
這篇文章主要介紹了python socket網路程式設計之黏包問題詳解,現在分享給大家,也給大家做個參考。一起過來看看吧
一,黏包問題詳情
1,只有TCP有黏包現象,UDP永遠不會黏包
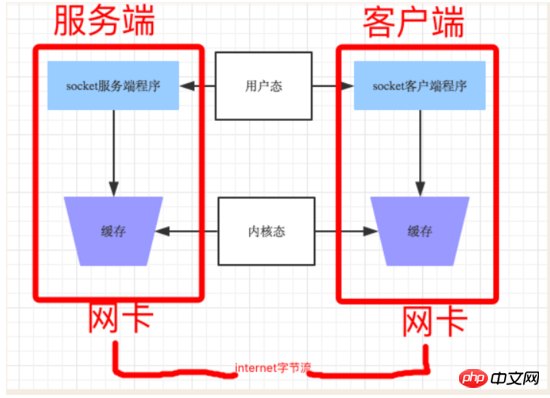
你的程式其實無權直接操作網卡的,你操作網卡都是透過作業系統給使用者程式暴露出來的接口,那每次你的程式要給遠端發送資料時,其實是先把資料從用戶態copy到核心態,這樣的操作是耗資源和時間的,頻繁的在內核態和用戶態之前交換資料勢必會導致發送效率降低, 因此socket 為提高傳輸效率,發送方往往要收集到足夠的資料後才傳送一次資料給對方。若連續幾次需要send的資料都很少,通常TCP socket 會根據最佳化演算法把這些資料合成一個TCP段後一次發送出去,這樣接收方就收到了黏包資料。
2,首先需要掌握一個socket收發訊息的原理
#發送端可以是1k,1k的發送資料而接受端的應用程式可以2k,2k的擷取數據,當然也有可能是3k或多k提取數據,也就是說,應用程式是不可見的,因此TCP協議是面來那個流的協議,這也是容易出現粘包的原因而UDP是面向無連接的協議,每個UDP段都是一條訊息,應用程式必須以訊息為單位提取數據,不能一次提取任一位元組的數據,這一點和TCP是很同的。怎樣定義訊息呢?認為對方一次性write/send的資料為一個訊息,需要命的是當對方send一則訊息的時候,無論鼎城怎麼樣分段分片,TCP協定層會把構成整個訊息的資料段排序完成後才呈現在內核緩衝區。
例如基於TCP的套接字客戶端往伺服器端上傳文件,發送時文件內容是按照一段一段的位元組流發送的,在接收方看來更笨不知道文件的位元組流從何初開始,在何處結束。
3,黏包的原因
3-1 直接原因
所謂黏包問題主要還是因為接收者不知道訊息之間的界限,不知道一次提取多少位元組的資料所造成的
3-2 根本原因
發送方引起的黏包是由TCP協定本身造成的,TCP為提高傳輸效率,發送方往往要收集到足夠的資料後才發送一個TCP段。若連續幾次需要send的資料都很少,通常TCP會根據 優化演算法 把這些資料合成一個TCP段後一次發送出去,這樣接收方就收到了黏包資料。
3-3 總結
TCP(transport control protocol,傳輸控制協定)是面向連接的,面向流的,提供高可靠性服務。收發兩端(客戶端和伺服器端)都要有一一成對的socket,因此,發送端為了將多個發送到接收端的包,更有效的發到對方,使用了優化方法(Nagle演算法),將多次間隔較小且資料量小的數據,合併成一個大的資料區塊,然後進行封包。這樣,接收端,就難於分辨出來了,必須提供科學的拆包機制。即面向流的通訊是無訊息保護邊界的。
UDP(user datagram protocol,用戶資料封包協定)是無連線的,面向訊息的,提供高效率服務。不會使用區塊的合併最佳化演算法,, 由於UDP支援的是一對多的模式,所以接收端的skbuff(套接字緩衝區)採用了鍊式結構來記錄每一個到達的UDP包,在每個UDP套件中就有了訊息頭(消息來源位址,連接埠等資訊),這樣,對於接收端來說,就容易進行區分處理了。 即訊息導向的通訊是有訊息保護邊界的。
tcp是基於資料流的,於是收發的訊息不能為空,這就需要在客戶端和服務端都加入空訊息的處理機制,防止程式卡住,而udp是基於數據報的,即使是你輸入的是空內容(直接回車),那也不是空消息,udp協議會幫你封裝上消息頭,實驗略
udp的recvfrom是阻塞的,一個recvfrom(x)必須對唯一一個sendinto(y),收完了x個位元組的資料就算完成,若是y>x資料就遺失,這意味著udp根本不會黏包,但是會丟數據,不可靠
tcp的協定數據不會丟,沒有收完包,下次接收,會繼續上次繼續接收,己端總是在收到ack時才會清除緩衝區內容。數據是可靠的,但是會黏包。
二,兩種情況下會發生黏包:
#1,發送端需要等到本機的緩衝區滿了以後才發出去,造成黏包(傳送資料時間間隔很短,資料很小,python使用了最佳化演算法,合在一起,產生黏包)
客戶端
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('feng'.encode('utf-8'))
服務端
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
2,接收端不及時接受緩衝區的包,造成多個包接受(客戶端發送一段數據,服務端只收了一小部分,服務端下次再收的時候還是從緩衝區拿上次遺留的數據,就產生黏包) 客戶端
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello feng'.encode('utf-8'))
服務端
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(2) #一次没有收完整 data2=conn.recv(10)#下次收的时候,会先取旧的数据,然后取新的 print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
三,黏包實例:
服務端
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) data2=conn.recv(1024) print(data1) print(data2)
客戶端:
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) din.send('sb'.encode('utf-8'))
四,拆包的發生情況
當發送端緩衝區的長度大於網路卡的MTU時,tcp會將這次發送的資料拆成幾個封包發送過去
補充問題一:為何tcp是可靠傳輸,udp是不可靠傳輸
