

mysql資料庫分庫分錶技術難點解決策略
mysql資料庫分庫分錶方案,一旦資料庫太龐大,尤其是當寫入過於頻繁,非常難由一台主機支撐的時候,我們還是會面臨到擴展瓶頸。這時候,我們必須許找其它技術手段來解決這個瓶頸,那就是我們這一章要介紹惡的資料切分技術。
mysql資料庫切分
前言
透過MySQLReplication功能所實現的擴充總是會受到資料庫大小的限制。一旦資料庫過於龐大,尤其是當寫入過於頻繁,非常難由一台主機支撐的時候,我們還是會面臨到擴展瓶頸。這時候,我們必須許找其它技術手段來解決這個瓶頸,那就是我們這一章要介紹惡的資料切分技術。
何謂資料切分
可能非常多讀者朋友在網路上或是雜誌上面都已經多次見到關於資料切分的相關文章了,僅僅只是在有些文章中稱之為數據的Sharding。事實上無論是稱之為資料的Sharding或是資料的切分,其概念都是一樣的。
簡單來說,就是指透過某種特定的條件,將我們存放在同一個資料庫中的資料分散存放到多個資料庫(主機)上面,以達到分散單一裝置負載的效果。資料的切分在同一時候也能夠提高系統的整體可用性,由於單一設備Crash之後。僅僅有總體數據的某部分不可用,而不是全部的數據。
資料的切分(Sharding)依據其切分規則的型別。能夠分為兩種切分模式。
一種是依照不同的表格(或Schema)來切割到不同的資料庫(主機)之上,這樣的切割能夠稱為資料的垂直(縱向)切分。另外一種則是依據表中的資料的邏輯關係,將同一個表中的資料依照某種條件拆分到多台資料庫(主機)上面。這樣的切分稱為資料的水平(橫向)切分。
垂直切分的最大特色是規則簡單,實施也更為方便,尤其適合各業務之間的耦合度非常低。相互影響非常小,業務邏輯非常清晰的系統。在這樣的系統中,能夠非常easy做到將不同業務模組所使用的表分拆到不同的資料庫中。依據不同的表格來進行拆分。對應用程式的影響也更小,拆分規則也會比較簡單清晰。
水平切分於垂直切分相較。相對來說略微複雜一些。由於要將同一個表中的不同資料拆分到不同的資料庫中,對於應用程式來說,拆分規則本身就較依據表名來拆分更為複雜,後期的資料維護也會更為複雜一些。
當我們某個(或某些)表的資料量和訪問量特別的大,透過垂直切分將其放在獨立的裝置上後仍然無法滿足效能要求,這時候我們就必須將垂直切分和水平切分結合。先垂直切分,再水平切分。才乾解決這樣的超大型表的效能問題。
以下我們針對垂直、水平以及組合切分這三種資料切分方式的架構實現及切分後資料的整合進行對應的分析。
資料的垂直切分
我們先來看看,資料的垂直切分究竟是怎樣一個切分法的。資料的垂直切分。也能夠稱之為縱向切分。將資料庫想像成為由非常多個一大塊的「資料塊」(表)組成。我們垂直的將這些「資料塊」切開,然後將他們分散到多台資料庫主機上面。這樣的切分方法就是一個垂直(縱向)的資料切分。
一個架構設計較好的應用系統。其整體功能肯定是由非常多個功能模組所組成的。而每一個功能模組所須要的資料對應到資料庫中就是一個或多個表。
而在架構設計中,各個功能模組彼此之間的交互點越統一越少,系統的耦合度就越低,系統各個模組的維護性以及擴充性也越好。這樣的系統。實現資料的垂直切分也就越easy。
當我們的功能模組越清晰,耦合度越低,資料垂直切分的規則定義就越easy。全然能夠依據功能模組來進行資料的切分,不同功能模組的資料存放於不同的資料庫主機中,能夠非常easy就避免掉跨資料庫的Join存在。同一時候系統架構也非常的清晰。
当然。非常难有系统能够做到全部功能模块所使用的表全然独立,全然不须要訪问对方的表或者须要两个模块的表进行Join操作。这样的情况下,我们就必须依据实际的应用场景进行评估权衡。决定是迁就应用程序将须要Join的表的相关某快都存放在同一个数据库中,还是让应用程序做很多其它的事情,也就是程序全然通过模块接口取得不同数据库中的数据,然后在程序中完毕Join操作。
一般来说。假设是一个负载相对不是非常大的系统,并且表关联又非常的频繁。那可能数据库让步。将几个相关模块合并在一起降低应用程序的工作的方案能够降低较多的工作量。是一个可行的方案。
当然。通过数据库的让步,让多个模块集中共用数据源,实际上也是简单介绍的默许了各模块架构耦合度增大的发展,可能会让以后的架构越来越恶化。尤其是当发展到一定阶段之后,发现数据库实在无法承担这些表所带来的压力。不得不面临再次切分的时候。所带来的架构改造成本可能会远远大于最初的时候。
所以。在数据库进行垂直切分的时候,怎样切分,切分到什么样的程度,是一个比較考验人的难题。仅仅能在实际的应用场景中通过平衡各方面的成本和收益。才干分析出一个真正适合自己的拆分方案。
比方在本书所使用演示样例系统的example数据库,我们简单的分析一下。然后再设计一个简单的切分规则,进行一次垂直垂直拆分。
系统功能能够基本分为四个功能模块:用户,群组消息,相冊以及事件。分别对应为例如以下这些表:
1. 用户模块表:user,user_profile,user_group,user_photo_album
2. 群组讨论表:groups,group_message,group_message_content,top_message
3. 相冊相关表:photo,photo_album,photo_album_relation,photo_comment
4. 事件信息表:event
初略一看,没有哪一个模块能够脱离其它模块独立存在,模块与模块之间都存在着关系。莫非无法切分?
