}
将以下内容插入 common中<?=$content;?> 它就是index文件中的内容
当然了,视图与模板之间还有数据传递以及继承覆盖的功能。<br/><br/><br/><br/><br/><br/>
YII2框架数据的运用
1、数据库连接
简介
一个项目根据需要会要求连接多个数据库,那么在yii2中如何链接多数据库呢?其实很简单,在配置文件中稍加配置即可完成。
配置
打开数据库配置文件common\config\main-local.php,在原先的db配置项下面添加db2,配置第二个数据库的属性即可
[php] view plain copy
'db' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii2', //数据库hyii2
'username' => 'root',
'password' => 'pwhyii2',
'charset' => 'utf8',
],
'db2' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii', //数据库hyii
'username' => 'root',
'password' => 'pwhyii',
'charset' => 'utf8',
],如上配置就可以完成yii2连接多个数据库的功能,但还是需要注意几个点
如果使用的数据库前缀 在建立模型时 这样: eg:这个库叫 haiyong_test return {{%test}}<br/>
应用
1.我们在hyii数据库中新建一个测试表test

2.通过gii生成模型,这里需要注意的就是数据库链接ID处要改成db2<br/>

3.查看生成的模型,比正常的model多了红色标记的地方

所以各位童鞋,如果使用多数据配置,在建db2的模型的时候,也要加上上图红色的代码。
好了,以上步骤就完成了,yii2的多数据库配置,配置完成之后可以和原因一样使用model或者数据库操作
2、数据操作:
<br/>方式一:使用createCommand()函数<br/>
增加 <br/>
获取自增id
$id=Yii::$app->db->getLastInsertID();
[php] view plain copy
Yii::$app->db->createCommand()->insert('user', [
'name' => 'test',
'age' => 30,
])->execute();批量插入数据
[php] view plain copy
Yii::$app->db->createCommand()->batchInsert('user', ['name', 'age'], [
['test01', 30],
['test02', 20],
['test03', 25],
])->execute();
删除[php] view plain copy
Yii::$app->db->createCommand()->delete('user', 'age = 30')->execute();修改
[php] view plain copy
Yii::$app->db->createCommand()->update('user', ['age' => 40], 'name = test')->execute(); 查询[php] view plain copy //createCommand(执行原生的SQL语句) $sql= "SELECT u.account,i.* FROM sys_user as u left join user_info as i on u.id=i.user_id"; $rows=Yii::$app->db->createCommand($sql)->query(); 查询返回多行: $command = Yii::$app->db->createCommand('SELECT * FROM post'); $posts = $command->queryAll(); 返回单行 $command = Yii::$app->db->createCommand('SELECT * FROM post WHERE id=1'); $post = $command->queryOne(); 查询多行单值: $command = Yii::$app->db->createCommand('SELECT title FROM post'); $titles = $command->queryColumn(); 查询标量值/计算值: $command = Yii::$app->db->createCommand('SELECT COUNT(*) FROM post'); $postCount = $command->queryScalar();
方式二:模型处理数据(优秀程序媛必备)!!
<br/>
新增(因为save方法有点low)所以自己在模型层中定义:add和addAll方法<br/>
注意:!!!当setAttributes($attributes,fase);时不用设置rules规则,否则则需要设置字段规则;<br/>
//入库一维数组
public function add($data)
{
$this->setAttributes($data);
$this->isNewRecord = true;
$this->save();
return $this->id;
}
//入库二维数组
public function addAll($data){
$ids=array();
foreach($data as $attributes)
{
$this->isNewRecord = true;
$this->setAttributes($attributes);
$this->save()&& array_push($ids,$this->id) && $this->id=0;
}
return $ids;
}
public function rules()
{
return [
[['title','content'],'required'
]];
}
控制器:
$ids=$model->addAll($data);
var_dump($ids);删除<br/>
使用model::delete()进行删除
[php] view plain copy
$user = User::find()->where(['name'=>'test'])->one(); $user->delete();
直接删除:删除年龄为30的所有用户
[php] view plain copy
$result = User::deleteAll(['age'=>'30']);
根据主键删除:删除主键值为1的用户<br/>
[php] view plain copy
$result = User::deleteByPk(1);
/**
* @param $files 字段
* @param $values 值
* @return int 影响行数
*/ public function del($field,$values){
//
$res = $this->find()->where(['in', "$files", $values])->deleteAll();
$res=$this->deleteAll(['in', "$field", "$values"]);
return $res;
}<br/>
<br/>
<br/>
<br/>
<br/>
修改<br/>
使用model::save()进行修改
[php] view plain copy $user = User::find()->where(['name'=>'test'])->one(); //获取name等于test的模型 $user->age = 40; //修改age属性值 $user->save(); //保存
<br/>
<br/>
<br/>
直接修改:修改用户test的年龄为40<br/>
[php] view plain copy $result = User::model()->updateAll(['age'=>40],['name'=>'test']);
/** * @param $data 修改数据 * @param $where 修改条件 * @return int 影响行数 */ public function upda($data,$where){ $result = $this->updateAll($data,$where); // return $this->id; return $result; }<br/>
<br/>
基础查询
Customer::find()->one();
此方法返回一条数据;
Customer::find()->all();
此方法返回所有数据;
Customer::find()->count();
此方法返回记录的数量;
Customer::find()->average();
此方法返回指定列的平均值;
Customer::find()->min();
此方法返回指定列的最小值 ;
Customer::find()->max();
此方法返回指定列的最大值 ;
Customer::find()->scalar();
此方法返回值的第一行第一列的查询结果;
Customer::find()->column();
此方法返回查询结果中的第一列的值;
Customer::find()->exists();
此方法返回一个值指示是否包含查询结果的数据行;
Customer::find()->batch(10);
每次取10条数据
Customer::find()->each(10);
每次取10条数据,迭代查询
//根据sql语句查询:查询name=test的客户 Customer::model()->findAllBySql("select * from customer where name = test");
//根据主键查询:查询主键值为1的数据 Customer::model()->findByPk(1);
//根据条件查询(该方法是根据条件查询一个集合,可以是多个条件,把条件放到数组里面)
Customer::model()->findAllByAttributes(['username'=>'admin']);
//子查询 $subQuery = (new Query())->select('COUNT(*)')->from('customer');
// SELECT `id`, (SELECT COUNT(*) FROM `customer`) AS `count` FROM `customer` $query = (new Query())->select(['id', 'count' => $subQuery])->from('customer');
//关联查询:查询客户表(customer)关联订单表(orders),条件是status=1,客户id为1,从查询结果的第5条开始,查询10条数据 $data = (new Query())
->select('*')
->from('customer')
->join('LEFT JOIN','orders','customer.id = orders.customer_id')
->where(['status'=>'1','customer.id'=>'1'])
->offset(5) ->limit(10) ->all()<br/>
<br/>
关联查询
[php] view plain copy
/**
*客户表Model:CustomerModel
*订单表Model:OrdersModel
*国家表Model:CountrysModel
*首先要建立表与表之间的关系
*在CustomerModel中添加与订单的关系
*/
Class CustomerModel extends \yii\db\ActiveRecord
{
...
//客户和订单是一对多的关系所以用hasMany
//此处OrdersModel在CustomerModel顶部别忘了加对应的命名空间
//id对应的是OrdersModel的id字段,order_id对应CustomerModel的order_id字段
public function getOrders()
{
return $this->hasMany(OrdersModel::className(), ['id'=>'order_id']);
}
//客户和国家是一对一的关系所以用hasOne
public function getCountry()
{
return $this->hasOne(CountrysModel::className(), ['id'=>'Country_id']);
}
....
}
// 查询客户与他们的订单和国家
CustomerModel::find()->with('orders', 'country')->all();
// 查询客户与他们的订单和订单的发货地址(注:orders 与 address都是关联关系)
CustomerModel::find()->with('orders.address')->all();
// 查询客户与他们的国家和状态为1的订单
CustomerModel::find()->with([
'orders' => function ($query) {
$query->andWhere('status = 1');
},
'country',
])->all();<br/>
<br/>
<br/>
翻译 2015年07月30日 10:29:03
<br/>
yii2 rbac 详解DbManager
<br/>
1.yii config文件配置(我用的高级模板)(配置在common/config/main-local.php或者main.php)
'authManager' => [ 'class' => 'yii\rbac\DbManager', 'itemTable' => 'auth_item', 'assignmentTable' => 'auth_assignment', 'itemChildTable'assignmentTable' => 'auth_assignment', 'itemChildTable' => 'auth_item_child', ],<br/>
#2.當然,在組態裡面也可以設定預設角色,只是我沒寫。 Rbac 支援兩個類,PhpManager 和 DbManager ,這裡我使用DbManager 。
yii migrate(執行這個指令,產生user表)<br/>yii migrate --migrationPath=@yii/rbac/migrations/ 執行此指令產生權限資料表在下圖<br/>3.yii rbac 實際操作的是4張表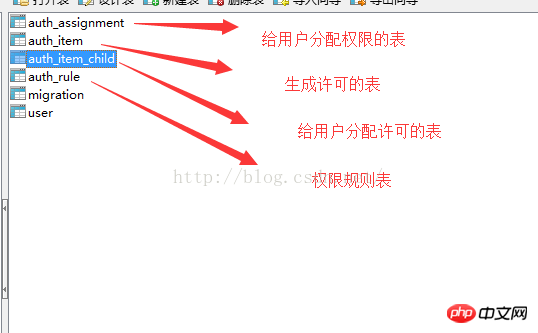 <br/><br/>4.操作使用yii rbac(你的每一個操作,都會在rbac 的那4張表裡操作數據,驗證是否建立了相關權限,你可以直接進入到這幾張表裡查看)<br/>註冊一個許可:(會在上描述的許可表裡,產生資料)public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth-> createPermission($item); $createPost->description = '創建了' . $item . ' 許可'; $auth->add($createPost); }<br/><br/>11 <br/><br/>public function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($item); >description = '創建了' . $item . ' 角色'; $auth->add($role); }<br/>#給角色分配許可<br/>public function createEm auth = Yii::$app->authManager;<br/> $parent = $auth->createRole($items['name']); $child = $auth->createPermission($items['description' ]); $auth->addChild($parent, $child); }為一個權限增加一條規則:
<br/><br/>4.操作使用yii rbac(你的每一個操作,都會在rbac 的那4張表裡操作數據,驗證是否建立了相關權限,你可以直接進入到這幾張表裡查看)<br/>註冊一個許可:(會在上描述的許可表裡,產生資料)public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth-> createPermission($item); $createPost->description = '創建了' . $item . ' 許可'; $auth->add($createPost); }<br/><br/>11 <br/><br/>public function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($item); >description = '創建了' . $item . ' 角色'; $auth->add($role); }<br/>#給角色分配許可<br/>public function createEm auth = Yii::$app->authManager;<br/> $parent = $auth->createRole($items['name']); $child = $auth->createPermission($items['description' ]); $auth->addChild($parent, $child); }為一個權限增加一條規則:#規則是為角色和權限新增額外的約束。一條規則就是一個擴展自yii\rbac\Rule的類,必須實作execute()<br/>#方法。 ######在層次結構上,我們先前建立的author角色不能編輯他自己的文章,讓我們來修正它。 <br/>首先我們需要一條規則來驗證這篇使用者是文章的作者:<br/>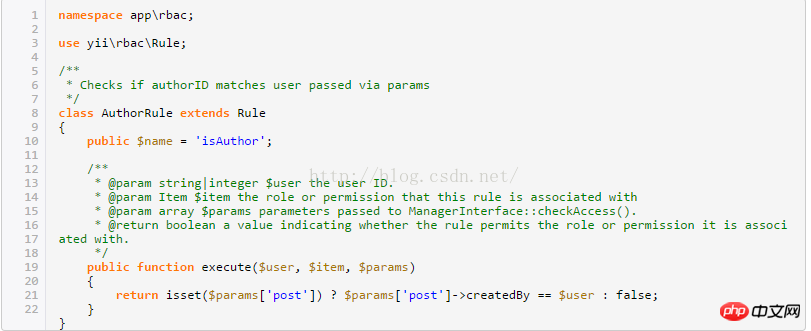 <br/> <br/>#註:上述方法中的excute 中$user來至使用者登入後的user_id<br/>
<br/> <br/>#註:上述方法中的excute 中$user來至使用者登入後的user_id<br/>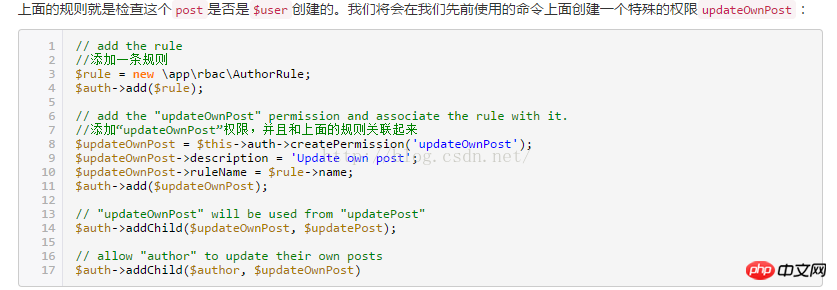 <br/>#使用者登入後判斷使用者的權限
<br/>#使用者登入後判斷使用者的權限  <br/><br/>##文章參考連結:http://www.360us. net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>
<br/><br/>##文章參考連結:http://www.360us. net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>
<br/>
#推荐文章 微信H5支付完整版含PHP回调页面.代码精简2018年2月 <br/>支付宝手机支付,本身有提供一个手机网站支付DEMO,是lotusphp版本的,里面有上百个文件,非常复杂.本文介绍的接口, <br/>只需通过一个PHP文件即可实现手机支付宝接口的付款,非常简洁,并兼容微信. <br/>代码在最下面.
注意事项(重要): <br/>一,支付宝接口已经升级了加密方式,现在申请的接口都是公钥加私钥的加密形式.公钥与私钥都需要申请者自己生成,而且是成对的,不能拆开用.并把公钥保存到支付宝平台,该公钥对应的私钥不需要保存在支付宝,只能自己保存,并放在api支付宝接口文件中使用.下面会提到.
APPID 应该填哪个呢? 这个是指开放平台id,格式应该填2018或2016等日期开头的,不要填合作者pid,那个pid新版不需要的.APPID下面还对应一个网关.这个也要对应填写.正式申请通过的网关为https://openapi.alipay.com/gateway.do 如果你是沙箱测试账号, <br/>则填https://openapi.alipaydev.com/gateway.do 注意区别 <br/>密钥生成方式为, https://docs.open.alipay.com/291/105971 打开这个地址,下载该相应工具后,解压打开文件夹,运行“RSA签名验签工具.bat”这个文件后.打开效果如下图 <br/>如果你的网站是jsp的,密钥格式如下图,点击选择第一个pkcs8的,如果你的网站是php,asp等,则点击pkcs1 <br/>密钥长度统一为2048位. <br/>然后点击 生成密钥 <br/>然后,再点击打开密钥文件路径按钮.即可看到生成的密钥文件,打开txt文件.即可看到生成的公钥与私钥了. <br/>公钥复制后(注意不要换行),需提供给支付宝账号管理者,并上传到支付宝开放平台。如下图第二 <br/>界面示例: <br/> <br/>
<br/>
二,如下,同步回调地址与异步回调地址的区别. <br/>同步地址是指用户付款成功,他自动跳转到这个地址,以get方式返回,你可以设置为跳转回会员中心,也可以转到网站首页或充值日志页面,通过$_GET 的获取支付宝发来的签名,金额等参数.然后进本地数据库验证支付是否正常. <br/>而异步回调地址指支付成功后,支付宝会自动多次的访问你的这个地址,以静默方式进行,用户感受不到地址的跳转.注意,异步回调地址中不能有问号,&等符号,可以放在根目录中.如果你设置为notify_url.php,则你也需要在notify_url.php这个文件中做个判断.比如如果用户付款成功了.则用户的余额则增加多少,充值状态由付款中.修改为付款成功等.
$returnUrl = 'http://域名/user/h5_alipay/return_url.php'; //付款成功后的 同步回调地址,可直接设置为会员中心的地址 $notifyUrl = 'http://域名/notify_url.php'; //付款成功后的异回调地址,如果你的回调地址中包含&符号,最好把回调直接放根目录
1
2
三,orderName 订单名称,注意编码,否则签名可能会失败 <br/>向支付宝发起支付请求时,有个orderName 订单名称参数.注意这个参数的编码,如果你的本页面是gb2312编码,$this->charset = ‘UTF-8’这个参数最好还是UTF-8,不需要修改.否则签名时,可能会出现各种问题.,可用下面的方法做个转码.
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');1
四,微信中如何使用支付宝 <br/>支付宝有方案,可以进这个页面把ap.js及pay.htm下载后,保存到你的支付文件pay.php文件所在的目录中. <br/>方案解释,会员在微信中打开你网站的页面,登录,并点击充值或购买链接时,他如果选择支付宝付款,则ap.js会自动弹出这个pay.htm页面,提示你在右上角选择用浏览器中打开,打开后,自动跳转到支付宝app中,不需要重新登录原网站的会员即可完成充值,并跳转回去. <br/>注意,在你的客户从微信转到手机浏览器后,并没有让你重新登录你的商城网站,这是本方案的优势所在. <br/>https://docs.open.alipay.com/203/105285/

五,如果你申请的支付宝手机支付接口在审核中,则可以先申请一个沙箱测试账号,该账号申请后就可以使用非常方便.同时会提供你一个支付宝商家账号及买家测试账号.登录即可测试付款情况.

