

Python模擬登入的多種方法

這篇文章主要介紹了Python模擬登入的多種方法,大概給大家提供了四種方法,每種方法給大家介紹的都很詳細,有興趣的朋友一起看看吧
正文
方法一:直接使用已知的cookie存取
特點:
簡單,但需要先在瀏覽器登入
原理:
簡單地說,cookie保存在發起請求的客戶端中,伺服器利用cookie來區分不同的客戶端。因為http是一種無狀態的連接,當伺服器一下子收到好幾個請求時,是無法判斷哪些請求是同一個客戶端發起的。而「造訪登入後才能看到的頁面」這一行為,恰恰需要客戶端向伺服器證明:「我是剛才登入的那個客戶端」。於是就需要cookie來標識客戶端的身份,以儲存它的資訊(如登入狀態)。
當然,這也意味著,只要得到了別的客戶端的cookie,我們就可以假冒成它來和伺服器對話。這為我們的程式帶來了可乘之機。
我們先用瀏覽器登入,然後再使用開發者工具查看cookie。接著在程式中攜帶該cookie向網站發送請求,就能讓你的程式假扮成剛才登入的那個瀏覽器,得到只有登入後才能看到的頁面。
具體步驟:
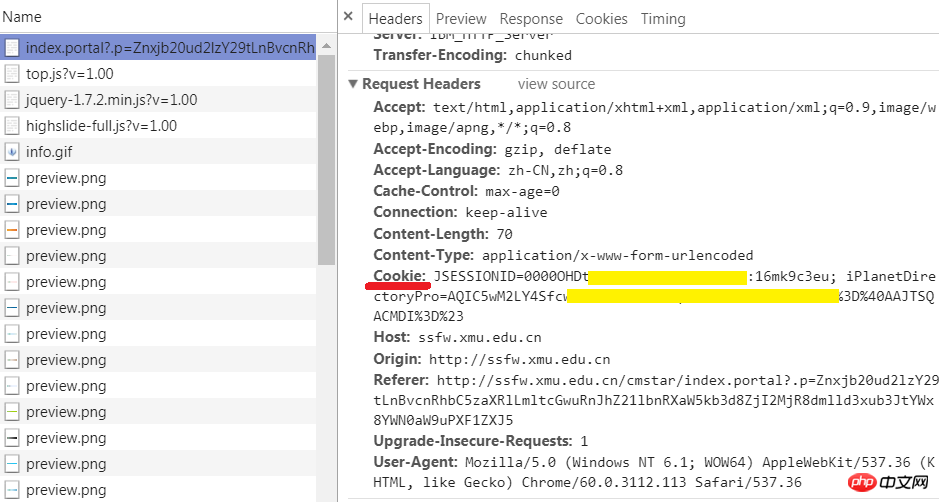
1.用瀏覽器登錄,取得瀏覽器裡的cookie字串
先使用瀏覽器登入。再開啟開發者工具,轉到network選項卡。在左邊的Name一欄找到目前的網址,選擇右邊的Headers選項卡,查看Request Headers,這裡包含了該網站頒發給瀏覽器的cookie。對,就是後面的字串。把它複製下來,一會兒程式碼裡要用到。
注意,最好是在執行你的程式前再登入。如果太早登錄,或是把瀏覽器關了,很可能複製的那個cookie就過期無效了。
2.寫程式碼
urllib函式庫的版本:
import sys import io from urllib import request sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码 #登录后才能访问的网站 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' #浏览器登录后得到的cookie,也就是刚才复制的字符串 cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx' #登录后才能访问的网页 url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal' req = request.Request(url) #设置cookie req.add_header('cookie', raw_cookies) #设置请求头 req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36') resp = request.urlopen(req) print(resp.read().decode('utf-8'))
# requests庫的版本:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value#方法二:模擬登入後再攜帶得到的cookie存取
原則:
我們先在程式中向網站發出登入要求,也就是提交包含登入資訊的表單(使用者名稱、密碼等)。從回應中得到cookie,今後在造訪其他頁面時也帶上這個cookie,就能得到只有登入後才能看到的頁面。
具體步驟:
1.找出表單提交到的頁面
還是要利用瀏覽器的開發者工具。前往network選項卡,並勾選Preserve Log(重要!)。在瀏覽器裡登入網站。然後在左邊的Name一欄找到表單提交到的頁面。怎麼找呢?看看右側,轉到Headers選項卡。首先,在General那段,Request Method應當是POST。其次最下方應該要有一段叫做Form Data的,裡面可以看到你剛才輸入的使用者名稱和密碼等。也可以看看左邊的Name,如果含有login這個詞,有可能就是提交表單的頁面(不一定!)。

這裡要強調一點,「表單提交到的頁面」通常不是你填寫使用者名稱和密碼的頁面!所以要利用工具來找到它。
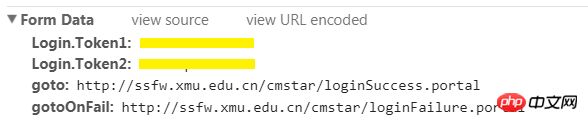
2.找出要提交的資料
雖然你在瀏覽器裡登陸時只填了使用者名稱和密碼,但表單裡包含的資料可不只這些。從Form Data就可以看到需要提交的所有資料。
3.寫程式碼
urllib函式庫的版本:
import sys
import io
import urllib.request