当然不是,我们再略微深入分析一下,能够发现,尽管各个模块所使用的表之间都有关联,可是关联关系还算比較清晰,也比較简单。
◆ 群组讨论模块和用户模块之间主要存在通过用户或者是群组关系来进行关联。一般关联的时候都会是通过用户的id或者nick_name以及group的id来进行关联。通过模块之间的接口实现不会带来太多麻烦。
◆ 相冊模块仅仅与用户模块存在通过用户的关联。这两个模块之间的关联基本就有通过用户id关联的内容。简单清晰,接口明白;
◆ 事件模块与各个模块可能都有关联,可是都仅仅关注其各个模块中对象的ID信息,相同能够做到非常easy分拆。
所以。我们第一步能够将数据库依照功能模块相关的表进行一次垂直拆分。每一个模块所涉及的表单独到一个数据库中,模块与模块之间的表关联都在应用系统端通过藉口来处理。例如以下图所看到的:

通过这样的垂直切分之后。之前仅仅能通过一个数据库来提供的服务。就被分拆成四个数据库来提供服务,服务能力自然是添加几倍了。
垂直切分的长处
◆ 数据库的拆分简单明了,拆分规则明白;
◆ 应用程序模块清晰明白,整合easy。
◆ 数据维护方便易行,easy定位。
垂直切分的缺点
◆ 部分表关联无法在数据库级别完毕。须要在程序中完毕。
◆ 对于訪问极其频繁且数据量超大的表仍然存在性能平静,不一定能满足要求。
◆ 事务处理相对更为复杂;
◆ 切分达到一定程度之后,扩展性会遇到限制;
◆ 过读切分可能会带来系统过渡复杂而难以维护。
针对于垂直切分可能遇到数据切分及事务问题,在数据库层面实在是非常难找到一个较好的处理方案。实际应用案例中,数据库的垂直切分大多是与应用系统的模块相对应,同一个模块的数据源存放于同一个数据库中,能够解决模块内部的数据关联问题。而模块与模块之间,则通过应用程序以服务接口方式来相互提供所须要的数据。
尽管这样做在数据库的总体操作次数方面确实会有所添加,可是在系统总体扩展性以及架构模块化方面,都是故意的。可能在某些操作的单次响应时间会稍有添加。可是系统的总体性能非常可能反而会有一定的提升。而扩展瓶颈问题。就仅仅能依靠下一节将要介绍的数据水平切分架构来攻克了。
数据的水平切分
上面一节分析介绍了数据的垂直切分,这一节再分析一下数据的水平切分。数据的垂直切分基本上能够简单的理解为依照表依照模块来切分数据,而水平切分就不再是依照表或者是功能模块来切分了。一般来说,简单的水平切分主要是将某个訪问极其平庸的表再依照某个字段的某种规则来分散到多个表之中。每一个表中包括一部分数据。
简单来说。我们能够将数据的水平切分理解为是依照数据行的切分。就是将表中的某些行切分到一个数据库,而另外的某些行又切分到其它的数据库中。当然,为了能够比較easy的判定各行数据被切分到哪个数据库中了,切分总是都须要依照某种特定的规则来进行的。
如依据某个数字类型字段基于特定数目取模,某个时间类型字段的范围。或者是某个字符类型字段的hash值。假设整个系统中大部分核心表都能够通过某个字段来进行关联。那这个字段自然是一个进行水平分区的上上之选了,当然,非常特殊无法使用就仅仅能另选其它了。
一般来说,像如今互联网非常火爆的Web2.0类型的站点。基本上大部分数据都能够通过会员用户信息关联上,可能非常多核心表都非常适合通过会员ID来进行数据的水平切分。
而像论坛社区讨论系统。就更easy切分了,非常easy依照论坛编号来进行数据的水平切分。
切分之后基本上不会出现各个库之间的交互。
如我们的演示样例系统。全部数据都是和用户关联的。那么我们就能够依据用户来进行水平拆分,将不同用户的数据切分到不同的数据库中。当然,唯一有点差别的是用户模块中的groups表和用户没有直接关系。所以groups不能依据用户来进行水平拆分。对于这样的特殊情况下的表,我们全然能够独立出来。单独放在一个独立的数据库中。
事实上这个做法能够说是利用了前面一节所介绍的“数据的垂直切分”方法。我将在下一节中更为具体的介绍这样的垂直切分与水平切分同一时候使用的联合切分方法。
所以,对于我们的演示样例数据库来说,大部分的表都能够依据用户ID来进行水平的切分。不同用户相关的数据进行切分之后存放在不同的数据库中。如将全部用户ID通过2取模然后分别存放于两个不同的数据库中。
每一个和用户ID关联上的表都能够这样切分。这样,基本上每一个用户相关的数据。都在同一个数据库中,即使是须要关联,也能够非常简单的关联上。
我们能够通过下图来更为直观的展示水平切分相关信息:水平切分的长处
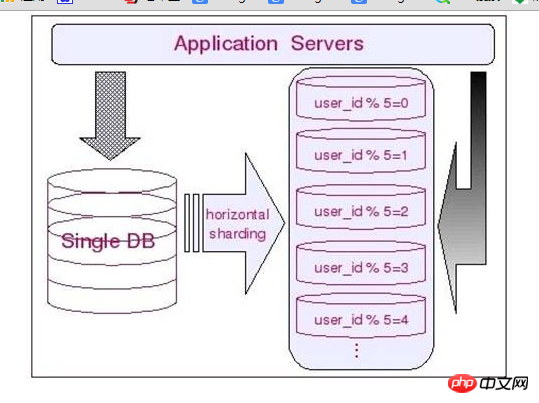
◆ 表关联基本能够在数据库端全部完毕;
◆ 不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
◆ 应用程序端总体架构修改相对较少;