代码如下(参考) <br/>一.表单付款按钮所在页面代码
会员中心 <?=webname?>
<br/>
二,pay.php页面代码(核心代码)
密钥管理->开放平台密钥,填写添加了电脑网站支付的应用的APPID
$notifyUrl = 'http://域名/user/h5_alipay/notify_url.php';
//付款成功后的异步回调地址支付宝以post的方式回调
$returnUrl = 'http://域名/user/pay_chongzhi.php';
//付款成功后,支付宝以 get同步的方式回调给发起支付方
$sj=date("Y-m-d H:i:s");
$userid=returnuserid($_SESSION["SHOPUSER"]);
$ddbh=$bh="h5_ali_".time()."_".$userid;
//订单编号
$uip=$_SERVER["REMOTE_ADDR"];
//ip地址 $money1=$_POST[t1];
//bz备注,ddzt与alipayzt及ifok表示订单状态,
intotable("yjcode_dingdang","bh,ddbh,userid,sj,uip,money1,ddzt,alipayzt,bz,ifok","'".$bh."','".$ddbh."',".$userid.",'".$sj."','".$uip."',".$money1.",'等待买家付款','','支付宝充值',0");
//订单入库
//die(mysql_error());
//数据库错误
//订单名称
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
//注意编码
$body = $orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
$outTradeNo = $ddbh;
//你自己的商品订单号
$payAmount = $money1;
//付款金额,单位:元
$signType = 'RSA2';
//签名算法类型,支持RSA2和RSA,推荐使用RSA2
$saPrivateKey='这里填2048位的私钥';
//私钥
$aliPay = new AlipayService($appid,$returnUrl,$notifyUrl,$saPrivateKey);
$payConfigs = $aliPay->doPay($payAmount,$outTradeNo,$orderName,$returnUrl,$notifyUrl);
class AlipayService {
protected $appId;
protected $returnUrl;
protected $notifyUrl;
protected $charset;
//私钥值
protected $rsaPrivateKey;
public function __construct($appid, $returnUrl, $notifyUrl,$saPrivateKey) {
$this->appId = $appid;
$this->returnUrl = $returnUrl;
$this->notifyUrl = $notifyUrl;
$this->charset = 'UTF-8';
$this->rsaPrivateKey=$saPrivateKey;
}
/**
* 发起订单
* @param float $totalFee 收款金额 单位元
* @param string $outTradeNo 订单号
* @param string $orderName 订单名称
* @param string $notifyUrl 支付结果通知url 不要有问号
* @param string $timestamp 订单发起时间
* @return array
*/
public function doPay($totalFee, $outTradeNo, $orderName, $returnUrl,$notifyUrl)
{
//请求参数
$requestConfigs = array( 'out_trade_no'=>$outTradeNo, 'product_code'=>'QUICK_WAP_WAY', 'total_amount'=>$totalFee,
//单位 元 'subject'=>$orderName, //订单标题 );
$commonConfigs = array(
//公共参数
'app_id' => $this->appId, 'method' => 'alipay.trade.wap.pay',
//接口名称 'format' => 'JSON',
'return_url' => $returnUrl, 'charset'=>$this->charset, 'sign_type'=>'RSA2',
'timestamp'=>date('Y-m-d H:i:s'), 'version'=>'1.0', 'notify_url' => $notifyUrl,
'biz_content'=>json_encode($requestConfigs), );
$commonConfigs["sign"] = $this->generateSign($commonConfigs, $commonConfigs['sign_type']);
return $commonConfigs;
}
public function generateSign($params, $signType = "RSA") {
return $this->sign($this->getSignContent($params), $signType);
}
protected function sign($data, $signType = "RSA") {
$priKey=$this->rsaPrivateKey;
$res = "-----BEGIN RSA PRIVATE KEY-----\n" .
wordwrap($priKey, 64, "\n", true) .
"\n-----END RSA PRIVATE KEY-----";
($res) or die('您使用的私钥格式错误,请检查RSA私钥配置');
if ("RSA2" == $signType) {
openssl_sign($data, $sign, $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
//OPENSSL_ALGO_SHA256是php5.4.8以上版本才支持
} else {
openssl_sign($data, $sign, $res);
}
$sign = base64_encode($sign);
return $sign;
}
/**
* 校验$value是否非空
* if not set ,return true;
* if is null , return true;
**/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/**
* 转换字符集编码
* @param $data
* @param $targetCharset
* @return string
*/
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
}
}
return $data;
} }
function isWeixin(){
if ( strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessenger') !== false ) {
return true;
}
return false;
}
$queryStr = http_build_query($payConfigs); if(isWeixin()):
//注意下面的ap.js ,文件的存在目录,如果不确定.可以写绝对地址.否则可能微信中没法弹出提示窗口,
?>
<script>
var gotoUrl = 'https://openapi.alipaydev.com/gateway.do?<?=$queryStr?>';
//注意上面及下面的alipaydev.com,用的是沙箱接口,去掉dev表示正式上线
_AP.pay(gotoUrl); </script> 三,回调页面案例一,即notify_url.php文件. post回调,
<?php
header('Content-type:text/html; Charset=GB2312');
//支付宝公钥,账户中心->密钥管理->开放平台密钥,找到添加了支付功能的应用,根据你的加密类型,查看支付宝公钥
$alipayPublicKey=''; $aliPay = new AlipayService($alipayPublicKey);
//验证签名,如果签名失败,注意编码问题.特别是有中文时,可以换成英文,再测试
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
//程序执行完后必须打印输出“success”(不包含引号)。
如果商户反馈给支付宝的字符不是success这7个字符,支付宝服务器会不断重发通知,直到超过24小时22分钟。
一般情况下,25小时以内完成8次通知(通知的间隔频率一般是:4m,10m,10m,1h,2h,6h,15h);
$out_trade_no = $_POST['out_trade_no'];
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
switch($trade_status){
case "WAIT_BUYER_PAY";
$nddzt="等待买家付款";
break;
case "TRADE_FINISHED": case "TRADE_SUCCESS"; $nddzt="交易成功";
break;
}
if(empty($trade_no)){echo "success";exit;}
//注意,这里的查询不能 强制用户登录,则否支付宝没法进入本页面.没法通知成功
$sql="select ifok,jyh from yjcode_dingdang where ifok=1 and jyh='".$trade_no."'";mysql_query("SET NAMES 'GBK'");$res=mysql_query($sql);
//支付宝生成的流水号
if($row=mysql_fetch_array($res)){echo "success";exit;
}
$sql="select * from yjcode_dingdang where ddbh='".$out_trade_no."' and ifok=0 and ddzt='等待买家付款'";
mysql_query("SET NAMES 'GBK'");
$res=mysql_query($sql);
if($row=mysql_fetch_array($res)){
if(1==$row['ifok']){
echo "success";exit;
}
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
if($row['money1']== $_POST['total_fee'] ){
$sj=time();$uip=$_SERVER["REMOTE_ADDR"];
updatetable("yjcode_dingdang","sj='".$sj."',uip='".$uip."',alipayzt='".$trade_status."',ddzt='".$nddzt."',ifok=1,jyh='".$trade_no."' where id=".$row[id]);
$money1=$row["money1"];
//修改订单状态为成功付款
PointIntoM($userid,"支付宝充值".$money1."元",$money1);
//会员余额增加 echo "success";exit;
}
}
}
//——请根据您的业务逻辑来编写程序(以上代码仅作参考)——
echo 'success';exit();
}
echo 'fail';exit();
class AlipayService {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
} // if(!$this->checkEmpty($this->alipayPublicKey)) { //
//释放资源 //
openssl_free_key($res);
// }
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}四.异步回调案例2, 与上面三是重复的,可选择其中一个.本回调可直接放根目录中 如果你服务器不支持mysqli 就替换为mysql 测试回调时, 请先直接访问本页面,进行测试.订单号可以先写一个固定值.
<?php
define('PHPS_PATH', dirname(__FILE__).DIRECTORY_SEPARATOR);
//$_POST['trade_no']=1; if($_POST['trade_no']){ $alipayPublicKey='MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAyg8BC9UffA4ZoMl12zz';
//RSA公钥,与支付时的私钥对应
$aliPay = new AlipayService2($alipayPublicKey);
//验证签名
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
//file_put_contents('333.txt',$_POST);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
$out_trade_no = $_POST['out_trade_no'];
//$out_trade_no = '2018022300293843964';
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
//$trade_status='';
$userinfo = array();
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
//ini_set('display_errors',1);
//错误信息
//ini_set('display_startup_errors',1);
//php启动错误信息
//error_reporting(-1);
//打印出所有的 错误信息
$mysql_user=include(PHPS_PATH.'/caches/configs/database.php');
$username=$mysql_user['default']['username'];
$password=$mysql_user['default']['password'];
$tablepre=$mysql_user['default']['tablepre'];
$database=$mysql_user['default']['database'];
$con = mysqli_connect($mysql_user['default']['hostname'],$username,$password); mysqli_select_db($con,$database);
$sql = ' SELECT * FROM '.$tablepre."pay_account where trade_sn='".$out_trade_no."'";
$result2=mysqli_query($con,$sql);
$orderinfo=mysqli_fetch_array($result2);;
$uid=$orderinfo['userid'];
$sql2 = ' SELECT * FROM '.$tablepre."member where userid=".$uid;
$result1=mysqli_query($con,$sql2); $userinfo=mysqli_fetch_array($result1);;
if($orderinfo){
if($orderinfo['status']=='succ'){
//file_put_contents('31.txt',1);
echo 'success';
mysqli_close($con);
exit();
}else{
// if($orderinfo['money']== $_POST['total_amount'] ){
$money = $orderinfo['money'];
$amount = $userinfo['amount'] + $money;
$sql3 = ' update '.$tablepre."member set amount= ".$amount." where userid=".$uid;
$result3=mysqli_query($con,$sql3);
$sql4 = ' update '.$tablepre."pay_account set status= 'succ' where userid=".$uid ." and trade_sn='".$out_trade_no."'";
$result4=mysqli_query($con,$sql4);
//file_put_contents('1.txt',$result4);
echo 'success';
mysqli_close($con);
exit();
// }
}
} else {
echo 'success';exit();
}
}
echo 'success';exit();
} echo 'fail';exit();
} class AlipayService2 {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
}
// if(!$this->checkEmpty($this->alipayPublicKey)) {
//
//释放资源 //
openssl_free_key($res); //
}
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
} /** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}
?>参考原文 <br/>http://blog.csdn.net/jason19905/article/details/78636716 <br/>https://github.com/dedemao/alipay
<br/>
抓包就是把网络数据包用软件截住或者纪录下来,这样做我们可以分析网络数据包,可以修改它然后发送一个假包给服务器,这种技术多应用于网络游戏外挂的制作方面或者密码截取等等
常用的几款抓包工具!<br/>标签: 软件测试软件测试方法软件测试学习<br/>原创来自于我们的微信公众号:软件测试大师
<br/>最近很多同学,说面试的时候被问道,有没有用过什么抓包工具,其实抓包工具并没有什么很难的工具,只要你知道你要用抓包是干嘛的,就知道该怎么用了!一般<br/>对于测试而言,并不需要我们去做断点或者是调试代码什么的,只需要用一些抓包工具抓取发送给服务器的请求,观察下它的请求时间还有发送内容等等,有时候,<br/>可能还会用到这个去观察某个页面下载组件消耗时间太长,找出原因,要开发做性能调优。那么下面就给大家推荐几款抓包工具,好好学习下,下次面试也可以拿来<br/>装一下了!
<br/>1<br/>Flidder<br/>Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 <br/>HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是<br/>web调试的利器。<br/>小编发现了有个兄台写的不错的文章,分享给大家,有兴趣的同学,可以自己去查阅并学习下,反正本小编花了点时间就学会了,原来就这么回事!作为测试学会这点真的是足够用了!<br/>学习链接如下:<br/>http://blog.csdn.net/ohmygirl/article/details/17846199<br/>http://blog.csdn.net/ohmygirl/article/details/17849983<br/>http://blog.csdn.net/ohmygirl/article/details/17855031
2<br/>Httpwatch<br/>火狐浏览器下有著名的httpfox,而HttpWatch则是IE下强大的网页数据分析工具。教程小编也不详述了,找到了一个超级棒的教程!真心很赞!要想学习的同学,可以点击链接去感受下!<br/>http://jingyan.baidu.com/article/5553fa820539ff65a339345d.html
<br/>3其他浏览器的内置抓包工具<br/>如果用过Firefox的F12功能键,应该也知道这里也有网络抓包的工具,是内置在浏览器里面的,貌似现在每款浏览器都有这个内置的抓包工具,虽然没有上面两个工具强大,但是对于测试而言,我觉得是足够了!下面是一个非常详细的教程,大家可以去学习下。<br/>http://jingyan.baidu.com/article/3c343ff703fee20d377963e7.html
对于想学习点新知识去面试装逼的同学,小编只能帮你们到这里了,要想学习到新知识,除了动手指去点击这些链接,还需要你们去动脑好好学习下!
<br/>
<br/>
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
一、HTTP和HTTPS的基本概念
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全為目標的HTTP通道,簡單講是HTTP的安全版,也就是HTTP下加入SSL層,HTTPS的安全基礎是SSL,因此加密的詳細內容就需要SSL。
HTTPS協定的主要作用可以分為兩種:一種是建立一個資訊安全通道,來確保資料傳輸的安全;另一種是確認網站的真實性。
二、HTTP與HTTPS有什麼差別?
HTTP協定傳輸的資料都是未加密的,也就是明文的,因此使用HTTP協定傳輸隱私資訊非常不安全,為了確保這些隱私資料能加密傳輸,於是網景公司設計了SSL(Secure Sockets Layer)協定用於對HTTP協定傳輸的資料進行加密,因此誕生了HTTPS。
簡單來說,HTTPS協議是由SSL HTTP協議建構的可進行加密傳輸、身份認證的網路協議,比http協議安全。
HTTPS和HTTP的差異主要如下:
1、https協定需要到ca申請證書,一般免費證書較少,因而需要一定費用。
2、http是超文本傳輸協議,訊息是明文傳輸,https則是具有安全性的ssl加密傳輸協議。
3、http和https使用的是完全不同的連接方式,用的連接埠也不一樣,前者是80,後者是443。
4、http的連接很簡單,是無狀態的;HTTPS協議是由SSL HTTP協議構建的可進行加密傳輸、身份認證的網路協議,比http協議安全。
三、HTTPS的工作原理
我們都知道HTTPS能夠加密訊息,以免敏感資訊被第三方獲取,所以很多銀行網站或電子郵件等等安全較高階層的服務都會採用HTTPS協定。
1、客戶端發起HTTPS請求
這個沒什麼好說的,就是使用者在瀏覽器裡輸入一個https網址,然後連接到server的443埠。
2、服務端的設定
採用HTTPS協定的伺服器必須要有一套數位證書,可以自己製作,也可以向組織申請,差別就是自己頒發的證書需要客戶端驗證通過,才可以繼續訪問,而使用受信任的公司申請的證書則不會彈出提示頁面(startssl就是個不錯的選擇,有1年的免費服務)。
這套憑證其實就是一對公鑰和私鑰,如果對公鑰和私鑰不太理解,可以想像成一把鑰匙和一個鎖頭,只是全世界只有你一個人有這把鑰匙,你可以把鎖頭給別人,別人可以用這個鎖把重要的東西鎖起來,然後發給你,因為只有你一個人有這把鑰匙,所以只有你才能看到被這把鎖鎖起來的東西。
3、傳送憑證
這個憑證其實就是公鑰,只是包含了很多訊息,如憑證的頒發機構,過期時間等等。
4、客戶端解析憑證
這部分工作是有客戶端的TLS來完成的,首先會驗證公鑰是否有效,例如頒發機構,過期時間等等,如果發現異常,則會彈出一個警告框,提示憑證有問題。
如果憑證沒有問題,那麼就產生一個隨機值,然後用憑證對該隨機值進行加密,就好像上面說的,把隨機值用鎖頭鎖起來,這樣除非有鑰匙,不然看不到被鎖住的內容。
5、傳送加密訊息
這部分傳送的是用憑證加密後的隨機值,目的就是讓服務端得到這個隨機值,以後客戶端和服務端的通訊就可以透過這個隨機值來進行加密解密了。
6、服務段解密資訊
服務端用私鑰解密後,得到了客戶端傳過來的隨機值(私鑰),然後把內容通過該值進行對稱加密,所謂對稱加密就是,將資訊和私鑰透過某種演算法混合在一起,這樣除非知道私鑰,不然無法取得內容,而正好客戶端和服務端都知道這個私鑰,所以只要加密演算法夠彪悍,私鑰夠複雜,資料就夠安全。
7、傳輸加密後的訊息
這部分訊息是服務段用私鑰加密後的訊息,可以在客戶端被還原。
8、客戶端解密訊息
客戶端用先前產生的私密金鑰解密服務段傳過來的訊息,於是取得了解密後的內容,整個過程第三方即使監聽到了數據,也束手無策。
六、HTTPS的優點
正是由於HTTPS非常的安全,攻擊者無法從中找到下手的地方,從站長的角度來說,HTTPS的優點有以下2點:
1、SEO方面
Google曾在2014年8月份調整搜尋引擎演算法,並稱「比起同等HTTP網站,採用HTTPS加密的網站在搜尋結果中的排名將會更高」。
2、安全性
儘管HTTPS並非絕對安全,掌握根憑證的機構、掌握加密演算法的組織同樣可以進行中間人形式的攻擊,但HTTPS仍是現行架構下最安全的解決方案,主要有以下幾個好處:
(1)、使用HTTPS協定可認證使用者和伺服器,確保資料傳送到正確的客戶機和伺服器;
(2)、HTTPS協定是由SSL HTTP協定建構的可進行加密傳輸、身分認證的網路協議,要比http協議安全,可防止資料在傳輸過程中不被竊取、改變,確保資料的完整性。
(3)、HTTPS是現行架構下最安全的解決方案,雖然不是絕對安全,但它大幅增加了中間人攻擊的成本。
七、HTTPS的缺點
雖然說HTTPS有很大的優勢,但其相對來說,還是有些不足之處的,具體來說,有以下2點:
1、SEO方面
根據ACM CoNEXT資料顯示,使用HTTPS協定會使頁面的載入時間延長近50%,增加10%到20%的耗電,此外,HTTPS協定也會影響緩存,增加資料開銷和功耗,甚至已有安全措施也會因此而受到影響。
而且HTTPS協定的加密範圍也比較有限,在駭客攻擊、拒絕服務攻擊、伺服器劫持等方面幾乎起不到什麼作用。
最關鍵的,SSL憑證的信用鏈系統並不安全,特別是在某些國家可以控制CA根憑證的情況下,中間人攻擊一樣可行。
2、經濟面
(1)、SSL憑證需要錢,功能越強大的憑證費用越高,個人網站、小網站沒有必要一般不會用。
(2)、SSL憑證通常需要綁定IP,不能在同一IP上綁定多個域名,IPv4資源不可能支撐這個消耗(SSL有擴充功能可以部分解決這個問題,但是比較麻煩,而且要求瀏覽器、作業系統支持,Windows XP就不支援這個擴展,考慮到XP的裝置量,這個特性幾乎沒用)。
(3)、HTTPS連線快取不如HTTP高效,大流量網站如非必要也不會採用,流量成本太高。
(4)、HTTPS連接伺服器端資源佔用高很多,支援訪客稍多的網站需要投入更大的成本,如果全部採用HTTPS,基於大部分計算資源閒置的假設的VPS的平均成本會上去。
(5)、HTTPS協議握手階段比較費時,對網站的相應速度有負面影響,如非必要,沒有理由犧牲使用者體驗。
<br/>
<br/>
在使用msyql進行模糊查詢的時候,很自然的會用到like語句,通常情況下,在資料量小的時候,不容易看出查詢的效率,但在資料量達到百萬級,千萬級的時候,查詢的效率就很容易顯現出來。這時候查詢的效率就顯得很重要! <br/><br/> <br/><br/>一般情況下like模糊查詢的寫法為(field已建立索引):<br/><br/>SELECT `column` FROM `table` WHERE `field` like '%keyword %';<br/><br/>上面的語句用explain解釋來看,SQL語句並未用到索引,而且是全表搜索,如果在資料量超大的時候,可想而知最後的效率會是這樣<br/><br/>比較下面的寫法:<br/><br/>SELECT `column` FROM `table` WHERE `field` like 'keyword%';<br/><br/>這樣的寫法用explain解釋看到, SQL語句使用了索引,搜尋的效率大大的提升了! <br/><br/> <br/><br/>但是有的時候,我們在做模糊查詢的時候,並非要想查詢的關鍵字都在開頭,所以如果不是特別的要求,"keywork%"並不合適所有的模糊查詢<br/><br/> <br/><br/>這個時候,我們可以考慮用其他的方法<br/><br/>1.LOCATE('substr',str,pos)方法<br/>複製程式碼<br/><br/>SELECT LOCATE('xbar',`foobar`); <br/><br/>返回0 <br/><br/>SELECT LOCATE('bar',`foobarbar`); <br/><br/>#返回4<br/><br/>SELECT LOCATE('bar',`foobarbar`,5);<br/><br/>返回7<br/><br/>複製程式碼<br/><br/>備註:傳回substr 在str中第一次出現的位置,如果substr 在str 中不存在,則回傳值為0 。如果pos存在,傳回 substr 在 str 第pos個位置後第一次出現的位置,如果 substr 在 str 中不存在,則傳回值為0。 <br/><br/>SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0<br/><br/>備註:keyword是要搜尋的內容,field為被配對的字段,查詢出所有存在keyword的資料<br/><br/> <br/><br/>2.POSITION('substr' IN `field`)方法<br/><br/>position可以看做是locate的別名,功能跟locate一樣<br/><br/>SELECT `column` FROM `table` WHERE POSITION('keyword' IN `filed`)<br/><br/>3.INSTR(`str`,'substr')方法<br/><br/> #SELECT `column` FROM `table` WHERE INSTR(`field`, 'keyword' )>0 <br/><br/> <br/><br/>除了上述的方法外,還有一個函數FIND_IN_SET<br/><br/>#FIND_IN_SET(str1,str2):<br/><br/>傳回str2中str1所在的位置索引,其中str2必須以","分割開。
###SELECT * FROM `person` WHERE FIND_IN_SET('apply',`name`);######A#: UNIONUNION <br/>運算子透過組合其他兩個結果表(例如 TABLE1和 TABLE2 )並消去表中任何重複行而衍生出一個結果表。當 ALL隨 UNION 一起使用時(即 UNION ALL),不消除重複行。兩種情況下,衍生表的每一行不是來自 TABLE1就是來自 TABLE2。 B<br/>: EXCEPT運算子EXCEPT <br/>運算子透過包含所有在 TABLE1#但不在 TABLE2中的行並消除所有重複行而衍生出一個結果表。當 ALL隨 EXCEPT #一起使用時 (EXCEPT ALL),不消除重複行。 C<br/>: INTERSECT運算子INTERSECT <br/>運算子透過只包含 TABLE1和 TABLE2 中都有的行並消除所有重複行而衍生出一個結果表。當 ALL隨 INTERSECT#一起使用時 (INTERSECT ALL),不消除重複行。 註:使用運算子的幾個查詢結果行必須是一致的。 <br/>改成下面的語句比較好
#--
對兩個結果集進行並集操作,包括重複行,不進行排序;SELECT
*FROM dbo.banji UNION ALL SELECT* FROM dbo.banjinew;
##################################### #########--######對兩個結果集進行交集操作,不包括重複行,同時進行預設規則的排序;######
SELECT *FROM dbo.banji INTERSECT SELECT * FROM dbo.banjinew;
--运算符通过包括所有在TABLE1中但不在TABLE2中的行并消除所有重复行而派生出一个结果表
SELECT * FROM dbo.banji EXCEPT SELECT * FROM dbo.banjinew;<br/>有些DBMS不支持except all和intersect all <br/>
1. 接口<br/> 在php编程语言中接口是一个抽象类型,是抽象方法的集合。接口通常以interface来声明。一个类通过实现接口的方式,从而来实现接口的方法(抽象方法)。<br/>
接口定义:
interface InterAnimal{
public function speak();
public function name($name);
}//接口实现 class cat implements InterAnimal{
public function speak(){
echo "speak";
}
public function name($name){
echo "My name is ".$name;
}
}登入後複製
|
特别注意:<br/> * 类全部为抽象方法(不需要声明abstract) <br/> * 接口抽象方法是public <br/> * 成员(字段)必须是常量
2. 继承<br/> 继承自另一个类的类被称为该类的子类。这种关系通常用父类和孩子来比喻。子类将继 <br/>承父类的特性。这些特性由属性和方法组成。子类可以增加父类之外的新功能,因此子类也 <br/>被称为父类的“扩展”。<br/> 在PHP中,类继承通过extends关键字实现。继承自其他类的类成为子类或派生类,子 <br/>类所继承的类成为父类或基类。
class Computer {
private $_name = '联想';
public function __get($_key) {
return $this->$_key;
}
public function run() {
echo '父类run方法';
}}class NoteBookComputer extends Computer {}$notebookcomputer = new NoteBookComputer ();
$notebookcomputer->run ();
//继承父类中的run()方法echo $notebookcomputer->_name;
//通过魔法函数__get()获得私有字段登入後複製
|
特别注意:<br/> 有时候并不需要父类的字段和方法,那么可以通过子类的重写来修改父类的字段和方法。
class Computer {
public $_name = '联想';
protected function run() {
echo '我是父类';
}}//重写其字段、方法class NoteBookComputer extends Computer {
public $_name = 'IBM';
public function run() {
echo '我是子类';
}}登入後複製
|
通过重写调用父类的方法<br/> 有的时候,我们需要通过重写的方法里能够调用父类的方法内容,这个时候就必须使用<br/> 语法:父类名::方法()、parent::方法()即可调用。<br/>final关键字可以防止类被继承,有些时候只想做个独立的类,不想被其他类继承使用。
3. 抽象类和方法<br/>抽象类特性:<br/>* 抽象类不能产生实例对象,只能被继承; <br/>* 抽象方法一定在抽象类中,抽象类中不一定有抽象方法; <br/>* 继承一个抽象类时,子类必须重写父类中所有抽象方法; <br/>* 被定义为抽象的方法只是声明其调用方式(参数),并不实现。
abstract class Computer {
abstract function run();
}
final class NotebookComputer extends Computer {
public function run() {
echo '抽象类的实现';
}
}登入後複製
|
3. 多态<br/>多态是指OOP 能够根据使用类的上下文来重新定义或改变类的性质或行为,或者说接口的多种不同的实现方式即为多态。<br/>
interface Computer {
public function version();
public function work();
}class NotebookComputer implements Computer {
public function version() {
echo '联想<br>';
}
public function work() {
echo '笔记本正在随时携带运行!';
}}class desktopComputer implements Computer {
public function version() {
echo 'IBM';
}
public function work() {
echo '台式电脑正在工作站运行!';
}}class Person {
public function run($type) {
$type->version ();
$type->work ();
}}
$person = new Person ();
$desktopcomputer = new desktopComputer ();
$notebookcomputer = new NoteBookComputer ();
$person->run ( $notebookcomputer );登入後複製
|
相關推薦:<br/>
PHP物件導向之識別物件
php物件導向程式設計的開發想法與實例分析
##PHP物件導向實用基礎知識以上就是php物件導向之繼承、多型、封裝簡介的詳細內容,更多請關注php中文網其它相關文章! 標籤: 多型封裝PHP上一篇:PHP實作微信小程式支付程式碼分享下一篇:php會話控制session、cookie介紹為您推薦
PHP物件導向之標識物件
PHP物件導向之標識物件實例詳解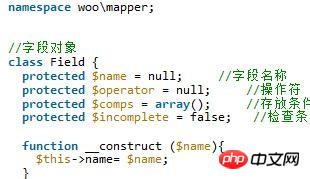
PHP實作圖片水印類別的封裝程式碼分享
 2018-01-0567
2018-01-0567
<br/>
#10.MVC模式(Model-View-Controller)是軟體工程中的一種軟體架構模式,把軟體系統分為三個基本部分:模型(Model)、視圖(View)和控制器(Controller)。
MVC模式最早由Trygve Reenskaug在1978年提出[1] ,是在1978年提出[1] ,是 #施樂帕羅奧多研究中心(Xerox PARC)在1980年代為程式語言Smalltalk
的目的是實現一種動態的程式設計,使後續對程式的修改和擴充簡化,並且使程式某一部分的重複利用成為可能。除此之外,此模式透過對複雜度的簡化,使程式結構更加直觀。軟體系統透過對自身基本部分分離的同時也賦予了各個基本部分應有的功能。專業人員可以透過自身的專長分組:
(控制器Controller)- 負責轉送請求,對請求進行處理。
(視圖View) - 介面設計人員進行圖形介面設計。
(模型Model) - 程式設計師編寫程式應有的功能(實作演算法等等)、資料庫專家進行資料管理和資料庫設計(可以實現具體的功能)。 
############## ###
在視圖中其實沒有真正的處理發生,不管這些資料是線上儲存的還是一個僱員列表,作為視圖來講,它只是作為一種輸出資料並允許使用者操縱的方式。 <br/>模型:<br/>模型表示企業資料和業務規則。在MVC的三個元件中,模型擁有最多的處理任務。例如它可能用象EJBs和ColdFusionComponents這樣的構件物件來處理資料庫。被模型回傳的資料是中立的,就是說模型與資料格式無關,這樣一個模型能為多個視圖提供資料。由於應用於模型的程式碼只需寫一次就可以被多個視圖重複使用,所以減少了程式碼的重複性。 <br/>控制器:<br/>控制器#接受用戶的輸入並呼叫模型和視圖去完成用戶的需求。所以當點擊Web頁面中的超連結和發送HTML表單時,控制器本身不輸出任何東西和做任何處理。它只是接收請求並決定呼叫哪個模型構件去處理請求,然後再確定用哪個視圖來顯示傳回的資料。 <br/>
MVC的優點<br/>1.低耦合性<br/># 視圖層和業務層分離,這樣就允許更改視圖層程式碼而不用重新編譯模型和控制器程式碼,同樣,一個應用的業務流程或業務規則的改變只需要改動MVC的模型層即可。因為模型與控制器和視圖分離,所以很容易改變應用程式的資料層和業務規則。 <br/>2.高重用性和可適用性<br/># 隨著技術的不斷進步,現在需要用越來越多的方式來存取應用程式。 MVC模式允許你使用各種不同樣式的視圖來存取同一個伺服器端的程式碼。它包括任何WEB(HTTP)瀏覽器或無線瀏覽器(wap),例如,使用者可以透過電腦也可透過手機來訂購某樣產品,雖然訂購的方式不一樣,但處理訂購產品的方式是一樣的。由於模型回傳的資料沒有進行格式化,所以同樣的構件能被不同的介面使用。例如,許多資料可能用HTML來表示,但是也有可能用WAP來表示,而這些表示所需的指令是改變視圖層的實作方式,而控制層和模型層不需要做任何改變。 <br/>3.較低的生命週期成本<br/> MVC使開發和維護使用者介面的技術含量降低。 <br/>4.快速的部署<br/> 使用MVC模式使開發時間得到相當大的縮減,它使程式設計師(Java開發人員)集中精力於業務邏輯,介面程式設計師(HTML和JSP開發人員)集中精力於表現形式上。 <br/>5.可維護性<br/> 分離視圖層和業務邏輯層也使得WEB應用更容易維護和修改。 <br/>6.有利於軟體工程化管理<br/># 由於不同的層各司其職,每一層不同的應用具有某些相同的特徵,有利於透過工程化、工具化管理程序代碼。
擴充功能:
WAP(Wireless Application Protocol)為無線應用協定,是一項全球性的網路通訊協定。 WAP讓行動Internet 有了一個通行的標準,其目標是將Internet的豐富資訊及先進的業務引入到行動電話等無線終端之中。 WAP定義可通用的平台,把目前Internet網上HTML語言的信息轉換成用WML(Wireless Markup Language)描述的信息,顯示在移動電話的顯示屏上。 WAP只要求行動電話和WAP代理伺服器的支持,而不要求現有的行動通訊網絡協定做任何的改動,因而可以廣泛地應用於GSM、CDMA、 TDMA、3G等多種網路。 隨著行動上網成為Internet時代新的寵兒,出現了WAP的各種應用需求。
一些手持設備,如掌上電腦,安裝微型瀏覽器後,借助WAP接入Internet。微型瀏覽器檔案很小,可較好的解決手持裝置記憶體小和無線網路頻寬#不寬的限制。雖然WAP能支援HTHL和XML,但WML才是專為小螢幕和無鍵盤手持裝置 服務的語言。 WAP也支援WMLScript。這種腳本語言類似與JavaScript,但對記憶體和CPU的要求較低,因為它基本上沒有其他#腳本語言#所包含的無用功能。
<br/>
<br/>
1、多網域載入資源
#一般情況下,瀏覽器都會對單一網域下的並發請求數(檔案載入)進行限制,通常最多有4個,那麼第5個加載項將會被阻塞,直到前面的某一個檔案載入完畢。
因為CDN檔案是存放在不同區域(不同#IP)的,所以對瀏覽器來說是可以同時載入頁面所需的所有檔案(遠不止4個),進而提高頁面載入速度。
2、檔案可能已經載入過並且儲存有快取
一些通用的js庫或css樣式庫,如jQuery,在網路中的使用是非常普遍的。當一個使用者在瀏覽你的某一個網頁的時候,很有可能他已經透過你網站使用的CDN訪問過了其他的某一個網站,恰巧這個網站同樣也使用了jQuery,那麼此時使用者瀏覽器已經快取有該jQuery檔案(同IP的同名文件如果有緩存,瀏覽器會直接使用緩存文件,不會再進行加載),所以就不會再加載一次了,從而間接的提高了網站的訪問速度。
3、高效率
你的網站做的再NB 也不會NB過百度NB過Google##吧?一個好的CDNs會提供更高的效率,更低的網路延遲和更小的丟包率。
4、分散式的資料中心
假如你的網站佈置在北京,當一個香港或更遠的用戶造訪你的站點的時候,他的資料請求勢必會很慢很慢。而CDNs則會讓使用者從離他最近的節點去載入所需的文件,所以載入速度提升就是理所當然的了。
5、內建版本控制
通常,對於CSS檔案和JavaScript函式庫來說都是有版本號碼的,你可以透過特定版本號碼從CDNs載入所需的文件,也可以使用latest載入最新版本(不建議)。
6、使用狀況分析
一般情況下CDNs提供者(如百度雲加速)都會提供資料統計功能,可以了解更多關於使用者造訪自己網站的情況,可以根據統計資料對自己的網站適時適當的做出些許調整。
7、有效防止網站被攻擊
#一般情況下CDNs 提供者也是會提供網站安全服務的。
<br/>
1. “第一公里”,這是指萬維網流量向用戶傳送的第一個出口,是網站伺服器接入互聯網的鏈路。這個出口頻寬決定了一個網站能為使用者提供的訪問速度和並發訪問量。當使用者請求量超出網站的出口頻寬,就會在出口處造成擁塞。 <br/>2. “最後一公里”,萬維網流量向用戶傳送的最後一段鏈路,即用戶接入互聯網的鏈路。用戶存取的頻寬影響用戶接收流量的能力。隨著電信業者的大力發展,用戶的接取頻寬得到了很大改善,「最後一公里」問題基本上得到解決。 <br/>3. ISP互聯,即網際網路服務供應商之間的互聯,例如中國電信和中國聯通兩個網路營運商之間的互聯互通。當某個網站伺服器部署在運營商A的機房,運營商B的用戶要訪問該網站,那就必須經過A、B之間的互聯互通點進行跨網訪問。從互聯網的架構來看,不同運營商之間的互聯互通頻寬,對任何一個運營商網路流量來說,佔比都非常小。因此,這裡也通常是網路傳輸的擁塞點。 <br/>4. 長途骨幹傳輸。首先是長距離傳輸延遲問題,其次是骨幹網路的壅塞問題,這些問題都會造成萬維網流量傳輸的擁塞。 <br/>從以上對於網路擁塞的情況分析,如果網路上的資料都使用從來源站直接交付到使用者的方法,那麼將極有可能會出現存取擁塞的情況。 <br/>如果能有一種技術方案,將資料快取在離用戶最近的地方,使用戶以最快的速度獲取,那這對於減少網站的出口頻寬壓力,減少網路傳輸的擁塞情況,將起到很大的作用。 CDN正是這樣一種技術方案。 <br/>
使用者透過瀏覽器造訪傳統的(沒有使用CDN)網站的過程如下。 <br/> <br/>1. 使用者在瀏覽器中輸入要存取的網域名稱。 <br/>2. 瀏覽器向DNS伺服器請求對該網域的解析。 <br/>3. DNS伺服器傳回該網域的IP位址給瀏覽器。 <br/>4. 瀏覽器使用該IP位址向伺服器要求內容。 <br/>5. 伺服器將使用者要求的內容傳回瀏覽器。
<br/>1. 使用者在瀏覽器中輸入要存取的網域名稱。 <br/>2. 瀏覽器向DNS伺服器請求對該網域的解析。 <br/>3. DNS伺服器傳回該網域的IP位址給瀏覽器。 <br/>4. 瀏覽器使用該IP位址向伺服器要求內容。 <br/>5. 伺服器將使用者要求的內容傳回瀏覽器。
如果使用了CDN,則其過程會變成以下這樣。 <br/> <br/>1. 使用者在瀏覽器中輸入要存取的網域名稱。 <br/>2. 瀏覽器向DNS伺服器請求對網域名稱進行解析。由於CDN對網域解析進行了調整,DNS伺服器會最終將網域的解析權交給CNAME指向的CDN專用DNS伺服器。 <br/>3. CDN的DNS伺服器將CDN的負載平衡設備IP位址回傳給使用者。 <br/>4. 使用者向CDN的負載平衡設備發起內容URL存取請求。 <br/>5. CDN負載平衡設備會為使用者選擇一台合適的快取伺服器提供服務。 <br/>選擇的依據包括:根據使用者IP位址,判斷哪一台伺服器距離使用者最近;根據使用者所要求的URL中攜帶的內容名稱,判斷哪一台伺服器上有使用者所需內容;查詢各個伺服器的負載情況,判斷哪一台伺服器的負載較小。 <br/>基於上述這些依據的綜合分析之後,負載平衡設定會把快取伺服器的IP位址傳回給使用者。 <br/>6. 使用者向快取伺服器發出請求。 <br/>7. 快取伺服器回應使用者要求,將使用者所需內容傳送到使用者。 <br/>如果這台快取伺服器上並沒有用戶想要的內容,而負載平衡設備依然將它分配給了用戶,那麼這台伺服器就要向它的上一級快取伺服器請求內容,直至追溯到網站的來源伺服器將內容拉取到本機。
<br/>1. 使用者在瀏覽器中輸入要存取的網域名稱。 <br/>2. 瀏覽器向DNS伺服器請求對網域名稱進行解析。由於CDN對網域解析進行了調整,DNS伺服器會最終將網域的解析權交給CNAME指向的CDN專用DNS伺服器。 <br/>3. CDN的DNS伺服器將CDN的負載平衡設備IP位址回傳給使用者。 <br/>4. 使用者向CDN的負載平衡設備發起內容URL存取請求。 <br/>5. CDN負載平衡設備會為使用者選擇一台合適的快取伺服器提供服務。 <br/>選擇的依據包括:根據使用者IP位址,判斷哪一台伺服器距離使用者最近;根據使用者所要求的URL中攜帶的內容名稱,判斷哪一台伺服器上有使用者所需內容;查詢各個伺服器的負載情況,判斷哪一台伺服器的負載較小。 <br/>基於上述這些依據的綜合分析之後,負載平衡設定會把快取伺服器的IP位址傳回給使用者。 <br/>6. 使用者向快取伺服器發出請求。 <br/>7. 快取伺服器回應使用者要求,將使用者所需內容傳送到使用者。 <br/>如果這台快取伺服器上並沒有用戶想要的內容,而負載平衡設備依然將它分配給了用戶,那麼這台伺服器就要向它的上一級快取伺服器請求內容,直至追溯到網站的來源伺服器將內容拉取到本機。
在網站和使用者之間引入CDN之後,使用者不會有任何與原來不同的感覺。 <br/>使用CDN服務的網站,只需將其域名的解析權交給CDN的負載平衡設備,CDN負載平衡設備將為用戶選擇一台合適的快取伺服器,用戶透過訪問這台快取伺服器來獲取自己所需的數據。 <br/>由於快取伺服器部署在網路營運商的機房,而這些營運商又是用戶的網路服務供應商,因此用戶可以以最短的路徑,最快的速度對網站進行存取。因此,CDN可以加速使用者存取速度,減少源站中心負載壓力。
<br/>
<br/>
負載平衡策略:
1. 輪化和平衡(Round Robin):每一次來自網路的請求輪流分配給內部中的伺服器,從1至N然後重新開始。此種均衡演算法適合於伺服器群組中的所有伺服器都有相同的軟硬體配置並且平均服務請求相對均衡的情況。
2. 權重輪循均衡(Weighted Round Robin):根據伺服器的不同處理能力,每個伺服器分配不同的權值,使其能夠接受相應權數值數的服務要求。例如:伺服器A的權值被設計成1,B的權值是3,C的權值是6,則伺服器A、B、C將分別接受到10%、30%、60%的服務請求。此種均衡演算法能確保高效能的伺服器得到更多的使用率,避免低效能的伺服器負載過重。
3. 隨機平衡(Random):將網路的請求隨機指派給內部中的多個伺服器。
4. 權重隨機均衡(Weighted Random):此均衡演算法類似權重輪循演算法,不過在處理請求分擔時是個隨機選擇的過程。
5. 回應速度平衡(Response Time):負載平衡設備對內部各伺服器發出一個探測請求(例如Ping),然後根據內部中各伺服器對探測請求的最快回應時間來決定哪一台伺服器來回應客戶端的服務請求。此種均衡演算法能較好的反映伺服器的目前運作狀態,但這最快回應時間僅指的是負載平衡設備與伺服器間的最快回應時間,而不是客戶端與伺服器間的最快回應時間。
6. 最少連線數均衡(Least Connection):客戶端的每個請求服務在伺服器停留的時間可能會有較大的差異,隨著工作時間加長,如果採用簡單的輪轉或隨機均衡演算法,每一台伺服器上的連線進程可能會產生極大的不同,並沒有達到真正的負載平衡。最少連線數平衡演算法對內部中需負載的每一台伺服器都有一個資料記錄,記錄目前該伺服器正在處理的連線數量,當有新的服務連線請求時,將把目前請求指派給連線數最少的伺服器,使均衡更加符合實際情況,負載更加平衡。此種均衡演算法適合長時處理的請求服務,如FTP。
7. 處理能力平衡:此均衡演算法將服務請求分配給內部中處理負載(根據伺服器CPU型號、CPU數量、記憶體大小及目前連線數等換算而成)最輕的伺服器,由於考慮到了內部伺服器的處理能力及目前網路運作狀況,所以此種均衡演算法相對來說更加精確,尤其適合運用到第七層(應用層)負載平衡的情況下。
8. DNS回應均衡(Flash DNS):在Internet上,無論是HTTP、FTP或是其它的服務請求,客戶端通常都是透過網域名稱解析來找到伺服器確切的IP位址的。在此均衡演算法下,分處在不同地理位置的負載平衡設備收到同一個客戶端的網域解析請求,並在同一時間內將此網域解析成各自相對應伺服器的IP位址(即與此負載平衡設備在同一位地理位置的伺服器的IP位址)並傳回給客戶端,則用戶端將以最先收到的網域名稱解析IP位址來繼續要求服務,而忽略其它的IP位址回應。在種平衡策略適合應用在全域負載平衡的情況下,對本地負載平衡是沒有意義的。
服務故障的偵測方式與能力:
1. Ping偵測:以ping的方式偵測伺服器及網路系統狀況,此種方式簡單快速,但只能大致檢測出網路及伺服器上的作業系統是否正常,對伺服器上的應用服務偵測就無能為力了。
2. TCP Open偵測:每個服務都會開放某個透過TCP連接,偵測伺服器上某個TCP埠(如Telnet的23口,HTTP的80口等)是否開放來判斷服務是否正常。
3. HTTP URL偵測:例如向HTTP伺服器發出一個對main.html檔案的存取請求,如果收到錯誤訊息,則認為伺服器發生故障。
<br/>
<br/>
1. 動態內容快取
#2.瀏覽器快取
3.伺服器快取
4. 反向代理快取
#5. 分散式快取
對於頁面快取具體方法,有許多實作方法,如類似 Smarty 的模板引擎或類似 Zend、Diango 的 MVC 框架,控制器和視圖分離,控制器很方便的擁有自己的快取控制權。
通常,我們將動態內容的快取儲存在磁碟上,磁碟提供了廉價的、儲存大量檔案的方式,不用擔心由於空間問題而淘汰緩存,這是一種簡單且容易部署的方法。但是,還是可能造成 cache 目錄下存在大量快取檔案的可能,從而使CPU 在遍歷目錄時花費大量時間,針對這個問題,可以使用快取目錄分級來解決這一問題,從而將每個目錄下的子目錄或文件數量控制在少量範圍內。這樣,在儲存大量快取檔案的情況下,可以減少 CPU 遍歷目錄的時間消耗。
當快取資料儲存在磁碟檔案中時,每次快取載入和過期檢查都存在磁碟I/O 開銷,同時也受磁碟負載影響,如果磁碟I/O 負載大,則快取文件的I/O 操作會存在一定的延遲。
另外,可以將快取放在本機記憶體中,借助PHP 的APC 模組或PHP 快取擴充XCache 可以很方便的實現,這樣,載入快取時就沒有任何磁碟I /O 操作。
最後,也可以將快取儲存在獨立的快取伺服器中,利用 memcached 可以很方便的透過 TCP 將快取儲存在其他伺服器。使用memcached,速度會比使用本機記憶體稍慢,但相比將快取存放到本機內存,使用memcached 來實現緩存有兩個優勢:
緩存有效期機制來檢查,主要兩種機制:
隨時強行清除快取的控制方法。
1.1.3 局部無快取在某些情況下,需要頁面中某塊區域的內容及時更新,如果因為一塊區域需要及時更新而重建整個頁面快取的話,會顯得不值得。在流行的模板框架中,都提供了局部無緩存的支持,如 Smary。 1.2 靜態化內容前面的方法需動態地控制是否使用緩存,靜態化方法將動態內容產生靜態內容,然後讓用戶直接請求靜態內容,大幅提高吞吐率。 同樣的,對於靜態化內容,同樣需要更新,一般有兩種方法:瀏覽器是Web 網站的重要組成部分。如果將內容快取在瀏覽器上,不僅可以減少伺服器運算開銷,還能避免不必要的傳輸和頻寬浪費。為了在瀏覽器端儲存快取內容,一般是在使用者的文件系統中建立一個目錄用來儲存快取文件,並給每個快取文件打上一些必要標籤,如過期時間等。另外,不同瀏覽器在儲存快取檔案時會有細微差別。
2.1 實作瀏覽器快取內容儲存在瀏覽器端,而內容由Web 伺服器生成,要利用瀏覽器緩存,瀏覽器和Web 伺服器之間必須溝通,這就是HTPP中的「快取協商」。当 Web 服务器接收到浏览器请求后,Web 服务器需要告知浏览器哪些内容可以缓存,一旦浏览器知道哪些内容可以缓存后,下次当浏览器需要请求这个内容时,浏览器便不会直接向服务器请求完整内容,二是询问服务器是否可以使用本地缓存,服务器在收到浏览的询问后回应是使用浏览器本地缓存还是将最新内容传回给浏览器。
Last-Modified
Last-Modified 是一种协商方式。通过动态程序为 HTTP 相应添加最后修改时间的标记
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");此时,Web 服务器的响应头部会多出一条:
Last-Modified: Fri, 9 Dec 2014 23:23:23 GMT
这代表 Web 服务器对浏览器的暗示,告诉浏览器当前请求内容的最后修改时间。收到 Web 服务器响应后,再次刷新页面,注意到发出的 HTTP 请求头部多了一段标记:
If-Modified-Since: Fri, 9 Dec 2014 23:23:23 GMT
这表示浏览器询问 Web 服务器在该时间后是否有更新过请求的内容,此时,Web 服务器需要检查请求的内容在该时间后是否有过更新并反馈给浏览器,这其实就是缓存过期检查。
如果这段时间里请求的内容没有发生变化,服务器做出回应,此时,Web 服务器响应头部:
HTTP/1.1 304 Not Modified
注意到此时的状态码是304,意味着 Web 服务器告诉浏览器这个内容没有更新,浏览器使用本地缓存。如下图所示: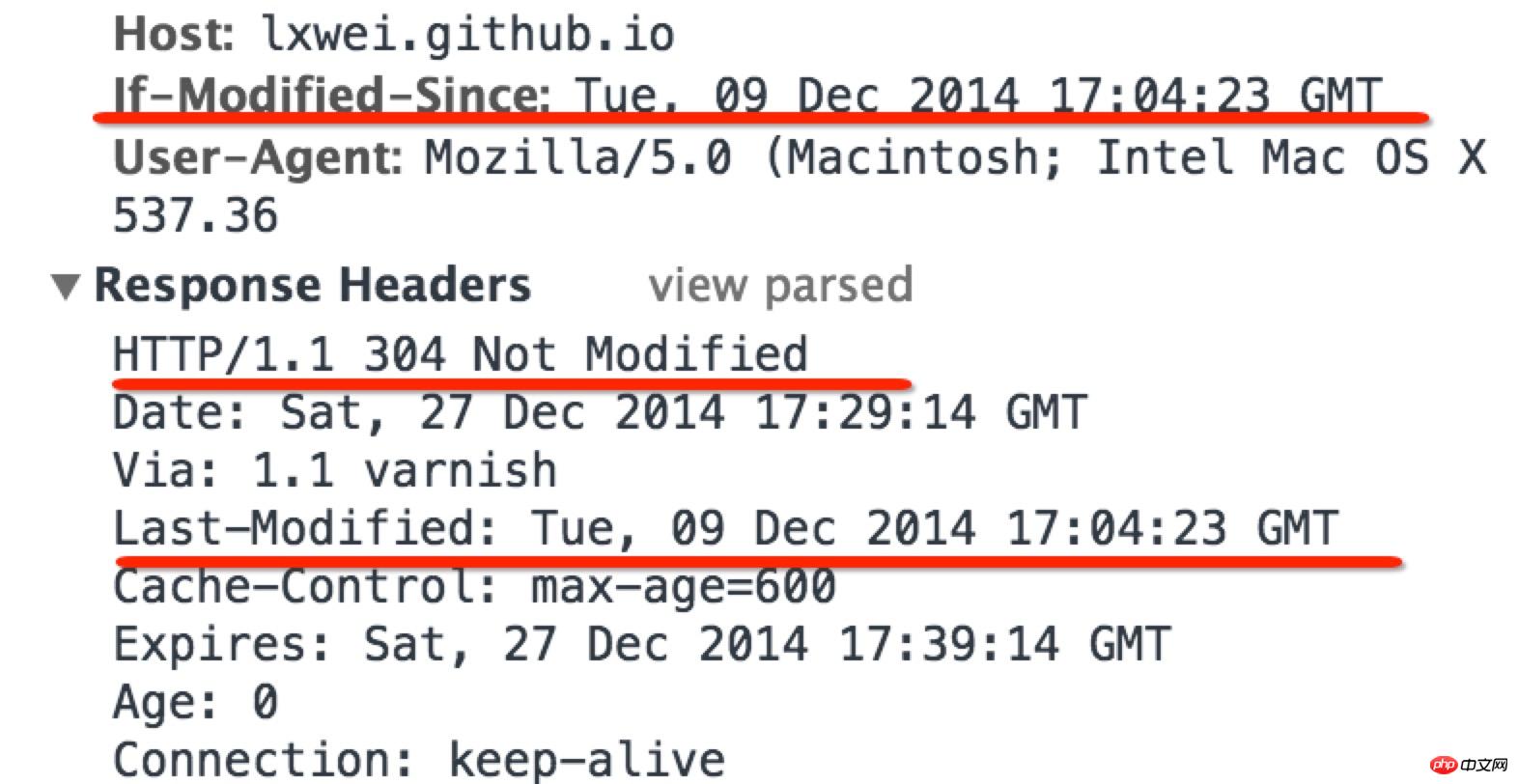
ETag
HTTP/1.1 还支持ETag缓存协商方法,与最后过期时间不同的是,ETag不再采用内容的最后修改时间,而是采用一串编码来标记内容,称为ETag,如果一个内容的 ETag 没有变化,那么这个内容就一定没有更新。
ETag 由 Web 服务器生成,浏览器在获得内容的 ETag 后,会在下次请求该内容时,在 HTTP 请求头中附加上相应标记来询问服务器该内容是否发生了变化:
If-None-Match: "87665-c-090f0adfadf"
这时,服务器需要重新计算这个内容的 ETag,并与 HTTP 请求中的 ETag 进行对比,如果相同,便返回 304,若不同,则返回最新内容。如下图所示,服务器发现请求的 ETag 与重新计算的 ETag 不同,返回最新内容,状态码为200。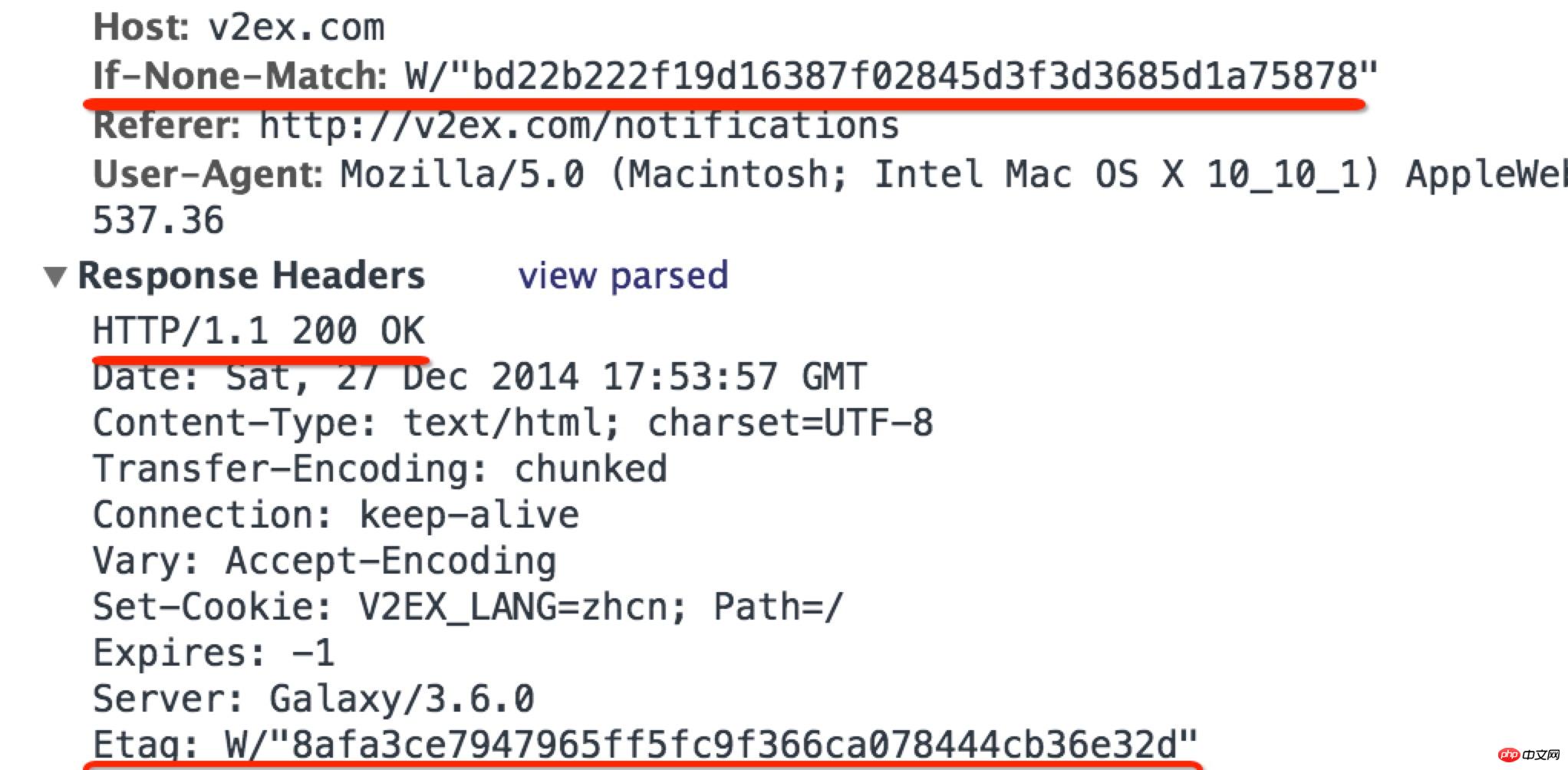
Last-Modified VS ETag
基于最后修改时间的缓存协商存在一些缺点,如有时候文件需频繁更新,但内容并没有发生变化,这种情况下,每次文件修改时间变化后,无论内容是否发生变化,都会重新获取全部内容。另外,在采用多台 Web 服务器时,用户请求可能在多台服务器间变化,而不同服务器上同一文件最后修改时间很难保证完全一样,便会导致重新获取所有内容。采用 ETag 方法就可以避免这些问题。
首先,原本使用浏览器缓存的动态内容,在使用浏览器缓存后,能否获得大的吞吐率提升,关键在于是否能避免一些额外的计算开销,同事,还取决于 HTTP 响应正文的长度,若 HTTP 响应较长,如较长的视频,则能带来大的吞吐率提到。
但使用浏览器缓存的最大价值并不在此,而在于减少带宽消耗。使用浏览器缓存后,如果 Web 服务器计算后发现可以使用浏览器端缓存,则返回的响应长度将大大减少,从而,大大减少带宽消耗。
The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases.
在上面两图中,有个Expires标记,告诉浏览器该内容何时过期,在内容过期前不需要再询问服务器,直接使用本地缓存即可。
对于主流浏览器,有三种请求页面方式:
Ctrl + F5:强制刷新,使网页以及所有组件都直接向 Web 浏览器发送请求,并且不适用缓存协商,从而获取所有内容的最新版本。等价于按住 Ctrl 键后点击浏览器刷新按钮。
F5:允许浏览器在请求中附加必要的缓存协商,但不允许直接使用本地缓存,即让Last-Modified生效、Expires无效。等价于单击浏览器刷新按钮。
单击浏览器地址栏“转到”按钮或通过超链接跳转:浏览器对于所有没过期的内容直接使用本地缓存,Expires只对这种方式生效。等价于在地址栏输入 URL 后回车。
| Last-Modified | Expires | |
|---|---|---|
| Ctrl F5 | 無效 | 無效 |
| F5 | #有效 | 無效 |
| 轉到 | 有效 | 有效 |
Expires指定的过期时间来源于 Web 服务器的系统时间,如果与用户本地时间不一致,就会影响到本地缓存的有效期检查。
一般情况下,操作系统都使用基于 GMT 的标准时间,然后通过时区来进行偏移计算,HTTP 中也使用 GMT 时间,所以,一般不会因为时区导致本地与服务器相差数个小时,但没人能保证本地时间与服务器一直,甚至有时服务器时间也是错误的。
针对这个问题,HTTP/1.1 添加了标记 Cache-Control,如上图1所示,max-age 指定缓存过期的相对时间,单位是秒,相对时间指相对浏览器本地时间。目前,当 HTTP 响应中同时含有 Expires 和 Cache-Control 时,浏览器会优先使用 Cache-Control。
HTTP 是浏览器与 Web 服务器沟通的语言,且是它们唯一的沟通方式,好好学学 HTTP 吧!
前面提到的动态内容缓存和静态化基本都是通过动态程序来实现的,下面讨论 Web 服务器自己实现缓存机制。
Web 服务器接收到 HTTP 请求后,需要解析 URL,然后将 URL 映射到实际内容或资源,这里的“映射”指服务器处理请求并生成响应内容的过程。很多时候,在一段时间内,一个 URL 对应一个唯一的响应内容,比如静态内容或更新不频繁的动态内容,如果将最终内容缓存起来,下次 Web 服务器接收到请求后可以直接将响应内容返回给浏览器,从而节省大量开销。现在,主流 Web 服务器都提供了对这种类型缓存的支持。
当使用 Web 服务器缓存时,如果直接命中,那么将省略后面的一系列操作,如 CPU 计算、数据库查询等,所以,Web 服务器缓存能带来较大性能提升,但对于普通 HTML 也,带来的性能提升较有限。
那么,缓存内容存储在什么位置呢?一般来说,本机内存和磁盘是主要选择,也可以采用分布式设计,存储到其它服务器的内存或磁盘中,这点跟前面提到的动态内容缓存类似,Apache、lighttpd 和 Nginx 都提供了支持,但配置上略有差别。
提到缓存,就不得不提有效期控制。与浏览器缓存相似,Web 服务器缓存过期检查仍然建立在 HTTP/1.1 协议上,要指定缓存有效期,仍然是在 HTTP 响应头中加入 Expires 标记,如果希望不缓存某个动态内容,那么最简单的办法就是使用:
header("Expires: 0");这样一来,Web服务器就不会将这个动态内容缓存起来,当然,也有其它方法实现这个功能。
如果动态内容没有输出 Expires 标记,也可以采用 Last-Modified来实现,具体方法不再叙述。
那么,是否可以使用 Web 服务器缓存取代动态程序自身的缓存机制呢?当然可以,但有些注意:
让动态程序依赖特定 Web 服务器,降低应用的可移植性。
Web 服务器缓存机制实质上是以 URL 为键的 key-value 结构缓存,所以,必须保证所有希望缓存的动态内容有唯一的 URL。
编写面向 HTTP 缓存友好的动态程序是唯一需要考虑的事。
对静态内容,特别是大量小文件站点, Web 服务器很大一部分开销花在了打开文件上,所以,可以考虑将打开后的文件描述符直接缓存到 Web 服务器的内存中,从而减少开销。但是,缓存文件描述符仅仅适用于静态内容,而且仅适用于小文件,对大文件,处理它们的开销主要在传送数据上,打开文件开销小,缓存文件描述符带来的收益小。
代理(Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(Proxy Server)。
上面是維基百科對代理的定義,在這種情況下,用戶隱藏在代理伺服器後,那麼,反向代理伺服器便剛好與此相反,Web 伺服器隱藏在代理伺服器後,這種機制即反向代理(Reverse Proxy),同樣的,實作這種機制的伺服器,便稱為反向代理伺服器(Reverse Proxy Server)。我們通常稱反向代理伺服器後的Web 伺服器為後端伺服器(Back-end Server),相應的,反向代理伺服器稱為前端伺服器(Front-end Server),通常,反向代理伺服器暴露在互聯網中,後端的Web 伺服器透過內部網路與它相連,使用者將透過反向代理伺服器來間接存取Web 伺服器,這既帶來一定的安全性,也可以實現基於快取的加速。
有很多方式可以實作反向代理,如最常見的 Nginx 伺服器就可以作為反向代理伺服器。
使用者瀏覽器、Web 伺服器要想正常運作,都需要經過反向代理伺服器,所以,反向代理伺服器擁有很大的控制權,可以透過任何手段重寫經過它的HTTP 頭訊息,也可以透過其他自訂機制來直接幹預快取策略。從前面的內容知道,HTTP 頭資訊決定內容是否可以被緩存,所以,反向代理伺服器以提高效能的原則可以修改經過它的資料的HTTP 頭訊息,決定哪些內容可以被緩存,哪些不能被緩存。
反向代理伺服器也提供了清除快取的功能,但是,與動態內容快取不同的是,在動態內容快取中,我們可以透過主動刪除快取的方法實現快取到期之前的更新,而基於 HTTP 的反向代理快取機制則不容易做到,後端的動態程式無法做到主動刪除某個快取內容,除非清空反向代理伺服器上的快取區。
現在已經有許多成熟的分散式快取系統,例如 memcached。為了實現高速緩存,我們不會將緩存內容放在磁碟上,基於這個原則,memcached 使用物理內存作為緩存區,使用 key-value 的方式存儲數據,這是一種單索引的結構和數據組織形式,我們將每個key 以及對應value 合起來稱為資料項,所有資料項之間彼此獨立,每個資料項以key 作為唯一索引,使用者可以透過key 來讀取或更新這個資料項,memcached 使用基於key的hash 演算法來設計儲存資料結構,使用精心設計的記憶體分配器,使得資料項查詢時間複雜度達到O(1)。
memcached 使用基於 LRU(Lease Recently Used) 演算法的淘汰機制淘汰數據,同時,也可以為數據項設定過期時間,同樣的,過期時間的設定在前面已經討論過了。
作為分散式快取系統,memcached 可以運行在獨立伺服器上,動態內容透過 TCP Socket 來訪問,在這種情況下,memcached 本身的網路並發處理模型就顯得十分重要。 memcached 使用 libevent 函式庫來實作網路並發模型,可以在較大並髮使用者數環境下使用 memcached。
在使用快取系統實現讀取操作時,相當於使用了資料庫的“前讀取快取”,可以較大的提高吞吐率。
對於寫入操作,快取系統也能帶來巨大好處。通常的資料寫操作包括插入、更新、刪除,這些寫入操作往往同時伴隨著查找和索引更新,往往帶來巨大開銷。在使用分散式快取時,我們可以暫時將資料儲存在快取中,然後進行批次寫入操作。
memcached 作為一個分散式快取系統,可以出色的完成任務,同時,memcached 也提供了協議,讓我們可以取得它的即時狀態,其中有幾個重要資訊:
空間使用率:專注於快取空間使用率,可以讓我們知道何時需要為快取系統擴容,以避免因快取空間已滿造成的資料被動淘汰。
快取命中率
I/O 流量:反映了快取系統的工作量,可以從中得知 memcached 是空閒還是忙碌。
#並發處理能力、快取空間容量等都可能到達極限,擴充在所難免。
當存在多台快取伺服器後,我們面臨的問題是,如何將快取資料均衡的分佈在多台快取伺服器上?在這種情況下,可以選擇基於 key 的分割方法,將所有資料項目的 key 均衡分佈在不同伺服器上,例如採取取餘的方法。在這種情況下,當我們擴展系統後,由於分區演算法的改變,會需要將快取資料從一台快取伺服器遷移到另一台快取伺服器,實際上,根本不需要考慮遷移,因為是快取數據,重建快取即可。
快取如何使用還得具體問題具體分析。舉例來講,當年在百度實習時,僅僅是一次搜索的結果,使用動態內容緩存都分了很多層,總之是能用緩存就用緩存,能儘早用緩存就儘早用緩存;而在我現在工作的新創公司有贊,現在也就使用了redis 做動態內容緩存,隨著業務量的增大,正在一步步完善,哦,差點忘了,還有瀏覽器緩存。
<br/>
加快頁面開啟瀏覽速度,靜態頁面無需連接資料庫開啟速度較動態頁面有明顯提高;
有利於搜尋引擎優化SEO ,Baidu、Google都會優先收錄靜態頁面,不僅被收錄的快還收錄的全;
減輕伺服器負擔,瀏覽網頁無需調用系統資料庫;
#網站比較安全,HTML頁面不會受php相關漏洞的影響;觀看一下大一點的網站基本上都是靜態頁面,而且可以減少攻擊,防sql注入。
當然有好處,也有不足?
訊息不同步。只有重新產生HTML頁面,才能保持資訊同步。
伺服器儲存問題。資料一直增加,靜態HTML頁面會不斷增加,會佔用大量的磁碟。需要考慮這個問題
靜態化演算法的精確度。要良好的處理資料與網頁模板,及各種文件連結路徑的問題,這就要求我們在靜態化的演算法中考慮到方方面面。稍有細小疏忽,將導致生成的頁面中存在這樣或那樣的錯誤鏈接,甚至存在死鏈。因此,我們必須恰到好處的解決這些問題。既不能增加演算法的可能性,又要照顧到各個面向。做到這一點,的確不容易。
參考文章:《分享常見的幾種頁面靜態化的方法》
# PHP靜態化的簡單理解就是讓網站產生頁面以靜態HTML的形式展現在訪客面前,PHP靜態化分純靜態化和偽靜態化,兩者的差別在於PHP產生靜態頁面的處理機制不同。
純靜態化:PHP產生HTML檔案<br/>偽靜態化:把內容存放在nosql記憶體(memcached),然後造訪頁面的時候,直接從記憶體裡面讀取。
參考文章:《大型網站的靜態化處理》
大型網站(高訪問量,高並發量),如果是靜態網站,可以透過擴展足夠多的網頁伺服器,然後支援超大規模的並發存取。
如果是一個動態的網站,特別是使用到了資料庫的網站是很難做到透過增加web伺服器數量的方式來有效的增加網站並發存取能力的。例如淘寶,京東。
大型靜態網站之所以能夠快速回應高並發,因為他們盡量把動態網站靜態化。
js,css,img等資源,服務端合併在返回
CDN 內容分發網路技術【網路傳輸的效率跟距離長短有關係的原理,透過演算法,計算最近的靜態伺服器節點】
web伺服器動靜結合。頁面有一部分是一直不變的,像是 header, footer 部分。那麼這一部分是否可以放在快取。 web伺服器 apache或ngnix, appache有一個模組叫做ESI,CSI。能夠動靜拼接。把靜態的部分緩存在 web伺服器上,然後和伺服器回傳的動態頁面拼接在一起。
瀏覽器實現動靜結合,前端MVC。
#1.靜態頁面
優點: 相對於其他兩種頁面(動態頁面和偽靜態頁面),速度最快,而且不需要從資料庫裡面提取數據,速度快的同時,也不會對伺服器產生壓力。
缺點:由於資料都是儲存在HTML裡面,所以導致檔案非常大。而最嚴重的問題是,更改原始碼必須全部更改,而不能改一個地方,全站靜態頁面就自動更改了。如果是大型網站有較多的數據,那會佔用大量的伺服器空間,每次新增內容都會產生新的HTML頁面。如果不是專業人士維護比較麻煩。
2.動態頁面
優點:空間使用量非常小,一般數萬個資料的網站,使用動態頁面,可能只有幾M的檔案大小,而使用靜態頁面少則十幾M,多則幾十M甚至更多。因為資料庫是從資料庫裡面調出來的,如果需要修改某些值,直接更改資料庫,那麼所有的動態網頁,就會自動更新了。這一點相比靜態頁面優點就顯而易見了。
缺點:使用者存取速度較慢,為什麼會造訪動態頁面較慢呢?這個問題要從動態頁面的存取機制說起了,其實我們的伺服器上面有一個解釋引擎,當使用者造訪的時候,這個解釋引擎就會把動態頁面翻譯為靜態頁面,這樣大家就能夠在瀏覽器裡面查看源碼了。而這個原始碼就是解釋引擎翻譯之後的原始碼。除訪問速度較慢以外,動態頁面的資料是從資料庫裡面呼叫過來的如果訪問的人數較多,資料庫的壓力會非常大。不過現在的動態程式多數都使用了快取技術。但是整體來講,動態頁面對於伺服器的壓力比較大一些。同時動態頁面的網站一般對於伺服器的要求比較高一些,同時造訪的人越多也會造成伺服器的壓力越大。
3.偽靜態頁面
# 透過url重寫,index.php 變成index.html<br/>
偽靜態頁面定義:「假」靜態頁面,實質上是動態頁面。
優點:相比靜態頁面而言,並沒有速度上的明顯提升,因為是「假」靜態頁面,其實還是一個動態頁面,也是同樣需要翻譯為靜態頁面的。最大的好處就是讓搜尋引擎(Search Engine)把自己的網頁當作靜態頁面來處理。
缺點:顧名思義,“偽靜態”就是“假靜態”,搜尋引擎不會把他當做靜態頁面來處理,這只是我們靠經驗考邏輯去分析的,並不一定準確。或許搜尋引擎直接把它認為是動態頁面。
簡單總結:
#靜態頁面最快存取;維護較為麻煩。
動態頁面佔用空間小、維護簡單;存取速度慢,如果造訪的人多,會對資料庫造成壓力。
使用純靜態和偽靜態對於SEO(Search Engine Optimization:搜尋引擎最佳化)沒有本質上的差異。
使用偽靜態將佔用一定量的CPU佔用率,大量使用會導致CPU超負荷。
<br/>
這段時間有幾次接觸到了css sprites的概念,一個就是在用css做滑動門的時候,另外一個就是在用YSlow分析網站性能的時候,於是對css sprites這個概念產生了濃厚的興趣。在網路上找了很多的資料,但可惜的是大部分都是只言片語,其中很多都是直接翻譯國外的資料,也有直接推薦國外的資料網站,無奈英語沒有過關,基本上沒有理解到什麼css sprites,更別談如何使用了。
最後還是在藍色理想中的一篇文章受到啟發,琢磨了老半天,才算弄清楚裡面的內涵,下面將透過本人的理解幫助其他人更加快速的去掌握css sprites。
先簡單介紹下概念,關於它的概念,網路上那到處都是,這裡簡單的提下。
什麼是css sprites
css sprites直譯過來就是CSS精靈,但是這種翻譯顯然是不夠的,其實就是透過將多個圖片融合到一副圖中,然後透過CSS的一些技術佈局到網頁上。這樣做的好處也是顯而易見的,因為圖片多的話,會增加http的請求,無疑促使了網站性能的減低,特別是圖片特別多的網站,如果能用css sprites降低圖片數量,帶來的將是速度的提升。
下面我们来用一个实例来理解css sprites,受蓝色理想中的《制作一副扑克牌系列教程》启发。
我们仅仅只需要制作一个扑克牌,拿黑桃10为例子。
可以直接把蓝色理想中融合好的一幅大图作为背景,这也是css sprites的一个中心思想,就是把多个图片融进一个图里面。

