

python爬蟲可以爬影片嗎
Jun 19, 2019 am 10:16 AM
python
爬蟲
網路爬蟲又稱為網路蜘蛛,是指依照某種規則在網路上爬取所需內容的腳本程式。眾所周知,每個網頁通常包含其他網頁的入口,而網路爬蟲則透過一個網址依序進入其他網址取得所需內容。

爬蟲結構
爬蟲排程程序(程式的入口,用於啟動整個程式)
url管理員(用於管理未爬取得url及已經爬取過的url)
#網頁下載器(用於下載網頁內容用於分析)
網頁解析器(用於解析下載的網頁,取得新的url和所需內容)
網頁輸出器(用來把取得到的內容以檔案的形式輸出)
第一步
分析網頁原始碼。例如:http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97,右鍵查看源碼,一般影片都是mp4後綴,搜尋發現沒有,但是有的直接就能看到了例如美拍的影片。
相關推薦:《python影片教學》
第二步
抓包,分析請求和回傳。這個也可以透過強大的chrome實現,還是上面的例子,右鍵->審查元素->NetWork,然後F5刷新網頁
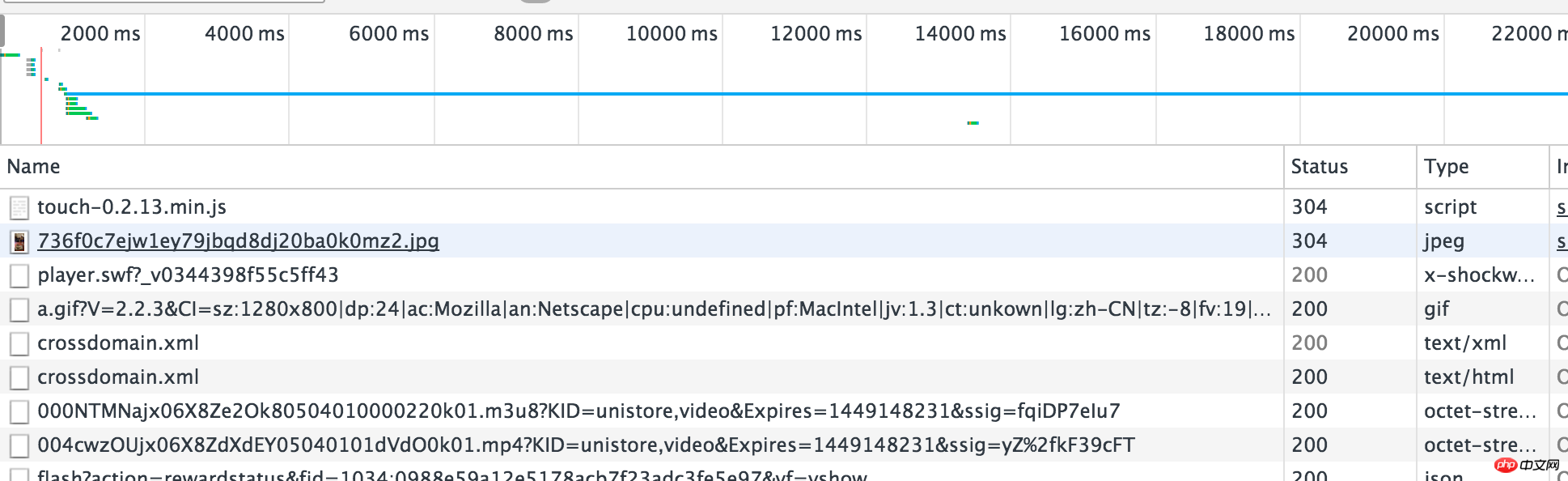
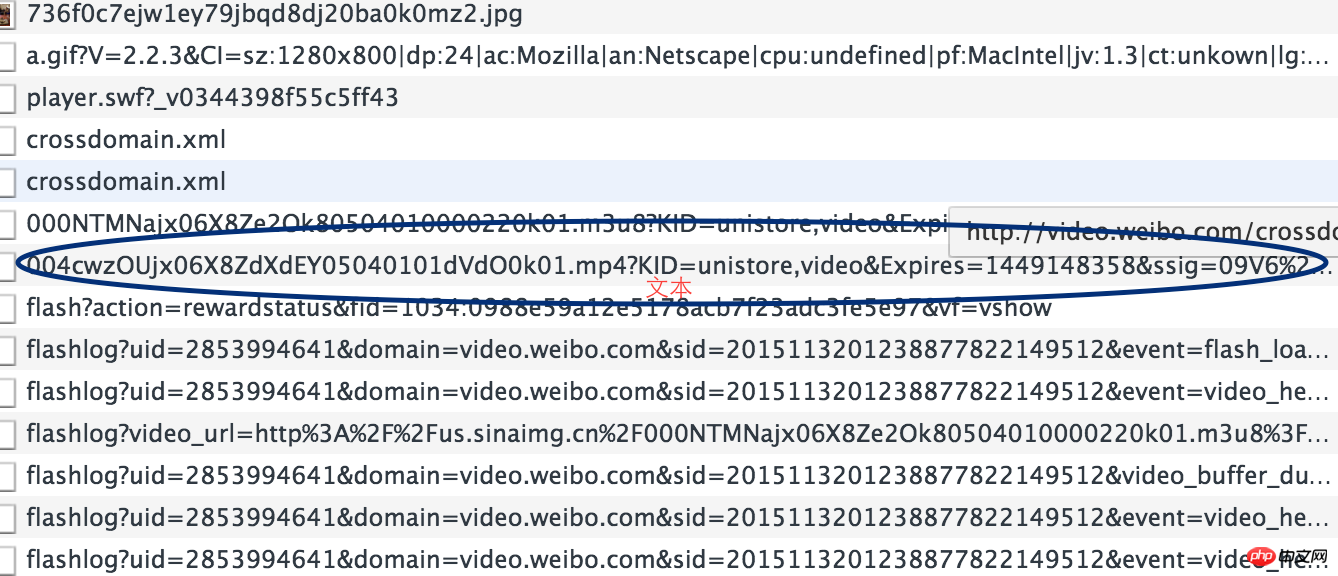
第三步驟
分析下載連結和影片連結的法則。即http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97與xxx.mp4的關係。這個又需要分析網頁源碼了,其實可以注意上面那個以.m3u8後綴的鏈接,m3u8記錄了一個索引純文本文件,打開它時播放軟體並不是播放它,而是根據它的索引找到對應的音視頻文件的網路位址進行線上播放,打開看,裡面確實記錄著我們想要的下載連結。而且.m3u8字尾的連結就在網頁源碼中。
總結
#經過前三個步驟的分析,取得影片下載連結的思路就是先從網頁源碼中獲取.m3u8後綴的鏈接,下載該文件,從裡面得到視頻下載鏈接,最後下載視頻就好了源碼
#coding=utf-8
import os
import re
import urllib2
import urllib
from common import Common
class SinaVideo():
URL_PIRFIX = "http://us.sinaimg.cn/"
def getM3u8(self,html):
reg = re.compile(r'list=([\s\S]*?)&fid')
result = reg.findall(html)
return result[0]
def getName(self,url):
return url.split('=')[1]
def getSinavideoUrl(self,filepath):
f = open(filepath,'r')
lines = f.readlines()
f.close()
for line in lines:
if line[0] !='#':
return line
def download(self,url,filepath):
#获取名称
name = self.getName(url)
html = Common.getHtml(url)
m3u8 = self.getM3u8(html)
Common.download(urllib.unquote(m3u8),filepath,name + '.m3u8')
url = self.URL_PIRFIX + self.getSinavideoUrl(filepath+name+'.m3u8')
Common.download(url,filepath,name+'.mp4')登入後複製
#common.py
#coding=utf-8
import urllib2
import os
import re
class Common():
# 获取网页源码
@staticmethod
def getHtml(url):
html = urllib2.urlopen(url).read()
print "[+]获取网页源码:"+url
return html
# 下载文件
@staticmethod
def download(url,filepath,filename):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'UTF-8,*;q=0.5',
'Accept-Encoding': 'gzip,deflate,sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.114 Mobile Safari/537.36'
}
request = urllib2.Request(url,headers = headers);
response = urllib2.urlopen(request)
path = filepath + filename
with open(path,'wb') as output:
while True:
buffer = response.read(1024*256);
if not buffer:
break
# received += len(buffer)
output.write(buffer)
print "[+]下载文件成功:"+path
@staticmethod
def isExist(filepath):
return os.path.exists(filepath)
@staticmethod
def createDir(filepath):
os.makedirs(filepath,0777)登入後複製
呼叫方式:
url = "http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97"sinavideo = SinaVideo() sinavideo.download(url,""/Users/cheng/Documents/PyScript/res/"")
登入後複製
結果:
##
以上是python爬蟲可以爬影片嗎的詳細內容。更多資訊請關注PHP中文網其他相關文章!
本網站聲明
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn

