

分析影響http效能的常見因素

本篇文章的主要內容是關於介紹影響HTTP效能的常見因素,具有一定的參考價值,有興趣的朋友可以了解一下。
我們在這裡討論HTTP效能是建立在一個最簡單模型之上就是單一伺服器的HTTP效能,當然對於大規模負載平衡叢集也適用畢竟這種叢集也是由多個HTTTP伺服器的個體所組成。另外我們也排除客戶端或伺服器本身負載過高或HTTP協定實現的軟體使用不同的IO模型,另外我們也忽略DNS解析過程和web應用程式開發本身的缺陷。
從TCP/IP模型來看,HTTP下層就是TCP層,所以HTTP的性能很大程度取決於TCP性能,當然如果是HTTPS的就還要加上TLS/SSL層,不過可以肯定的是HTTPS效能肯定比HTTP差,其通訊過程這裡都不多說總之層數越多效能損耗越嚴重。
在上述條件下,最常見的影響HTTP效能的包括:
TCP連線建立,也就是三次握手階段
#TCP慢啟動
TCP延遲確認
#Nagle演算法
- ##TIME_WAIT累積與連接埠耗盡
- 服務端連接埠耗盡
- 服務端HTTP程序開啟檔案數達到最大
1,在TCP剛建立好之後的最初傳輸階段會限制連線的最大傳輸速度,如果資料傳輸成功,後續會逐步提高傳輸速度,這就TCP慢啟動。慢啟動限制了某一時刻可以傳輸的IP分組2數量。那為什麼會有慢啟動呢?主要是為了避免網路因為大規模的資料傳輸而癱瘓,在互聯網上資料傳輸很重要的一個環節就是路由器,而路由器本身的速度並不快加之互聯網上的很多流量都可能發送過來要求其進行路由轉發,如果在某一時間內到達路由器的資料量遠大於其發送的數量那麼路由器在本地快取耗盡的情況下就會丟棄資料包,這種丟棄行為被稱作擁塞,一個路由器出現這種狀況就會影響很多條鏈路,嚴重的會導致大面積癱瘓。所以TCP通訊的任何一方需要進行擁塞控制,而慢啟動就是其中一種擁塞控制的演算法或叫做機制。 你設想一種情況,我們知道TCP有重傳機制,假設網路中的一個路由器因為擁塞而出現大面積丟包情況,作為數據的發送方其TCP協議棧肯定會檢測到這種情況,那麼它就會啟動TCP重傳機制,而且該路由器影響的發送方肯定不止你一個,那麼大量的發送方TCP協議棧都開始了重傳那這就等於在原本擁塞的網絡上發送更多的數據包,這等於火上澆油。
確認報文通常都比較小,也就是一個IP分組可以承載多個確認報文,所以為了避免過多的發送小報文,那麼接收方在回傳確認報文的時候會等待看看有沒有發給接收方的其他數據,如果有那麼就把確認報文和數據一起放在一個TCP分段中發送過去,如果在一定時間內容通常是100-200毫秒沒有需要發送的其他數據那麼就將該確認訊息放在單獨的分組中發送。其實這麼做的目的也是為了盡量降低網路負擔。
一個通俗的例子就是物流,卡車的載重是一定的,假如是10噸載重,從A城市到B城市,你肯定希望它能盡可能的裝滿一車貨而不是來了一個小包裹你就立刻起身開向B城市。
所以TCP被設計成不是來一個資料包就馬上回傳ACK確認,它通常都會在快取中積攢一段時間,如果還有相同方向的資料就捎帶把前面的ACK確認回傳過去,但是也不能等的時間過長否則對方會認為丟包了從而引發對方的重傳。
對於是否使用以及如何使用延遲確認不同作業系統會有不同,例如Linux可以啟用也可以關閉,關閉就意味著來一個就確認一個,這也是快速確認模式。
要注意的是是否啟用或說設定多少毫秒,也要看場景。例如線上遊戲場景下一定是盡快確認,SSH會話可以使用延遲確認。