这就是融合后的图,相信对PS熟悉的同学应该很容易的理解,通过PS我们就可以组合多个图为一个图。
现在我们书写html的结构:
<p> <p> <b class="N1 n10"></b> <em class="First small_up1"></em> <span class="A1 up1"></span> <span class="A2 up1"></span> <span class="A3 down1"></span> <span class="A4 down1"></span> <span class="B1 up1"></span> <span class="B2 down1"></span> <span class="C1 up1"></span> <span class="C2 up1"></span> <span class="C3 down1"></span> <span class="C4 down1"></span> <em class="Last small_down1"></em> <b class="N2 n10_h"></b> </p> </p>
在这里我们来分析强调几点:
一:card为这个黑桃十的盒子或者说快,对p了解的同学应该很清楚这点。
二:我用span,b,em三种标签分别代表三种不同类型的图片,span用来表标中间的图片,b用来表示数定,em用来表示数字下面的小图标。
三:class里面的声明有2种,一个用来定位黑桃10中间的图片的位置,一个用来定义方向(朝上,朝下)。
上面是p基本概念,这还不是重点,不过对p不太清楚的同学可以了解。
下面我们重点谈下定义CSS:
span{display:block;width:20px;height:21px; osition:absolute;background:url(images/card.gif) no-repeat;}
这个是对span容器的CSS定义,其他属性就不说了,主要谈下如何从这个里面来理解css sprites。
背景图片,大家看地址就是最开始我们融合的一张大图,那么如何将这个大图中的指定位置显示出来呢?因为我们知道我们做的是黑桃10,这个大图其他的图像我们是不需要的,这就用到了css中的overflow:hidden;
但大家就奇怪了span的CSS定义里面没有overflow:hidden啊,别急,我们已经在定义card的CSS里面设置了(这是CSS里面的继承关系):
.card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;}
理解到这点还不够,还要知道width:125px;height:170px; 这个可以理解成是对这个背景图片的准确切割,当然其实并不是切割,而是把多余其他的部分给隐藏了,这就是overflow:hidden的妙用。
通过以上的部分的讲解,你一定可以充分的把握css sprites的运用,通过这个所谓的“切割”,然后再通过CSS的定位技术将这些图准确的分散到这个card里面去!
PS:CSS的定位技术,大家可以参考其他资料,例如相对定位和绝对定位,这里我们只能尝试用绝对定位。
最后我们来补充一点:
为什么要采取这样的结构?
span这个容器是主要作用就是存放这张大的背景图片,并在里面实现”切割“,span里面切割后的背景是所有内容块里面通用的!
后面class为什么要声明2个属性?
很显然,一个是用来定位内容块的位置,一个是用来定义内容块中的图像的朝上和朝下,方位的!
下面我们附上黑桃10的完整源码:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>制作一幅扑克牌--黑桃10</title>
<style type="text/css"><!--
.card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;}
/*中间图片通用设置*/
span{display:block;width:20px;height:21px; position:absolute;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;}
/*小图片通用设置*/
b{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat; overflow:hidden;}
/*数字通用设置*/
em{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;overflow:hidden;}
/*各坐标点位置*/
.N1{left:1px;top:8px;}
.First{left:5px;top:20px;}
.A1{left:20px;top:20px;}
.A2{left:20px;top:57px;}
.A3{left:20px;top:94px;}
.A4{left:20px;top:131px;}
.B1{left:54px;top:38px;}
.B2{left:54px;top:117px;}
.C1{left:86px;top:20px;}
.C2{left:86px;top:57px;}
.C3{left:86px;top:94px;}
.C4{left:86px;top:131px;}
.Last{bottom:20px;right:0px;}
.N2{bottom:8px;right:5px;
}
/*大图标黑红梅方四种图片-上方向*/
.up1{background-position:0 1px;}/*黑桃*/
/*大图标黑红梅方四种图片-下方向*/
.down1{background-position:0 -19px;}/*黑桃*/
/*小图标黑红梅方四种图片-上方向*/
.small_up1{background-position:0 -40px;}/*黑桃*/
/*小图标黑红梅方四种图片-下方向*/
.small_down1{background-position:0 -51px;}/*黑桃*/
/*A~k数字图片-左上角*/
.n10{background-position:-191px 0px;left:-4px;width:21px;}
/*A~k数字图片-右下角*/
.n10_h{background-position:-191px -22px;right:3px;width:21px;}
/*A~k数字图片-左上角红色字*/
.n10_red{background-position:-191px 0px;}
/*A~k数字图片-右下角红色字*/
.n10_h_red{background-position:-191px -33px;}
-->
</style>
</head>
<body>
<!--10字符-->
<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
</body>
</html>最后感谢蓝色理想提供的参考资料!
<br/>
<br/>
1、前言
最近工作中用到反向代理,發現網路代理的玩法還真不少,網路背後有很多需要去學習。而在此之前僅使用了過代理軟體,曾經為了訪問google,使用了代理軟體,需要在瀏覽器中配置代理的位址。我只知道有代理這個概念,並不清楚代理還有正向和反向之分,於是趕緊學習一下,補充一下知識。首先弄清楚什麼是正向代理,什麼是反向代理,然後是二者在實際使用中展示的方式是什麼樣的,最後總結一下正向代理用來做什麼,反向代理可以做什麼。
2、正向代理程式
正向代理程式類似一個跳板機,代理程式存取外部資源。

