

詳解PyTorch批次訓練及優化器比較

本篇文章主要介紹了詳解PyTorch批訓練及優化器比較,詳細的介紹了什麼是PyTorch批訓練和PyTorch的Optimizer優化器,非常具有實用價值,需要的朋友可以參考下
一、PyTorch批訓練
#1. 概述
PyTorch提供了一種將資料包裝起來進行批訓練的工具-DataLoader。使用的時候,只需要將我們的資料先轉換成torch的tensor形式,再轉換成torch可以辨識的Dataset格式,然後將Dataset放入DataLoader中就可以啦。
import torch
import torch.utils.data as Data
torch.manual_seed(1) # 设定随机数种子
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(0.5, 5, 10)
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE, # 批大小
# 若dataset中的样本数不能被batch_size整除的话,最后剩余多少就使用多少
shuffle=True, # 是否随机打乱顺序
num_workers=2, # 多线程读取数据的线程数
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch:', epoch, '|Step:', step, '|batch_x:',
batch_x.numpy(), '|batch_y', batch_y.numpy())
'''''
shuffle=True
Epoch: 0 |Step: 0 |batch_x: [ 6. 7. 2. 3. 1.] |batch_y [ 3. 3.5 1. 1.5 0.5]
Epoch: 0 |Step: 1 |batch_x: [ 9. 10. 4. 8. 5.] |batch_y [ 4.5 5. 2. 4. 2.5]
Epoch: 1 |Step: 0 |batch_x: [ 3. 4. 2. 9. 10.] |batch_y [ 1.5 2. 1. 4.5 5. ]
Epoch: 1 |Step: 1 |batch_x: [ 1. 7. 8. 5. 6.] |batch_y [ 0.5 3.5 4. 2.5 3. ]
Epoch: 2 |Step: 0 |batch_x: [ 3. 9. 2. 6. 7.] |batch_y [ 1.5 4.5 1. 3. 3.5]
Epoch: 2 |Step: 1 |batch_x: [ 10. 4. 8. 1. 5.] |batch_y [ 5. 2. 4. 0.5 2.5]
shuffle=False
Epoch: 0 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 0 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 1 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 1 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 2 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 2 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
'''2. TensorDataset
classtorch.utils.data.TensorDataset(data_tensor, target_tensor)
TensorDataset類別用來將樣本及其標籤打包成torch的Dataset,data_tensor,和target_tensor都是tensor。
3. DataLoader
#複製程式碼 程式碼如下:
classtorch.utils .data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,num_workers=0, collate_fn=
二、PyTorch的Optimizer優化器#本實驗中,先建構一組資料集,轉換格式並置於DataLoader中,備用。定義一個固定結構的預設神經網絡,然後為每個優化器建立一個神經網絡,每個神經網路的差異只是優化器不同。透過記錄訓練過程中的loss值,最後在影像上呈現得到各個優化器的最佳化過程。
程式碼實作:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 定义超参数
LR = 0.01 # 学习率
BATCH_SIZE = 32 # 批大小
EPOCH = 12 # 迭代次数
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show()
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
# 定义损失函数
loss_function = torch.nn.MSELoss()
losses_history = [[], [], [], []] # 记录training时不同神经网络的loss值
for epoch in range(EPOCH):
print('Epoch:', epoch + 1, 'Training...')