tcp在資料傳輸時,發送端先把資料傳送到自己的快取中,然後協定控制將快取中的資料傳送到對端,對端傳回一個ack=1,發送端則清理快取中的數據,對端回傳ack=0,則重新傳送數據,所以tcp是可靠的
而udp發送數據,對端是不會回傳確認訊息的,因此不可靠
補充問題二:send(位元組流)和recv(1024)及sendall是什麼意思?
recv裡指定的1024意思是從快取裡一次拿出1024個位元組的資料
send的位元組流是先放入己端緩存,然後由協定控制將緩存內容發送到對端,如果位元組流大小大於快取剩餘空間,那麼資料遺失,用sendall就會循環呼叫send,資料不會遺失。
五,黏包問題如何解決?
問題的根源在於,接收端不知道發送端將要傳送的位元組流的長度,所以解決黏包的方法就是圍繞,如何讓發送端在發送資料前,把自己將要傳送的位元組流總大小讓接收端知曉,然後接收端來一個死循環接收完所有資料。
5-1 簡單的解決方法(從表面解決):
在客戶端發送下邊添加一個時間睡眠,就可以避免黏包現象。在服務端接收的時候也要進行時間睡眠,才能有效的避免黏包狀況。
客戶端:
#客户端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) time.sleep(3) din.send('sb'.encode('utf-8'))
服務端:
#服务端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) time.sleep(4) data2=conn.recv(1024) print(data1) print(data2)
上面解決方法肯定會出現很多紕漏,因為你不知道什麼時候傳輸完,時間暫停的長短都會有問題,長的話效率低,短的話不合適,所以這種方法是不合適的。
5-2 普通的解決方法(從根本看問題):
問題的根源在於,接收端不知道發送端將要傳送的位元組流的長度,所以解決黏包的方法就是圍繞,如何讓發送端在發送資料前,把自己將要發送的位元組流總大小讓接收端知曉,然後接收端來一個死循環接收完所有資料
為位元組流加上自訂固定長度標頭,標頭中包含字節流長度,然後依次send到對端,對端在接受時,先從緩存中取出定長的報頭,然後再取真是數據。
使用struct模組對打包的長度為固定4個位元組或八個位元組,struct.pack.format參數是「i」時,只能打包長度為10的數字,那麼還可以先將長度轉換為json字串,再打包。
普通的客戶端
# _*_ coding: utf-8 _*_ import socket import struct phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8880)) #连接服 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头 header_struct = phone.recv(4) #收四个 unpack_res = struct.unpack('i',header_struct) total_size = unpack_res[0] #总长度 #后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) # total_data+=recv_data # print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
普通的服務端
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.bind(('127.0.0.1',8880)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
#先发报头(转成固定长度的bytes类型,那么怎么转呢?就用到了struct模块)
#len(stdout) + len(stderr)#统计数据的长度
header = struct.pack('i',len(stdout)+len(stderr))#制作报头
coon.send(header)
#再发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()5-3 最佳化版的解決方法(從根本解決問題)
優化的解決黏包問題的想法就是服務端將報頭資訊進行最佳化,對要傳送的內容用字典進行描述,首先字典不能直接進行網路傳輸,需要進行序列化轉成json格式化字串,然後轉成bytes格式服務端進行傳送,因為bytes格式的json字串長度不是固定的,所以要用struct模組將bytes格式的json字串長度壓縮成固定長度,發送給客戶端,客戶端進行接受,反解就會得到完整的資料包。
終極版的客戶端
# _*_ coding: utf-8 _*_ import socket import struct import json phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) #连接服务器 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头的长度 header_len = struct.unpack('i',phone.recv(4))[0] #吧bytes类型的反解 #在收报头 header_bytes = phone.recv(header_len) #收过来的也是bytes类型 header_json = header_bytes.decode('utf-8') #拿到json格式的字典 header_dic = json.loads(header_json) #反序列化拿到字典了 total_size = header_dic['total_size'] #就拿到数据的总长度了 #最后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) #有可能接收的不是1024个字节,或许比1024多呢, # 那么接收的时候就接收不全,所以还要加上接收的那个长度 total_data+=recv_data #最终的结果 print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
終極版的服務端
