

PyTorch上搭建簡單神經網路實作迴歸與分類的範例

本篇文章主要介紹了PyTorch上搭建簡單神經網路實作迴歸和分類的範例,現在分享給大家,也給大家做個參考。一起來看看吧
本文介紹了PyTorch上搭建簡單神經網路實作迴歸與分類的範例,分享給大家,具體如下:

##一、PyTorch入門
1. 安裝方法
登入PyTorch官網,http://pytorch.org,可以看到以下介面:
conda install pytorch torchvision -c soumith
2. Numpy與Torch
torch_data = torch.from_numpy(np_data)可以將numpy(array)格式轉換為torch(tensor)格式;torch_data.numpy( )又可以將torch的tensor格式轉換為numpy的array格式。注意Torch的Tensor和numpy的array會共用他們的儲存空間,修改一個會導致另外的一個也被修改。 對於1維(1-D)的數據,numpy是以行向量的形式列印輸出,而torch是以列向量的形式列印輸出的。 其他例如sin, cos, abs,mean等numpy中的函數在torch中用法相同。要注意的是,numpy中np.matmul(data, data)和data.dot(data)矩陣相乘會得到相同結果;torch中torch.mm(tensor, tensor)是矩陣相乘的方法,得到一個矩陣,tensor.dot(tensor)會把tensor轉換成1維的tensor,然後逐元素相乘後求和,得到與一個實數。相關程式碼:
import torch import numpy as np np_data = np.arange(6).reshape((2, 3)) torch_data = torch.from_numpy(np_data) # 将numpy(array)格式转换为torch(tensor)格式 tensor2array = torch_data.numpy() print( '\nnumpy array:\n', np_data, '\ntorch tensor:', torch_data, '\ntensor to array:\n', tensor2array, ) # torch数据格式在print的时候前后自动添加换行符 # abs data = [-1, -2, 2, 2] tensor = torch.FloatTensor(data) print( '\nabs', '\nnumpy: \n', np.abs(data), '\ntorch: ', torch.abs(tensor) ) # 1维的数据,numpy是行向量形式显示,torch是列向量形式显示 # sin print( '\nsin', '\nnumpy: \n', np.sin(data), '\ntorch: ', torch.sin(tensor) ) # mean print( '\nmean', '\nnumpy: ', np.mean(data), '\ntorch: ', torch.mean(tensor) ) # 矩阵相乘 data = [[1,2], [3,4]] tensor = torch.FloatTensor(data) print( '\nmatrix multiplication (matmul)', '\nnumpy: \n', np.matmul(data, data), '\ntorch: ', torch.mm(tensor, tensor) ) data = np.array(data) print( '\nmatrix multiplication (dot)', '\nnumpy: \n', data.dot(data), '\ntorch: ', tensor.dot(tensor) )
#3. Variable
PyTorch中的神經網路來自於autograd包,autograd包提供了Tensor所有操作的自動求導方法。 autograd.Variable這是這個套件中最核心的類別。可以將Variable理解為裝有tensor的容器,它包裝了一個Tensor,並且幾乎支援所有的定義在其上的操作。一旦完成運算,便可以呼叫 .backward()來自動計算出所有的梯度。也就是說只有把tensor置於Variable中,才能在神經網路中實現反向傳遞、自動求導等運算。 可以透過屬性 .data 來存取原始的tensor,而關於這一Variable的梯度則可透過 .grad屬性查看。相關程式碼:
import torch from torch.autograd import Variable tensor = torch.FloatTensor([[1,2],[3,4]]) variable = Variable(tensor, requires_grad=True) # 打印展示Variable类型 print(tensor) print(variable) t_out = torch.mean(tensor*tensor) # 每个元素的^ 2 v_out = torch.mean(variable*variable) print(t_out) print(v_out) v_out.backward() # Variable的误差反向传递 # 比较Variable的原型和grad属性、data属性及相应的numpy形式 print('variable:\n', variable) # v_out = 1/4 * sum(variable*variable) 这是计算图中的 v_out 计算步骤 # 针对于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2 print('variable.grad:\n', variable.grad) # Variable的梯度 print('variable.data:\n', variable.data) # Variable的数据 print(variable.data.numpy()) #Variable的数据的numpy形式
#部分輸出結果:
variable:Variable containing:
1 2
3 4
[torch.FloatTensor of size 2x2]
variable.grad:
Variable containing:
0.5000 1.0000
1.5000 2.0000
[torch.FloatTensor of size 2x2]
variable.data:
1 2
3 4
[torch.FloatTensor of size 2x2]
#[[ . 2.]
