

淺談Java應用分散式架構的演進過程

一.分散式架構的發展歷史
1946年,世界上第一台電子電腦在美國的賓州大學誕生,它的名字是:ENICAC ,這台計算機的體重比較大,計算速度也不快,但是而代表了計算機時代的到來,再以後的互聯網的發展中也有基礎性的意義。
電腦的組成是有五部分完成的,分別是:輸入設備,輸出設備,記憶體,記憶體裡面由運算器和控制器,有一個馮諾依曼的模型非常形象的物件電腦的組成進行了描述,不過計算機也是有資料流,指令流,控制流來進行計算的和正常運轉的。如圖:
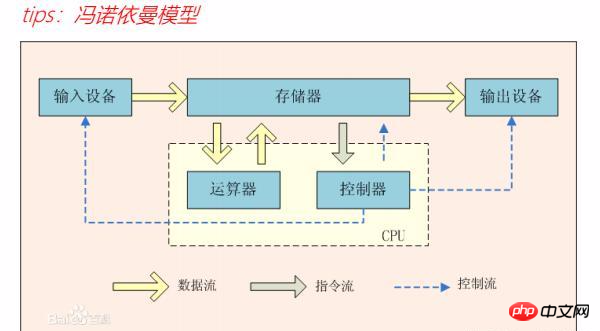
ENIAC之後,電子計算機進入到了IBM主導的大型機的時代, 在1946年第一台IBM大型機SYSTEM/360誕生,這使得IBM在20世紀50~60年代統治了整個大型電腦的工業,在大型主機時代,電腦架構向兩個方向發展CISC(微處理器執行的電腦語言指令集)CPU為架構的價格便宜的個人PC和RISC(精簡指令集電腦)價格高的小型UNIX伺服器。
大型主機的出現,憑藉著計算能力和處理能力,高的穩定性和安全性,在很長的一段時間內引領到計算領域的發展。但是集中式的電腦系統來帶來了一些問題,來越來越不能滿足用戶的需求比如說:
1.大型的主機非常貴,一般的小企業用不起。
2.大型主機比較複雜,培養人才的成本比較高。
3.單點問題,如過大型機出現故障,整個系統都掛了運作不了,使企業的損失非常大。
4.隨著科技的進步,個人PC電腦的性能越來越高,成本也越來越低。
阿里巴巴在2009年發起了一項去「IOE」的驅動程式
IOE指的是IBM的小型機,Oracle的資料庫和EMC的高階儲存設備,2009年的去IOE的運動,一直到2003的支付寶的最後一台IBM的小型機的下線。
為什麼要去IOE
阿里巴巴過去資料庫使用的是Oracle,並使用小型機和高階儲存裝置提供高效能的資料處理和儲存服務。隨著公司的業務量的上升,用戶規模的不斷上漲,傳統的集中式的架構Oracle資料庫在擴展方面遭遇了瓶頸。向傳統的Oracle,DB2都是以集中式的為主,存在的缺點就是擴展性的不足,集中式的擴展主要是採用的是向上的擴展不是水平的擴展,這樣時間長了,早晚都會遇到系統瓶頸。
一.分散式架構的常見概念
集群
小飯店原來是個廚師,切菜洗菜備料炒菜全乾。後來客人多了,廚房一個廚師忙不過來,又請了個廚師,兩個廚師都能炒一樣的菜,這兩個廚師的關係就是集群。
分散式
為了讓廚師專心炒菜,把菜做到極致,又請了個配菜師負責切菜,備菜,備料,廚師和配菜師的關係就是分佈式的,一個配菜師也忙不過來,有請了個配菜師,這兩個配菜師的關係就是集群了。所以說有分散式的架構中可能有集群,但集群不等於有分佈式。