import http.cookiejar
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
post_data = urllib.parse.urlencode(data).encode('utf-8')
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = ' http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal
#构造登录请求
req = urllib.request.Request(login_url, headers = headers, data = post_data)
#构造cookie
cookie = http.cookiejar.CookieJar()
#由cookie构造opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
#发送登录请求,此后这个opener就携带了cookie,以证明自己登录过
resp = opener.open(req)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#构造访问请求
req = urllib.request.Request(url, headers = headers)
resp = opener.open(req)
print(resp.read().decode('utf-8'))# requests函式庫的版本:
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#浏览器登录后得到的cookie,也就是刚才复制的字符串
cookie_str = r'JSESSIONID=xxxxxxxxxxxxxxxxxxxxxx; iPlanetDirectoryPro=xxxxxxxxxxxxxxxxxx'
#把cookie字符串处理成字典,以便接下来使用
cookies = {}
for line in cookie_str.split(';'):
key, value = line.split('=', 1)
cookies[key] = value
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#在发送get请求时带上请求头和cookies
resp = requests.get(url, headers = headers, cookies = cookies)
print(resp.content.decode('utf-8'))明顯感覺requests函式庫用著更方便啊~~~
方法三:模擬登入後用session保持登入狀態
原理:
session是會話的意思。和cookie的相似之處在於,它也可以讓伺服器「認得」客戶端。簡單理解就是,把每個客戶端和伺服器的互動當作一個「會話」。既然在同一個「會話」裡,伺服器自然就能知道這個客戶端是否登入過。
具體步驟:
1.找出表單提交到的頁面
2.找出要提交的資料
这两步和方法二的前两步是一样的
3.写代码
requests库的版本
import requests
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8') #改变标准输出的默认编码
#登录时需要POST的数据
data = {'Login.Token1':'学号',
'Login.Token2':'密码',
'goto:http':'//ssfw.xmu.edu.cn/cmstar/loginSuccess.portal',
'gotoOnFail:http':'//ssfw.xmu.edu.cn/cmstar/loginFailure.portal'}
#设置请求头
headers = {'User-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'}
#登录时表单提交到的地址(用开发者工具可以看到)
login_url = 'http://ssfw.xmu.edu.cn/cmstar/userPasswordValidate.portal'
#构造Session
session = requests.Session()
#在session中发送登录请求,此后这个session里就存储了cookie
#可以用print(session.cookies.get_dict())查看