[ 3. 4.]]
4.激勵函數activationfunction
Torch的激勵函數都在torch.nn. functional中,relu,sigmoid, tanh, softplus都是常用的激勵函數。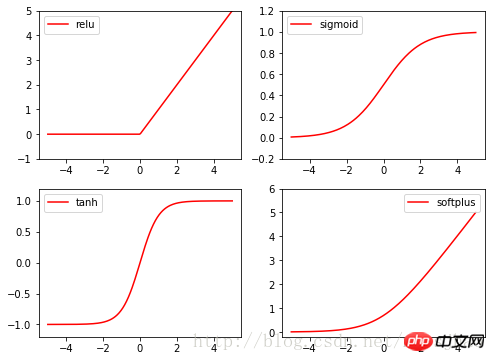
相關程式碼:
#
import torch import torch.nn.functional as F from torch.autograd import Variable import matplotlib.pyplot as plt x = torch.linspace(-5, 5, 200) x_variable = Variable(x) #将x放入Variable x_np = x_variable.data.numpy() # 经过4种不同的激励函数得到的numpy形式的数据结果 y_relu = F.relu(x_variable).data.numpy() y_sigmoid = F.sigmoid(x_variable).data.numpy() y_tanh = F.tanh(x_variable).data.numpy() y_softplus = F.softplus(x_variable).data.numpy() plt.figure(1, figsize=(8, 6)) plt.subplot(221) plt.plot(x_np, y_relu, c='red', label='relu') plt.ylim((-1, 5)) plt.legend(loc='best') plt.subplot(222) plt.plot(x_np, y_sigmoid, c='red', label='sigmoid') plt.ylim((-0.2, 1.2)) plt.legend(loc='best') plt.subplot(223) plt.plot(x_np, y_tanh, c='red', label='tanh') plt.ylim((-1.2, 1.2)) plt.legend(loc='best') plt.subplot(224) plt.plot(x_np, y_softplus, c='red', label='softplus') plt.ylim((-0.2, 6)) plt.legend(loc='best') plt.show()
##二、PyTorch實作迴歸
先看完整程式碼:import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 将1维的数据转换为2维数据
y = x.pow(2) + 0.2 * torch.rand(x.size())
# 将tensor置入Variable中
x, y = Variable(x), Variable(y)
#plt.scatter(x.data.numpy(), y.data.numpy())
#plt.show()
# 定义一个构建神经网络的类
class Net(torch.nn.Module): # 继承torch.nn.Module类
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__() # 获得Net类的超类(父类)的构造方法
# 定义神经网络的每层结构形式
# 各个层的信息都是Net类对象的属性
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出
self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出
# 将各层的神经元搭建成完整的神经网络的前向通路
def forward(self, x):
x = F.relu(self.hidden(x)) # 对隐藏层的输出进行relu激活
x = self.predict(x)
return x
# 定义神经网络
net = Net(1, 10, 1)
print(net) # 打印输出net的结构
# 定义优化器和损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.5) # 传入网络参数和学习率
loss_function = torch.nn.MSELoss() # 最小均方误差
# 神经网络训练过程
plt.ion() # 动态学习过程展示
plt.show()
for t in range(300):
prediction = net(x) # 把数据x喂给net,输出预测值
loss = loss_function(prediction, y) # 计算两者的误差,要注意两个参数的顺序
optimizer.zero_grad() # 清空上一步的更新参数值
loss.backward() # 误差反相传播,计算新的更新参数值
optimizer.step() # 将计算得到的更新值赋给net.parameters()
# 可视化训练过程
if (t+1) % 10 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
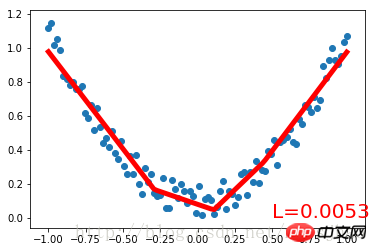
plt.text(0.5, 0, 'L=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)運行結果:
Net (
(hidden): Linear (1 -> 10)(predict): Linear (10 -> 1)
)
三、PyTorch实现简单分类
完整代码:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 生成数据
# 分别生成2组各100个数据点,增加正态噪声,后标记以y0=0 y1=1两类标签,最后cat连接到一起
n_data = torch.ones(100,2)
# torch.normal(means, std=1.0, out=None)
x0 = torch.normal(2*n_data, 1) # 以tensor的形式给出输出tensor各元素的均值,共享标准差
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # 组装(连接)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
# 置入Variable中
x, y = Variable(x), Variable(y)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2)
print(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.012)
loss_func = torch.nn.CrossEntropyLoss()
plt.ion()
plt.show()
for t in range(100):
out = net(x)
loss = loss_func(out, y) # loss是定义为神经网络的输出与样本标签y的差别,故取softmax前的值
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 2 == 0:
plt.cla()
# 过了一道 softmax 的激励函数后的最大概率才是预测值
# torch.max既返回某个维度上的最大值,同时返回该最大值的索引值
prediction = torch.max(F.softmax(out), 1)[1] # 在第1维度取最大值并返回索引值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
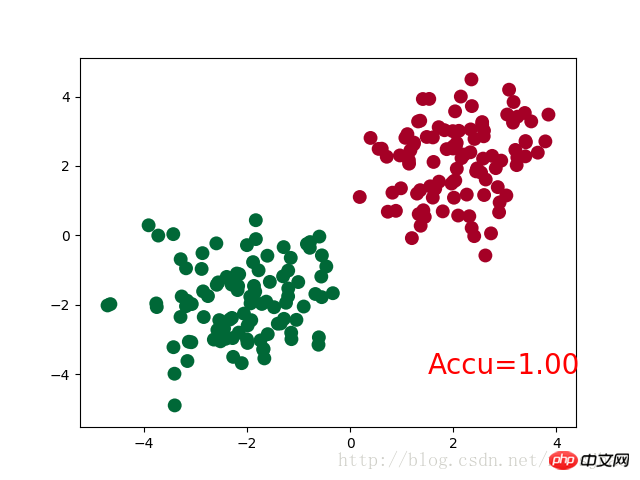
accuracy = sum(pred_y == target_y)/200 # 预测中有多少和真实值一样
plt.text(1.5, -4, 'Accu=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()神经网络结构部分的Net类与前文的回归部分的结构相同。
需要注意的是,在循环迭代训练部分,out定义为神经网络的输出结果,计算误差loss时不是使用one-hot形式的,loss是定义在out与y上的torch.nn.CrossEntropyLoss(),而预测值prediction定义为out经过Softmax后(将结果转化为概率值)的结果。
运行结果:
Net (
(hidden): Linear (2 -> 10)
(out):Linear (10 -> 2)
)
四、补充知识
1. super()函数
在定义Net类的构造方法的时候,使用了super(Net,self).__init__()语句,当前的类和对象作为super函数的参数使用,这条语句的功能是使Net类的构造方法获得其超类(父类)的构造方法,不影响对Net类单独定义构造方法,且不必关注Net类的父类到底是什么,若需要修改Net类的父类时只需修改class语句中的内容即可。
2. torch.normal()
torch.normal()可分为三种情况:(1)torch.normal(means,std, out=None)中means和std都是Tensor,两者的形状可以不必相同,但Tensor内的元素数量必须相同,一一对应的元素作为输出的各元素的均值和标准差;(2)torch.normal(mean=0.0, std, out=None)中mean是一个可定义的float,各个元素共享该均值;(3)torch.normal(means,std=1.0, out=None)中std是一个可定义的float,各个元素共享该标准差。
3. torch.cat(seq, dim=0)
torch.cat可以将若干个Tensor组装连接起来,dim指定在哪个维度上进行组装。
4. torch.max()
(1)torch.max(input)→ float
input是tensor,返回input中的最大值float。
(2)torch.max(input,dim, keepdim=True, max=None, max_indices=None) -> (Tensor, LongTensor)
同时返回指定维度=dim上的最大值和该最大值在该维度上的索引值。
相关推荐:
以上是PyTorch上搭建簡單神經網路實作迴歸與分類的範例的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PyCharm與PyTorch完美結合:安裝設定步驟詳解
Feb 21, 2024 pm 12:00 PM
PyCharm與PyTorch完美結合:安裝設定步驟詳解