舉個例子:
我是一個用戶,我訪問不了某網站,但是我能訪問一個代理伺服器,這個代理伺服器呢,他能訪問那個我不能訪問的網站,於是我先連上代理伺服器,告訴他我需要那個無法訪問網站的內容,代理伺服器去取回,然後返回給我。從網站的角度,只在代理伺服器來取內容的時候有一次記錄,有時候並不知道是用戶的請求,也隱藏了用戶的資料,這取決於代理告不告訴網站。
客戶端必須設定正向代理伺服器,當然前提是要知道正向代理伺服器的IP位址,還有代理程式的連接埠。
例如之前使用過這類軟體例如CCproxy,http://www.ccproxy.com/ 需要在瀏覽器中設定代理程式的位址。
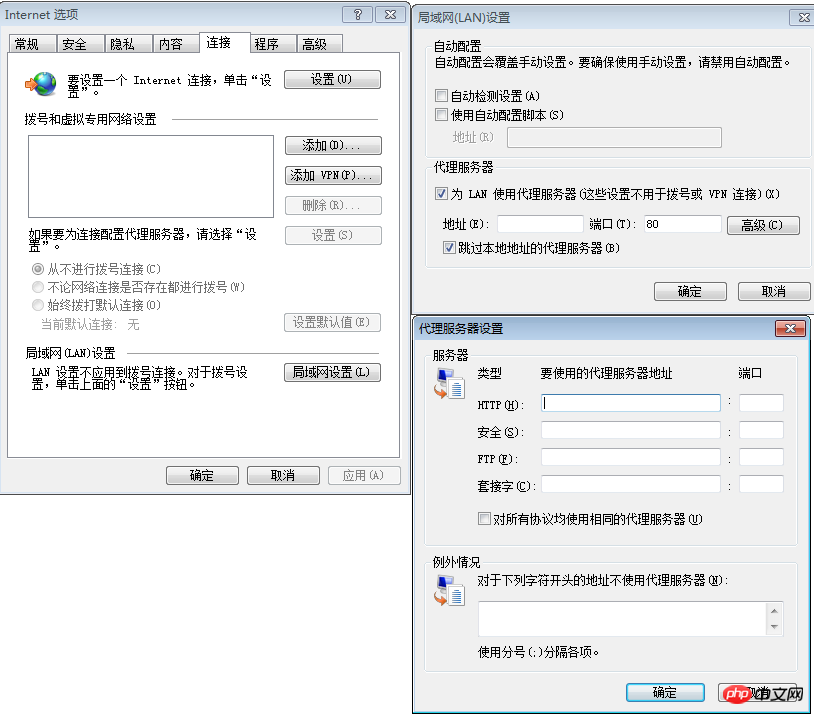
總結:正向代理 是位於客戶端和原始伺服器(origin server)之間的伺服器,為了從原始伺服器取得內容,客戶端向代理程式傳送一個請求並指定目標(原始伺服器),然後代理程式向原始伺服器轉交請求並將獲得的內容傳回給客戶端。客戶端必須要進行一些特別的設定才能使用正向代理。
正向代理程式的用途:
# (1)存取原來無法存取的資源,如google
# (2) 可以做緩存,加速存取資源
(3)對用戶端存取授權,上網進行認證
(4)代理程式可以記錄使用者存取記錄(上網行為管理),對外隱藏使用者資訊
例如CCProxy用途:

#3、反向代理
初次接觸方向代理的感覺是,客戶端是無感知代理的存在的,反向代理對外都是透明的,訪問者並不知道自己訪問的是一個代理。因為客戶端不需要任何設定就可以存取。
反向代理(Reverse Proxy)實際運作方式是指以代理伺服器來接受internet上的連線要求,然後將請求轉送給內部網路上的伺服器,並將從伺服器上得到的結果傳回給internet上請求連線的客戶端,此時代理伺服器對外就表現為一個伺服器。
反向代理的作用:
(1)保證內網的安全,可以使用反向代理提供WAF功能,阻止web攻擊
大型網站,通常將反向代理作為公網存取位址,Web伺服器是內網。
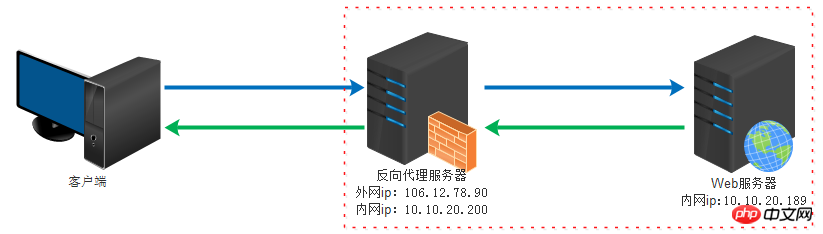
(2)負載平衡,透過反向代理伺服器來最佳化網站的負載
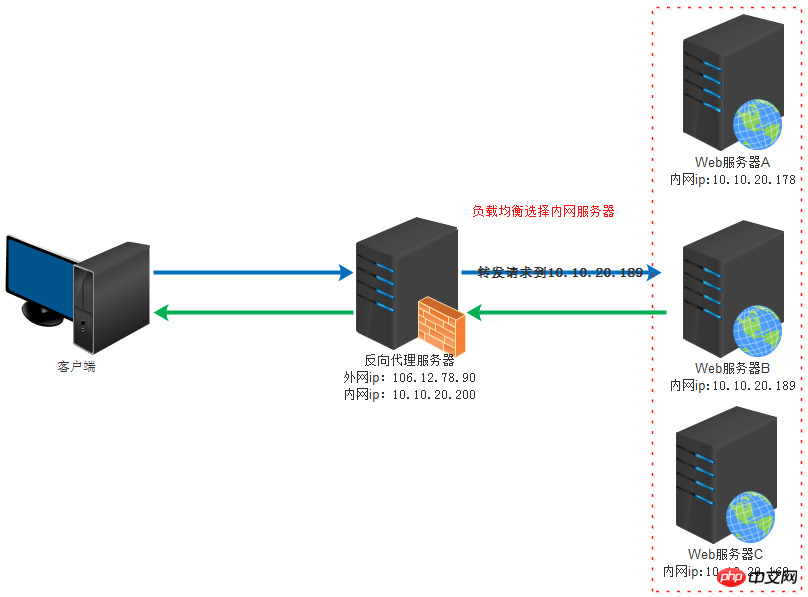
4、二者區別
借用知乎兩張圖來表達:https://www.zhihu.com/question/24723688
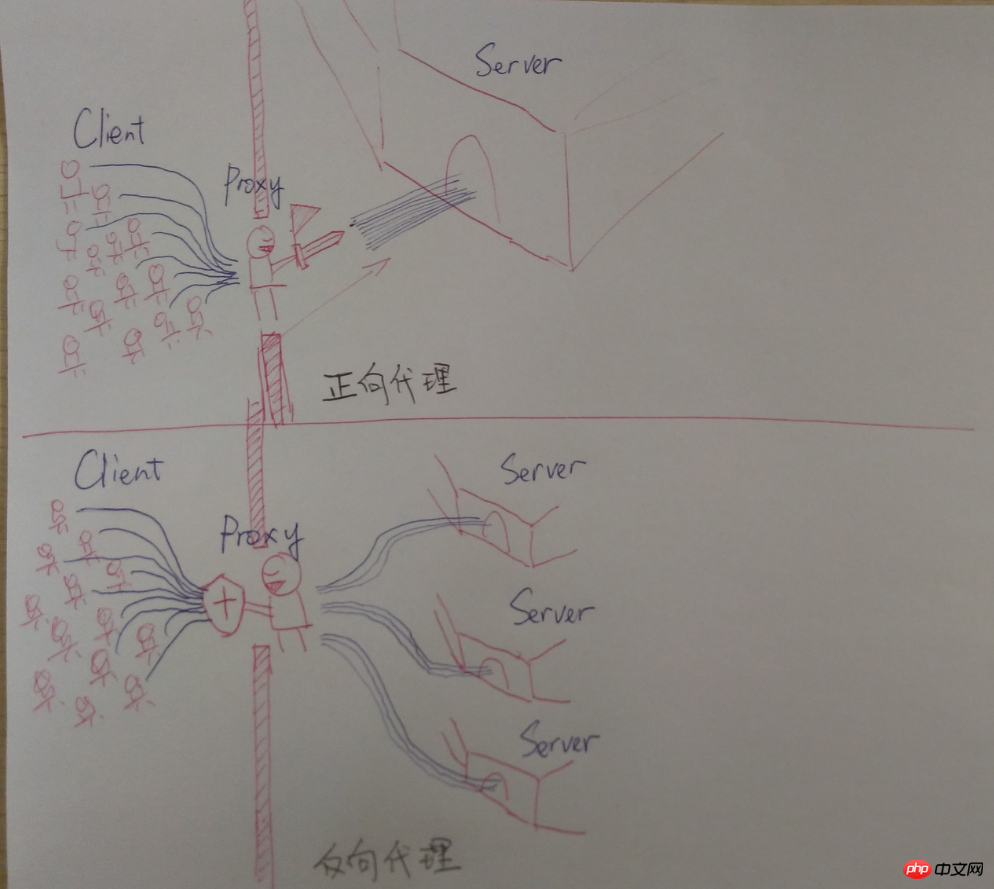
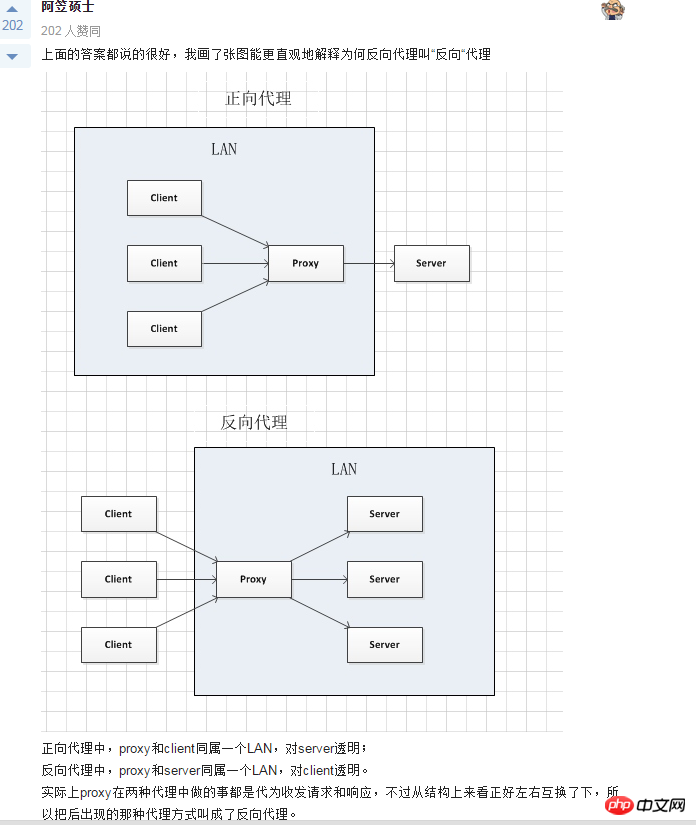
5、nginx的反向代理
nginx支援設定反向代理,透過反向代理實現網站的負載平衡。這部分先寫一個nginx的配置,後續需要深入研究nginx的代理模組和負載平衡模組。
nginx透過proxy_pass_http 設定代理站點,upstream實現負載平衡。
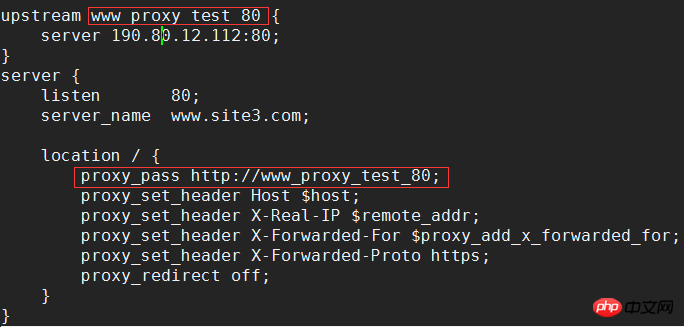
參考資料:
代理」顧名思義,就是不透過自己,透過第三方去代替自己執行自己要做的事情。可以想像成在本機和目標伺服器中又多了一個中間伺服器(代理伺服器)
正向代理程式是位於客戶端和原始伺服器之間的伺服器(代理伺服器)。 IP和連接埠),將每個請求先傳送到代理伺服器上,代理伺服器轉送到真實伺服器並取得回應結果後,傳回給客戶端。 #簡單說明,就是代理伺服器取代客戶端去存取目標伺服器。 ##繞過無法訪問的結點,從另一條路由路徑進行目標伺服器的訪問(例如翻牆)#加速訪問,透過不同的路由路徑提高訪問速度(現在透過頻寬的提高等方式,基本上不用此方式提速)
快取作用,資料快取在代理伺服器中,若客戶端請求的資料在快取中則不去存取目標主機。 ##隱藏訪問者,透過配置,目標伺服器只能獲得到代理伺服器的信息,無法獲取真實訪客的信息。 #反向代理正好相反,對於客戶端而言它就像是原始伺服器,並且
客戶端不需要進行任何特別的設定。請求,接著反向代理將判斷向原始伺服器轉交請求,並將獲得的內容傳回給客戶端,就像這些內容原本就是它自己的一樣。去接受並傳回客戶端的請求。惡意攻擊等,讓客戶端認為代理伺服器是原始伺服器。透明代理程式的意思是客戶端根本不需要知道有代理伺服器的存在,它改編你的request fields(訊息),並會傳送真實IP。的透明代理則是屬於匿名代理,意思是不用設定使用代理了。如下圖3.1
CDN的全名是Content Delivery Network,即內容分發網路。其基本想法是盡可能避開網路上有可能影響資料傳輸速度和穩定性的瓶頸和環節,使內容傳輸的更快、更穩定。透過在網絡各處放置節點伺服器所構成的在現有的互聯網基礎之上的一層智能虛擬網絡,CDN系統能夠實時地根據網絡流量和各節點的連接、負載狀況以及到用戶的距離和響應時間等綜合資訊將使用者的請求重新導向離用戶最近的服務節點上。其目的是使用戶可就近取得所需內容,解決 Internet網路擁擠的狀況,並提高使用者造訪網站的回應速度。
##典型用途是為在防火牆內的區域網路用戶端提供存取Internet的途徑。
反向代理
#典型用途是將防火牆後面的伺服器提供給Internet用戶存取。
為後端的多台伺服器提供負載平衡,或為後端較慢的伺服器提供緩衝服務。mysql 用主從同步的方法進行讀寫分離,減輕主伺服器的壓力的做法現在在業內做的非常普遍。主從同步基本上能做到即時同步。我從別的網站借用了主從同步的原理圖。
<br/>
<br/>
#在設定好了, 主從同步以後, 主伺服器會把更新語句寫入binlog, 從伺服器的IO 線程(這裡要注意, 5.6.3 之前的IO線程僅有一個,5.6.3之後的有多線程去讀了,速度自然也就加快了)回去讀取主伺服器的binlog 並且寫到從伺服器的Relay log 裡面,然後從伺服器的的SQL thread 會一個一個執行relay log 裡面的sql , 進行資料復原。
<br/>
relay 是傳遞, relay race 是接力賽的意思
<br/>
1. 主從同步的延遲的原因
我們知道, 一個伺服器開放N個連結給客戶端來連接的, 這樣有會有大並發的更新操作, 但是從伺服器的內部讀取binlog 的線程僅有一個, 當某個SQL在從伺服器上執行的時間稍長 或由於某個SQL要進行鎖定表就會導致,主伺服器的SQL大量積壓,未被同步到從伺服器裡。這就導致了主從不一致, 也就是主從延遲。
<br/>
2. 主從同步延遲的解決方法
其實主從同步延遲根本沒有什麼一招制敵的辦法, 因為所有的SQL必須都要在從伺服器裡面執行一遍,但是主伺服器如果不斷的有更新操作源源不斷的寫入, 那麼一旦有延遲產生, 那麼延遲加重的可能性就會原來越大。當然我們可以做一些緩解的措施。
a. 我們知道因為主伺服器要負責更新操作, 他對安全性的要求比從伺服器高, 所有有些設定可以修改,例如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之類別的設置,而slave則不需要這麼高的資料安全,完全可以講sync_binlog設定為0或關閉binlog,innodb_flushlog,#innodb_flush_log_at_trx_commit # 也可以設定為0來提高sql的執行效率這個能很大程度提高效率。另外就是使用比主庫更好的硬體設備作為slave。
b. 就是把,一台從伺服器當度當作備份使用, 而不提供查詢, 那邊他的負載下來了, 執行relay log 裡面的SQL效率自然就高了。
c. 增加從伺服器嘍,這個目的還是分散讀取的壓力, 從而降低伺服器負載。
<br/>
3. 判斷主從延遲的方法
MySQL提供了從伺服器狀態指令,可以透過show slave status 來查看, 例如可以看看Seconds_Behind_Master參數的值來判斷,是否有發生主從延遲。 <br/>其值有這麼多種:<br/>NULL - 表示io_thread或是sql_thread有任何一個發生故障,也就是該執行緒的Running狀態是No,而非是.<br/>0 - 該值為零,是我們極為渴望看到的情況,表示主從複製狀態正常
<br/>
 <br/>
<br/>
<br/>
> 1. Redis 支援更豐富的資料儲存類型,String、Hash、List、Set 和Sorted Set 。 Memcached 僅支援簡單的 key-value 結構。 <br/>> 2. Memcached key-value儲存比 Redis 採用 hash 結構來做 key-value 儲存的記憶體利用率更高。 <br/>> 3. Redis 提供了事務的功能,可以保證一系列命令的原子性<br/>> 4. Redis 支援資料的持久化,可以將記憶體中的資料保持在磁碟中<br/>> ; 5. Redis 只使用單核心,而Memcached 可以使用多核心,所以平均每一個核上Redis 在儲存小資料時比Memcached 效能更高。 <br/><br/>- Redis 如何持久化? <br/><br/>> 1. RDB 持久化,將 Redis 在記憶體中的狀態儲存到硬碟中,相當於備份資料庫狀態。 <br/>> 2. AOF 持久化(Append-Only-File),AOF 持久化是透過保存 Redis 伺服器鎖定執行的寫入狀態來記錄資料庫的。相當於備份資料庫接收到的指令,所有寫入 AOF 的指令都是以 Redis 的協定格式來保存的。 <br/>
<br/>
<br/>
Apache HTTP##伺服器是個模組化的伺服器,幾乎可運作所有廣泛使用的 計算機平台上。其屬於應用程式伺服器。 Apache支援支援模組多,效能穩定,Apache本身是靜態解析,適合靜態HTML、圖片等,但可以透過擴充腳本、模組等支援動態頁面等。
(Apche可以支援PHPcgiperl,但要使用 #Java的話,你需要Tomcat在Apache後台支撐,將##Java 請求由Apache轉發給Tomcat處理。 #缺點:配置相對複雜,本身不支援動態頁面。 2. Tomcat:
#Tomcat
#是應用程式(Java#)伺服器,它只是一個Servlet(JSP也翻譯成Servlet)容器,可以認為是Apache #的擴展,但是可以獨立於Apache運行。 3. Nginx#Nginx
是俄羅斯人所寫的十分輕量級的#HTTP伺服器,Nginx,它的發音為「engine X」,是一個高效能的HTTP 和反向代理伺服器,同時也是IMAP/POP3/SMTP 代理伺服器。 二、 比較
1. Apache與Tomcat的比較
相同要點:#l兩者都是
Apache組織開發的 l 兩者都有
HTTP服務的功能l #兩者都是免費的
不同點:
l Apache是專門用了提供HTTP#服務的,以及相關配置的(例如虛擬主機、URL轉發等等),而#Tomcat##是Apache組織在符合Java EE#的##JSP、Servlet 標準下開發的一個JSP伺服器#.
lApache是一個Web伺服器環境程式#,#啟用他可以作為Web 伺服器使用,不過只支援靜態網頁如(ASP,PHP,CGI,JSP)等動態網頁的就不行。如果要在Apache環境下執行JSP#的話就需要一個解釋器來執行JSP 網頁,而這個JSP#解釋器就是Tomcat#。
lApache:著重於HTTPServer ,#Tomcat :著重於Servlet引擎,如果以Standalone方式運行,功能上與Apache等效,支援##JSP,但對靜態網頁不太理想;l
Apache是Web伺服器,Tomcat是應用程式(Java)伺服器,它只是一個Servlet(JSP也被翻譯成Servlet)容器,可以認為是Apache的擴展,但可以獨立於Apache運行。
實際使用中Apache與Tomcat常常是整合使用: l
如果用戶端要求的是靜態頁面,則只需要Apache伺服器回應請求。 l
如果用戶端要求動態頁面,則是Tomcat伺服器回應請求。 l
因為JSP是伺服器端解釋程式碼的,這樣整合就可以減少Tomcat的服務開銷。
可以理解Tomcat為#Apache的一種擴充。
##nginx##nginx
## apache的優點l #輕量級,同樣起##web 服務,比apache佔用較少的記憶體及資源
l 抗併發,nginx
處理請求是非同步非阻塞的,而apache 則是阻塞型的
,在高並發下nginx 能維持低資源低消耗高效能
#l 提供負載平衡
#l
社群活躍,各種高效能模組出品快速2) apache #相對於nginx 的優點
的 # rewrite 比nginx 的強大 ;
l 支援動態頁面;l 支援的模組多,基本上涵蓋所有應用程式;l 效能穩定,而nginx相對
bug較多。 3) 兩者優缺點比較l Nginx
#設定簡單, Apache 複雜 ;##l
################################################################# Nginx ######靜態處理效能比##### Apache ############# 3######超過倍率###### #### ##;############l ######Apache ######對###### PHP ######支援比較簡單,### ###Nginx ######需要配合其他後端使用;############l ######Apache ######的元件比#### ## Nginx ######多###### ######;############l #########apache#### ##是同步多進程模型,一個連接對應一個進程;######nginx######是異步的,多個連接(萬級)可以對應一個進程;####### ##
l nginx#處理靜態檔案好#,#耗費記憶體少;
##l 動態請求由apache去做,nginx只適合靜態和反向;
l Nginx適合做前端伺服器,負載效能很好;
l Nginx本身就是反向代理伺服器 #,且支援負載平衡
3. 總結l Nginx#優點:負載平衡、反向代理、處理靜態檔案優勢。 nginx處理靜態請求的速度高於apache;
l Apache優點:相對於Tomcat伺服器來說處理靜態檔案是它的優勢,速度快。 Apache是靜態解析,適合靜態HTML、圖片等。
l Tomcat:動態解析容器,處理動態要求,是編譯JSP\Servlet#的容器,Nginx有動態分離機制,靜態請求直接就可以透過Nginx處理,動態請求才轉送請求到後台交由Tomcat處理。
#Apache在處理動態有優勢,Nginx並發性比較好,CPU記憶體佔用低,如果rewrite頻繁,那還是Apache比較適合。
<br/>
<br/>
lsof -i:連接埠號碼查看某個連接埠是否已被佔用<br/><br/>##2.使用netstat  使用netstat -anp|grep 80 <br/><br/><br/>
使用netstat -anp|grep 80 <br/><br/><br/> 更多內容,可以點這裡:http://www.findme.wang/blog/detail/id/1.html
更多內容,可以點這裡:http://www.findme.wang/blog/detail/id/1.html
查看CPU
<br/>top指令是Linux下常用的效能分析工具,能夠即時顯示系統中各個行程的資源佔用狀況,類似Windows的任務管理器
可以直接使用top指令後,查看%MEM的內容。可以選擇按進程查看或按用戶查看,如想查看oracle用戶的進程內存使用情況的話可以使用如下的命令:
$ top -u oracle<br/>Linux 查看進程和刪除進程
#
1. 在 LINUX 命令平台输入 1-2 个字符后按 Tab 键会自动补全后面的部分(前提是要有这个东西,例如在装了 tomcat 的前提下, 输入 tomcat 的 to 按 tab)。<br/>2. ps 命令用于查看当前正在运行的进程。<br/>grep 是搜索<br/>例如: ps -ef | grep java<br/>表示查看所有进程里 CMD 是 java 的进程信息<br/>ps -aux | grep java<br/>-aux 显示所有状态<br/>ps<br/>3. kill 命令用于终止进程<br/>例如: kill -9 [PID]<br/>-9 表示强迫进程立即停止<br/>通常用 ps 查看进程 PID ,用 kill 命令终止进程<br/>网上关于这两块的内容<br/>
<br/>
<br/> <br/>
优化手段主要有缓存、集群、异步等。
网站性能优化第一定律:优先考虑使用缓存。
缓存是指将数据存储在相对较高访问速度的存储介质中。 (1)访问速度快,减少数据访问时间; (2)如果缓存的数据进过计算处理得到的,那么被缓存的数据无需重复计算即可直接使用。 缓存的本质是一个内存Hash表,以一对Key、Value的形式存储在内存Hash表中,读写时间复杂度为O(1)。
不合理使用缓存非但不能提高系统的性能,还会成为系统的累赘,甚至风险。
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读取缓存,数据就已经失效,徒增系统负担。一般来说,数据的读写比在2:1以上,缓存才有意义。
如果应用系统访问数据没有热点,不遵循二八定律,那么缓存就没有意义。
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段时间才能被买家看到。还有一种策略是数据更新立即更新缓存,不过这也会带来更多系统开销和事务一致性问题。
1
2
缓存会承担大部分数据库访问压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因为完全不能承受如此大压力而宕机,导致网站不可用。 这种情况被称作缓存雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复。 实践中,有的网站通过缓存热备份等手段提高缓存可用性:当某台缓存服务器宕机时,将缓存访问切换到热备服务器上。 但这种设计有违缓存的初衷,**缓存根本就不应该当做一个可靠的数据源来使用**。 通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。 当一台缓存服务器宕机时,只有部分缓存数据丢失,重新从数据库加载这部分数据不会产生很大的影响。
缓存中的热点数据利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间。 那么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫缓存预热。
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成压力,甚至崩溃。
**一个简单的对策是将不存在的数据也缓存起来(其value为null)** 。<br/>
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其架构方式有两种,一种是以JBoss Cache为代表的需要更新同步的分布式缓存,一种是以Memcached为代表的不互相通信的分布式缓存。 JBoss Cache在集群中所有服务器中保存相同的缓存数据,当某台服务器有缓存数据更新,就会通知其他机器更新或清除缓存数据。 它通常将应用程序和缓存部署在同一台服务器上,但受限于单一服务器的内存空间;当集群规模较大的时候,缓存更新需要同步到所有机器,代价惊人。因此这种方案多见于企业应用系统中。 Memcached采用一种集中式的缓存集群管理(互不通信的分布式架构方式)。缓存与应用分离部署,缓存系统部署在一组专门的服务器上,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问数据,缓存服务器之间不通信,集群规模可以很容易地实现扩容,具有良好的伸缩性。 (1)简单的通信协议。Memcached使用TCP协议(UDP也支持)通信; (2)丰富的客户端程序。 (3)高性能的网络通信。Memcached服务端通信模块基于Libevent,一个支持事件触发的网络通信程序库,具有稳定的长连接。 (4)高效的内存管理。 (5)互不通信的服务器集群架构。
<br/>
使用消息队列将调用异步化(生产者--消费者模式),可改善网站的扩展性,还可以改善系统的性能。 在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,会对数据库造成巨大压力,使得响应延迟加剧。 在使用消息队列后,用户请求的数据发送给消息队列后立即返回,再由消息队列的消费者进程(通常情况下,该进程独立部署在专门的服务器集群上)从消息队列中获取数据, 异步写入数据库。由于消息队列服务器处理速度远快于服务器(消息队列服务器也比数据库具有更好的伸缩性)。 消息队列具有很好的削峰作用--通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。 需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后, 需要适当修改业务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完后, 甚至商品出库后,再通过电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
<br/>
任何可以晚点做的事情都应该晚点再做。
在网站高并发访问的场景下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器上处理。
从资源利用的角度看,使用多线程的原因主要有两个:IO阻塞与多CPU。 当前线程进行IO处理的时候,会被阻塞释放CPU以等待IO操作完成,由于IO操作(不管是磁盘IO还是网络IO)通常都需要较长的时间,这时CPU可以调度其他的线程进行处理。 理想的系统Load是既没有进程(线程)等待也没有CPU空闲,利用多线程IO阻塞与执行交替进行,可最大限度利用CPU资源。 使用多线程的另一个原因是服务器有多个CPU。 简化启动线程估算公式: 启动线程数 = [任务执行时间 / (任务执行时间 - IO等待时间)]*CPU内核数 多线程编程一个需要注意的问题是线程安全问题,即多线程并发对某个资源进行修改,导致数据混乱。 所有的资源---对象、内存、文件、数据库,乃至另一个线程都可能被多线程并发访问。 编程上,解决线程安全的主要手段有: (1)将对象设计为无状态对象。 所谓无状态对象是指对象本身不存储状态信息(对象无成员变量,或者成员变量也是无状态对象),不过从面向对象设计的角度看,无状态对象是一种不良设计。 (2)使用局部对象。 即在方法内部创建对象,这些对象会被每个进入该方法的线程创建,除非程序有意识地将这些对象传递给其他线程,否则不会出现对象被多线程并发访问的情形。 (3)并发访问资源时使用锁。 即多线程访问资源的时候,通过锁的方式使多线程并发操作转化为顺序操作,从而避免资源被并发修改。
1系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。 2从编程角度,资源复用主要有两种模式:单例(Singleton)和对象池(Object Pool)。 3单例虽然是GoF经典设计模式中较多被诟病的一个模式,但由于目前Web开发中主要使用贫血模式,从Service到Dao都是些无状态对象,无需重复创建,使用单例模式也就自然而然了。 4对象池模式通过复用对象实例,减少对象创建和资源消耗。 5对于数据库连接对象,每次创建连接,数据库服务端都需要创建专门的资源以应对,因此频繁创建关闭数据库连接,对数据库服务器是灾难性的, 同时频繁创建关闭连接也需要花费较长的时间。 6因此实践中,应用程序的数据库连接基本都使用连接池(Connection Pool)的方式,数据库连接对象创建好以后, 将连接对象放入对象池容器中,应用程序要连接的时候,就从对象池中获取一个空闲的连接使用,使用完毕再将该对象归还到对象池中即可,不需要创建新的连接。
早期关于程序的一个定义是,程序就是数据结构+算法,数据结构对于编程的重要性不言而喻。 在不同场景中合理使用数据结构,灵活组合各种数据结构改善数据读写和计算特性可极大优化程序的性能。
理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
摘自《大型网站技术架构》–李智慧
<br/>
手机网站支付主要应用于手机、掌上电脑等无线设备的网页上,通过网页跳转或浏览器自带的支付宝快捷支付实现买家付款的功能,资金即时到账。
1、您申请前必须拥有企业支付宝账号(不含个体工商户账号),且通过支付宝实名认证审核。<br/>2、如果您有已经建设完成的无线网站(非淘宝、天猫、诚信通网店),网站经营的商品或服务内容明确、完整(古玩、珠宝等奢侈品、投资类行业无法申请本产品)。<br/>3、网站必须已通过ICP备案,备案信息与签约商户信息一致。
假设我们已经成功申请到手机网站支付接口,在进行开发之前,需要使用公司账号登录支付宝开放平台。
1、开发者登录开放平台,点击右上角的“账户及密钥管理”。<br/>
2、选择“合作伙伴密钥”,即可查询到合作伙伴身份(PID),以2088开头的16位纯数字。<br/>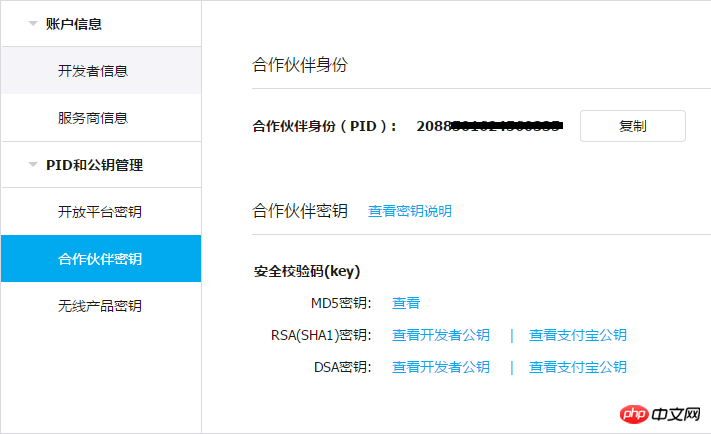
支付宝提供了DSA、RSA、MD5三种签名方式,本次开发中,我们使用RSA签名和加密,那就只配置RSA密钥就好了。
关于RSA加密的详解,参见《支付宝签名与验签》。
本节可以忽略,本节可以忽略,本节可以忽略!因为官方文档并没有提及应用环境配置的问题。
进入管理中心,对应用进行设置。<br/>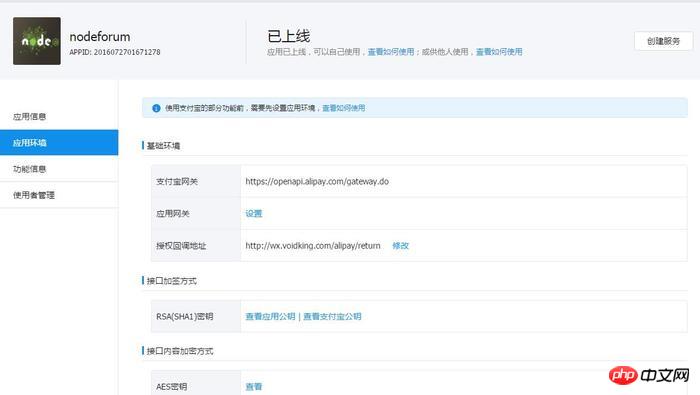 <br/>
<br/>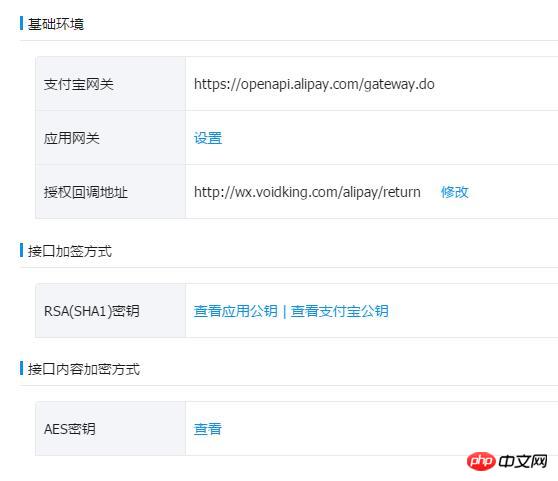 <br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。
<br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。
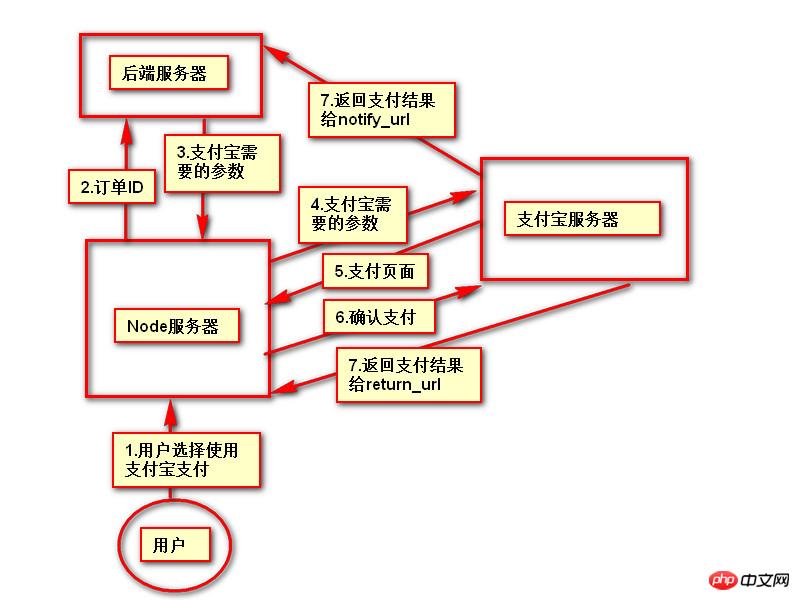 <br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。
<br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。
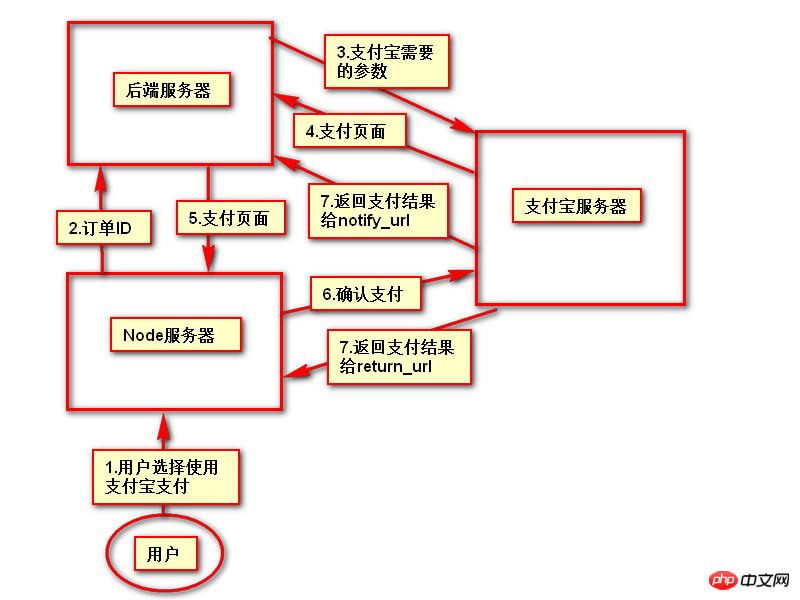 <br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。
<br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。
return_url,支付完成后的回调url;notify_url,支付完成后通知的url。支付宝发送给两个url的参数是一样的,只不过一个是get,一个是post。
以上两种发起请求的方式中,return_url在Node端,notify_url在后端。我们也可以根据需要,把两个url都放在后端,或者都放在Node端,改变相应业务逻辑即可。
Node端发起支付请求有两种选择,一种是获取到后端给的参数后,通过request模块发起get请求,获取到支付宝返回的支付页面,然后显示到页面上;另一种是获取到后端给的参数后,把参数全部输出到页面中的form表单,然后通过js自动提交表单,获取到支付宝返回的支付页面(同时显示出来)。
// 通过orderId向后端请求获取支付宝支付参数alidata var alipayUrl = 'https://mapi.alipay.com/gateway.do?'+ alidata; request.get({url: alipayUrl},function(error, response, body){ res.send(response.body); });理论上完全正确的请求,然而,获取到的支付页面,输出到页面上,却是乱码。没错,还是一个错误提示页面。<br/>
神奇的地方在于,在刷新页面多次后,正常了!!!啊嘞,这是什么鬼?
先解决乱码问题,看看报什么错!
request.get({url: alipayUrl},function(error, response, body){
var str = response2.body;
str = str.replace(/gb2312/, "utf-8");
res.setHeader('content-type', 'text/html;charset=utf-8');
res.send(str);
});很遗憾,无效!乱码依然是乱码。。。和沈晨帅哥讨论很久,最终决定换一种方案——利用表单提交。
// node端 // 通过orderId向后端请求获取支付宝支付参数alidata function getArg(str,arg) { var reg = new RegExp('(^|&)' + arg + '=([^&]*)(&|$)', 'i'); var r = str.match(reg); if (r != null) { return unescape(r[2]); } return null; } var alipayParam = { _input_charset: getArg(alidata,'_input_charset'), body: getArg(alidata,'body'), it_b_pay: getArg(alidata, 'it_b_pay'), notify_url: getArg(alidata, 'notify_url'), out_trade_no: getArg(alidata, 'out_trade_no'), partner: getArg(alidata, 'partner'), payment_type: getArg(alidata, 'payment_type'), return_url: getArg(alidata, 'return_url'), seller_id: getArg(alidata, 'seller_id'), service: getArg(alidata, 'service'), show_url: getArg(alidata, 'show_url'), subject: getArg(alidata, 'subject'), total_fee: getArg(alidata, 'total_fee'), sign_type: getArg(alidata, 'sign_type'), sign: getArg(alidata, 'sign'), app_pay: getArg(alidata, 'app_pay') }; res.render('artist/alipay',{ // 其他参数 alipayParam: alipayParam });<!--alipay.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>支付宝支付</title> </head> <body> <form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get"> <input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>"> <input type="hidden" name="body" value="<%= alipayParam.body%>"> <input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>"> <input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>"> <input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>"> <input type="hidden" name="partner" value="<%= alipayParam.partner%>"> <input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>"> <input type="hidden" name="return_url" value="<%= alipayParam.return_url%>"> <input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>"> <input type="hidden" name="service" value="<%= alipayParam.service%>"> <input type="hidden" name="show_url" value="<%= alipayParam.show_url%>"> <input type="hidden" name="subject" value="<%= alipayParam.subject%>"> <input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>"> <input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>"> <input type="hidden" name="sign" value="<%= alipayParam.sign%>"> <input type="hidden" name="app_pay" value="<%= alipayParam.app_pay%>"> </form> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/alipay.js?v=2016052401"></script> </body> </html>
// alipay.js seajs.use(['zepto'],function($){
var index = {
init:function(){
var self = this;
this.bindEvent();
},
bindEvent:function(){
var self = this;
$('#ali-form').submit();
}
}
index.init();
}); <br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。
<br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。
开始时,打算把alidata直接输出到form表单的action中接口的后面,因为这样似乎最简便。但是,提交表单时,后面的参数全部被丢弃了。所以,不得不得把所有参数放在form表单中。Node端拆分了一下参数,组装成了一个alipayParam对象,这个工作也可以交给后端来做。
显然,request模拟表单提交和真实表单提交结果的不同,得出的结论是,request并不能完全模拟表单提交。或者,request可以模拟,而我不会-_-|||。
 <br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。
<br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。
