

透過網頁爬蟲中cookie自動取得及過期自動更新(詳細教學)
這篇文章主要介紹了網頁爬蟲之cookie自動獲取及過期自動更新的實現方法,需要的朋友可以參考下
本文實現cookie的自動獲取,及cookie過期自動更新。
社群網站中的許多資訊都需要登入才能取得到,以微博為例,不登入帳號,只能看到大V的前十條微博。保持登入狀態,必須使用到Cookie。以登入www.weibo.cn 為例:
在chrome中輸入:http://login.weibo.cn/login/
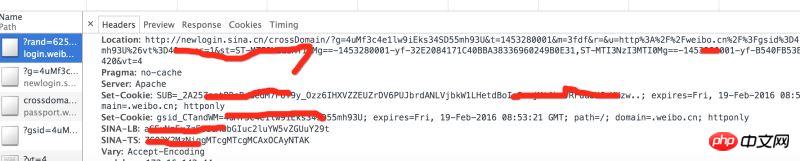
實作步驟:
1,採用selenium自動登入取得cookie,儲存到檔案;2,讀取cookie,比較cookie的有效期,若過期則再次執行步驟1;3,在請求其他網頁時,填入cookie,實現登入狀態的維持。 1,線上取得cookie採用selenium PhantomJS 模擬瀏覽器登錄,取得cookie;cookies一般會有多個,逐一將cookie存入以.weibo後綴的文件。def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dictdef get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dictdef get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...vue2.0 computed 計算list循環後累加值的實例#
以上是透過網頁爬蟲中cookie自動取得及過期自動更新(詳細教學)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 cookie存在哪裡
Dec 20, 2023 pm 03:07 PM
cookie存在哪裡
Dec 20, 2023 pm 03:07 PM
Cookie通常儲存在瀏覽器的Cookie資料夾中的,瀏覽器中的Cookie檔案通常以二進位或SQLite格式存儲,如果直接開啟Cookie文件,可能會看到一些亂碼或無法讀取的內容,因此最好使用瀏覽器提供的Cookie管理介面來檢視和管理Cookie。
 電腦上的cookie在哪裡
Dec 22, 2023 pm 03:46 PM
電腦上的cookie在哪裡
Dec 22, 2023 pm 03:46 PM
電腦上的Cookie儲存在瀏覽器的特定位置,具體位置取決於使用的瀏覽器和作業系統:1、Google Chrome, 儲存在C:\Users\YourUsername\AppData\Local\Google\Chrome\User Data\Default \Cookies中等等。
 Linux小技巧:取消vim貼上時的自動縮排
Mar 07, 2024 am 08:30 AM
Linux小技巧:取消vim貼上時的自動縮排
Mar 07, 2024 am 08:30 AM
前言vim是個強大的文字編輯的工具,在Linux端得到極大的使用熱度。最近在另外一台伺服器上使用vim時,遇到了一個奇怪的問題:當我將本地編寫好的腳本複製並貼上到伺服器中的空白檔案時,出現了自動縮排的情況。用個簡單的例子來說,就是我在本地寫的腳本如下:aaabbbcccddd當我將上述內容複製後,粘貼到伺服器中的空白文件後得到的卻是:aabbbcccddd很明顯,這是vim給我們自動進行了格式縮排。但是,這個自動有點不聰明。這裡記錄下解決方案。解決方案:設定.vimrc設定檔我們在家目錄下,新
 手機cookie在哪裡
Dec 22, 2023 pm 03:40 PM
手機cookie在哪裡
Dec 22, 2023 pm 03:40 PM
手機上的Cookie儲存在行動裝置的瀏覽器應用程式中:1、在iOS裝置上,Cookie儲存在Safari瀏覽器的Settings -> Safari -> Advanced -> Website Data中;2、在Android裝置上,Cookie儲存在Chrome瀏覽器的Settings -> Site settings -> Cookies中等等。
 Cookie工作原理是什麼
Sep 20, 2023 pm 05:57 PM
Cookie工作原理是什麼
Sep 20, 2023 pm 05:57 PM
Cookie運作方式涉及到伺服器發送Cookie、瀏覽器儲存Cookie以及瀏覽器對Cookie的處理和儲存。詳細介紹:1、伺服器發送Cookie,伺服器會傳送一個包含Cookie的HTTP回應標頭給瀏覽器。這個Cookie包含了一些訊息,例如使用者的身份認證、偏好設定或購物車內容等,瀏覽器接收到這個Cookie後,會將它儲存在使用者的電腦上;2、瀏覽器儲存Cookie等等。
 在Linux上自動裝載驅動器
Mar 20, 2024 am 11:30 AM
在Linux上自動裝載驅動器
Mar 20, 2024 am 11:30 AM
如果您使用Linux作業系統,並希望系統在啟動時自動載入驅動器,可以透過將裝置的唯一識別碼(UID)和掛載點路徑新增至fstab設定檔來實現。 fstab是位於/etc目錄中的檔案系統表文件,它包含了系統在啟動時需要掛載的檔案系統的資訊。透過編輯fstab文件,您可以確保在每次系統啟動時都能正確載入所需的驅動器,從而確保系統的穩定運作。自動安裝驅動器可方便地應用於多種情境。例如,我計劃將系統備份到外部儲存設備。為了實現自動化,需確保設備與系統保持連接,甚至在啟動時。同樣,很多應用程式會直接
 清除cookie有什麼影響嗎
Sep 20, 2023 pm 06:01 PM
清除cookie有什麼影響嗎
Sep 20, 2023 pm 06:01 PM
清除cookie產生的影響有重置個人化設定和偏好、影響廣告體驗、破壞登入狀態和記住密碼功能。詳細介紹:1、重置個人化設定和偏好,如果清除了cookie,購物車將被重置為空,需要重新添加商品,同樣清除cookie還會導致在社群媒體平台上的登入狀態遺失,需要重新輸入使用者名稱和密碼;2、影響廣告體驗,如果清除了cookie,網站將無法了解我們的興趣和偏好,會顯示無關的廣告等等。
 瀏覽器cookie的儲存位置詳解
Jan 19, 2024 am 09:15 AM
瀏覽器cookie的儲存位置詳解
Jan 19, 2024 am 09:15 AM
隨著網路的普及,我們使用瀏覽器進行上網已經成為一種生活方式。在日常使用瀏覽器過程中,我們常會遇到需要輸入帳號密碼的情況,如網購、社交、郵件等。這些資訊需要瀏覽器記錄下來,以便下次造訪時不需要再次輸入,這時候Cookie就派上了用場。什麼是Cookie? Cookie是指由伺服器端發送到使用者瀏覽器上並儲存在本地的一種小型資料文件,它包含了一些網站的使用者行為