Feb 21, 2024 pm 12:00 PM
PyCharm是一款強大的整合開發環境(IDE),而PyTorch則是深度學習領域備受歡迎的開源架構。在機器學習和深度學習領域,使用PyCharm和PyTorch進行開發可以大大提高開發效率和程式碼品質。本文將詳細介紹如何在PyCharm中安裝設定PyTorch,並附上具體的程式碼範例,幫助讀者更好地利用這兩者的強大功能。第一步:安裝PyCharm和Python
 YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死! YOLOv9出爐:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度學習方法專注於設計最適合的目標函數,以使模型的預測結果與實際情況最接近。同時,必須設計一個合適的架構,以便為預測取得足夠的資訊。現有方法忽略了一個事實,當輸入資料經過逐層特徵提取和空間變換時,大量資訊將會遺失。本文將深入探討資料透過深度網路傳輸時的重要問題,即資訊瓶頸和可逆函數。基於此提出了可編程梯度資訊(PGI)的概念,以應對深度網路實現多目標所需的各種變化。 PGI可以為目標任務提供完整的輸入訊息,以計算目標函數,從而獲得可靠的梯度資訊以更新網路權重。此外設計了一種新的輕量級網路架
 自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現
Feb 20, 2024 am 08:50 AM
自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現
Feb 20, 2024 am 08:50 AM
在自然語言生成任務中,取樣方法是從生成模型中獲得文字輸出的一種技術。這篇文章將討論5種常用方法,並使用PyTorch進行實作。 1.GreedyDecoding在貪婪解碼中,生成模型根據輸入序列逐個時間步地預測輸出序列的單字。在每個時間步,模型會計算每個單字的條件機率分佈,然後選擇具有最高條件機率的單字作為當前時間步的輸出。這個單字成為下一個時間步的輸入,生成過程會持續直到滿足某種終止條件,例如產生了指定長度的序列或產生了特殊的結束標記。 GreedyDecoding的特點是每次選擇當前條件機率最
 華為手機如何實現雙微信登入?
Mar 24, 2024 am 11:27 AM
華為手機如何實現雙微信登入?
Mar 24, 2024 am 11:27 AM
華為手機如何實現雙微信登入?隨著社群媒體的興起,微信已成為人們日常生活中不可或缺的溝通工具之一。然而,許多人可能會遇到一個問題:在同一部手機上同時登入多個微信帳號。對於華為手機用戶來說,實現雙微信登入並不困難,本文將介紹華為手機如何實現雙微信登入的方法。首先,華為手機自帶的EMUI系統提供了一個很方便的功能-應用程式雙開。透過應用程式雙開功能,用戶可以在手機上同
 安裝PyTorch的PyCharm教學
Feb 24, 2024 am 10:09 AM
安裝PyTorch的PyCharm教學
Feb 24, 2024 am 10:09 AM
PyTorch作為一個功能強大的深度學習框架,被廣泛應用於各類機器學習專案。 PyCharm作為一個強大的Python整合開發環境,在實現深度學習任務時也能提供很好的支援。本文將詳細介紹如何在PyCharm中安裝PyTorch,並提供具體的程式碼範例,幫助讀者快速上手使用PyTorch進行深度學習任務。第一步:安裝PyCharm首先,我們需要確保已經在電腦上
 真快!幾分鐘就把視訊語音辨識為文字了,不到10行程式碼
Feb 27, 2024 pm 01:55 PM
真快!幾分鐘就把視訊語音辨識為文字了,不到10行程式碼
Feb 27, 2024 pm 01:55 PM
大家好,我是風箏兩年前,將音視頻檔轉換為文字內容的需求難以實現,但是如今只需幾分鐘便可輕鬆解決。據說一些公司為了獲取訓練數據,已經對抖音、快手等短視頻平台上的視頻進行了全面爬取,然後將視頻中的音頻提取出來轉換成文本形式,用作大數據模型的訓練語料。如果您需要將視訊或音訊檔案轉換為文字,可以嘗試今天提供的這個開源解決方案。例如,可以搜尋影視節目的對話出現的具體時間點。話不多說,進入正題。 Whisper這個方案就是OpenAI開源的Whisper,當然是用Python寫的了,只需要簡單安裝幾個套件,然
 PHP程式設計指南:實作斐波那契數列的方法
Mar 20, 2024 pm 04:54 PM
PHP程式設計指南:實作斐波那契數列的方法
Mar 20, 2024 pm 04:54 PM
程式語言PHP是一種用於Web開發的強大工具,能夠支援多種不同的程式設計邏輯和演算法。其中,實作斐波那契數列是一個常見且經典的程式設計問題。在這篇文章中,將介紹如何使用PHP程式語言來實作斐波那契數列的方法,並附上具體的程式碼範例。斐波那契數列是一個數學上的序列,其定義如下:數列的第一個和第二個元素為1,從第三個元素開始,每個元素的值等於前兩個元素的和。數列的前幾元
 1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗時!清華最新開源行動裝置神經網路架構 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显著的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
