
這篇文章主要介紹了關於Redis面試題及分散式集群,有著一定的參考價值,現在分享給大家,有需要的朋友可以參考一下

(1) 速度快,因為資料存在記憶體中,類似HashMap,HashMap的優點就是尋找和操作的時間複雜度都是O(1)
(2) 支援豐富資料型,支援string,list,set,sorted set,hash
(3) 支援事務,操作都是原子性,所謂的原子性就是對資料的變更要麼全部執行,要麼全部不執行
(4) 豐富的功能:可用於緩存,訊息,按key設定過期時間,過期後將會自動刪除
專題推薦:2020年redis面試題大全(最新)
(1) memcached所有的值都是簡單的字串,redis作為其替代者,支援更豐富的資料型別
(2) redis的速度比memcached快很多
( 3) redis可以持久化其資料
(1) Master最好不要做任何持久化工作,如RDB記憶體快照和AOF日誌文件
(2) 如果數據比較重要,某個Slave開啟AOF備份數據,策略設定為每秒同步一次
(3) 為了主從複製的速度和連接的穩定性,Master和Slave最好在同一個區域網路內
(4) 盡量避免在壓力很大的主庫上增加從庫
(5) 主從複製不要用圖狀結構,用單向鍊錶結構更為穩定,即: Master 這樣的結構方便解決單點故障問題,實現Slave對Master的替換。如果Master掛了,可以立刻啟用Slave1做Master,其他不變。
相關知識:redis 內存數據集大小上升到一定大小的時候,就會施行數據淘汰策略。 redis 提供6種資料淘汰策略:
voltile-lru:從已設定過期時間的資料集(server.db[i].expires)中挑選最近最少使用的資料淘汰
# volatile-ttl:從已設定過期時間的資料集(server.db[i].expires)中挑選將要過期的資料淘汰
volatile-random:從已設定過期時間的資料集(server.db[i].expires)中任意選擇資料淘汰
allkeys-lru:從資料集(server.db[i] .dict)中挑選最近最少使用的資料淘汰
allkeys-random:從資料集(server.db[i].dict)中任意選擇資料淘汰
no-enviction(驅逐):禁止驅逐資料
1)、儲存方式
Memecache把資料全部存在記憶體之中,斷電後會掛掉,資料不能超過記憶體大小。
Redis有部份存在硬碟上,這樣能確保資料的持久性。
2)、資料支援類型
Memcache對資料型別支援相對簡單。
Redis有複雜的資料型態。
3)、使用底層模型不同
它們之間底層實作方式 以及與客戶端之間通訊的應用協定不一樣。
Redis直接自己建構了VM 機制 ,因為一般的系統呼叫系統函數的話,會浪費一定的時間去移動和請求。
4),value大小
redis最大可以達到1GB,而memcache只有1MB
1).Master寫記憶體快照,save指令調度rdbSave函數,會阻塞主執行緒的工作,當快照比較大時對效能影響是非常大的,會間斷性暫停服務,所以Master最好不要寫記憶體快照。
2).Master AOF持久化,如果不重寫AOF文件,這個持久化方式對性能的影響是最小的,但是AOF文件會不斷增大,AOF文件過大會影響Master重啟的恢復速度。 Master最好不要做任何持久化工作,包括內存快照和AOF日誌文件,特別是不要啟用內存快照做持久化,如果數據比較關鍵,某個Slave開啟AOF備份數據,策略為每秒同步一次。
3).Master呼叫BGREWRITEAOF重寫AOF文件,AOF在重寫的時候會佔大量的CPU和記憶體資源,導致服務load過高,出現短暫服務暫停現象。
4). Redis主從複製的效能問題,為了主從複製的速度和連接的穩定性,Slave和Master最好在同一個區域網路內
Redis最適合所有資料in-momory的場景,雖然Redis也提供持久化功能,但實際上更多的是一個disk-backed的功能,跟傳統意義上的持久化有比較大的差別,那麼可能大家就會有疑問,似乎Redis更像一個加強版的Memcached,那麼何時使用Memcached,何時使用Redis呢?
如果簡單地比較Redis與Memcached的區別,大多數都會得到以下觀點:
1 、Redis不僅支援簡單的k/v類型的數據,同時也提供list,set,zset,hash等資料結構的儲存。
2 、Redis支援資料的備份,即master-slave模式的資料備份。
3 、Redis支援資料的持久化,可以將記憶體中的資料保持在磁碟中,重新啟動的時候可以再次載入進行使用。
(1)、會話快取(Session Cache)
最常用的一種使用Redis的情境是會話快取(session cache)。用Redis快取會話比其他儲存(如Memcached)的優點在於:Redis提供持久化。當維護一個不是嚴格要求一致性的快取時,如果用戶的購物車資訊全部遺失,大部分人都會不高興的,現在,他們還會這樣嗎?