節點
節點是指一個可以獨立依照分散式協定完成一組邏輯的程式個體。在具體的項目中,一個節點表示的是一個作業系統上的進程。
副本機制
副本指的是分散式系統中為資料或服務提供冗餘。
資料副本指在不同的節點上持久化同一份資料,當出現某一個節點的資料遺失時,可以從副本讀取資料。資料副本是分散式系統中結果資料遺失的唯一手段。
服務副本表示的是多個節點提供相同的服務,透過主從關係來實現服務的高可用方案。
中間件
中間件位元與作業系統提供的服務之外,又不屬於應用程式,它是位元與應用程式和系統層之間為開發者方便的處理通訊,輸入和輸出的一類軟體,能夠讓使用者關心自己應用的一部分。
架構的發展過程
一個成熟的大型網站系統架構並不是一開始就設計的非常完美的,也不是一開始就具備高性能,高可用,安全性等特性,而是隨著用戶量的增加,業務功能的擴展慢慢完善演變過來的。在這個發展過程中,開發模式,技術架構等都會發生非常大的變化。
假如係統具備一下功能:
使用者模組:使用者註冊與管理
商品模組:商品展示與管理
交易模組:建立交易及支付結算
#階段一:單應用架構
系統的初級都是應用程式和資料庫都放在一台伺服器上。

階段二:應用程式伺服器與資料庫伺服器分離
隨著網站的使用者量增大,流量增大,對應用程式伺服器和資料庫伺服器單獨的部署機器,這樣可以增加系統的性能,提高存取的效率,提高單機的負載能力和容災的能力。
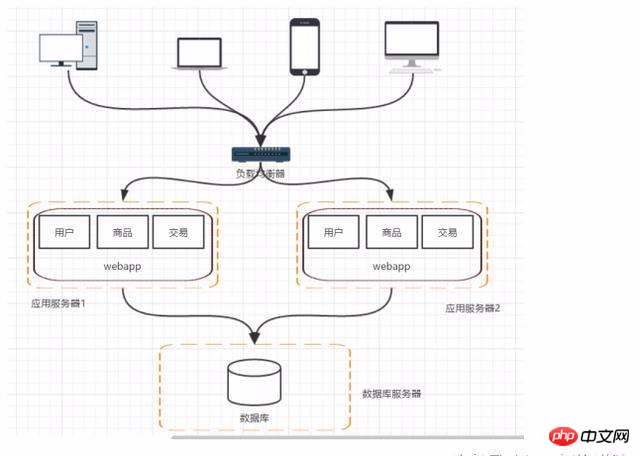
階段三:應用伺服器叢集-應用伺服器負載警告
隨著訪問量和流量的增加,假設資料庫沒有遇到瓶頸,對應用伺服器叢集來對請求進行分流,提高程式的性能。存在的問題:使用者的請求由誰來轉送,session如何來管理的問題。
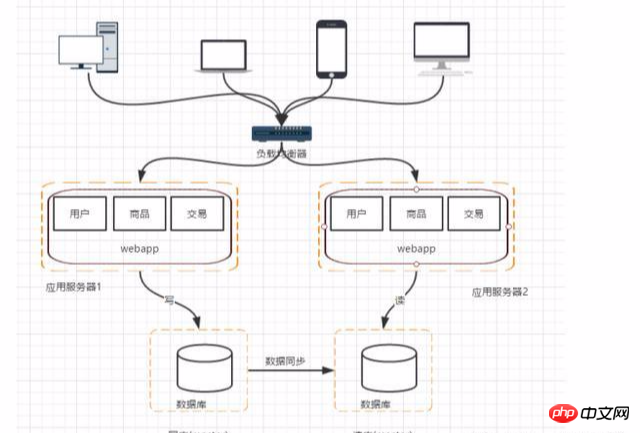
階段四:資料庫壓力變大-資料庫讀寫分離
#讀寫分離的話,這樣以後的請求,查詢的請求就可以去從庫裡面讀資料,寫的資料可以到主庫中了,但是會帶來幾個問題:
1.主從的資料庫之間的資料同步:可以使用mysql自帶的master-slave方式實現主從複製
2.對應的資料來源的選擇:採用第三方資料庫中間件,例如:mycat
 ##
##
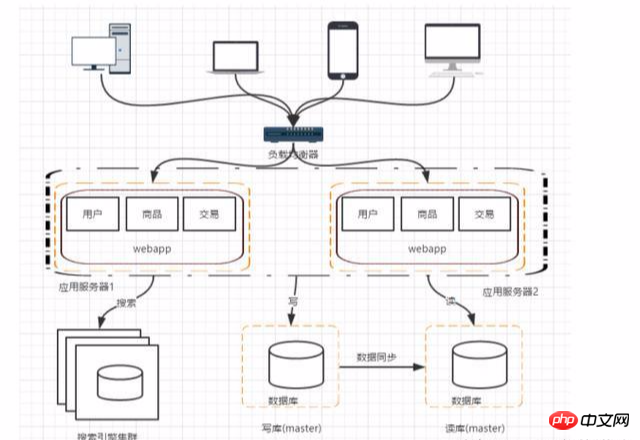
階段五:使用搜尋引擎緩解讀庫的壓力
資料庫做讀庫的話,常常對模糊查詢的性能不是很好,特別是對於大型的互聯網公司來說,想搜尋的模組就比較核心了,這是可以使用搜尋引擎了,雖然可以大幅度的提高查詢的速度,但是同時也會帶來一些問題比如索引的構建。
階段六:引入快取機制緩解資料庫的壓力
對一些熱點的資料,可以使用redis,memcache來作為應用層的快取;另外在某些場景下,可以使用mongodb來取代關係型資料庫來儲存。