對於HTTP來說我們可以關閉或調整TCP延遲確認。
Nagle演算法
這個演算法其實也是為了提高IP分組利用率以及降低網路負擔而設計,這裡面依然涉及到小報文和全尺寸報文(按乙太網路的標準MTU1500位元組一個的報文計算,小於1500的都算非全尺寸報文),但是無論小報文怎麼小也不會小於40個字節,因為IP首部和TCP首部就各佔用20個字節。如果你發送一個50個位元組小報文,其實這意味著有效資料太少,就像延遲確認一樣小尺寸包在區域網路問題不大,主要是影響廣域網路。
這個演算法其實就是如果發送方目前TCP連線中有發出去但還沒有收到確認的報文的時候,那麼此時如果發送方還有小報文要發送的話就不能發送而是要放到緩衝區等待之前發出報文的確認,收到確認之後,發送方會收集快取中同方向的小報文組裝成一個報文進行發送。其實這也意味著接收方回傳ACK確認的速度越快,發送方傳送資料也就越快。
現在我們說延遲確認和Nagle演算法結合將會帶來的問題。其實很容易看出,因為有延遲確認,那麼接收方則會在一段時間內積攢ACK確認,而發送方在這段時間內收不到ACK那麼也就不會繼續發送剩下的非全尺寸數據包(資料被分成多個IP分組,發送方要發送的回應資料的分組數量不可能一定是1500的整數倍,大概率會發生資料尾部的一些資料就是小尺寸IP分組),所以你就看出這裡的矛盾所在,那麼這種問題在TCP傳輸中會影響傳輸性能那麼HTTP又依賴TCP所以自然也會影響HTTP性能,通常我們會在伺服器端禁用該演算法,我們可以在作業系統上停用或在HTTP程式中設定TCP_NODELAY來停用該演算法。例如在Nginx中你可以使用tcp_nodelay on;來停用。
TIME_WAIT累積與連接埠耗盡3
這裡指的是作為客戶端的一方或是說是在TCP連線中主動關閉的一方,雖然伺服器也可以主動發起關閉,但是我們這裡討論的是HTTP效能,由於HTTP這種連線的特性,通常都是客戶端發起主動關閉,
客戶端發起一個HTTP請求(這裡說的是對一個特定資源的請求而不是打開一個所謂的主頁,一個主頁有N多資源所以會導致有N個HTTP請求的發起)這個請求結束後就會斷開TCP連接,那麼該連接在客戶端上的TCP狀態會出現一種叫做TIME_WAIT的狀態,從這個狀態到最終關閉通常會經過2MSL4的時長,我們知道客戶端存取服務端的HTTP服務會使用自己本機隨機高位連接埠來連接伺服器的80或者443端口來建立HTTP通信(其本質就是TCP通信)這意味著會消耗客戶端上的可用端口數量,雖然客戶端斷開連接會釋放這個隨機端口,不過客戶端主動斷開連接後,TCP狀態從TIME_WAIT到真正CLOSED之間的這2MSL時長內,該隨機端口不會被使用(如果客戶端又發起對相同伺服器的HTTP存取),其目的之一是為了防止相同TCP套接字上的髒數據。透過上面的結論我們就知道如果客戶端對伺服器的HTTP存取過於密集那麼就有可能出現連接埠使用速度高於連接埠釋放速度最終導致因沒有可用隨機連接埠而無法建立連線。
上面我們說過通常都是客戶端主動關閉連接,
TCP/IP詳解卷1 第二版,P442,最後的一段寫到對於互動式應用程式而言,客戶端通常執行主動關閉操作並進入TIME_WAIT狀態,伺服器通常執行被動關閉操作並且不會直接進入TIME_WAIT狀態。