resp = session.post(login_url, data)
#登录后才能访问的网页
url = 'http://ssfw.xmu.edu.cn/cmstar/index.portal'
#发送访问请求
resp = session.get(url)
print(resp.content.decode('utf-8'))方法四:使用无头浏览器访问
特点:
功能强大,几乎可以对付任何网页,但会导致代码效率低
原理:
如果能在程序里调用一个浏览器来访问网站,那么像登录这样的操作就轻而易举了。在Python中可以使用Selenium库来调用浏览器,写在代码里的操作(打开网页、点击……)会变成浏览器忠实地执行。这个被控制的浏览器可以是Firefox,Chrome等,但最常用的还是PhantomJS这个无头(没有界面)浏览器。也就是说,只要把填写用户名密码、点击“登录”按钮、打开另一个网页等操作写到程序中,PhamtomJS就能确确实实地让你登录上去,并把响应返回给你。
具体步骤:
1.安装selenium库、PhantomJS浏览器
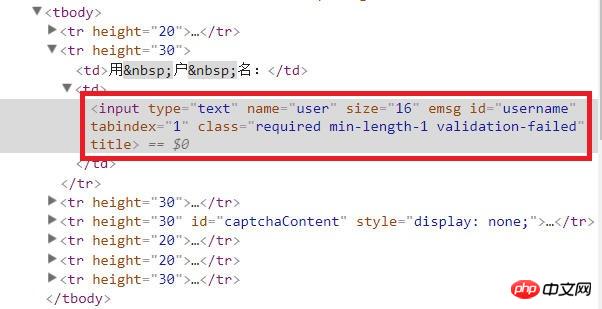
2.在源代码中找到登录时的输入文本框、按钮这些元素
因为要在无头浏览器中进行操作,所以就要先找到输入框,才能输入信息。找到登录按钮,才能点击它。
在浏览器中打开填写用户名密码的页面,将光标移动到输入用户名的文本框,右键,选择“审查元素”,就可以在右边的网页源代码中看到文本框是哪个元素。同理,可以在源代码中找到输入密码的文本框、登录按钮。
3.考虑如何在程序中找到上述元素
Selenium库提供了find_element(s)_by_xxx的方法来找到网页中的输入框、按钮等元素。其中xxx可以是id、name、tag_name(标签名)、class_name(class),也可以是xpath(xpath表达式)等等。当然还是要具体分析网页源代码。
4.写代码
import requests import sys import io from selenium import webdriver sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf8') #改变标准输出的默认编码 #建立Phantomjs浏览器对象,括号里是phantomjs.exe在你的电脑上的路径 browser = webdriver.PhantomJS('d:/tool/07-net/phantomjs-windows/phantomjs-2.1.1-windows/bin/phantomjs.exe') #登录页面 url = r'http://ssfw.xmu.edu.cn/cmstar/index.portal' # 访问登录页面 browser.get(url) # 等待一定时间,让js脚本加载完毕 browser.implicitly_wait(3) #输入用户名 username = browser.find_element_by_name('user') username.send_keys('学号') #输入密码 password = browser.find_element_by_name('pwd') password.send_keys('密码') #选择“学生”单选按钮 student = browser.find_element_by_xpath('//input[@value="student"]') student.click() #点击“登录”按钮 login_button = browser.find_element_by_name('btn') login_button.submit() #网页截图 browser.save_screenshot('picture1.png') #打印网页源代码 print(browser.page_source.encode('utf-8').decode()) browser.quit()
相关推荐:
以上是Python模擬登入的多種方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
mysql 是否要付費
Apr 08, 2025 pm 05:36 PM
MySQL 有免費的社區版和收費的企業版。社區版可免費使用和修改,但支持有限,適合穩定性要求不高、技術能力強的應用。企業版提供全面商業支持,適合需要穩定可靠、高性能數據庫且願意為支持買單的應用。選擇版本時考慮的因素包括應用關鍵性、預算和技術技能。沒有完美的選項,只有最合適的方案,需根據具體情況謹慎選擇。
 mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
文章介紹了MySQL數據庫的上手操作。首先,需安裝MySQL客戶端,如MySQLWorkbench或命令行客戶端。 1.使用mysql-uroot-p命令連接服務器,並使用root賬戶密碼登錄;2.使用CREATEDATABASE創建數據庫,USE選擇數據庫;3.使用CREATETABLE創建表,定義字段及數據類型;4.使用INSERTINTO插入數據,SELECT查詢數據,UPDATE更新數據,DELETE刪除數據。熟練掌握這些步驟,並學習處理常見問題和優化數據庫性能,才能高效使用MySQL。
 mysql 需要互聯網嗎
Apr 08, 2025 pm 02:18 PM
mysql 需要互聯網嗎
Apr 08, 2025 pm 02:18 PM
MySQL 可在無需網絡連接的情況下運行,進行基本的數據存儲和管理。但是,對於與其他系統交互、遠程訪問或使用高級功能(如復制和集群)的情況,則需要網絡連接。此外,安全措施(如防火牆)、性能優化(選擇合適的網絡連接)和數據備份對於連接到互聯網的 MySQL 數據庫至關重要。
 如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何針對高負載應用程序優化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL數據庫性能優化指南在資源密集型應用中,MySQL數據庫扮演著至關重要的角色,負責管理海量事務。然而,隨著應用規模的擴大,數據庫性能瓶頸往往成為製約因素。本文將探討一系列行之有效的MySQL性能優化策略,確保您的應用在高負載下依然保持高效響應。我們將結合實際案例,深入講解索引、查詢優化、數據庫設計以及緩存等關鍵技術。 1.數據庫架構設計優化合理的數據庫架構是MySQL性能優化的基石。以下是一些核心原則:選擇合適的數據類型選擇最小的、符合需求的數據類型,既能節省存儲空間,又能提升數據處理速度
 HadiDB:Python 中的輕量級、可水平擴展的數據庫
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的輕量級、可水平擴展的數據庫
Apr 08, 2025 pm 06:12 PM
HadiDB:輕量級、高水平可擴展的Python數據庫HadiDB(hadidb)是一個用Python編寫的輕量級數據庫,具備高度水平的可擴展性。安裝HadiDB使用pip安裝:pipinstallhadidb用戶管理創建用戶:createuser()方法創建一個新用戶。 authentication()方法驗證用戶身份。 fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
直接通過 Navicat 查看 MongoDB 密碼是不可能的,因為它以哈希值形式存儲。取回丟失密碼的方法:1. 重置密碼;2. 檢查配置文件(可能包含哈希值);3. 檢查代碼(可能硬編碼密碼)。
 mysql workbench 可以連接到 mariadb 嗎
Apr 08, 2025 pm 02:33 PM
mysql workbench 可以連接到 mariadb 嗎
Apr 08, 2025 pm 02:33 PM
MySQL Workbench 可以連接 MariaDB,前提是配置正確。首先選擇 "MariaDB" 作為連接器類型。在連接配置中,正確設置 HOST、PORT、USER、PASSWORD 和 DATABASE。測試連接時,檢查 MariaDB 服務是否啟動,用戶名和密碼是否正確,端口號是否正確,防火牆是否允許連接,以及數據庫是否存在。高級用法中,使用連接池技術優化性能。常見錯誤包括權限不足、網絡連接問題等,調試錯誤時仔細分析錯誤信息和使用調試工具。優化網絡配置可以提升性能
 mysql 需要服務器嗎
Apr 08, 2025 pm 02:12 PM
mysql 需要服務器嗎
Apr 08, 2025 pm 02:12 PM
對於生產環境,通常需要一台服務器來運行 MySQL,原因包括性能、可靠性、安全性和可擴展性。服務器通常擁有更強大的硬件、冗餘配置和更嚴格的安全措施。對於小型、低負載應用,可在本地機器運行 MySQL,但需謹慎考慮資源消耗、安全風險和維護成本。如需更高的可靠性和安全性,應將 MySQL 部署到雲服務器或其他服務器上。選擇合適的服務器配置需要根據應用負載和數據量進行評估。