◆ 事务处理相对简单;
◆ 仅仅要切分规则能够定义好。基本上较难遇到扩展性限制;
水平切分的缺点
◆ 切分规则相对更为复杂,非常难抽象出一个能够满足整个数据库的切分规则;
◆ 后期数据的维护难度有所添加,人为手工定位数据更困难;
◆ 应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
垂直與水平切分的組合使用
上面兩節內容。我們分別,了解了「垂直」和「水平」這兩種切分方式的實現以及切分之後的架構資訊。同一時候也分析了兩種架構各自的優缺點。可是在實際的應用場景中,除了那些負載並非太大。業務邏輯也相對較簡單的系統能夠透過上面兩種切分方法之中的一個來解決擴展性問題之外。恐怕其它大部分業務邏輯略微複雜一點,系統負載大一些的系統,都無法透過上面不論什麼一種資料的切分方法來實現較好的擴展性。而須要將上述兩種切分方法結合使用,不同的場景使用不同的切分法。
在這一節中。我將結合垂直切分和水平切分各自的優缺點,進一步完好我們的整體架構,讓系統的擴展性進一步提高。
一般來說。我們資料庫中的全部表格非常難透過某一個(或少數幾個)欄位全部關聯起來,所以非常難簡單的僅僅透過資料的水平切分來解決全部問題。而垂直切分也僅僅能解決部分問題,對於那些負載非常高的系統,即使僅僅是單一表都無法透過單一資料庫主機來承擔其負載。
我們必須結合「垂直」和「水平」兩種切分方式在同一時候使用,充分利用兩者的長處,避開其缺點。
每個應用系統的負載都是一步一步增長上來的,在開始遇到效能瓶頸的時候,大多數架構師和DBA都會選擇先進行資料的垂直拆分,由於這樣的成本最先。最符合這個時期所追求的最大投入產出比。然而。隨著業務的不斷擴張。系統負載的持續成長,在系統穩定一段時期之後,經過了垂直分割之後的資料庫叢集可能又再一次不堪重負,遇到了效能瓶頸。
這時候我們該怎麼抉擇?是再次進一步細分模組呢,還是尋求其它的辦法來解決?假設我們再一次像最開始那樣繼續細分模組,進行資料的垂直切分,那我們可能在不久的將來,又會遇到如今所面對的相同的問題。而隨著模組的不斷的細化,應用系統的架構也會越來越複雜,整個系統非常可能會出現失控的局面。
這時候我們必須透過資料的水平切分的優勢,來解決這裡所遇到的問題。並且,我們全然不必要在使用數據水平切分的時候,推倒之前進行數據垂直切分的成果,而是在其基礎上利用水平切分的優勢來避開垂直切分的弊端。解決系統複雜度不斷擴大的問題。
而水平分割的弊端(規則難以統一)也已經被先前的垂直切分解決掉了。讓水平拆分能夠進行的得心應手。
對於我們的示範範例資料庫。假設在最開始。我們進行了資料的垂直切分,然而隨著業務的不斷成長,資料庫系統遇到了瓶頸,我們選擇重構資料庫叢集的架構。怎樣重構?考慮到之前已經做好了資料的垂直切分,並且模組結構清晰理解。
而業務成長的動能越來越激烈。即使如今進一步再次拆分模組,也堅持不了太久。
我們選擇了在垂直切分的基礎上再進行水平分割。
經歷垂直分割後的各個資料庫叢集中的每一個都有一個功能模組。而每一個功能模組中的全部表基本上都會與某個欄位進行關聯。如用戶模組全部都能夠透過用戶ID進行切分,群組討論模組則都透過群組ID來切分。相冊模組則是依據相冊ID來進切分。最後的事件通知資訊表考慮到資料的時限性(僅僅會訪問近期某個事件段的資訊),則考慮按時間來切分。
下圖展示了切分後的整個架構:
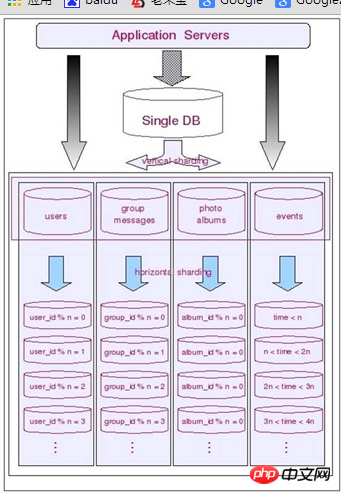
實際上,在非常多大型的應用系統中,垂直切割與水平切這兩種資料的切分方法基本上都是並存的。並且經常在不斷的交替進行,以不斷的添加系統的擴展能力。我們在應對不同的應用場景的時候,也須要充分考慮到這兩種切分方法各自的局限,以及各自的優勢。在不同的時期(負載壓力)使用不同的結合方式。
聯合切分的長處
◆ 能夠充分利用垂直切分和水平切分各自的優勢而避免各自的缺陷;
##◆ 讓系統擴展性得到最大化提升。 聯合切分的缺點◆ 数据库系统架构比較复杂。维护难度更大。
◆ 应用程序架构也相对更复杂;
数据切分及整合方案
通过前面的章节。我们已经非常清晰了通过数据库的数据切分能够极大的提高系统的扩展性。可是,数据库中的数据在经过垂直和(或)水平切分被存放在不同的数据库主机之后,应用系统面临的最大问题就是怎样来让这些数据源得到较好的整合。可能这也是非常多读者朋友非常关心的一个问题。这一节我们主要针对的内容就是分析能够使用的各种能够帮助我们实现数据切分以及数据整合的总体解决方式。
数据的整合非常难依靠数据库本身来达到这个效果,尽管MySQL存在Federated存储引擎,能够解决部分相似的问题。可是在实际应用场景中却非常难较好的运用。那我们该怎样来整合这些分散在各个MySQL主机上面的数据源呢?