幸運的是,隨著 Redis 這些年的改進,很容易找到怎麼恰當的使用Redis來快取會話的文檔。甚至廣為人知的商業平台Magento也提供Redis的插件。
(2)、全頁快取(FPC)
除基本的會話token之外,Redis也提供很簡單的FPC平台。回到一致性問題,即使重啟了Redis實例,因為有磁碟的持久化,使用者也不會看到頁面載入速度的下降,這是一個極大改進,類似PHP本地FPC。
再次以Magento為例,Magento提供一個外掛程式來使用Redis作為全頁快取後端。
此外,對WordPress的用戶來說,Pantheon有一個非常好的插件 wp-redis,這個外掛程式能幫助你以最快速度載入你曾經瀏覽過的頁面。
(3)、佇列
Reids在記憶體儲存引擎領域的一大優點是提供 list 和 set 操作,這使得Redis能作為一個很好的訊息佇列平台來使用。 Redis作為佇列使用的操作,就類似於本機程式語言(如Python)對 list 的 push/pop 操作。
如果你快速的在Google中搜尋“Redis queues”,你馬上就能找到大量的開源項目,這些項目的目的就是利用Redis創建非常好的後端工具,以滿足各種隊列需求。例如,Celery有一個後台就是使用Redis當broker,你可以從這裡去查看。
(4),排行榜/計數器
Redis在記憶體中對數字進行遞增或遞減的操作實現的非常好。集合(Set)和有序集合(Sorted Set)也使得我們在執行這些運算的時候變的非常簡單,Redis只是剛好提供了這兩種資料結構。所以,我們要從排序集合中獲取到排名最靠前的10個用戶–我們稱之為“user_scores”,我們只需要像下面一樣執行即可:
當然,這是假定你是根據你用戶的分數做遞增的排序。如果你想回傳使用者及使用者的分數,你需要這樣執行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一個很好的例子,用Ruby實現的,它的排行榜就是使用Redis來儲存資料的,你可以在這裡看到。
(5)、發布/訂閱
最後(但肯定不是最不重要的)是Redis的發布/訂閱功能。發布/訂閱的使用場景確實非常多。我已看見人們在社群網路連線中使用,還可作為基於發布/訂閱的腳本觸發器,甚至用Redis的發布/訂閱功能來建立聊天系統! (不,這是真的,你可以去核實)。
Redis提供的所有特性中,我感覺這個是喜歡的人最少的一個,雖然它為用戶提供如果此多功能。
高可用(High Availability),是當一台伺服器停止服務後,對於業務及使用者毫無影響。停止服務的原因可能由於網路卡、路由器、機房、CPU負載過高、記憶體溢出、自然災害等不可預期的原因導致,在很多時候也稱單點問題。
(1)解決單點問題主要有2種方式:
主備方式
這種通常是一台主機、一台或多台備機,在正常情況下主機對外提供服務,並把資料同步到備機,當主機宕機後,備機立刻開始服務。
Redis HA中使用比較多的是keepalived,它使主機備機對外提供同一個虛擬IP,客戶端透過虛擬IP進行資料操作,正常期間主機一直對外提供服務,宕機後VIP自動漂移到備機上。
優點是對客戶端毫無影響,仍然透過VIP操作。
缺點也很明顯,在絕大多數時間內備機是一直沒使用,被浪費著的。
主從方式
這種採取一主多從的辦法,主從之間進行資料同步。當Master宕機後,透過選舉演算法(Paxos、Raft)從slave中選出新Master繼續對外提供服務,主機恢復後以slave的身份重新加入。
主從另一個目的是進行讀寫分離,這是當單機讀寫壓力過高的一種通用型解決方案。其主機的角色只提供寫入操作或少量的讀,把多餘讀請求透過負載平衡演算法分流到單一或多個slave伺服器上。
缺點是主機宕機後,Slave雖然被選成新Master了,但對外提供的IP服務位址卻改變了,代表會影響到客戶端。解決這種情況需要一些額外的工作,在主機位址變更後及時通知到客戶端,客戶端收到新位址後,使用新位址繼續發送新要求。
