

網易雲音樂評論爬取
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
#總結:
1、第一行的「# coding=gbk」表示的是可以在文字編輯器中輸入文字字串。
2、"id = music_url.split('=')[1]"中split()函數表示將元素分組,例中為「https://music.163.com /#/song?id=”,“28815250”
3、由requests模組取得的HTML文字需要用json.loads()方法轉換為Python可讀的文本,否則會報錯。在jupyter notebook中則不會出現這種情況。
4、replace()函數可以移除字串中的元素,例中將換行符號變成空。
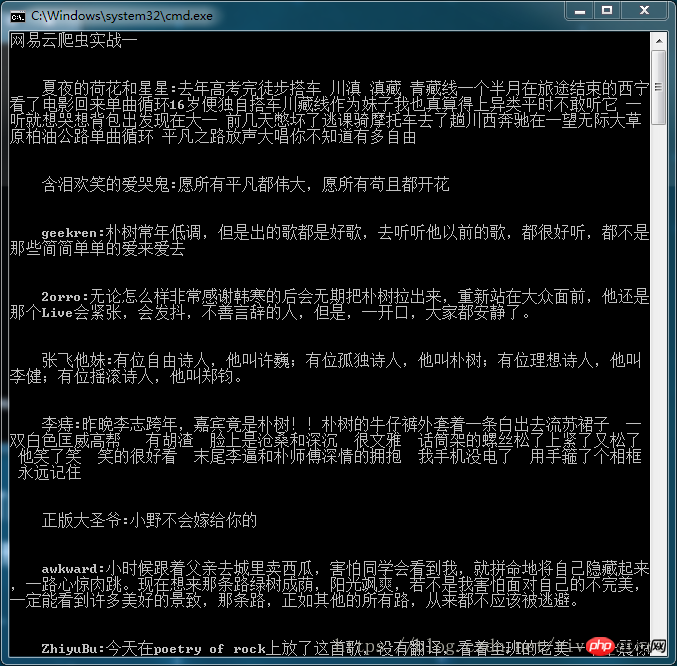
最終顯示結果如下圖:
#本文介紹了網易雲音樂評論爬取的相關內容,請關注php中文網。
相關推薦:
#以上是網易雲音樂評論爬取的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 利用紐約時報API進行元資料爬取
Sep 02, 2023 pm 10:13 PM
利用紐約時報API進行元資料爬取
Sep 02, 2023 pm 10:13 PM
簡介上週,我寫了一篇關於抓取網頁以收集元資料的介紹,並提到不可能抓取《紐約時報》網站。 《紐約時報》付費牆會阻止您收集基本元資料的嘗試。但有一種方法可以使用紐約時報API來解決這個問題。最近我開始在Yii平台上建立一個社群網站,我將在以後的教程中發布該網站。我希望能夠輕鬆添加與網站內容相關的連結。雖然人們可以輕鬆地將URL貼到表單中,但提供標題和來源資訊卻非常耗時。因此,在今天的教程中,我將擴展我最近編寫的抓取程式碼,以在添加《紐約時報》連結時利用《紐約時報》API來收集頭條新聞。請記住,我參與了
 如何在PHP專案中透過呼叫API介面來實現資料的爬取與處理?
Sep 05, 2023 am 08:41 AM
如何在PHP專案中透過呼叫API介面來實現資料的爬取與處理?
Sep 05, 2023 am 08:41 AM
如何在PHP專案中透過呼叫API介面來實現資料的爬取與處理?一、介紹在PHP專案中,我們經常需要爬取其他網站的數據,並對這些數據進行處理。而許多網站提供了API接口,我們可以透過呼叫這些接口來取得資料。本文將介紹如何使用PHP來呼叫API接口,實現資料的爬取與處理。二、取得API介面的URL和參數在開始之前,我們需要先取得目標API介面的URL以及所需的
 Vue開發經驗總結:優化SEO和搜尋引擎爬取的技巧
Nov 22, 2023 am 10:56 AM
Vue開發經驗總結:優化SEO和搜尋引擎爬取的技巧
Nov 22, 2023 am 10:56 AM
Vue開發經驗總結:優化SEO和搜尋引擎爬取的技巧隨著網路的快速發展,網站的SEO(SearchEngineOptimization,搜尋引擎優化)變得越來越重要。對於使用Vue進行開發的網站來說,優化SEO和搜尋引擎爬取是至關重要的。本文將總結一些Vue開發經驗,分享一些優化SEO和搜尋引擎爬取的技巧。使用預渲染(Prerendering)技術Vue
 如何使用Scrapy爬取豆瓣圖書及其評分和評論?
