

用python處理MS Word的實例

這篇文章主要介紹了關於用python處理MS Word的實例,有著一定的參考價值,現在分享給大家,有需要的朋友可以參考一下
使用python工具讀寫MS Word文件(docx與doc檔案),主要利用了python-docx套件。本文給一些常用的操作,並完成一個範例,幫助大家快速著手。
安裝
pyhton處理docx檔案需要使用python-docx 包,可以利用pip工具很方便的安裝,pip工具在python安裝路徑下的Scripts資料夾中
pip install python-docx
當然你也可以選擇使用easy_install或手動方式進行安裝
寫入檔案內容
這裡我們直接給出一個範例,根據自己的需求摘取有用的內容
#coding=utf-8 from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn #打开文档 document = Document() #加入不同等级的标题 document.add_heading(u'MS WORD写入测试',0) document.add_heading(u'一级标题',1) document.add_heading(u'二级标题',2) #添加文本 paragraph = document.add_paragraph(u'我们在做文本测试!') #设置字号 run = paragraph.add_run(u'设置字号、') run.font.size = Pt(24) #设置字体 run = paragraph.add_run('Set Font,') run.font.name = 'Consolas' #设置中文字体 run = paragraph.add_run(u'设置中文字体、') run.font.name=u'宋体' r = run._element r.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') #设置斜体 run = paragraph.add_run(u'斜体、') run.italic = True #设置粗体 run = paragraph.add_run(u'粗体').bold = True #增加引用 document.add_paragraph('Intense quote', style='Intense Quote') #增加无序列表 document.add_paragraph( u'无序列表元素1', style='List Bullet' ) document.add_paragraph( u'无序列表元素2', style='List Bullet' ) #增加有序列表 document.add_paragraph( u'有序列表元素1', style='List Number' ) document.add_paragraph( u'有序列表元素2', style='List Number' ) #增加图像(此处用到图像image.bmp,请自行添加脚本所在目录中) document.add_picture('image.bmp', width=Inches(1.25)) #增加表格 table = document.add_table(rows=1, cols=3) hdr_cells = table.rows[0].cells hdr_cells[0].text = 'Name' hdr_cells[1].text = 'Id' hdr_cells[2].text = 'Desc' #再增加3行表格元素 for i in xrange(3): row_cells = table.add_row().cells row_cells[0].text = 'test'+str(i) row_cells[1].text = str(i) row_cells[2].text = 'desc'+str(i) #增加分页 document.add_page_break() #保存文件 document.save(u'测试.docx')
該段程式碼產生的文件樣式如下

# 註:有一個問題沒找到如何解決,也就是如何設定邊框線。如果您知道,也請能夠指教。
讀取檔案內容
##coding=utf-8 from docx import Document #打开文档 document = Document(u'测试.docx') #读取每段资料 l = [ paragraph.text.encode('gb2312') for paragraph in document.paragraphs]; #输出并观察结果,也可以通过其他手段处理文本即可 for i in l: print i #读取表格材料,并输出结果 tables = [table for table in document.tables]; for table in tables: for row in table.rows: for cell in row.cells: print cell.text.encode('gb2312'),'\t', print print '\n'
我們仍然使用剛才我們產生的文件,可以看到,輸出的結果為
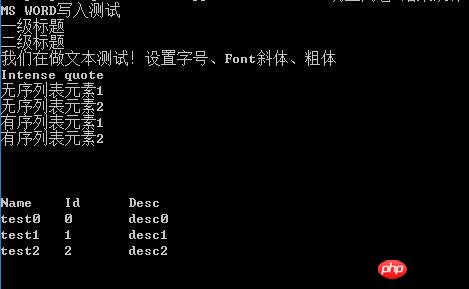
注意:這裡我們使用gb2312編碼方式讀取,主要是保證中文的讀寫正確。一般情況下,使用的utf-8編碼方式。另外,python-docx主要處理docx文件,在載入doc文件時,會出現問題,如果有大量doc文件,建議先將doc文件批量轉換為docx文件,例如利用工具doc2doc
相關推薦:
以上是用python處理MS Word的實例的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
notepad 怎麼運行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中運行 Python 代碼需要安裝 Python 可執行文件和 NppExec 插件。安裝 Python 並為其添加 PATH 後,在 NppExec 插件中配置命令為“python”、參數為“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通過快捷鍵“F6”運行 Python 代碼。
 vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
vscode 擴展是否是惡意的
Apr 15, 2025 pm 07:57 PM
VS Code 擴展存在惡意風險,例如隱藏惡意代碼、利用漏洞、偽裝成合法擴展。識別惡意擴展的方法包括:檢查發布者、閱讀評論、檢查代碼、謹慎安裝。安全措施還包括:安全意識、良好習慣、定期更新和殺毒軟件。