以上,大功告成?不!还有一个坑要填,因为微信屏蔽了支付宝!<br/>在电脑上,跳转支付宝支付页面正常,很完美!然而,在微信浏览器中测试时,却没有跳转,而是出现如下信息。<br/>
微信端支付宝支付,iframe改造<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html
该办法的核心在于:把微信屏蔽的链接,赋值给iframe的src属性。
res.render('artist/alipay',{ alipayParam: alipayParam, param: urlencode(alidata) });<input type="hidden" id="param" value="<%= param%>"> <iframe id="payFrame" name="mainIframe" src="" frameborder="0" scrolling="auto" ></iframe>
var iframe = document.getElementById('payFrame'); var param = $('#param').val(); iframe.src='https://mapi.alipay.com/gateway.do?'+param;
然而,在改造时,先是报错ILLEGAL_SIGN,于是利用urlencode处理了字符串。接着,又报错ILLEGAL_EXTERFACE,没有找到解决办法。
暂时放弃,以后如果有了解决办法再补上。
关于微信公众平台无法使用支付宝收付款的解决方案说明<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702
该方法的核心在于:确认支付时,提示用户打开外部系统浏览器,在系统浏览器中支付。
<!--alipay.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>支付宝支付</title> </head> <body> <form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get"> <input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>"> <input type="hidden" name="body" value="<%= alipayParam.body%>"> <input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>"> <input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>"> <input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>"> <input type="hidden" name="partner" value="<%= alipayParam.partner%>"> <input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>"> <input type="hidden" name="return_url" value="<%= alipayParam.return_url%>"> <input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>"> <input type="hidden" name="service" value="<%= alipayParam.service%>"> <input type="hidden" name="show_url" value="<%= alipayParam.show_url%>"> <input type="hidden" name="subject" value="<%= alipayParam.subject%>"> <input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>"> <input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>"> <input type="hidden" name="sign" value="<%= alipayParam.sign%>"> <p class="wrapper buy-wrapper" style="max-width:90%"> <a href="javascript:void(0);" class="J-btn-submit btn mj-submit btn-strong btn-larger btn-block">确认支付</a> </p> </form> <input type="hidden" id="param" value="<%= param%>"> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/ap.js"></script> <script> var btn = document.querySelector(".J-btn-submit"); btn.addEventListener("click", function (e) { e.preventDefault(); e.stopPropagation(); e.stopImmediatePropagation(); var queryParam = ''; Array.prototype.slice.call(document.querySelectorAll("input[type=hidden]")).forEach(function (ele) { queryParam += ele.name + "=" + encodeURIComponent(ele.value) + '&'; }); var gotoUrl = document.querySelector("#ali-form").getAttribute('action') + '?' + queryParam; _AP.pay(gotoUrl); return false; }, false); btn.click(); </script> </body> </html>该页面会自动跳转到同一文件夹下的pay.htm,该文件官方已经提供,把其中的引入ap.js的路径修改一下即可。最终效果如下:<br/>
支付宝的支付流程和微信的支付流程,有很多相似之处。沈晨指出一点不同:支付宝支付完成后有return_url和notify_url;微信支付完成后只有notify_url。
研读了一下微信支付的开发文档,确实如此。微信支付完成后的通知也分成两路,一路通知到notify_url,另一路返回给调用支付接口的JS,同时发微信消息提示。也就是说,跳转return_url的工作我们需要自己做。
最后,感谢沈晨帅哥提供的思路和帮助,感谢体超帅哥辛苦改后端。
支付寶開放平台<br/>https://openhome.alipay.com/platform/home.htm
#支付寶開放平台-手機網站支付-文件中心<br/> https://doc.open.alipay.com/doc2/detail?treeId=60&articleId=103564&docType=1
支付寶WAP支付介面開發<br/>http://blog.csdn.net/tspangle/article /details/39932963
wap h5手機網站支付介面喚起支付寶錢包付款
商家服務- 支付寶知託付! <br/>https://b.alipay.com/order/techService.htm
微信支付-開發文件<br/>https://pay.weixin.qq.com/wiki/doc/api/ jsapi.php?chapter=7_1
微信端支付寶支付,iframe改造<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html
#微信如何突破支付寶的封鎖<br/>http://blog.csdn.net/lee_sire/article/details/49530875
JavaScript專題(二):深入理解iframe<br/>http://www.cnblogs.com/ fangjins/archive/2012/08/19/2645631.html
關於微信公眾平台無法使用支付寶收付款的解決方案說明<br/>https://cshall.alipay.com/enterprise/help_detail.htm ?help_id=524702
<br/>
對於當今大流量的網站,每天幾千萬甚至上億的流量,是如何解決訪問量問題的呢?
以下是一些總結的方法: 第一,確認伺服器硬體是否足夠支援目前的流量。 普通的P4伺服器一般最多能支援每天10萬獨立IP,如果存取量比這個還要大,那麼必須先配置一台更高效能的專用伺服器才能解決問題,否則怎麼優化都不可能徹底解決效能問題。
第二,最佳化資料庫存取。 伺服器的負載過大,一個重要的原因是CPU負載過大,降低伺服器CPU的負載,才能有效打破瓶頸。而使用靜態頁面可以使得CPU的負荷最小化。前台實現完全的靜態化 當然最好,可以完全不用存取資料庫,不過對於頻繁更新的網站,靜態化往往無法滿足某些功能。 快取技術 是另一個解決方案,就是將動態資料儲存到快取檔案中,動態網頁直接呼叫這些文件,而不必再存取資料庫,WordPress和Z-Blog都大量使用這種快取技術 。我自己也寫過一個Z-Blog的計數器插件,也是基於這樣的原理。 如果確實無法避免對資料庫的訪問,那麼可以嘗試最佳化資料庫的查詢SQL.避免使用Select *from這樣的語句,每次查詢只傳回自己需要的結果,避免短時間內的大量SQL查詢。
第三,禁止外在的盜鏈。外部網站的圖片或文件盜鏈往往會帶來大量的負載壓力,因此應該嚴格限制外部對於自身的圖片或者文件盜鏈,好在目前可以簡單地通過refer來控制盜鏈,Apache自己就可以通過配置來禁止盜鏈,IIS也有一些第三方的ISAPI可以實現同樣的功能。當然,偽造refer也可以透過程式碼來實現盜用 鏈,不過目前蓄意偽造refer盜鏈的還不多,可以先不去考慮,或是使用非技術手段來解決,例如在圖片上增加水印。
第四,控制大檔案的下載。 大檔案的下載會佔用很大的流量,對於非SCSI硬碟來說,大量檔案下載會消耗CPU,使得網站回應能力下降。因此,盡量不要提供超過2M的大 檔案下載,如果需要提供,建議將大型檔案放在另一台伺服器上。目前有不少免費的Web2.0網站提供圖片分享和文件分享功能,因此可以盡量將圖片和文件上 傳到這些分享網站。
第五,使用不同主機分流主要流量 將檔案放在不同的主機上,並提供不同的鏡像供使用者下載。例如如果覺得RSS檔案佔用流量大,那麼使用FeedBurner或FeedSky等服務將RSS輸出放在其他主機上,這樣別人存取的流量壓力就大多集中在FeedBurner的主機上,RSS就不佔用太多資源了。
第六,使用流量分析統計軟體。 在網站上安裝一個流量分析統計軟體,可以即時知道哪些地方耗費了大量流量,哪些頁面需要再進行優化,因此,解決流量問題還需要進行精確的統計分析 才可以。我推薦使用的流量分析統計軟體是GoogleAnalytics(Google分析)。我使用過程中感覺其效果非常不錯,稍後我將詳細介紹 GoogleAnalytics的一些使用常識和技巧。 1.分錶 2.讀寫分離 3.前端最佳化。 Nginx替換Apache(前端做負載平衡) 個人認為主要還是分散式架構是否到位,mysql和快取的最佳化都是有限的最佳化,而分散式架構做出來了,PV成長後,只需要堆機器就能擴容。
另附一些優化經驗,首先學會用explain語句分析select語句,優化索引、表結構,其次,合理運用memcache等緩存,降低mysql的負載,最後,如果可能的話,盡量用facebook的hiphop-php把PHP編譯了,提高程式效率。
<br/>
NoSQL與關係型資料庫設計概念比較 <br/>
在關係型資料庫中的表都是儲存一些格式化的資料結構,每個元組字段的組成都一樣,即使不是每個元組都需要所有的字段,但資料庫會為每個元組分配所有的字段,這樣的結構可以便於表與表之間進行連接等操作,但從另一個角度來說它也是關係型資料庫效能瓶頸的一個因素。而非關係型資料庫以鍵值對存儲,它的結構不固定,每一個元組可以有不一樣的字段,每個元組可以根據需要增加一些自己的鍵值對,這樣就不會局限於固定的結構,可以減少一些時間和空間的開銷。 <br/><br/>特點:<br/>它們可以處理超大量的資料。 <br/>它們運行在便宜的PC伺服器叢集上。 <br/>它們擊碎了效能瓶頸。 <br/>沒有過多的操作。 <br/>Bootstrap支援 <br/><br/>缺點:<br/>但是有些人承認,沒有正式的官方支持,萬一出了差錯會是可怕的,至少很多管理人員是這樣看。 <br/>此外,nosql並未形成一定標準,各種產品層出不窮,內部混亂,各種項目還需要時間來檢驗
MySQL或NoSQL:開源盛世下的資料庫該如何選擇
##摘要:MySQL ,關係型資料庫,有數量龐大的支持者。 NoSQL,非關係型資料庫,被視為資料庫革命者。兩者似乎注定要有一場廝殺,可同屬開源大家庭的它們卻又能攜手並進、和睦相處,齊心協力為開發者提供更好的服務。
如何選擇:永遠正確的經典答案仍然是:具體問題具體分析。 <br/>
MySQL體積小、速度快、成本低、結構穩定、方便查詢,可以保證資料的一致性,但缺乏彈性。 NoSQL高效能、高擴充、高可用,不用侷限於固定的結構,減少了時間和空間上的開銷,但又很難保證資料一致性。兩者都有大量的使用者和支持者,尋求兩者的結合無疑是個很好的解決方案。作者John Engates是Rackspace主機託管部門CTO,也是個開放雲端支持者,他為我們帶來了詳細的分析。 http://www.csdn.net/article/2014-03-05/2818637-open-source-data-grows-choosing-mysql-nosql
# #選擇其中一個?還是兩者都要?
應用程式是否應該與關聯式資料庫或NoSQL(也許是兩者)一致,當然,這得基於被產生或被檢索資料的性質。和大多數科技領域的事物一樣,做決定時要折衷。
如果規模和效能比24小時的資料一致性更重要,那麼NoSQL是一個理想的選擇(NoSQL依賴BASE模型-基本上可用、軟狀態、最終一致性)。
但如果要保證到“始終一致”,尤其是對於機密資訊和財務信息,那麼MySQL很可能是最優的選擇(MySQL依賴於ACID模型-原子性、一致性、獨立性和耐久性)。
作為開源資料庫,無論是關係型資料庫或非關係型資料庫都在不斷成熟,我們可以預期還會有一大批基於ACID和BASE模型的新應用產生。 #
雖然09年出現了比較激進的文章《關聯式資料庫已死》,但我們心裡都清楚,關係資料庫其實還活得好好的,你還不能不用關係資料庫。但也說明了一個事實,關聯式資料庫在處理WEB2.0資料的時候,的確已經出現了瓶頸。
那我們到底是用NoSQL還是關聯式資料庫呢?我想我們沒有必要來進行一個絕對的回答。我們需要根據我們的應用場景來決定我們到底用什麼。
如果關係資料庫在你的應用程式場景中,完全能夠很好的工作,而你又是非常善於使用和維護關聯式資料庫的,那麼我覺得你完全沒有必要遷移到NoSQL上面,除非你是個喜歡折騰的人。如果你在金融,電信等以數據為王的關鍵領域,目前使用的是Oracle資料庫來提供高可靠性的,除非遇到特別大的瓶頸,不然也別貿然嘗試NoSQL。
然而,在WEB2.0的網站中,關聯式資料庫大部分都出現了瓶頸。在磁碟IO、資料庫可擴充上都花費了開發人員相當多的精力來優化,例如做分錶分庫(database sharding)、主從複製、異質複製等等,然而,這些工作需要的技術能力越來越高,也越來越具挑戰性。如果你正在經歷這些場合,那麼我覺得你應該嘗試NoSQL了。
<br/>
相對於結構化數據(即行數據,儲存在資料庫裡,可以用二維表結構來邏輯表達實現的數據)而言,不方便用資料庫二維邏輯表來表現的數據即稱為非結構化數據,包括所有格式的辦公室文件、文字、圖片、XML、HTML、各類報表、圖像和音訊/視訊資訊等等。
非結構化資料庫是指其欄位長度可變,而每個欄位的記錄又可以由可重複或不可重複的子欄位構成的資料庫,用它不僅可以處理結構化資料(如數字、符號等資訊)而且更適合處理非結構化資料(全文文字、圖像、聲音、影視、超媒體等資訊)。
非結構化WEB資料庫主要是針對非結構化資料而產生的,與以往流行的關係資料庫相比,其最大區別在於它突破了關係資料庫結構定義不易改變和資料定長的限制,支援重複欄位、子欄位以及變長欄位並實現了對變長資料和重複欄位進行處理和資料項目的變長儲存管理,在處理連續資訊(包括全文資訊)和非結構化資訊(包括各種多媒體資訊)中有著傳統關係型資料庫無法比擬的優勢。
結構化資料(即行資料,儲存在資料庫中,可以用二維表結構來邏輯表達實現的資料)
# 非結構化資料,包括所有格式的辦公室文件、文字、圖片、XML、HTML、各類報表、圖像和音訊/視訊資訊等等
所謂半結構化數據,就是介於完全結構化資料(如關係型資料庫、物件導向資料庫中的資料)和完全無結構的資料(如聲音、影像檔案等)之間的數據,HTML文件就屬於半結構化資料。它一般是自描述的,資料的結構和內容混在一起,沒有明顯的區分。
結構化資料:二維表(關係型)<br/> 半結構化資料:樹、圖<br/> 非結構化資料:無
RMDBS的資料模型有:如網狀資料模型、層次資料模型、關係型
其他:
結構化資料:先有結構、再有數據<br/> 半結構化資料:先有數據,再有結構
隨著網路技術的發展,特別是Internet和Intranet技術的快速發展,使得非結構化資料的數量日益增長。這時,主要用於管理結構化資料的關係資料庫的限制暴露地越來越明顯。因而,資料庫技術也相應地進入了“後關係資料庫時代”,發展進入基於網路應用的非結構化資料庫時代。
我國非結構化資料庫以北京國信貝斯(iBase)軟體有限公司的IBase資料庫為代表。 IBase資料庫是一種面向最終用戶的非結構化資料庫,在處理非結構化資訊、全文資訊、多媒體資訊和大量資訊等領域以及Internet/Intranet應用程式上處於國際先進水平,在非結構化資料的管理和全文檢索方面獲得突破。它主要有以下幾個優點:
(1)Internet應用中,存在大量的複雜資料類型,iBase透過其外部文件資料類型,可以管理各種文件資訊、多媒體資訊,並且對於各種具有檢索意義的文件資訊資源,如HTML、DOC、RTF、TXT等也提供了強大的全文檢索能力。
(2)它採用子字段、多值字段以及變長字段的機制,允許創建許多不同類型的非結構化的或任意格式的字段,從而突破了關係資料庫非常嚴格的表結構,使得非結構化資料得以儲存和管理。
(3)iBase將非結構化和結構化資料都定義為資源,使得非結構資料庫的基本元素就是資源本身,而資料庫中的資源可以同時包含結構化和非結構化的信息。所以,非結構化資料庫能夠儲存和管理各種各樣的非結構化數據,實現了資料庫系統資料管理到內容管理的轉換。
(4)iBase採用了物件導向的基石,將企業業務資料和商業邏輯緊密結合在一起,特別適合表達複雜的資料物件和多媒體物件。
(5)iBase是適應Internet發展的需要而產生的資料庫,它基於Web是一個廣域網路的海量資料庫的思想,提供一個網路資源管理系統iBase Web,將網路伺服器(WebServer)和資料庫伺服器(Database Server)直接集成為一個整體,使資料庫系統和資料庫技術成為Web的一個重要有機組成部分,突破了資料庫僅充當Web體系後台角色的局限,實現資料庫和Web的有機無縫組合,從而為在Internet/Intranet上進行資訊管理乃至開展電子商務應用開啟了更為廣闊的領域。
(6)iBase全面相容於各種大中小型的資料庫,對傳統關聯式資料庫,如Oracle、Sybase、SQLServer、DB2、Informix等提供匯入和連結的支援能力。
透過從上面的分析後我們可以預言,隨著網路技術和網路應用技術的快速發展,完全基於Internet應用的非結構化資料庫將成為繼層次資料庫、網狀資料庫和關聯式資料庫之後的另一個重點、熱點技術。
在做一個資訊系統設計時肯定會涉及到資料的存儲,一般我們都會將系統資訊保存在某個指定的關係資料庫中。我們會將資料依業務分類,並設計對應的表,然後將對應的資訊儲存到對應的表中。例如我們做一個業務系統,要保存員工基本資料:工號、姓名、性別、出生日期等等;我們就會建立一個對應的staff表。
但不是系統中所有資訊都可以這樣簡單的用一個表中的欄位就能對應的。
就像上面舉的例子。這種類別的資料最好處理,只要簡單的建立一個對應的表格就可以了。
像圖片、聲音、影片等等。這類資訊我們通常無法直接知道他的內容,資料庫也只能將它保存在一個BLOB欄位中,對以後檢索非常麻煩。一般的做法是,建立一個包含三個欄位的表格(編號 number、內容描述 varchar(1024)、內容 blob)。引用經編號,檢索透過內容描述。現在還有很多非結構化資料的處理工具,市面上常見的內容管理器就是其中的一種。
這樣的數據和上面兩個類別都不一樣,它是結構化的數據,但是結構變化很大。因為我們要了解資料的細節所以不能將資料簡單的組織成一個檔案依照非結構化資料處理,由於結構變化很大也不能夠簡單的建立一個表格和他對應。本文主要討論針對半結構化資料儲存常用的兩種方式。
先举一个半结构化的数据的例子,比如存储员工的简历。不像员工基本信息那样一致每个员工的简历大不相同。有的员工的简历很简单,比如只包括教育情况;有的员工的简历却很复杂,比如包括工作情况、婚姻情况、出入境情况、户口迁移情况、党籍情况、技术技能等等。还有可能有一些我们没有预料的信息。通常我们要完整的保存这些信息并不是很容易的,因为我们不会希望系统中的表的结构在系统的运行期间进行变更。
这种方法通常是对现有的简历中的信息进行粗略的统计整理,总结出简历中信息所有的类别同时考虑系统真正关心的信息。对每一类别建立一个子表,比如上例中我们可以建立教育情况子表、工作情况子表、党籍情况子表等等,并在主表中加入一个备注字段,将其它系统不关心的信息和已开始没有考虑到的信息保存在备注中。
优点:查询统计比较方便。
缺点:不能适应数据的扩展,不能对扩展的信息进行检索,对项目设计阶段没有考虑到的同时又是系统关心的信息的存储不能很好的处理。
XML可能是最适合存储半结构化的数据了。将不同类别的信息保存在XML的不同的节点中就可以了。
优点:能够灵活的进行扩展,信息进行扩展式只要更改对应的DTD或者XSD就可以了。
缺点:查询效率比较低,要借助XPATH来完成查询统计,随着数据库对XML的支持的提升性能问题有望能够很好的解决。
<br/>
单链表<br/><br/> 1、链接存储方法<br/> 链接方式存储的线性表简称为链表(Linked List)。<br/> 链表的具体存储表示为:<br/> ① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)<br/> ② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))<br/> 注意:<br/> 链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。<br/> <br/> 2、链表的结点结构<br/> ┌──┬──┐<br/> │data│next│<br/> └──┴──┘ <br/> data域--存放结点值的数据域<br/> next域--存放结点的直接后继的地址(位置)的指针域(链域)<br/>注意:<br/> ①链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的。<br/> ②每个结点只有一个链域的链表称为单链表(Single Linked List)。<br/> 【例】线性表(bat,cat,eat,fat,hat,jat,lat,mat)的单链表示如示意图<br/><br/>
单链表的反转是常见的面试题目。本文总结了2种方法。
单链表node的数据结构定义如下:
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
把当前链表的下一个节点pCur插入到头结点dummy的下一个节点中,就地反转。
dummy->1->2->3->4->5的就地反转过程:
dummy->2->1->3->4->5dummy->3->2->1->4->5dummy->4>-3->2->1->5dummy->5->4->3->2->1
pCur是需要反转的节点。
prev连接下一次需要反转的节点
反转节点pCur
纠正头结点dummy的指向
pCur指向下一次要反转的节点
伪代码
1 prev.next = pCur.next; 2 pCur.next = dummy.next; 3 dummy.next = pCur; 4 pCur = prev.next;
pCur is not null
1 // 1.就地反转法
2 public ListNode reverseList1(ListNode head) {
3 if (head == null)
4 return head;
5 ListNode dummy = new ListNode(-1);
6 dummy.next = head;
7 ListNode prev = dummy.next;
8 ListNode pCur = prev.next;
9 while (pCur != null) {
10 prev.next = pCur.next;
11 pCur.next = dummy.next;
12 dummy.next = pCur;
13 pCur = prev.next;
14 }
15 return dummy.next;
16 }
1个头结点,2个指针,4行代码
注意初始状态和结束状态,体会中间的图解过程。
新建一个头结点,遍历原链表,把每个节点用头结点插入到新建链表中。最后,新建的链表就是反转后的链表。
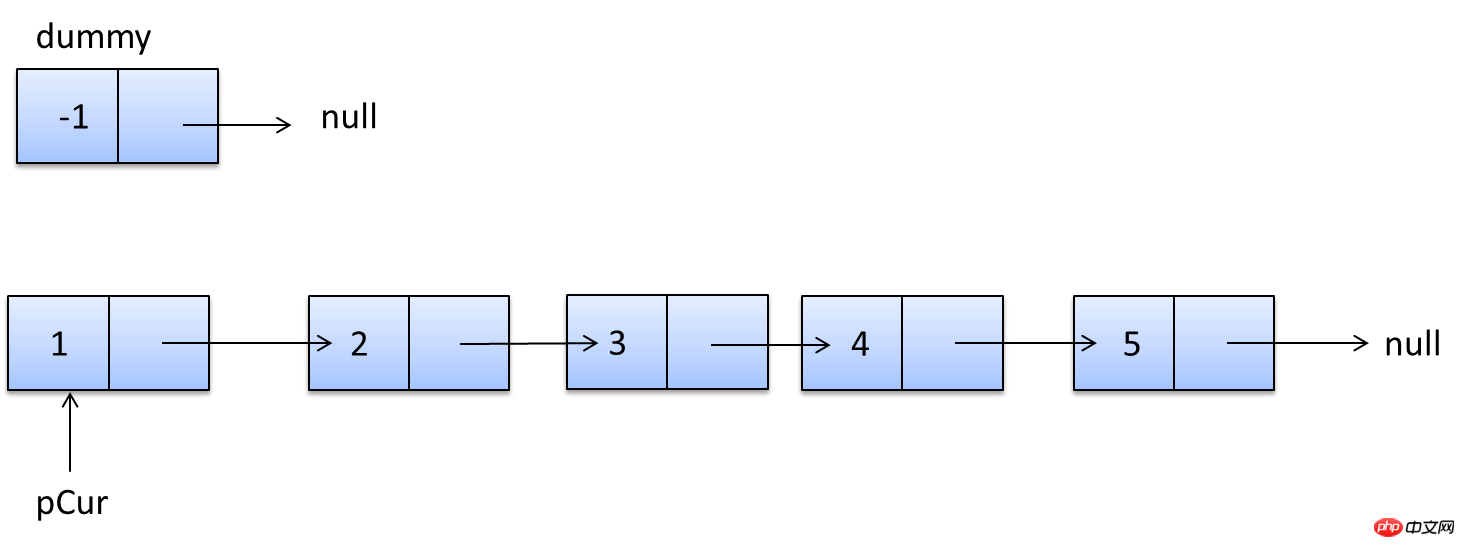
pCur是要插入到新链表的节点。
pNex是临时保存的pCur的next。
pNex保存下一次要插入的节点
把pCur插入到dummy中
纠正头结点dummy的指向
pCur指向下一次要插入的节点
伪代码
1 pNex = pCur.next 2 pCur.next = dummy.next 3 dummy.next = pCur 4 pCur = pNex
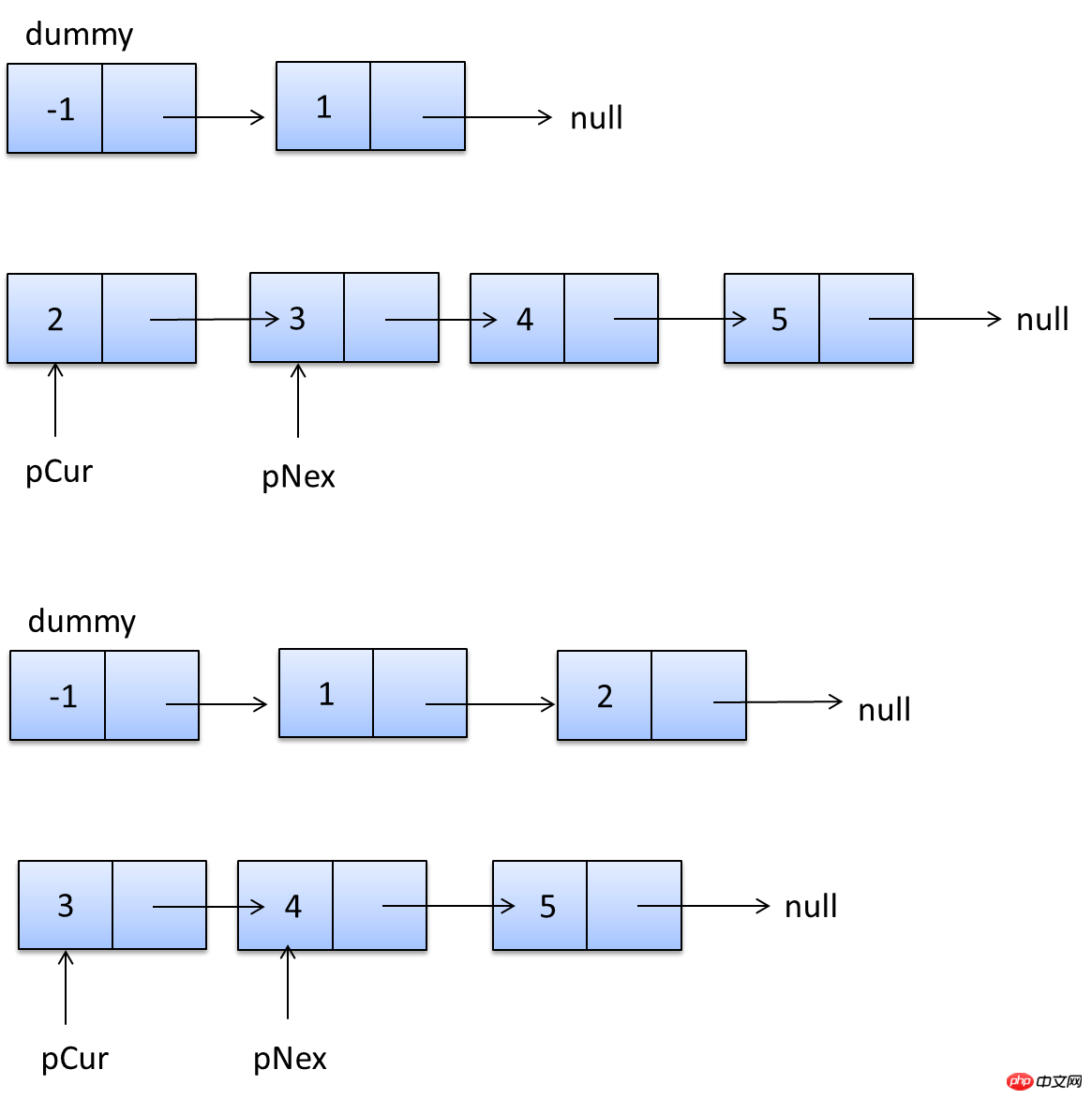
pCur is not null
1 // 2.新建链表,头节点插入法
2 public ListNode reverseList2(ListNode head) {
3 ListNode dummy = new ListNode(-1);
4 ListNode pCur = head;
5 while (pCur != null) {
6 ListNode pNex = pCur.next;
7 pCur.next = dummy.next;
8 dummy.next = pCur;
9 pCur = pNex;
10 }
11 return dummy.next;
12 }<br/>
<br/>
MySQL官方对索引的定义:索引是帮助MySQL高效获取数据的数据结构。索引是在存储引擎中实现的,所以每种存储引擎中的索引都不一样。如MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。
这里仅针对常用的InnoDB存储引擎所支持的BTree索引进行介绍:
先创建一个新表,用于演示索引类型
CREATE TABLE index_table ( id BIGINT NOT NULL auto_increment COMMENT '主键', NAME VARCHAR (10) COMMENT '姓名', age INT COMMENT '年龄', phoneNum CHAR (11) COMMENT '手机号', PRIMARY KEY (id) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
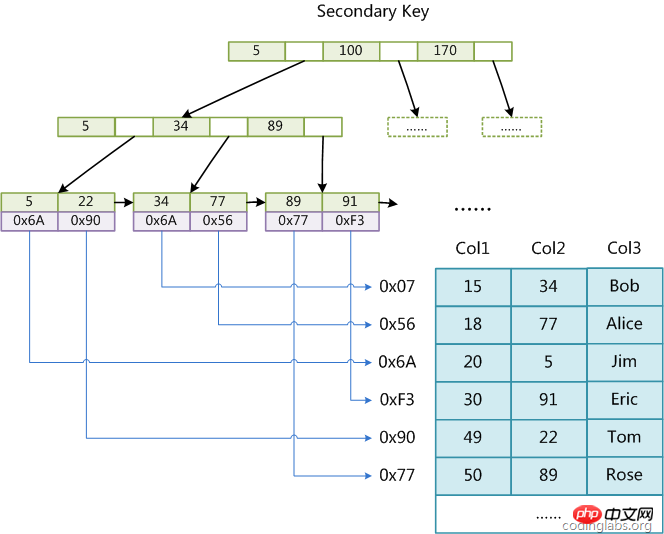
这是最基本的索引,没有任何限制。
------直接创建索引 create index index_name on index_table(name);
索引列的值必须唯一,可以有空值
---------直接创建唯一索引 create UNIQUE index index_phoneNum on index_table(phoneNum);
是一种特殊的唯一索引,必须指定为 PRIMARY KEY,如我们常用的AUTO_INCREMENT自增主键
也称为组合索引,就是在多个字段上联合建立一个索引
-------直接创建组合索引 create index index_union on index_table(name,age,phoneNum);
这里一个组合索引,相当于在有如下三个索引:
name;
name,age;
name,age,phoneNum;
这里或许有这样一个疑惑:为什么age或者age,phoneNum字段上没有索引。这是由于BTree索引因要遵守最左前缀原则,这个原则在后面详细展开。
创建索引简单,但是在哪些列上创建索引则需要好好思考。可以考虑在where字句中出现列或者join字句中出现的列上建索引
SELECT age----不使用索引 FROM index_union WHERE NAME = 'xiaoming'---考虑使用索引 AND phoneNum = '18668247687';---考虑使用索引
联合索引(name,age,phoneNum) ,B+树是按照从左到右的顺序来建立搜索树的。如('张三',18,'18668247652')来检索数据的时候,B+树会优先匹配name来确定搜索方向,name匹配成功再依次匹配age、phoneNum,最后检索到最终的数据。也就是说这种情况下是有三级索引,当name相同,查找age,age也相同时,去比较phoneNum;但是如果拿 (18,'18668247652')来检索时,B+树没有拿到一级索引,根本就无法确定下一步的搜索方向。('张三','18668247652')这种场景也是一样,当name匹配成功后,没有age这个二级索引,只能在name相同的情况下,去遍历所有的phoneNum。
B+树的数据结构决定了在使用索引的时候必须遵守最左前缀原则,在创建联合索引的时候,尽量将经常参与查询的字段放在联合索引的最左边。
一般情况下不建议使用like操作,如果非使用不可的话,需要注意:like '%abd%'不会使用索引,而like ‘aaa%’可以使用索引。这也是前面的最左前缀原则的一个使用场景。
mysql会按照联合索引从左往右进行匹配,直到遇到范围查询,如:>,<,between,like等就停止匹配,a = 1 and b =2 and c > 3 and d = 4,如果建立(a,b,c,d)顺序的索引,d是不会使用索引的。但如果联合索引是(a,b,d,c)的话,则a b d c都可以使用到索引,只是最终c是一个范围值。
order by排序有两种排序方式:using filesort使用算法在内存中排序以及使用mysql的索引进行排序;我们在部分不情况下希望的是使用索引。
| 1 | select test_index where id = 3 order by id desc; |
如果ID是单列索引,则order by会使用索引
| 1 | select test_index where id = 3 order by name desc; |
如果ID是單列索引,name不是索引或name也是單列索引,則order by不會使用索引。因為Mysql的一次查詢只會從眾多索引中選擇一個索引,而這次查詢中使用的是ID列索引,而不是name列索引。 在這種場景下,如果想讓order by也使用索引的話,就建立聯合索引(id,name),這裡需要注意最左前綴原則,不要建立這樣的聯合索引(name,id )。
最後要注意mysql對排序記錄的大小有限制:max_length_for_sort_data 預設為1024;也就表示如果需要排序的資料量大於1024,則order by不會使用索引,而是使用using filesort。
<br/>
<br/>
分散式大型網站,目前看主要有幾類1.大型門戶,如網易,新浪等;2.SNS網站,如校內,開心網等;3.電商網站:例如阿里巴巴,京東商城,國美在線,汽車之家等。 大型入口網站一般是新聞類信息,可以使用CDN,靜態化等方式優化,開心網等交互性比較多,可能會引入更多的NOSQL,分佈式緩存,使用高性能的通信框架等。電商網站具備以上兩類的特點,例如產品詳情可以採用CDN,靜態化,互動性高的需要採用NOSQL等技術。因此,我們採用電商網站作為案例,進行分析。
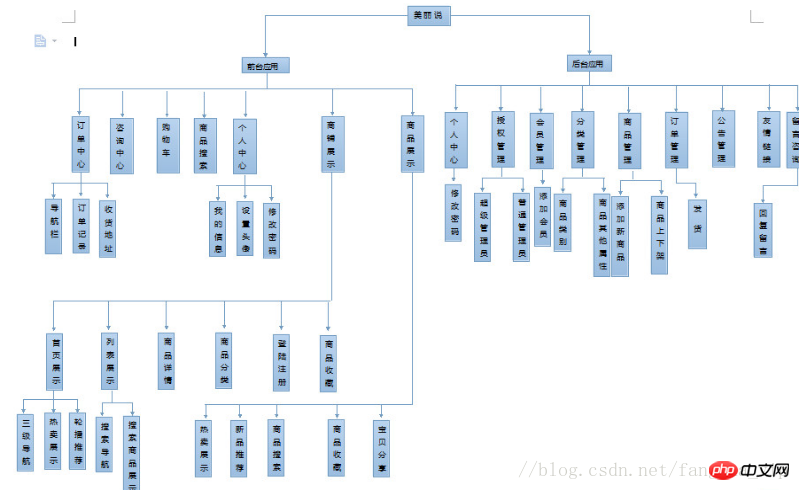
客戶需求:
建立一個全類別的電子商務網站( B2C),用戶可以在線上購買商品,可以在線上支付,也可以貨到付款;
用戶購買時可以在線上與客服溝通;
用戶收到商品後,可以給商品評分,評價;
目前有成熟的進銷存系統;需要與網站對接;
#希望能夠支援3~5年,業務的發展;
預計3~5年用戶數達到1000萬;
定期舉辦雙11,雙12,三八男人節等活動;
其他的功能參考京東或國美在線等網站。
客戶就是客戶,不會告訴你具體要什麼,只會告訴你他想要什麼,我們很多時候要引導,挖掘客戶的需求。好在提供了明確的參考網站。因此,下一步要進行大量的分析,結合產業,以及參考網站,提供給客戶方案。
需求管理傳統的做法,會使用使用案例圖或模組圖(需求清單)進行需求的描述。這樣做常常忽略掉一個很重要的需求(非功能需求),因此推薦大家使用需求功能矩陣,進行需求描述。
本電商網站的需求矩陣如下:


以上是電商網站需求的簡單舉例,目的是說明(1)需求分析的時候,要全面,大型分散式系統重點考慮非功能需求;(2)描述一個簡單的電商需求場景,使大家對下一步的分析設計有個依據。
一般網站,剛開始的做法,是三台伺服器,一台部署應用,一台部署資料庫,一台部署NFS檔案系統。這是前幾年比較傳統的做法,之前見到一個網站10萬多會員,垂直服裝設計門戶,N多圖片。使用了一台伺服器部署了應用,資料庫以及圖片儲存。出現了很多效能問題。如下圖:

但是,目前主流的網站架構已經發生了翻天覆地的變化。 一般都會採用叢集的方式,進行高可用設計。至少是下面這個樣子。

(1)使用叢集對應用伺服器進行冗餘,實現高可用;(負載平衡設備可與應用一塊部署)
(2)使用資料庫主備模式,實現資料備份和高可用;
#預估步驟:
註冊用戶數-日均UV量-每日的PV量-每天的並發量;
峰值預估:平常量的2~3倍;
#根據並發量(並發,事務數),儲存容量計算系統容量;
客戶需求:3~5年用戶數達到1000萬註冊用戶;
每秒並發數預估:
每天的UV為200萬(二八原則);
每日每天點擊瀏覽30次;
PV量:200*30=6000萬;
集中訪問量:240.2=4.8小時會有6000萬0.8=4800萬(二八原則) ;
每分鐘並發量:4.8*60=288分鐘,每分鐘訪問4800/288=16.7萬(約等於);
#每秒並發量:16.7萬/60=2780(約等於);
假設:高峰期為平常值的三倍,則每秒的並發數可以達到8340次。
1毫秒=1.3次存取;
伺服器預估:(以tomcat伺服器舉例)
按一台web伺服器,支援每秒300個並發計算。平常需要10台伺服器(約等於);[tomcat預設配置是150]
#高峰期:需要30台伺服器;
系統CPU一般維持在70%左右的水平,高峰期達到90%的水平,是不浪費資源,並比較穩定的。內存,IO類似。
依業務屬性垂直切分,分割為產品子系統,購物子系統,支付子系統,評論子系統,客服子系統,介面子系統(對接如進銷存,簡訊等外部系統)。
依據業務子系統進行等級定義,可分為核心系統與非核心系統。核心系統:產品子系統,購物子系統,支付子系統;非核心:評論子系統,客服子系統,介面子系統。
業務分割角色:提升為子系統可由專門的團隊和部門負責,專業的人做專業的事,解決模組之間耦合以及擴展性問題;每個子系統單獨部署,避免集中部署導致一個應用程式掛了,全部應用不可用的問題。
等級定義作用:用於流量突發時,對關鍵應用進行保護,實現優雅降級;保護關鍵應用不受到影響。