总的来说,存在两种解决思路:
1. 在每一个应用程序模块中配置管理自己须要的一个(或者多个)数据源。直接訪问各个数据库,在模块内完毕数据的整合;
2. 通过中间代理层来统一管理全部的数据源。后端数据库集群对前端应用程序透明;
可能90%以上的人在面对上面这两种解决思路的时候都会倾向于选择另外一种,尤其是系统不断变得庞大复杂的时候。
确实。这是一个非常正确的选择,尽管短期内须要付出的成本可能会相对更大一些,可是对整个系统的扩展性来说,是非常有帮助的。
所以,对于第一种解决思路我这里就不准备过多的分析,以下我重点分析一下在另外一种解决思路中的一些解决方式。
★ 自行开发中间代理层
在决定选择通过数据库的中间代理层来解决数据源整合的架构方向之后,有不少公司(或者企业)选择了通过自行开发符合自身应用特定场景的代理层应用程序。
通过自行开发中间代理层能够最大程度的应对自身应用的特定。最大化的定制非常多个性化需求,在面对变化的时候也能够灵活的应对。这应该说是自行开发代理层最大的优势了。
当然,选择自行开发,享受让个性化定制最大化的乐趣的同一时候,自然也须要投入很多其它的成本来进行前期研发以及后期的持续升级改进工作。并且本身的技术门槛可能也比简单的Web应用要更高一些。所以,在决定选择自行开发之前,还是须要进行比較全面的评估为好。
由于自行开发很多其它时候考虑的是怎样更好的适应自身应用系统,应对自身的业务场景,所以这里也不好分析太多。后面我们主要分析一下当前比較流行的几种数据源整合解决方式。
★利用MySQLProxy实现数据切分及整合
MySQLProxy是MySQL官方提供的一个数据库代理层产品,和MySQLServer一样,相同是一个基于GPL开源协议的开源产品。可用来监视、分析或者传输他们之间的通讯信息。他的灵活性同意你最大限度的使用它,眼下具备的功能主要有连接路由,Query分析,Query过滤和修改,负载均衡。以及主要的HA机制等。
实际上,MySQLProxy本身并不具有上述全部的这些功能。而是提供了实现上述功能的基础。
要实现这些功能,还须要通过我们自行编写LUA脚本来实现。
MySQLProxy实际上是在client请求与MySQLServer之间建立了一个连接池。全部client请求都是发向MySQLProxy,然后经由MySQLProxy进行对应的分析。推断出是读操作还是写操作,分发至对应的MySQLServer上。对于多节点Slave集群,也能够起做到负载均衡的效果。以下是MySQLProxy的基本架构图:
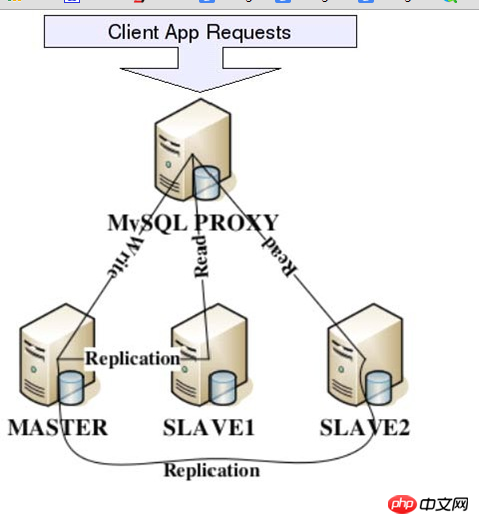
通过上面的架构简图。我们能够非常清晰的看出MySQLProxy在实际应用中所处的位置,以及能做的基本事情。
关于MySQLProxy更为具体的实施细则在MySQL官方文档中有非常具体的介绍和演示样例。感兴趣的读者朋友能够直接从MySQL官方站点免费下载或者在线阅读,我这里就不累述浪费纸张了。
★利用Amoeba实现数据切分及整合
Amoeba是一個基於Java開發的,專注於解決分散式資料庫資料來源整合Proxy程式的開源框架,基於GPL3開源協定。眼下,Amoeba已經有Query路由,Query過濾,讀寫分離,負載平衡以及HA機制等相關內容。
Amoeba 主要解決的以下幾個問題:
1. 資料切分後複雜資料來源整合;
2. 提供資料切分規則並降低資料切分規則給資料庫帶來的影響。
3. 降低資料庫與client的連線數。
4. 讀寫分離路由;
我們能夠看出,Amoeba所做的事情,正好就是我們透過資料切分來提升資料庫的擴充性所須要的。
Amoeba並非一個代理層的Proxy程序,而是一個開發資料庫代理層Proxy程序的開發框架,眼下基於Amoeba所開發的Proxy程序有AmoebaForMySQL和AmoebaForAladin兩個。
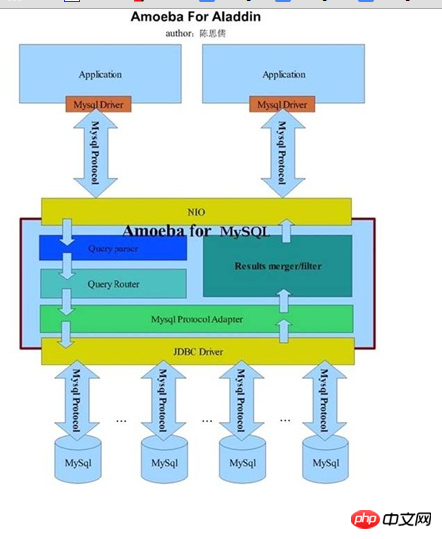
AmoebaForMySQL主要是專門針對MySQL資料庫的解決方式,前端應用程式所要求的協定以及後端連接的資料來源資料庫都必須是MySQL。對於client的不論什麼應用程式來說,AmoebaForMySQL和一個MySQL資料庫沒有什麼差別。不論什麼使用MySQL協定的client請求,都能夠被AmoebaForMySQL解析並進行對應的處理。下如能夠告訴我們AmoebaForMySQL的架構資訊(來自Amoeba開發人員部落格):