Jun 22, 2023 am 10:21 AM
如何使用Scrapy爬取豆瓣圖書及其評分和評論?
Jun 22, 2023 am 10:21 AM
隨著網路的發展,人們越來越依賴網路來獲取資訊。而對於圖書愛好者而言,豆瓣圖書已經成為了一個不可或缺的平台。並且,豆瓣圖書也提供了豐富的圖書評分和評論,使讀者能夠更全面地了解一本圖書。但是,手動取得這些資訊無異於大海撈針,這時候,我們可以藉助Scrapy工具進行資料爬取。 Scrapy是一個基於Python的開源網路爬蟲框架,它可以幫助我們有效率地
 Scrapy實戰:爬取百度新聞數據
Jun 23, 2023 am 08:50 AM
Scrapy實戰:爬取百度新聞數據
Jun 23, 2023 am 08:50 AM
Scrapy實戰:爬取百度新聞資料隨著網路的發展,人們獲取資訊的主要途徑已從傳統媒體轉移到網路,人們越來越依賴網路獲取新聞資訊。而對於研究者或分析師來說,需要大量的數據來進行分析和研究。因此,本文將介紹如何用Scrapy爬取百度新聞數據。 Scrapy是一個開源的Python爬蟲框架,它可以快速且有效率地爬取網站資料。 Scrapy提供了強大的網頁解析與抓取功
 如何使用PHP Goutte類別庫進行網頁爬取與資料擷取?
Aug 09, 2023 pm 02:16 PM
如何使用PHP Goutte類別庫進行網頁爬取與資料擷取?
Aug 09, 2023 pm 02:16 PM
如何使用PHPGoutte類別庫進行網頁爬取與資料擷取?概述:在日常的開發過程中,我們經常需要從網路上取得各種數據,例如電影排名、天氣預報等等。而網頁爬取則是取得這些資料的常用方法之一。在PHP開發中,我們可以利用Goutte類別庫來實現網頁爬取與資料擷取的功能。本文將介紹如何使用PHPGoutte類別庫進行網頁爬取與資料擷取,並附上程式碼範例。什麼是Gout
 Scrapy實戰:爬取豆瓣電影數據與評分熱度排名
Jun 22, 2023 pm 01:49 PM
Scrapy實戰:爬取豆瓣電影數據與評分熱度排名
Jun 22, 2023 pm 01:49 PM
Scrapy是一個開源的Python框架,用於快速且有效率地爬取資料。在本文中,我們將使用Scrapy爬取豆瓣影片的數據和評分熱度排名。準備工作首先,我們需要安裝Scrapy。您可以在命令列中輸入以下命令來安裝Scrapy:pipinstallscrapy接下來,我們將建立Scrapy專案。在命令列中,輸入以下命令:scrapystartproject
 使用 PHP 爬取 Steam 遊戲訊息
Jun 14, 2023 pm 05:26 PM
使用 PHP 爬取 Steam 遊戲訊息
Jun 14, 2023 pm 05:26 PM
隨著遊戲產業的發展,越來越多的遊戲玩家透過Steam平台購買遊戲。作為全球最大的PC遊戲分銷平台,Steam提供了豐富的遊戲和社群功能,吸引了來自全球的大量遊戲愛好者。如果你是Steam遊戲愛好者,或是想要了解Steam遊戲資訊的開發者,那麼本文將介紹如何使用PHP語言爬取Steam遊戲資訊。一、了解SteamAPISteam提供了官方A