不過如果web伺服器並且開啟了keep-alive的話,當達到超時時長伺服器也會主動關閉。 (我這裡並不是說TCP/IP詳解錯了,而是它在那一節主要是針對TCP來說,並沒有引入HTTP,而且它說的是通常而不是一定)
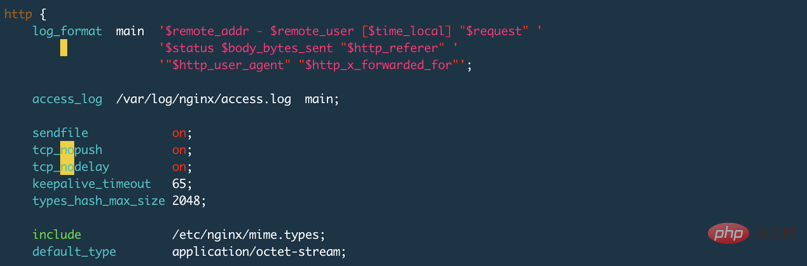
#我使用Nginx做測試,並且在設定檔中設定了keepalive_timeout 65s;,Nginx的預設設定是75s,設定為0表示停用keepalive,如下圖:
下面我使用Chrom瀏覽器存取這個Nginx預設提供的主頁,並透過抓包程式來監控整個通訊過程,如下圖:
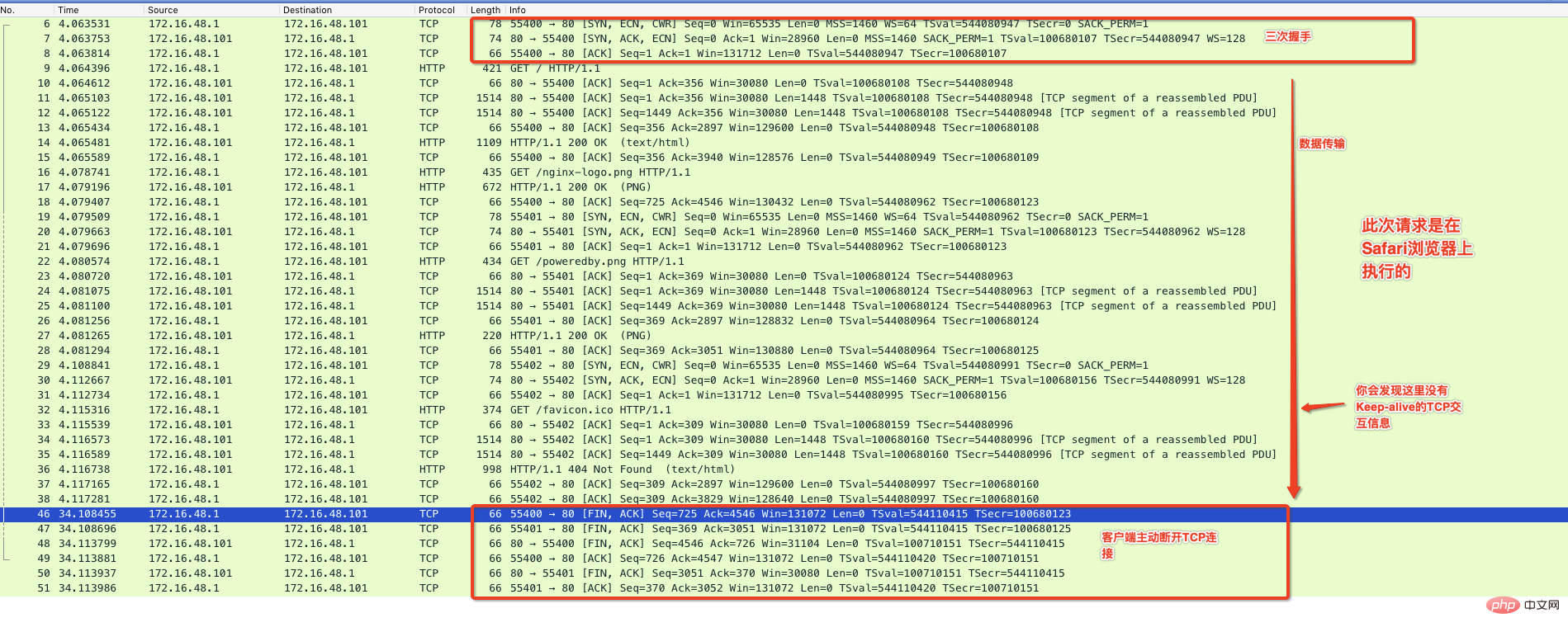
從上圖可以看出來在有效資料傳送完畢後,中間出現了Keep-Alive標記的通信,並且在65秒內沒有請求後伺服器主動斷開連接,這種情況你在Nginx的伺服器上就會看到TIME_WAIT的狀態。
服務端連接埠耗盡
有人說Nginx監聽80或443,客戶端都是連接這個連接埠,服務端怎麼會連接埠耗盡呢?就像下圖一樣(忽略圖中的TIME_WAIT,產生這個的原因上面已經說過了是因為Nginx的keepalive_timeout設定導致的)
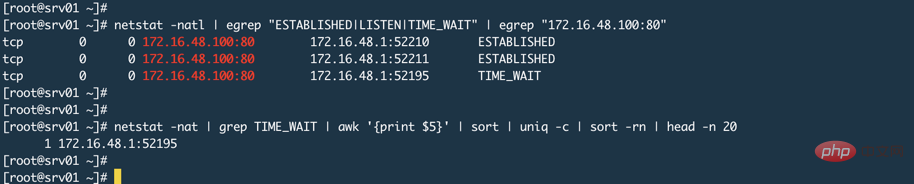
其實,這取決於Nginx工作模式,我們使用Nginx通常都是讓其工作在代理模式,這意味著真正的資源或資料在後端Web應用程式上,例如Tomcat。代理模式的特徵是代理伺服器取代使用者去後端取得數據,那麼此時相對於後端伺服器來說,Nginx就是一個客戶端,這時候Nginx就會使用隨機連接埠來向後端發起請求,而係統可用隨機連接埠範圍是一定的,可以使用sysctl net.ipv4.ip_local_port_range指令來查看伺服器上的隨機連接埠範圍。
透過我們先前介紹的延遲確認、Nagle演算法以及代理模式下Nginx充當後端的客戶端角色並使用隨機連接埠連接後端,這意味著服務端的連接埠耗盡風險是存在的。隨機連接埠釋放速度如果比與後端建立連線的速度慢就有可能出現。不過通常不會出現這個情況,至少我們公司的Nginx我沒有發現有這種現象產生。因為首先是靜態資源都在CDN上;其次後端大部分都是REST介面提供使用者認證或資料庫操作,這些操作其實後端如果沒有瓶頸的話基本上都很快。不過話說回來如果後端真的有瓶頸且擴容或者改架構成本比較高的話,那麼當面對大量並發的時候你應該做的是限流防止後端被打死。
服務端HTTP進程打開檔案數量達到最大
我們說過HTTP通訊依賴TCP連接,一個TCP連接就是一個套接字,對於類別Unix系統來說,打開一個套接字就是打開一個文件,如果有100個請求連接服務端,那麼一旦連接建立成功服務端就會打開100個文件,而Linux系統中一個進程可以打開的文件數量是有限的ulimit -f,所以如果這個數值設定的太小那麼也會影響HTTP連線。而對於以代理模式運行的Nginx或其他HTTP程式來說,通常一個連接它就要打開2個套接字也會佔用2個檔案(命中Nginx本地快取或Nginx直接回傳資料的除外)。所以對於代理伺服器這個進程可開啟的檔案數量也要設定的大一點。
持久連結Keepalive