熱門文章
擊敗分裂小說需要多長時間?
3 週前
By DDD
倉庫:如何復興隊友
3 週前
By 尊渡假赌尊渡假赌尊渡假赌
Hello Kitty Island冒險:如何獲得巨型種子
3 週前
By 尊渡假赌尊渡假赌尊渡假赌
R.E.P.O.能量晶體解釋及其做什麼(黃色晶體)
1 週前
By 尊渡假赌尊渡假赌尊渡假赌
公眾號網頁更新緩存難題:如何避免版本更新後舊緩存影響用戶體驗?
3 週前
By 王林


熱門文章
擊敗分裂小說需要多長時間?
3 週前
By DDD
倉庫:如何復興隊友
3 週前
By 尊渡假赌尊渡假赌尊渡假赌
Hello Kitty Island冒險:如何獲得巨型種子
3 週前
By 尊渡假赌尊渡假赌尊渡假赌
R.E.P.O.能量晶體解釋及其做什麼(黃色晶體)
1 週前
By 尊渡假赌尊渡假赌尊渡假赌
公眾號網頁更新緩存難題:如何避免版本更新後舊緩存影響用戶體驗?
3 週前
By 王林

熱門文章標籤

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)





 Google AI 為開發者發佈 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
Google AI 為開發者發佈 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
Google AI 為開發者發佈 Gemini 1.5 Pro 和 Gemma 2
 只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3