AmoebaForAladin則是一個適用更為廣泛。功能更為強大的Proxy程式。
他能夠在同一時候連接不同資料庫的資料來源為前端應用程式提供服務,可是僅接受符合MySQL協定的client應用程式請求。也就是說,僅僅要前端應用程式透過MySQL協定連接上來之後,AmoebaForAladin會自己主動分析Query語句,依據Query語句中所請求的資料來自己主動辨識出該所Query的資料來源是在什麼類型資料庫的哪一個實體主機上面。下圖展示了AmoebaForAladin的架構細節(出自Amoeba開發人員部落格):
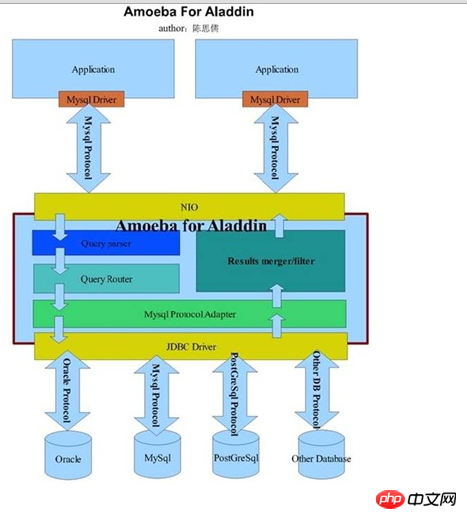
咋一看,兩者好像全然一樣嘛。細看之後,才會發現兩者主要的差異僅在於透過MySQLProtocalAdapter處理之後。依據分析結果推斷出資料來源資料庫。然後選擇特定的JDBC驅動和對應協定連接後端資料庫。
事實上透過上面兩個架構圖大家可能也已經發現了Amoeba的特色了,他只是一個開發框架。我們除了選擇他已經提供的ForMySQL和ForAladin這兩款產品之外。也能夠基於自身的需求進行對應的二次開發。得到更適應我們自己應用特點的Proxy程式。
當對於使用MySQL資料庫。不論是AmoebaForMySQL還是AmoebaForAladin都能夠非常好的使用。當然,考慮到不論什麼一個系統越是複雜,其效能肯定就會有一定的損失,維護成本自然也會相對更高一些。所以,對於僅僅要使用MySQL資料庫的時候,我還是建議使用AmoebaForMySQL。
AmoebaForMySQL的使用非常簡單,全部的設定檔都是標準的XML文件,總是共同擁有四個設定檔。分別為:
◆ amoeba.xml:主設定文件,配置全部資料來源以及Amoeba本身的參數設定。
◆ rule.xml:設定全部Query路由規則的資訊。
◆ functionMap.xml:設定用於解析Query中的函數所對應的Java實作類別;
◆ rullFunctionMap.xml:設定路由規則中必須使用到的特定函數的實作類;
假設您的規則不是太複雜,基本上只要使用到上面四個檔案裡的前面兩個就可完成全部工作。 Proxy程式常用的功能如讀寫分離。負載平衡等配置都在amoeba.xml中進行。另外。 Amoeba已經支援了實現數據的垂直切分和水平切分的自己主動路由。路由規則能夠在rule.xml進行設定。
眼下Amoeba少有欠缺的主要是其線上管理功能以及對事務的支持了,以前在與相關開發人員的溝通過程中提出過相關的建議,希望能夠提供一個能夠進行在線維護管理的命令列管理工具,方便線上維護使用,得到的回饋是管理專門的管理模組已經納入開發日程了。另外在事務支援方面臨時還是Amoeba無法做到的,即使client應用程式在提交給Amoeba的請求是包含事務資訊的,Amoeba也會忽略事務相關資訊。當然,在經過不斷完好之後,我相信事務支援肯定是Amoeba重點考慮添加的feature。
关于Amoeba更为具体的用法读者朋友能够通过Amoeba开发人员博客(http://amoeba.sf.net)上面提供的使用手冊获取,这里就不再细述了。
★利用HiveDB实现数据切分及整合
和前面的MySQLProxy以及Amoeba一样,HiveDB相同是一个基于Java针对MySQL数据库的提供数据切分及整合的开源框架,仅仅是眼下的HiveDB仅仅支持数据的水平切分。
主要解决大数据量下数据库的扩展性及数据的高性能訪问问题,同一时候支持数据的冗余及主要的HA机制。
HiveDB的实现机制与MySQLProxy和Amoeba有一定的差异,他并非借助MySQL的Replication功能来实现数据的冗余,而是自行实现了数据冗余机制,而其底层主要是基于HibernateShards来实现的数据切分工作。
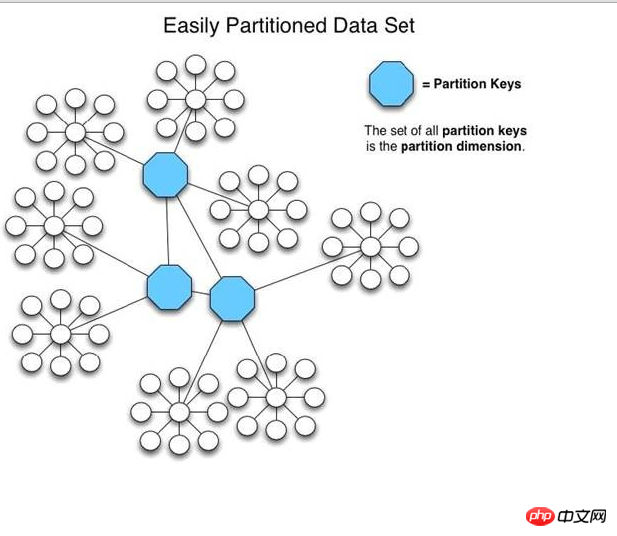