(2)資料同步
無論是主備或主從都牽扯到資料同步的問題,這也分成2種情況:
同步方式:當主機收到客戶端寫入操作後,以同步方式把資料同步到從機上,當從機也成功寫入後,主機才回傳客戶端成功,也稱為資料強一致性。很顯然這種方式效能會降低不少,當從機很多時,可以不用每台都同步,主機同步某一台從機後,從機再把資料分發同步到其他從機上,這樣提高主機效能分擔同步壓力。在redis中是支援這楊配置的,一台master,一台slave,同時這台salve又作為其他slave的master。
非同步方式:主機接收到寫入操作後,直接返回成功,然後在後台用非同步方式把資料同步到從機上。這種同步效能比較好,但無法保證資料的完整性,例如在非同步同步過程中主機突然宕機了,也稱這種方式為資料弱一致性。
Redis主從同步採用的是非同步方式,因此會有少量丟資料的危險。還有種弱一致性的特例叫最終一致性,這塊詳細內容可參考CAP原理及一致性模型。
(3)方案選擇
keepalived方案配置簡單、人力成本小,在資料量少、壓力小的情況下建議使用。如果資料量比較大,不希望過多浪費機器,還希望在宕機後,做一些自訂的措施,例如警報、記日誌、資料遷移等操作,推薦使用主從方式,因為和主從搭配的一般還有個管理監控中心。
宕機通知這塊,可以整合到客戶端元件上,也可單獨抽離出來。 Redis官方Sentinel支援故障自動轉移、通知等,詳情請見低成本高可用方案設計(四)。
邏輯圖: 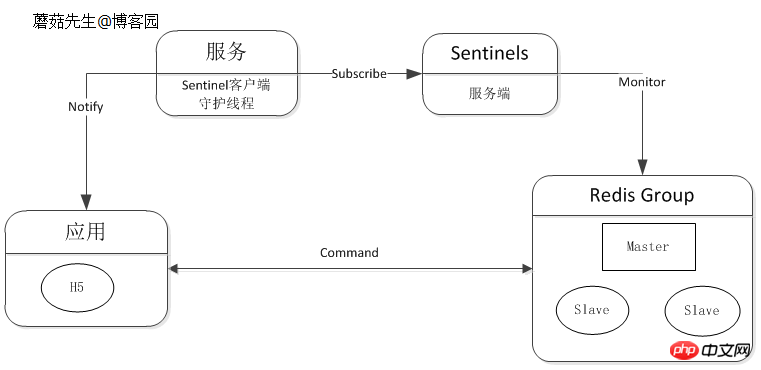
分散式(distributed), 是當業務量、資料量增加時,可以透過任意增加減少伺服器數量來解決問題。
叢集時代
至少部署兩台Redis伺服器構成一個小的集群,主要有2個目的:
高可用性:在主機掛掉後,自動故障轉移,使前端服務對用戶無影響。
讀寫分離:將主機讀取壓力分流到從機上。
可在客戶端元件上實現負載平衡,依照不同伺服器的運作情況,分擔不同比例的讀取請求壓力。
邏輯圖: 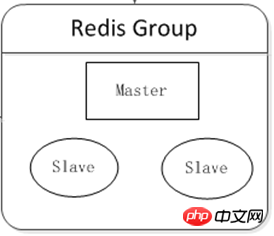
當快取資料量不斷增加時,單機記憶體不夠使用,需要把資料切分不同部分,分佈到多台伺服器上。
可在客戶端對資料進行分片,資料分片演算法詳見C#一致性Hash詳解、C#之虛擬桶分片。
邏輯圖: 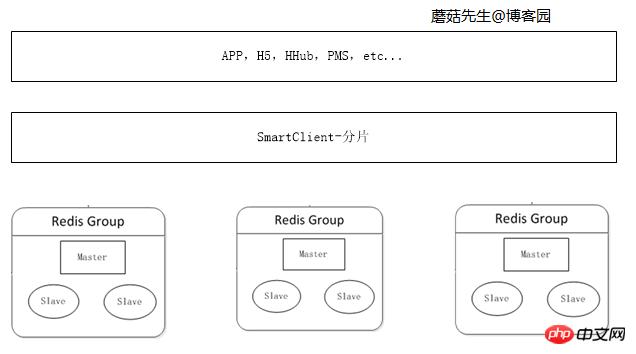
大規模分散式叢集時代
當資料量持續增加時,應用程式可根據不同情境下的業務申請對應的分散式集群。這塊最關鍵的是快取治理這塊,其中最重要的部分是加入了代理服務。應用程式透過代理程式存取真實的Redis伺服器進行讀寫,這樣做的好處是:
避免越來越多的客戶端直接存取Redis伺服器難以管理,而造成風險。
在代理這一層可以做對應的安全措施,例如限流、授權、分片。
避免客戶端越來越多的邏輯程式碼,不但臃腫升級還比較麻煩。
代理這層無狀態的,可任一擴充節點,對客戶端來說,存取代理程式跟存取單機Redis一樣。
目前樓主公司使用的是客戶端元件和代理商兩種方案並存,因為透過代理商會影響一定的效能。代理這塊對應的方案實作有Twitter的Twemproxy和豌豆莢的codis。
邏輯圖: 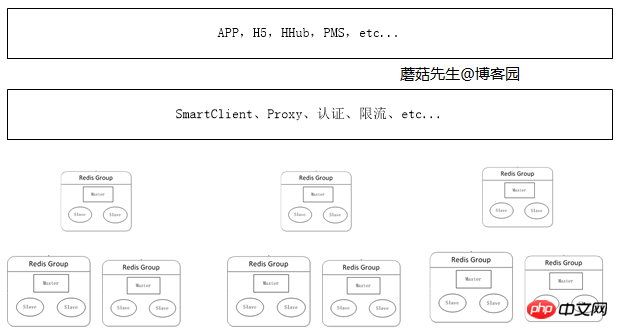
分散式快取再向後是雲端服務緩存,對使用端完全屏蔽細節,各應用自行申請大小、流量方案即可,如淘寶OCS雲端服務快取。
分散式快取對應需要的實作元件有:
一個快取監控、遷移、管理中心。
一個自訂的客戶端元件,上圖的SmartClient。
一個無狀態的代理服務。
N台伺服器。
相關學習推薦:redis影片教學
#### ####相關學習推薦:mysql影片教學
以上是Redis面試題目及分散式集群的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