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_history):
output = net(b_x)
loss = loss_function(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data[0])
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()實驗結果:
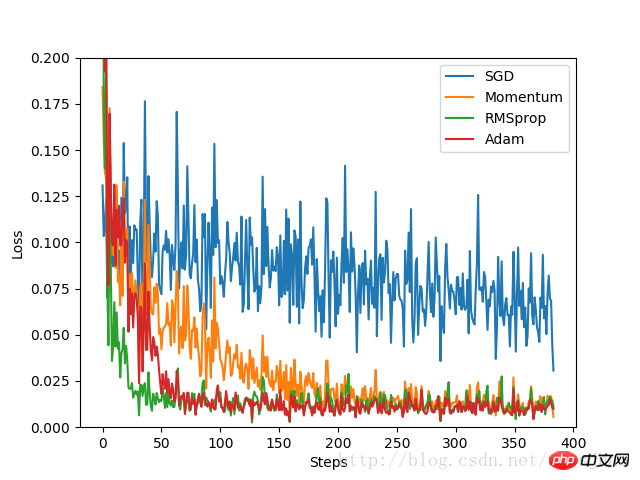 由實驗結果可見,SGD的最佳化效果是最差的,速度很慢;作為SGD的改良版本,Momentum表現就好許多;相比RMSprop和Adam的優化速度就非常好。實驗中,針對不同的最佳化問題,比較各個最佳化器的效果再來決定要使用哪一個。
由實驗結果可見,SGD的最佳化效果是最差的,速度很慢;作為SGD的改良版本,Momentum表現就好許多;相比RMSprop和Adam的優化速度就非常好。實驗中,針對不同的最佳化問題,比較各個最佳化器的效果再來決定要使用哪一個。
三、其他補充
#1. Python的zip函數zip函數接受任意多個(包括0個和1個)序列作為參數,傳回一個tuple清單。
x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] xyz = zip(x, y, z) print xyz [(1, 4, 7), (2, 5, 8), (3, 6, 9)] x = [1, 2, 3] x = zip(x) print x [(1,), (2,), (3,)] x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy [(1, 4), (2, 5), (3, 6)]
相關推薦:
Pytorch入門之mnist分類實例以上是詳解PyTorch批次訓練及優化器比較的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 小米14 Pro怎麼開啟nfc功能?
Mar 19, 2024 pm 02:28 PM
小米14 Pro怎麼開啟nfc功能?
Mar 19, 2024 pm 02:28 PM
現今手機的效能和功能越來越強大,幾乎所有手機都配備了便利的NFC功能,方便用戶進行行動支付和身分認證。然而,有些小米14Pro的用戶可能不清楚如何啟用NFC功能。接下來,讓我詳細向大家介紹一下。小米14Pro怎麼開啟nfc功能?步驟一:打開手機的設定選單。步驟二:找到並點選「連接和分享」或「無線和網路」選項。步驟三:在連接和共享或無線和網路選單中,找到並點擊「NFC和付款」。步驟四:找到並點選「NFC開關」。一般情況下,預設是關閉的狀態。步驟五:在NFC開關頁面上,點選開關按鈕,將其切換為開啟狀
 華為 Pocket2怎麼隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
華為 Pocket2怎麼隔空刷抖音?
Mar 18, 2024 pm 03:00 PM
隔空滑動螢幕是華為的一項功能,在華為mate60系列中可以說是備受好評,這個功能是通過利用手機上的激光感應器和前置攝像頭的3D深感攝像頭,來完成一系列不需要觸碰螢幕的功能,比如說隔空刷抖音,但華為Pocket2該要怎麼隔空刷抖音呢?華為Pocket2怎麼隔空截圖? 1.開啟華為Pocket2的設定2、然後選擇【輔助功能】。 3.點選打開【智慧感知】。 4.打開【隔空滑動螢幕】、【隔空截圖】、【隔空按壓】開關就可以了。 5.使用的時候,需要再距離螢幕20~40CM處,張開手掌,待螢幕上出現手掌圖標,
 WPS Word怎麼設定行距讓文件更工整
Mar 20, 2024 pm 04:30 PM
WPS Word怎麼設定行距讓文件更工整
Mar 20, 2024 pm 04:30 PM