首先我們要知道keepalive可以設定在2個層面上,且2個層面意義不同。 TCP的keepalive是一種探活機制,例如我們常說的心跳訊息,表示對方還在線,而這種心跳訊息的發送由有時間間隔的,這意味著彼此的TCP連線要始終保持開啟狀態;而HTTP中的keep-alive是一種複用TCP連線的機制,避免頻繁建立TCP連線。 所以一定明白TCP的Keepalive和HTTP的Keep-alive不是一回事。
HTTP的keep-alive機制
非持久連接會在每個HTTP事務完成後斷開TCP連接,下一個HTTP事務則會再重新建立TCP連接,這顯然不是一種高效機制,所以在HTTP/1.1以及HTTP/1.0的增強版本中允許HTTP在事務結束後將TCP連接保持打開狀態,以便後續的HTTP事務可以復用這個連接,直到客戶端或伺服器主動關閉該連接。持久連線減少了TCP連線建立的次數同時也最大化的規避了TCP慢啟動所帶來的流量限制。
相關教學:HTTP影片教學

再來看這張圖,圖中的keepalive_timeout 65s設定了開啟http的keep-alive特性並且設定了逾時時長為65秒,其實還有比較重要的選項是keepalive_requests 100;它表示同一個TCP連線最多可以發起多少個HTTP請求,預設是100個。
在HTTP/1.0中keep-alive並不是預設使用的,客戶端發送HTTP請求時必須帶有Connection: Keep-alive的首部來試圖啟動keep-alive,如果伺服器不支援那麼將無法使用,所有請求將以常規形式進行,如果伺服器支援那麼在回應頭中也會包含Connection: Keep-alive的資訊。
在HTTP/1.1中預設就使用Keep-alive,除非特別說明,否則所有連線都是持久的。如果要在一個交易結束後關閉連接,那麼HTTP的回應頭中必須包含Connection: CLose首部,否則該連接會始終保持打開狀態,當然也不能總是打開,也必須關閉空閒連接,就像上面Nginx的設定一樣最多保持65秒的空閒連接,超過後服務端將會主動斷開該連接。
TCP的keepalive
在Linux上沒有一個統一的開關去開啟或關閉TCP的Keepalive功能,查看系統keepalive的設定sysctl -a | grep tcp_keepalive,如果你沒有修改過,那麼在Centos系統上它會顯示:
net.ipv4.tcp_keepalive_intvl = 75 # 两次探测直接间隔多少秒 net.ipv4.tcp_keepalive_probes = 9 # 探测频率 net.ipv4.tcp_keepalive_time = 7200 # 表示多长时间进行一次探测,单位秒,这里也就是2小时
按照默認設置,那麼上面的整體含義就是2小時探測一次,如果第一次探測失敗,那麼過75秒再探測一次,如果9次都失敗就主動斷開連線。
如何開啟Nginx上的TCP層面的Keepalive,在Nginx中有一個語句叫做listen它是server段裡面用來設定Nginx監聽在哪個埠的語句,其實它後面還有其他參數就是用來設定套接字屬性的,看下面幾種設定:
# 表示开启,TCP的keepalive参数使用系统默认的 listen 80 default_server so_keepalive=on; # 表示显式关闭TCP的keepalive listen 80 default_server so_keepalive=off; # 表示开启,设置30分钟探测一次,探测间隔使用系统默认设置,总共探测10次,这里的设 # 置将会覆盖上面系统默认设置 listen 80 default_server so_keepalive=30m::10;
所以是否要在Nginx上設定這個so_keepalive,取決於特定場景,千萬不要把TCP的keepalive和HTTP的keepalive搞混淆,因為Nginx不開啟so_keepalive也不影響你的HTTP請求使用keep-alive特性。如果客戶端和Nginx直接或Nginx和後端伺服器之間有負載平衡設備的話而且是回應和請求都會經過這個負載平衡設備,那麼你就要注意這個so_keepalive了。例如在LVS的直接路由模式下就不受影響,因為回應不經過
LVS,不過要是NAT模式就需要留意,因為LVS保持TCP會話也有一個時長,如果該時長小於後端回傳資料的時長那麼LVS就會在客戶端還沒收到資料的情況下中斷這條TCP連線。
TCP擁塞控制有一些演算法,其中就包括TCP慢啟動、擁塞避免等演算法↩
有些地方也叫做IP分片但都是一個意思,至於為什麼分片簡單來說就是受限於資料鏈結層,不同的資料鏈路其MTU不同,乙太網路的是1500字節,在某些場景會是1492位元組;FDDI的MTU又是另一個大小,單純考慮IP層那麼IP封包最大是65535位元組↩
在《HTTP權威指南》P90頁中並沒有說的特別清楚,這種情況是相對於客戶端來說還是服務端,因為很有可能讓人誤解,當然並不是說服務端不會出現連接埠耗盡的情況,所以我這裡才增加了2項內容↩
最長不會超過2分鐘↩
相關教學:HTTP影片教學
以上是分析影響http效能的常見因素的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 http狀態碼520是什麼意思
Oct 13, 2023 pm 03:11 PM
http狀態碼520是什麼意思
Oct 13, 2023 pm 03:11 PM
http狀態碼520是指伺服器在處理請求時遇到了一個未知的錯誤,無法提供更具體的資訊。用於表示伺服器在處理請求時發生了一個未知的錯誤,可能是由於伺服器配置問題、網路問題或其他未知原因導致的。通常是由伺服器配置問題、網路問題、伺服器過載或程式碼錯誤等原因導致的。如果遇到狀態碼520錯誤,最好聯絡網站管理員或技術支援團隊以取得更多的資訊和協助。
 麒麟8000與驍龍處理器效能分析:細數強弱對比
Mar 24, 2024 pm 06:09 PM
麒麟8000與驍龍處理器效能分析:細數強弱對比
Mar 24, 2024 pm 06:09 PM
麒麟8000與驍龍處理器效能分析:細數強弱對比隨著智慧型手機的普及和功能不斷增強,處理器作為手機的核心組件也備受關注。目前市面上最常見且性能優異的處理器品牌之一就是華為的麒麟系列和高通的驍龍系列。本文將圍繞麒麟8000和驍龍處理器展開效能分析,探討兩者在各方面的強弱對比。首先,讓我們來了解一下麒麟8000處理器。作為華為公司最新推出的旗艦處理器,麒麟8000
 效能比較:Go語言與C語言的速度與效率
Mar 10, 2024 pm 02:30 PM
效能比較:Go語言與C語言的速度與效率
Mar 10, 2024 pm 02:30 PM