(1)如上圖每個應用單獨部署;(2)核心系統和非核心系統組合部署;6.2 應用叢集部署(分散式,集群,負載均衡)
分散式部署:將業務分割後的應用程式單獨部署,應用直接透過RPC進行遠端通訊;
叢集部署:電商網站的高可用要求,每個應用至少部署兩台伺服器進行叢集部署;
負載平衡:是高可用系統必須的,一般應用程式透過負載平衡實現高可用,分散式服務透過內建的負載平衡實現高可用,關係型資料庫透過主備方式實現高可用。

快取依照存放的位置一般可分為兩類本機快取和分散式快取。本案例採用二級緩存的方式,進行緩存的設計。一級快取為本地緩存,二級緩存為分散式快取。 (還有頁面緩存,片段緩存等,那是更細粒度的劃分)
一級緩存,緩存數據字典,和常用熱點數據等基本不可變/有規則變化的信息,二級緩存緩存所需的所有緩存。當一級快取過期或不可用時,存取二級快取的資料。如果二級快取也沒有,則存取資料庫。
快取的比例,一般1:4,即可考慮使用快取。 (理論上是1:2即可)。

根據業務特性可使用下列快取過期策略:
(1)快取自動過期;
#(2)快取觸發過期;
系統分割為多個子系統,獨立部署後,不可避免的會遇到會話管理的問題。 一般可採用Session同步,Cookies,分散式Session方式。電商網站一般採用分散式Session實作。
再進一步可以根據分散式Session,建立完善的單一登入或帳號管理系統。

流程說明:
(1)使用者第一次登入時,將會話資訊(使用者Id和使用者資訊),例如以使用者Id為Key,寫入分散式Session;
(2)使用者再次登入時,取得分散式Session,是否有會話訊息,如果沒有則調到登入頁;
( 3)一般採用Cache中間件實現,建議使用Redis,因此它有持久化功能,方便分散式Session宕機後,可以從持久化儲存中載入會話資訊;
(4)存入會話時,可以設定會話保持的時間,例如15分鐘,超過後自動逾時;
結合Cache中間件,實現的分散式Session,可以很好的模擬Session會話。
大型網站需要儲存海量的數據,為達到海量資料存儲,高可用,高效能一般採用冗餘餘的方式進行系統設計。 一般有兩種方式讀寫分離和分庫分錶。
讀寫分離:一般解讀比例遠大於寫比例的場景,可採用一主一備,一主多備或多主多備方式。
本案例在業務分割的基礎上,結合分庫分錶和讀寫分離。如下圖:

(1)業務拆分後:每個子系統需要單獨的庫;
(2)如果單獨的庫太大,可以根據業務特性,進行再次分庫,例如商品分類庫,產品庫;
(3)分庫後,如果表中有資料量很大的,則進行分錶,一般可以依照Id,時間等進行分錶;(進階的用法是一致性Hash)
(4)在分庫,分錶的基礎上,進行讀寫分離;
相關中間件可參考Cobar(阿里,目前已不在維護),TDDL(阿里),Atlas(奇虎360),MyCat(在Cobar基礎上,國內很多牛人,號稱國內第一開源專案)。
分庫分錶後序列的問題,JOIN,事務的問題,會在分庫分錶主題分享中,介紹。
將多個子系統公用的功能/模組,進行抽取,作為公用服務使用。例如本案例的會員子系統就可以抽取為公用的服務。

訊息佇列可以解決子系統/模組之間的耦合,實現非同步,高可用,高效能的系統。是分散式系統的標準配置。本案例中,訊息佇列主要應用在購物,配送環節。
(1)用戶下單後,寫入訊息佇列,然後直接返回客戶端;
(2)庫存子系統:讀取訊息佇列信息,完成減庫存;
(3)配送子系統:讀取訊息佇列訊息,進行配送;

目前使用较多的MQ有Active MQ,Rabbit MQ,Zero MQ,MS MQ等,需要根据具体的业务场景进行选择。建议可以研究下Rabbit MQ。
除了以上介绍的业务拆分,应用集群,多级缓存,单点登录,数据库集群,服务化,消息队列外。还有CDN,反向代理,分布式文件系统,大数据处理等系统。
此处不详细介绍,大家可以问度娘/Google,有机会的话也可以分享给大家。

<br/>
RESTful是"分布式超媒体应用"的架构风格<br/>1.采用URI标识资源;<br/><br/>2.使用“链接”关联相关的资源;<br/><br/>3.使用统一的接口;<br/><br/>4.使用标准的HTTP方法;<br/><br/>5.支持多种资源表示方式;<br/><br/>
6.无状态性;
<br/>
<br/>
windows
最近要熟悉一下网站优化,包括前端优化,后端优化,涉及到的细节Opcode,Xdebuge等,都会浅浅的了解一下。
像类似于,刷刷CSDN博客的人气啦,完全是得心应手啊。
我测试了博客园,使用ab并不能刷访问量,为什么CSDN可以,因为两者统计的方式不同。
--PV(访问量):Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。 --UV(独立访客):Unique Visitor,访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只会被计算一次。 --IP(独立IP):指独立IP数。00:00-24:00内相同IP地址之被计算一次。
1
2
3
4
5
6
PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量。比如一个网站就你一个人进来,通过不断的刷新页面,也可以制造出非常高的PV。这也就是ab可以刷csdn访问的原因了。
UV是指不同的、通过互联网访问、浏览一个网页的自然人。类似于注册用户,保存session的形式
IP就不用说啦。类似于博客园,使用的统计方式就必须是IP啦
ab是Apache的自带的工具,如果是window安装的,找到Apache的bin目录,在系统全局变量中添加Path,然后就可以使用ab了
-c 并发的请求数 -n 要执行的请求总数 -k 启用keep-alive功能(开启的话,请求会快一些) -H 一个使用冒号分隔的head报文头的附加信息 -t 执行这次测试所用的时间
1
2
3
4
5
6
ab -c 5 -n 60 -H "Referer: http://baidu.com" -H "Connection: close" http://blog.csdn.net /XXXXXX/article/details/XXXXXXX
1
2
3
ab -c 100 -n 100 -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:3 8.0) Gecko/20100101 Firefox/38.0" -e "E:\ab.csv" http://blog.csdn.net/uxxxxx/artic le/details/xxxx
1
2
3

本文介绍ab测试,并没有恶意使用它。途中的博客地址,也只是测试过程中借用了一下,没有别的恶意。
原创 2015年10月19日 18:24:31
<br/>
安装ab工具
ubuntu安装ab
apt-get install apache2-utils
centos安装ab
yum install httpd-tools
ab 测试命令
ab -kc 1000-n 1000 http://localhost/ab.html(是服务器下的页面)
<br/>
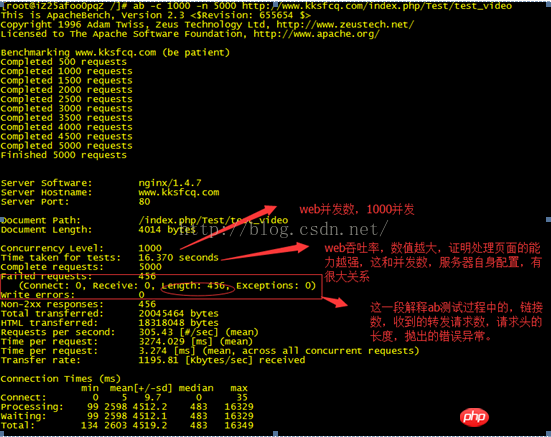
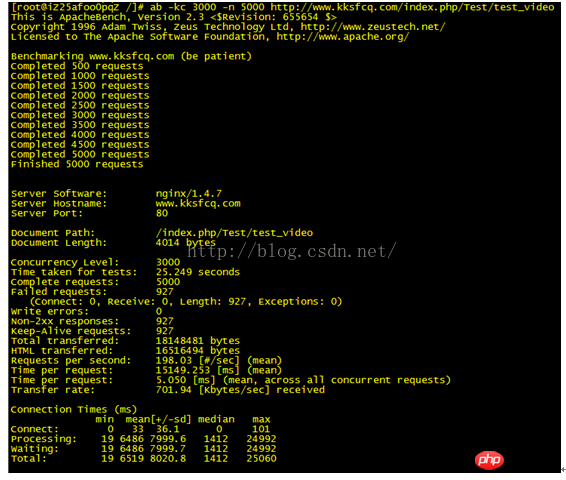 <br/>
<br/>
ySQL中的日誌包含:錯誤日誌、二進位日誌、通用查詢日誌、慢查詢日誌等等。這裡主要介紹下比較常用的兩個功能:通用查詢日誌和慢查詢日誌。
1)通用查詢日誌:記錄建立的客戶端連線和執行的語句。
2)慢查詢日誌:記錄所有執行時間超過long_query_time秒的所有查詢或不使用索引的查詢
(1)通用查詢日誌
在學習通用日誌查詢時,需要知道兩個資料庫中的常用指令:
1) showvariables like '%version%';
效果圖如下:
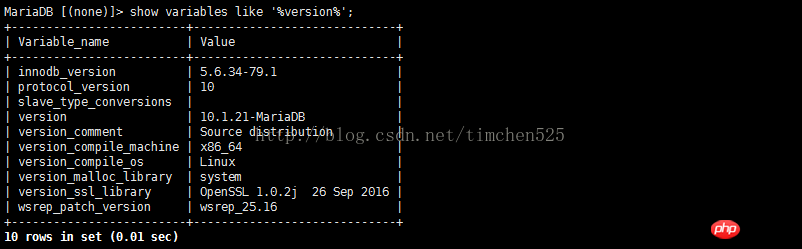 <br/>
<br/>
上述指令,顯示目前資料庫中與版本號相關的東西。
1) showvariables like '%general%';
 <br/>
<br/>
#可以查看,目前的通用日誌查詢是否開啟,如果general_log的值為ON則為開啟,為OFF則為關閉(預設為關閉的)。
1) showvariables like '%log_output%';
 <br/>
<br/>
#查看目前慢查詢日誌輸出的格式,可以是FILE(儲存在數資料庫的資料檔案中的hostname.log),也可以是TABLE(儲存在資料庫中的mysql.general_log)
問題:如何開啟MySQL通用查詢日誌,以及如何設定要輸出的通用日誌輸出格式呢?
開啟通用日誌查詢: set global general_log=on;
關閉通用日誌查詢: set globalgeneral_log=off;
設定通用日誌輸出為表格方式: set globallog_output='TABLE';
設定通用日誌輸出為檔案方式: set globallog_output='FILE';
設定通用日誌輸出為表格和檔案方式:set global log_output='FILE,TABLE';
(注意:上述指令只對目前生效,當MySQL重啟失效,如果要永久生效,需要設定my.cnf)
#日誌輸出的效果圖如下:
記錄到mysql.general_log表中的資料如下:
 <br/>
<br/>
記錄到本機中的.log中的格式如下:
 <br/>
<br/>
my.cnf檔案的設定如下:
general_log=1 #為1表示開啟通用日誌查詢,值為0表示關閉通用日誌查詢
log_output =FILE,TABLE#設定通用日誌的輸出格式為檔案和表格
(2)慢查詢日誌
MySQL的慢查詢日誌是MySQL提供的一種日誌記錄,用來記錄在MySQL中回應時間超過閾值的語句,具體指運行時間超過long_query_time值的SQL,則會被記錄到慢查詢日誌中(日誌可以寫入檔案或資料庫表,如果對效能要求高的話,建議寫文件)。預設情況下,MySQL資料庫是不開啟慢查詢日誌的,long_query_time的預設值為10(即10秒,通常設定為1秒),即執行10秒以上的語句是慢查詢語句。
一般來說,慢查詢發生在大表(例如:一個表的資料量有幾百萬),且查詢條件的欄位沒有建立索引,此時,要匹配查詢條件的欄位會進行全表掃描,耗時查過long_query_time,
則為慢查詢語句。
問題:如何查看目前慢查詢日誌的開啟狀況?
在MySQL中輸入指令:
showvariables like '%quer%';
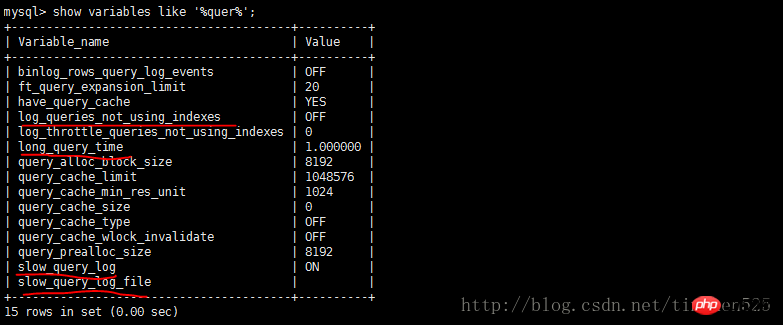 <br/>
<br/>
主要掌握以下的幾個參數:
(1)slow_query_log的值為ON為開啟慢查詢日誌,OFF則為關閉慢查詢日誌。
(2)slow_query_log_file 的值是記錄的慢查詢日誌到檔案中(注意:預設名稱為主機名稱.log,慢查詢日誌是否寫入指定文件中,需要指定慢查詢的輸出日誌格式為文件,相關指令為:show variables like '%log_output%';去查看輸出的格式)。
(3)long_query_time 指定了慢查詢的閾值,即如果執行語句的時間超過該閾值則為慢查詢語句,預設值為10秒。
(4)log_queries_not_using_indexes 如果值設為ON,則會記錄所有沒有利用索引的查詢(注意:如果只是將log_queries_not_using_indexes設為ON,而將slow_query_log設定為OFF,此時該設定也不會生效,即該設定生效的前提是slow_query_log的值設為ON),一般在效能調優的時候會暫時開啟。
問題:設定MySQL慢查詢的輸出日誌格式為檔案還是表,或是兩者都有?
透過指令:show variables like '%log_output%';
 <br/>
<br/>
#透過log_output的值可以檢視輸出的格式,上面的值為TABLE。當然,我們也可以設定輸出的格式為文本,或者同時記錄文本和資料庫表中,設定的命令如下:
#慢查詢日誌輸出到表中(即mysql.slow_log)
set globallog_output='TABLE';
#慢查詢日誌只輸出到文字中(即:slow_query_log_file指定的檔案)
setglobal log_output='FILE';
##慢查詢日誌同時輸出到文字和表格中
setglobal log_output='FILE,TABLE';
關於慢查詢日誌的表中的資料個文字中的數據格式分析:
慢查詢的日誌記錄myql.slow_log表中,格式如下:
 <br/>
<br/>
慢查詢的日誌記錄到hostname.log檔案中,格式如下:
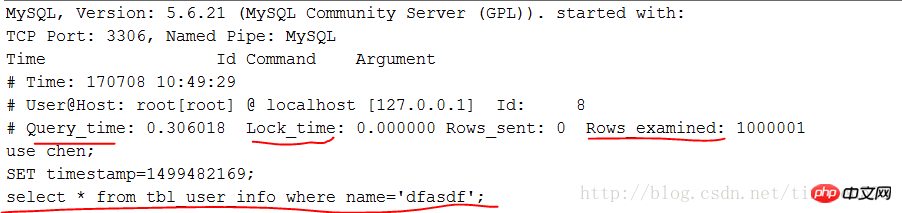 <br/>
<br/>
可以看到,不管是表還是文件,都具體記錄了:是那個語句導致慢查詢( sql_text),此慢查詢語句的查詢時間(query_time),鎖定表時間(Lock_time),以及掃描過的行數(rows_examined)等資訊。
問題:如何查詢目前慢查詢的語句的個數?
在MySQL中有一個變數專門記錄目前慢查詢語句的個數:
輸入指令:show global status like '%slow%';
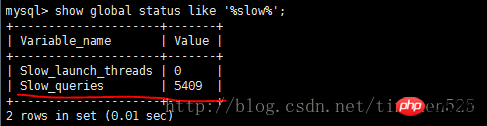 <br/>
<br/>
#(注意:上述所有指令,如果都是透過MySQL的shell將參數設定進去,如果重新啟動MySQL,所有設定好的參數將會失效,如果想要永久的生效,需要將設定參數寫入my.cnf檔案中)。
補充知識點:如何利用MySQL自帶的慢查詢日誌分析工具mysqldumpslow分析日誌?
perlmysqldumpslow –s c –t 10 slow-query.log
具體參數設定如下:
-s 表示以何種方式排序,c 、t、l、r分別是依照記錄次數、時間、查詢時間、傳回的記錄數來排序,ac、at、al、ar,表示對應的倒敘;
##-t 表示top的意思,後面跟著的資料表示返回前面多少條;-g 後面可以寫正規表示式匹配,大小寫不敏感。 <br/>
<br/>
http://blog.csdn.net/a600423444/article/details/68544428968544428 (
注意:mysqldumpslow腳本是用perl語言寫的,具體mysqldumpslow的用法後期再講)
問題:實際上在學習過程中,如何得知設定的慢查詢是有效的?
很簡單,我們可以手動產生一條慢查詢語句,比如,如果我們的慢查詢log_query_time的值設為1,則我們可以執行如下語句:
selectsleep(1);
該條語句即是慢查詢語句,之後,便可以在對應的日誌輸出檔案或表格中去查看是否有該條語句。 <br/>
#開源框架(TP,CI,Laravel,Yii)
<br/>
#######ThinkPHP简称TP,TP借鉴了Java思想,基于PHP5,充分利用了PHP5的特性,部署简单只需要一个入口文件,一起搞定,简单高效。中文文档齐全,入门超级简单。自带模板引擎,具有独特的数据验证和自动填充功能,框架更新速度比较速度。
优点:这个框架易使用 易学 安全 对bae sae支持很好提供的工具也很强大 可以支持比较大的项目开发 易扩展 全中文文档 总的来说这款框架适合非常适合国人使用 性能 上比CI还要强一些
缺点:配置对有些人来说有些复杂(其实是因为没有认真的读过其框架源码)文档有些滞后 有些组件未有文档说明。
CodeIgniter简称CI 简单配置,上手很快,全部的配置使用PHP脚本来配置,没有使用很多太复杂的设计模式,(MVC设计模式)执行性能和代码可读性上都不错。执行效率较高,具有基本的MVC功能,快速简洁,代码量少,框架容易上手,自带了很多简单好用的library。 框架适合中小型项目,大型项目也可以,只是扩展能力差。优点:这个框架的入门槛很底 极易学 极易用 框架很小 静态化非常容易 框架易扩展 文档比较详尽
缺点:在极易用的极小下隐藏的缺点即是不安全 功能不是太全 缺少非常多的东西 比如你想使用MongoDB你就得自己实现接口… 对数据的操作亦不是太安全 比如对update和delete操作等不够安全 暂不支持sae bae等(毕竟是欧洲)对大型项目的支持不行 小型项目会非常好。
CI和TP的对比(http://www.jcodecraeer.com/a/phpjiaocheng/2012/0711/309.html)
Laravel的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD和BDD(http://blog.csdn.net/bennes/article/details/47973129 TDD DDD BDD解释 ),作为一个框架,它为你准备好了一切,composer是个php的未来,没有composer,PHP肯定要走向没落。laravel最大的特点和处优秀之就是集合了php比较新的特性,以及各种各样的设计模式,Ioc容器,依赖注入等。因此laravel是一个适合学习的框架,他和其他的框架思想有着极大的不同,这也要求你非常熟练php,基础扎实。
优点:http://www.codeceo.com/article/why-laravel-best-php-framework.html
Yii是一个基于组件的高性能的PHP的框架,用于开发大规模Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主体化,I18N和L10N,Yii提供了今日Web 2.0应用开发所需要的几乎一切功能。而且这个框架的价格也并不太高。事实上,Yii是最有效率的PHP框架之一。
<br/>
原创 2016年11月09日 17:58:50
<br/>
在PHP中,出现同名函数或是同名类是不被允许的。为防止编程人员在项目中定义的类名或函数名出现重复冲突,在PHP5.3中引入了命名空间这一概念。
1.命名空间,即将代码划分成不同空间,不同空间的类名相互独立,互不冲突。一个php文件中可以存在多个命名空间,第一个命名空间前不能有任何代码。内容空间声明后的代码便属于这个命名空间,例如:
<?php
echo 111;
//由于namespace前有代码而报错
namespace Teacher;
class Person{
function __construct(){
echo 'Please study!';
}
}2.调用不同空间内类或方法需写明命名空间。例如:
登入後複製
3.在命名空间内引入其他文件不会属于本命名空间,而属于公共空间或是文件中本身定义的命名空间。例:
首先定义一个1.php和2.php文件:
登入後複製
<?php namespace Newer; require_once './1.php'; new Person(); //报错,找不到Person; new \Person(); //输出 I am tow!;
登入後複製
<?php namespace New; require_once './2.php'; new Person(); //报错,(当前空间)找不到 Person; new \Person(); //报错,(公共空间)找不到 Person; new \Two\Person(); //输出 I am tow!;
4.下面我们来看use的使用方法:(use以后引用可简写)
namespace School\Parents;
class Man{
function __construct(){
echo 'Listen to teachers!<br/>';
}
}
namespace School\Teacher;
class Person{
function __construct(){
echo 'Please study!<br/>';
}
}
namespace School\Student;
class Person{
function __construct(){
echo 'I want to play!<br/>';
}
}
new Person();
//输出I want to play!
new \School\Teacher\Person();
//输出Please study!
new Teacher\Person();
//报错 ----------
use School\Teacher;
new Teacher\Person();
//输出Please study! ----------
use School\Teacher as Tc;
new Tc\Person();
//输出Please study! ----------
use \School\Teacher\Person;
new Person();
//报错 ----------
use \School\Parent\Man;
new Man();
//报错相关推荐:
以上是php面試的總結的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