在HiveDB中,通过用户自己定义的各种Partitionkeys(事实上就是制定数据切分规则),将数据分散到多个MySQLServer中。在訪问的时候。在执行Query请求的时候。会自己主动分析过滤条件,并行从多个MySQLServer中读取数据,并合并结果集返回给client应用程序。
单纯从功能方面来讲,HiveDB可能并不如MySQLProxy和Amoeba那样强大,可是其数据切分的思路与前面二者并无本质差异。此外,HiveDB并不仅仅仅仅是一个开源爱好者所共享的内容,而是存在商业公司支持的开源项目。
以下是HiveDB官方站点上面一章图片,描写叙述了HiveDB怎样来组织数据的基本信息,尽管不能具体的表现出太多架构方面的信息,可是也基本能够展示出其在数据切分方面独特的一面了。
★ mycat 数据整合:具体http://www.songwie.com/articlelist/11
★ 其它实现数据切分及整合的解决方式
除了上面介绍的几个数据切分及整合的总体解决方式之外,还存在非常多其它相同提供了数据切分与整合的解决方式。如基于MySQLProxy的基础上做了进一步扩展的HSCALE,通过Rails构建的SpockProxy。以及基于Pathon的Pyshards等等。
无论大家选择使用哪一种解决方式,总体设计思路基本上都不应该会有不论什么变化。那就是通过数据的垂直和水平切分,增强数据库的总体服务能力,让应用系统的总体扩展能力尽可能的提升。扩展方式尽可能的便捷。
仅仅要我们通过中间层Proxy应用程序较好的攻克了数据切分和数据源整合问题。那么数据库的线性扩展能力将非常easy做到像我们的应用程序一样方便。仅仅须要通过加入便宜的PCServerserver,就可以线性添加数据库集群的总体服务能力,让数据库不再轻易成为应用系统的性能瓶颈。
数据切分与整合可能存在的问题
这里。大家应该对数据切分与整合的实施有了一定的认识了。也许非常多读者朋友都已经依据各种解决方式各自特性的优劣基本选定了适合于自己应用场景的方案,后面的工作主要就是实施准备了。
在实施数据切分方案之前,有些可能存在的问题我们还是须要做一些分析的。
一般来说,我们可能遇到的问题主要会有以下几点:
◆ 引入分布式事务的问题。
◆ 跨节点Join的问题;
◆ 跨节点合并排序分页问题。
1. 引入分布式事务的问题
一旦数据进行切分被分别存放在多个MySQLServer中之后,无论我们的切分规则设计的多么的完美(实际上并不存在完美的切分规则),都可能造成之前的某些事务所涉及到的数据已经不在同一个MySQLServer中了。
在这样的场景下,假设我们的应用程序仍然依照老的解决方式。那么势必须要引入分布式事务来解决。而在MySQL各个版本号中,仅仅有从MySQL5.0開始以后的各个版本号才開始对分布式事务提供支持,并且眼下仅有Innodb提供分布式事务支持。不仅如此。即使我们刚好使用了支持分布式事务的MySQL版本号。同一时候也是使用的Innodb存储引擎,分布式事务本身对于系统资源的消耗就是非常大的,性能本身也并非太高。并且引入分布式事务本身在异常处理方面就会带来较多比較难控制的因素。
怎麼辦?事實上我們能夠透過一個變通的方法來解決這樣的問題。首先要考慮的一件事情就是:是否資料庫是唯一一個能夠解決事務的地方呢?事實上並非這樣的,我們全然能夠結合資料庫以及應用程式兩者來共同解決。各個資料庫解決自己身上的事務。然後透過應用程式來控制多個資料庫上面的事務。
也就是說。僅僅要我們願意。全然能夠將一個跨多個資料庫的分散式交易分拆成多個僅處於單一資料庫上面的小事務。並透過應用程式來總控各個小事務。
當然,這樣做的要求是我們的俄羅斯應用程式必須要有足夠的健全性。當然也會為應用程式帶來一些技術難度。
2.跨節點Join的問題
上面介紹了可能引入分散式事務的問題,如今我們再看看須要跨節點Join的問題。
資料切分之後。可能會造成有些老的Join語句無法繼續使用。由於Join所使用的資料來源可能被切分到多個MySQLServer中了。
怎麼辦?這個問題從MySQL資料庫角度來看,假設非得在資料庫端來直接解決的話,恐怕僅僅能透過MySQL一種特殊的儲存引擎Federated來攻克了。 Federated儲存引擎是MySQL解決相似於Oracle的DBLink之類問題的解決方式。