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8080)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
# 制作报头
header_dic = {
'total_size': len(stdout)+len(stderr), # 总共的大小
'filename': None,
'md5': None
}
header_json = json.dumps(header_dic) #字符串类型
header_bytes = header_json.encode('utf-8') #转成bytes类型(但是长度是可变的)
#先发报头的长度
coon.send(struct.pack('i',len(header_bytes))) #发送固定长度的报头
#再发报头
coon.send(header_bytes)
#最后发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()六,struct模組
了解c语言的人,一定会知道struct结构体在c语言中的作用,它定义了一种结构,里面包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理。而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,不必担心太多的问题,而当传递诸如int、char之类的基本数据的时候,就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化(This module performs conversions between Python values and C structs represented as Python strings.)。stuct模块提供了很简单的几个函数,下面写几个例子。
1,基本的pack和unpack
struct提供用format specifier方式对数据进行打包和解包(Packing and Unpacking)。例如:
#该模块可以把一个类型,如数字,转成固定长度的bytes类型 import struct # res = struct.pack('i',12345) # print(res,len(res),type(res)) #长度是4 res2 = struct.pack('i',12345111) print(res2,len(res2),type(res2)) #长度也是4 unpack_res =struct.unpack('i',res2) print(unpack_res) #(12345111,) # print(unpack_res[0]) #12345111
代码中,首先定义了一个元组数据,包含int、string、float三种数据类型,然后定义了struct对象,并制定了format‘I3sf',I 表示int,3s表示三个字符长度的字符串,f 表示 float。最后通过struct的pack和unpack进行打包和解包。通过输出结果可以发现,value被pack之后,转化为了一段二进制字节串,而unpack可以把该字节串再转换回一个元组,但是值得注意的是对于float的精度发生了改变,这是由一些比如操作系统等客观因素所决定的。打包之后的数据所占用的字节数与C语言中的struct十分相似。
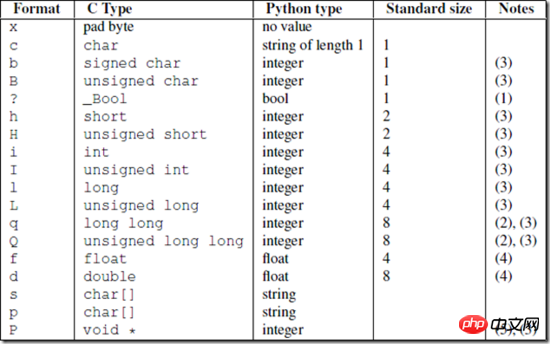
2,定义format可以参照官方api提供的对照表:
3,基本用法
import json,struct
#假设通过客户端上传1T:1073741824000的文件a.txt
#为避免粘包,必须自定制报头
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值
#为了该报头能传送,需要序列化并且转为bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输
#为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度
#客户端开始发送
conn.send(head_len_bytes) #先发报头的长度,4个bytes
conn.send(head_bytes) #再发报头的字节格式
conn.sendall(文件内容) #然后发真实内容的字节格式
#服务端开始接收
head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式
x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度
head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式
header=json.loads(json.dumps(header)) #提取报头
#最后根据报头的内容提取真实的数据,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)以上是python socket網路程式設計黏包問題詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