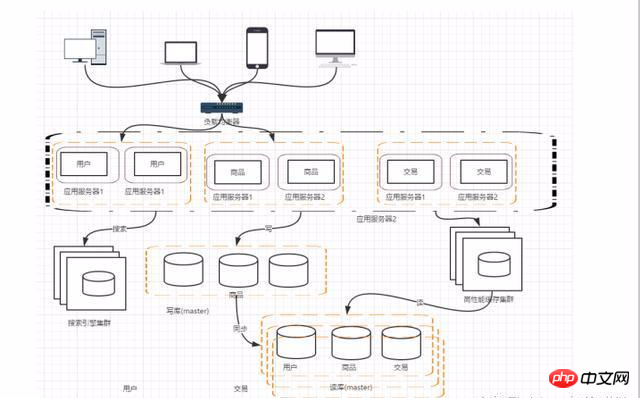
階段七:資料庫的水平/垂直拆分
#垂直拆分:把資料庫中不同的業務資料拆分到不同的資料庫中。
水平拆分:把同一個表中的資料拆分到兩個甚至更多的資料庫中,水平拆分的原因是某些業務量資料量大的已經達到了單一資料庫的瓶頸,這時候可以採取將表格拆分到多個資料庫中。

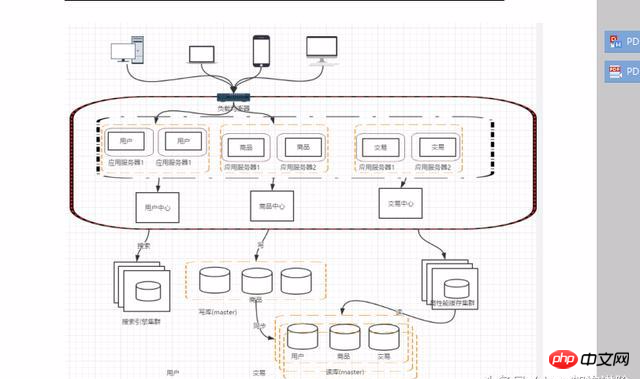
階段八:應用程式的拆分
隨著業務的發展,業務越來越多,應用的壓力越來越大。工程規模也越來越龐大。這個時候就可以考慮將應用拆分,按照領域模型將我們的用戶,商品,交易分拆成子系統。
這樣拆分以後,可能會有一些相同的程式碼,例如使用者操作,商品的交易查詢,所有會導致每個系統都會有使用者查詢和存取相關的操作。這些相同的程式碼和模組一定要抽象化。這樣有利於維修和管理。
服務拆分以後,服務之間的通訊可以透過RPC技術,比較典型的有:webservice、hession、http、RMI等。
以上是淺談Java應用分散式架構的演進過程的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP行動:現實世界中的示例和應用程序
Apr 14, 2025 am 12:19 AM
PHP行動:現實世界中的示例和應用程序
Apr 14, 2025 am 12:19 AM
PHP在電子商務、內容管理系統和API開發中廣泛應用。 1)電子商務:用於購物車功能和支付處理。 2)內容管理系統:用於動態內容生成和用戶管理。 3)API開發:用於RESTfulAPI開發和API安全性。通過性能優化和最佳實踐,PHP應用的效率和可維護性得以提升。
 PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP是一種廣泛應用於服務器端的腳本語言,特別適合web開發。 1.PHP可以嵌入HTML,處理HTTP請求和響應,支持多種數據庫。 2.PHP用於生成動態網頁內容,處理表單數據,訪問數據庫等,具有強大的社區支持和開源資源。 3.PHP是解釋型語言,執行過程包括詞法分析、語法分析、編譯和執行。 4.PHP可以與MySQL結合用於用戶註冊系統等高級應用。 5.調試PHP時,可使用error_reporting()和var_dump()等函數。 6.優化PHP代碼可通過緩存機制、優化數據庫查詢和使用內置函數。 7
 神秘的JavaScript:它的作用以及為什麼重要
Apr 09, 2025 am 12:07 AM
神秘的JavaScript:它的作用以及為什麼重要