與OracleDBLink的主要差異在於Federated會保存一份遠端表結構的定義資訊在本地。咋一看,Federated確實是解決跨節點Join非常好的解決方法。可是我們還要清晰一點,那就似乎假設遠端的表結構發生了變更,本地的表定義資訊是不會跟著發生對應變化的。假設在更新遠端表結構的時候並沒有更新本地的Federated表定義資訊。就非常可能造成Query執行出錯,無法得到正確的結果。
處理這類問題,我還是推薦透過應用程式來處理,先在驅動表所在的MySQLServer中取出對應的驅動程式結果集。然後依據驅動結果集再到被驅動表所在的MySQLServer中取出對應的資料。可能非常多讀者朋友會覺得這樣做對性能會產生一定的影響,是的,確實是會對性能有一定的負面影響,可是除了此法,基本上沒有太多其它更好的解決的方法了。
並且,由於資料庫經過較好的擴充功能之後,每台MySQLServer的負載就能夠得到較好的控制。單純針對單條Query來說,其反應時間可能比不切分之前要提升一些,所以效能方面所帶來的負面影響也並非太大。更何況。相似於這樣的須要跨節點Join的需求也並非太多。相對於整體性能而言,可能也只是非常小一部分而已。所以為了整體表現的考慮,偶爾犧牲那麼一點點。事實上是值得的。畢竟系統優化本身就是存在著非常多取捨和平衡的過程。
3. 跨節點合併排序分頁問題
一旦進行了資料的水平切分之後,可能就不僅僅僅僅有跨節點Join無法正常執行,有些排序分頁的Query語句的資料來源可能也會被切分到多個節點。這樣造成的直接後果就是這些排序分頁Query無法繼續正常執行。事實上這和跨節點Join是一個道理。資料來源存在於多個節點上,要透過一個Query來解決,就和跨節點Join是一樣的操作。相同Federated也能夠部分解決。當然存在的風險也一樣。
還是相同的問題,該怎麼辦?我相同仍然繼續建議透過應用程式來解決。
怎麼解決?解決的思路大致上和跨節點Join的解決相似,可是有一點和跨節點Join不太一樣。 Join非常多時候都有一個驅動與被驅動的關係。所以Join本身牽涉到的多個表之間的資料讀取一般都會存在一個順序關係。可是排序分頁就不太一樣了,排序分頁的資料來源基本上能夠說是一個表(或一個結果集)。本身並不存在一個順序關係,所以在從多個資料來源取資料的過程是全然能夠並行的。
這樣。排序分頁資料的取數效率我們所能做的比跨庫Join更高。所以帶來的效能損失相對的要更小,在有些情況下可能比在原來未進行資料切分的資料庫中效率更高了。
當然,無論是跨節點Join或跨節點排序分頁。都會使我們的應用server消耗許多其它的資源,尤其是記憶體資源,由於我們在讀取訪問以及合併結果集的這個過程須要比原來處理很多其它的資料。
After analyzing this point, many readers may find that all the above problems are basically solved through applications. Everyone may be starting to murmur in their hearts. Is it because I am a DBA that I leave a lot of things to the application architects and developers?
In fact, this is not the case at all. First of all, the application is due to its particularity. It is very easy to achieve very good scalability, but the database is different. Expansion must be achieved in many other ways. And in this expansion process, it is very difficult to avoid situations that can be solved in a centralized database but become a difficult problem after being split into a database cluster.