WPS是我們常用的辦公室軟體,在進行長篇文章的編輯時,常常會因為字體太小而看不清楚,所以會對字體和整個文件進行調整。例如:把文件進行行距的調整,會讓整個文件變得非常清晰,我建議各位小夥伴們都要學會這個操作步驟,今天就分享給大家,具體的操作步驟如下,快來看一看!開啟要調整的WPS文字文件,在【開始】選單中找到段落設定工具欄,你會看到行距設定小圖示(如圖中紅色線圈所示)。 2.點選行距設定右下角的小倒三角形,會出現對應的行距數值,可以選擇1~3倍行距(如圖箭頭所示)。 3.或者點選滑鼠右鍵點擊段落,就會出
 TrendX 研究院:Merlin Chain 計畫分析及生態盤點
Mar 24, 2024 am 09:01 AM
TrendX 研究院:Merlin Chain 計畫分析及生態盤點
Mar 24, 2024 am 09:01 AM
根據3月2日數據統計,比特幣二層網路MerlinChain總TVL已達30億美元。其中比特幣生態資產佔比達90.83%,包括價值15.96億美元的BTC以及4.04億美元的BRC-20資產等。上一個月,MerlinChain在開啟質押活動14天內,其TVL總額就已經達到了19.7億美元,超過了去年11月份上線也是最近同樣引人注目的Blast。 2月26日,MerlinChain生態內的NFT總價值超過了4.2億美元,成為除以太坊以外NFT市值最高的公鏈項目。項目簡介MerlinChain是OKX支
 C語言與PHP的區別及比較分析
Mar 20, 2024 am 08:54 AM
C語言與PHP的區別及比較分析
Mar 20, 2024 am 08:54 AM
C語言與PHP的差異及比較分析C語言和PHP都是常見的程式語言,但它們在許多方面有著明顯的差異。本文將對C語言和PHP進行比較分析,並透過具體的程式碼範例來說明它們之間的差異。一、語法和用途:C語言:C語言是一種過程導向的程式語言,主要用於系統級程式設計和嵌入式開發。 C語言的語法相對較為簡潔和底層,能夠直接操作內存,具有高效性和靈活性。 C語言強調程式設計師對程式的完全
 大模型中常用的注意力機制GQA詳解以及Pytorch程式碼實現
Apr 03, 2024 pm 05:40 PM
大模型中常用的注意力機制GQA詳解以及Pytorch程式碼實現
Apr 03, 2024 pm 05:40 PM
群組查詢注意力(GroupedQueryAttention)是大型語言模型中的多查詢注意力方法,它的目標是在保持MQA速度的同時實現MHA的品質。 GroupedQueryAttention將查詢分組,每個群組內的查詢共享相同的注意力權重,這有助於降低計算複雜度和提高推理速度。在這篇文章中,我們將解釋GQA的想法以及如何將其轉化為程式碼。 GQA是在論文GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 C++ 程式最佳化:時間複雜度降低技巧
Jun 01, 2024 am 11:19 AM
C++ 程式最佳化:時間複雜度降低技巧
Jun 01, 2024 am 11:19 AM
時間複雜度衡量演算法執行時間與輸入規模的關係。降低C++程式時間複雜度的技巧包括:選擇合適的容器(如vector、list)以最佳化資料儲存和管理。利用高效演算法(如快速排序)以減少計算時間。消除多重運算以減少重複計算。利用條件分支以避免不必要的計算。透過使用更快的演算法(如二分搜尋)來優化線性搜尋。
 小米14 Ultra AI智慧擴圖如何使用?
Mar 16, 2024 pm 12:37 PM
小米14 Ultra AI智慧擴圖如何使用?
Mar 16, 2024 pm 12:37 PM
時代的進步讓許多人收入越來越高了,平時使用的手機也會經常更換,最近小米剛推出的小米14Ultra想必用戶們都是有所了解的,性能配置非常高,能夠為用戶們提供更為舒適的流暢體驗,不過新手機難免會遇到很多不會用的功能,例如小米14UltraAI智慧擴圖怎麼使用?快來看看下面的使用教學吧!小米14UltraAI智慧擴圖怎麼使用?先打開小米14Ultra,進入相冊,選擇想要進行擴圖的圖片,進入相簿編輯選項。點選其中的裁切旋轉,點選裁切,在出現的選擇中點選智慧擴圖。最後根據你自己的需求來選擇擴圖的方式,