Apr 09, 2025 am 12:07 AM
JavaScript是現代Web開發的基石,它的主要功能包括事件驅動編程、動態內容生成和異步編程。 1)事件驅動編程允許網頁根據用戶操作動態變化。 2)動態內容生成使得頁面內容可以根據條件調整。 3)異步編程確保用戶界面不被阻塞。 JavaScript廣泛應用於網頁交互、單頁面應用和服務器端開發,極大地提升了用戶體驗和跨平台開發的靈活性。
 PHP的持久相關性:它還活著嗎?
Apr 14, 2025 am 12:12 AM
PHP的持久相關性:它還活著嗎?
Apr 14, 2025 am 12:12 AM
PHP仍然具有活力,其在現代編程領域中依然佔據重要地位。 1)PHP的簡單易學和強大社區支持使其在Web開發中廣泛應用;2)其靈活性和穩定性使其在處理Web表單、數據庫操作和文件處理等方面表現出色;3)PHP不斷進化和優化,適用於初學者和經驗豐富的開發者。
 PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP和Python各有優勢,選擇應基於項目需求。 1.PHP適合web開發,語法簡單,執行效率高。 2.Python適用於數據科學和機器學習,語法簡潔,庫豐富。
 PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP適合web開發,特別是在快速開發和處理動態內容方面表現出色,但不擅長數據科學和企業級應用。與Python相比,PHP在web開發中更具優勢,但在數據科學領域不如Python;與Java相比,PHP在企業級應用中表現較差,但在web開發中更靈活;與JavaScript相比,PHP在後端開發中更簡潔,但在前端開發中不如JavaScript。
 PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP和Python各有優勢,適合不同場景。 1.PHP適用於web開發,提供內置web服務器和豐富函數庫。 2.Python適合數據科學和機器學習,語法簡潔且有強大標準庫。選擇時應根據項目需求決定。
 為什麼要使用PHP?解釋的優點和好處
Apr 16, 2025 am 12:16 AM
為什麼要使用PHP?解釋的優點和好處
Apr 16, 2025 am 12:16 AM
PHP的核心優勢包括易於學習、強大的web開發支持、豐富的庫和框架、高性能和可擴展性、跨平台兼容性以及成本效益高。 1)易於學習和使用,適合初學者;2)與web服務器集成好,支持多種數據庫;3)擁有如Laravel等強大框架;4)通過優化可實現高性能;5)支持多種操作系統;6)開源,降低開發成本。