To maximize the overall system expansion, we can only allow the application to do many other things. To solve problems that cannot be solved well by database clusters.
Summary
Use data segmentation technology to split a large MySQLServer into multiple small MySQLServers, which not only overcomes the write performance bottleneck problem, but also once again improves the entire database cluster. scalability. Whether through vertical segmentation or horizontal segmentation. All can make the system less likely to encounter bottlenecks. Especially when we use a combination of vertical and horizontal slicing methods, theoretically we will no longer encounter expansion bottlenecks.
Related recommendations:
Mysql database sub-database and sub-table methods (commonly used)_MySQL
mysql master-slave database, sub-database sub-database Table and other notes_MySQL
##Old boy mysql video:MySQL database multi-instance startup problem troubleshooting method and practical troubleshooting
以上是mysql資料庫分庫分錶技術難點解決策略的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 與MySQL中使用索引相比,全表掃描何時可以更快?
Apr 09, 2025 am 12:05 AM
與MySQL中使用索引相比,全表掃描何時可以更快?
Apr 09, 2025 am 12:05 AM
全表掃描在MySQL中可能比使用索引更快,具體情況包括:1)數據量較小時;2)查詢返回大量數據時;3)索引列不具備高選擇性時;4)複雜查詢時。通過分析查詢計劃、優化索引、避免過度索引和定期維護表,可以在實際應用中做出最優選擇。
 說明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
說明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
InnoDB的全文搜索功能非常强大,能够显著提高数据库查询效率和处理大量文本数据的能力。1)InnoDB通过倒排索引实现全文搜索,支持基本和高级搜索查询。2)使用MATCH和AGAINST关键字进行搜索,支持布尔模式和短语搜索。3)优化方法包括使用分词技术、定期重建索引和调整缓存大小,以提升性能和准确性。
 可以在 Windows 7 上安裝 mysql 嗎
Apr 08, 2025 pm 03:21 PM
可以在 Windows 7 上安裝 mysql 嗎
Apr 08, 2025 pm 03:21 PM
是的,可以在 Windows 7 上安裝 MySQL,雖然微軟已停止支持 Windows 7,但 MySQL 仍兼容它。不過,安裝過程中需要注意以下幾點:下載適用於 Windows 的 MySQL 安裝程序。選擇合適的 MySQL 版本(社區版或企業版)。安裝過程中選擇適當的安裝目錄和字符集。設置 root 用戶密碼,並妥善保管。連接數據庫進行測試。注意 Windows 7 上的兼容性問題和安全性問題,建議升級到受支持的操作系統。
 InnoDB中的聚類索引和非簇索引(次級索引)之間的差異。
Apr 02, 2025 pm 06:25 PM
InnoDB中的聚類索引和非簇索引(次級索引)之間的差異。
Apr 02, 2025 pm 06:25 PM
聚集索引和非聚集索引的區別在於:1.聚集索引將數據行存儲在索引結構中,適合按主鍵查詢和範圍查詢。 2.非聚集索引存儲索引鍵值和數據行的指針,適用於非主鍵列查詢。
 mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
mysql:簡單的概念,用於輕鬆學習
Apr 10, 2025 am 09:29 AM
MySQL是一個開源的關係型數據庫管理系統。 1)創建數據庫和表:使用CREATEDATABASE和CREATETABLE命令。 2)基本操作:INSERT、UPDATE、DELETE和SELECT。 3)高級操作:JOIN、子查詢和事務處理。 4)調試技巧:檢查語法、數據類型和權限。 5)優化建議:使用索引、避免SELECT*和使用事務。
 mysql用戶和數據庫的關係
Apr 08, 2025 pm 07:15 PM
mysql用戶和數據庫的關係
Apr 08, 2025 pm 07:15 PM
MySQL 數據庫中,用戶和數據庫的關係通過權限和表定義。用戶擁有用戶名和密碼,用於訪問數據庫。權限通過 GRANT 命令授予,而表由 CREATE TABLE 命令創建。要建立用戶和數據庫之間的關係,需創建數據庫、創建用戶,然後授予權限。
 mysql 和 mariadb 可以共存嗎
Apr 08, 2025 pm 02:27 PM
mysql 和 mariadb 可以共存嗎
Apr 08, 2025 pm 02:27 PM
MySQL 和 MariaDB 可以共存,但需要謹慎配置。關鍵在於為每個數據庫分配不同的端口號和數據目錄,並調整內存分配和緩存大小等參數。連接池、應用程序配置和版本差異也需要考慮,需要仔細測試和規劃以避免陷阱。在資源有限的情況下,同時運行兩個數據庫可能會導致性能問題。
 說明不同類型的MySQL索引(B樹,哈希,全文,空間)。
Apr 02, 2025 pm 07:05 PM
說明不同類型的MySQL索引(B樹,哈希,全文,空間)。
Apr 02, 2025 pm 07:05 PM
MySQL支持四種索引類型:B-Tree、Hash、Full-text和Spatial。 1.B-Tree索引適用於等值查找、範圍查詢和排序。 2.Hash索引適用於等值查找,但不支持範圍查詢和排序。 3.Full-text索引用於全文搜索,適合處理大量文本數據。 4.Spatial索引用於地理空間數據查詢,適用於GIS應用。