效能比較:Go語言與C語言的速度與效率在電腦程式設計領域,效能一直是開發者關注的重要指標。在選擇程式語言時,開發者通常會注意其速度和效率。 Go語言和C語言作為兩種流行的程式語言,被廣泛用於系統級程式設計和高效能應用。本文將比較Go語言和C語言在速度和效率方面的表現,並透過具體的程式碼範例來展示它們之間的差異。首先,我們來看看Go語言和C語言的概況。 Go語言是由G
 瞭解網頁重定向的常見應用場景並了解HTTP301狀態碼
Feb 18, 2024 pm 08:41 PM
瞭解網頁重定向的常見應用場景並了解HTTP301狀態碼
Feb 18, 2024 pm 08:41 PM
掌握HTTP301狀態碼的意思:網頁重定向的常見應用場景隨著網路的快速發展,人們對網頁互動的要求也越來越高。在網頁設計領域,網頁重定向是一種常見且重要的技術,透過HTTP301狀態碼來實現。本文將探討HTTP301狀態碼的意義以及在網頁重新導向中的常見應用場景。 HTTP301狀態碼是指永久重新導向(PermanentRedirect)。當伺服器接收到客戶端發
 HTTP 200 OK:了解成功回應的意義與用途
Dec 26, 2023 am 10:25 AM
HTTP 200 OK:了解成功回應的意義與用途
Dec 26, 2023 am 10:25 AM
HTTP狀態碼200:探索成功回應的意義與用途HTTP狀態碼是用來表示伺服器回應狀態的數字代碼。其中,狀態碼200表示請求已成功被伺服器處理。本文將探討HTTP狀態碼200的具體意義與用途。首先,讓我們來了解HTTP狀態碼的分類。狀態碼分為五個類別,分別是1xx、2xx、3xx、4xx和5xx。其中,2xx表示成功的回應。而200是2xx中最常見的狀態碼
 http請求415錯誤解決方法
Nov 14, 2023 am 10:49 AM
http請求415錯誤解決方法
Nov 14, 2023 am 10:49 AM
解決方法:1、檢查請求頭中的Content-Type;2、檢查請求體中的資料格式;3、使用適當的編碼格式;4、使用適當的請求方法;5、檢查伺服器端的支援。
 C#常見的網路通訊與安全性問題及解決方法
Oct 09, 2023 pm 09:21 PM
C#常見的網路通訊與安全性問題及解決方法
Oct 09, 2023 pm 09:21 PM
C#中常見的網路通訊和安全性問題及解決方法在當今互聯網時代,網路通訊已成為了軟體開發中必不可少的一部分。在C#中,我們通常會遇到一些網路通訊的問題,例如資料傳輸的安全性、網路連線的穩定性等。本文將針對C#中常見的網路通訊和安全性問題進行詳細討論,並提供相應的解決方法和程式碼範例。一、網路通訊問題網路連線中斷:網路通訊過程中,可能會出現網路連線的中斷,這會導致
 如何進行C++程式碼的效能分析?
Nov 02, 2023 pm 02:36 PM
如何進行C++程式碼的效能分析?
Nov 02, 2023 pm 02:36 PM
如何進行C++程式碼的效能分析?在開發C++程式時,效能是一個重要的考量。優化程式碼的效能可以提高程式的運行速度和效率。然而,想要優化程式碼,首先需要了解它的效能瓶頸在哪裡。而要找到效能瓶頸,首先需要進行程式碼的效能分析。本文將介紹一些常用的C++程式碼效能分析工具和技術,幫助開發者找到程式碼中的效能瓶頸,以便進行最佳化。使用Profiling工具Profiling工
