

python程式設計透過蒙特卡羅法計算定積分詳解

這篇文章主要介紹了python程式設計透過蒙特卡羅法計算定積分詳解,具有一定借鑒價值,需要的朋友可以參考下。
想當初,考研的時候要是知道有這麼好東西,計算定積分。 。 。開玩笑,那時候計算定積分根本沒有這麼簡單的。但這確實給我開啟了一個思路,用程式語言解決更多更複雜的數學問題。下面進入正題。
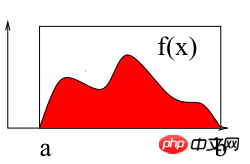
如上圖所示,計算區間[a b]上f(x)的積分即求曲線與X軸圍成紅色區域的面積。以下使用蒙特卡羅法計算區間[2 3]上的定積分:∫(x2 4*x*sin(x))dx
##
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2 + 4*x*np.sin(x)
def intf(x):
return x**3/3.0+4.0*np.sin(x) - 4.0*x*np.cos(x)
a = 2;
b = 3;
# use N draws
N= 10000
X = np.random.uniform(low=a, high=b, size=N) # N values uniformly drawn from a to b
Y =f(X) # CALCULATE THE f(x)
# 蒙特卡洛法计算定积分:面积=宽度*平均高度
Imc= (b-a) * np.sum(Y)/ N;
exactval=intf(b)-intf(a)
print "Monte Carlo estimation=",Imc, "Exact number=", intf(b)-intf(a)
# --How does the accuracy depends on the number of points(samples)? Lets try the same 1-D integral
# The Monte Carlo methods yield approximate answers whose accuracy depends on the number of draws.
Imc=np.zeros(1000)
Na = np.linspace(0,1000,1000)
exactval= intf(b)-intf(a)
for N in np.arange(0,1000):
X = np.random.uniform(low=a, high=b, size=N) # N values uniformly drawn from a to b
Y =f(X) # CALCULATE THE f(x)
Imc[N]= (b-a) * np.sum(Y)/ N;
plt.plot(Na[10:],np.sqrt((Imc[10:]-exactval)**2), alpha=0.7)
plt.plot(Na[10:], 1/np.sqrt(Na[10:]), 'r')
plt.xlabel("N")
plt.ylabel("sqrt((Imc-ExactValue)$^2$)")
plt.show()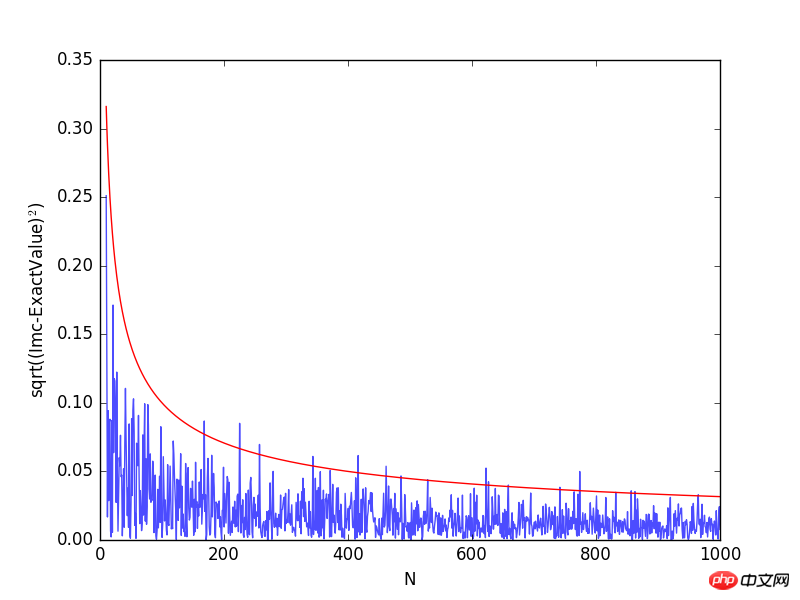
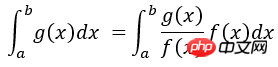
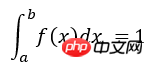
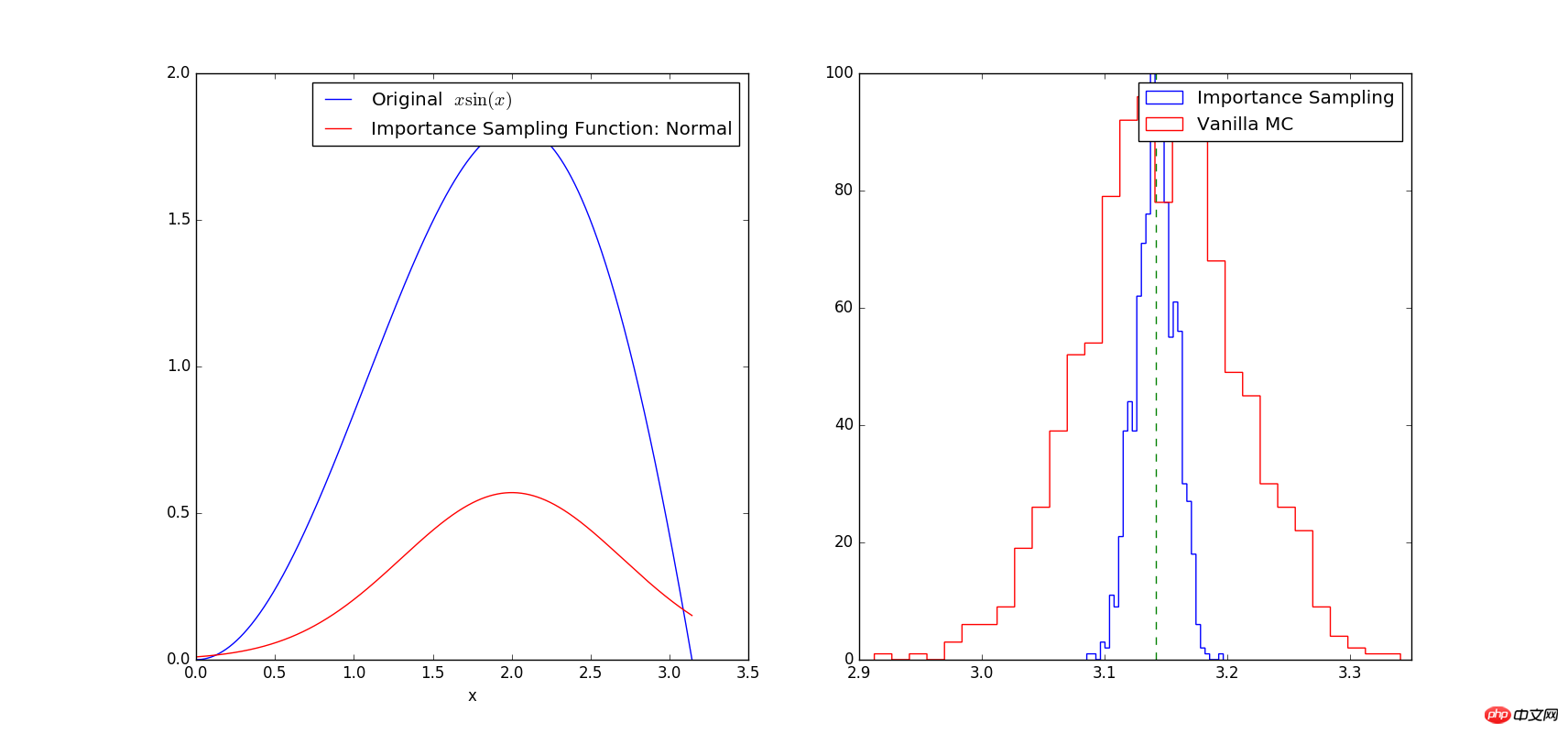
# -*- coding: utf-8 -*- # Example: Calculate ∫sin(x)xdx # The function has a shape that is similar to Gaussian and therefore # we choose here a Gaussian as importance sampling distribution. from scipy import stats from scipy.stats import norm import numpy as np import matplotlib.pyplot as plt mu = 2; sig =.7; f = lambda x: np.sin(x)*x infun = lambda x: np.sin(x)-x*np.cos(x) p = lambda x: (1/np.sqrt(2*np.pi*sig**2))*np.exp(-(x-mu)**2/(2.0*sig**2)) normfun = lambda x: norm.cdf(x-mu, scale=sig) plt.figure(figsize=(18,8)) # set the figure size # range of integration xmax =np.pi xmin =0 # Number of draws N =1000 # Just want to plot the function x=np.linspace(xmin, xmax, 1000) plt.subplot(1,2,1) plt.plot(x, f(x), 'b', label=u'Original $x\sin(x)$') plt.plot(x, p(x), 'r', label=u'Importance Sampling Function: Normal') plt.xlabel('x') plt.legend() # ============================================= # EXACT SOLUTION # ============================================= Iexact = infun(xmax)-infun(xmin) print Iexact # ============================================ # VANILLA MONTE CARLO # ============================================ Ivmc = np.zeros(1000) for k in np.arange(0,1000): x = np.random.uniform(low=xmin, high=xmax, size=N) Ivmc[k] = (xmax-xmin)*np.mean(f(x)) # ============================================ # IMPORTANCE SAMPLING # ============================================ # CHOOSE Gaussian so it similar to the original functions # Importance sampling: choose the random points so that # more points are chosen around the peak, less where the integrand is small. Iis = np.zeros(1000) for k in np.arange(0,1000): # DRAW FROM THE GAUSSIAN: xis~N(mu,sig^2) xis = mu + sig*np.random.randn(N,1); xis = xis[ (xis<xmax) & (xis>xmin)] ; # normalization for gaussian from 0..pi normal = normfun(np.pi)-normfun(0) # 注意:概率密度函数在采样区间[0 pi]上的积分需要等于1 Iis[k] =np.mean(f(xis)/p(xis))*normal # 因此,此处需要乘一个系数即p(x)在[0 pi]上的积分 plt.subplot(1,2,2) plt.hist(Iis,30, histtype='step', label=u'Importance Sampling'); plt.hist(Ivmc, 30, color='r',histtype='step', label=u'Vanilla MC'); plt.vlines(np.pi, 0, 100, color='g', linestyle='dashed') plt.legend() plt.show()
Python程式設計中NotImplementedError的使用方法_python
以上是python程式設計透過蒙特卡羅法計算定積分詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
