

python爬蟲需要安裝什麼


世界上80%的爬蟲是基於Python開發的,學好爬蟲技能,可為後續的大數據分析、挖掘、機器學習等提供重要的資料來源。
python爬蟲需要安裝相關庫:
python爬蟲涉及的庫:
請求庫,解析庫,存儲庫,工具庫
1. 請求庫:urllib/re/requests
(1) urllib/re是python預設自帶的函式庫,可以透過以下指令進行驗證:
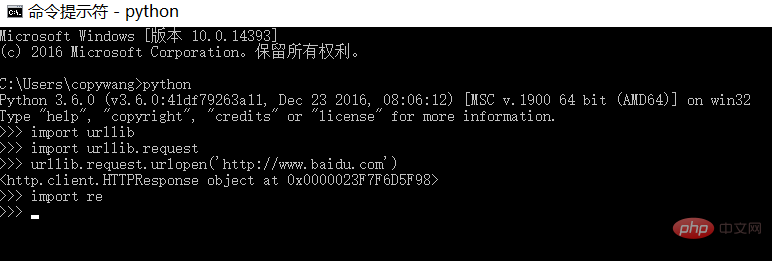
#沒有報錯訊息輸出,表示環境正常
(2) requests安裝
2.1 開啟CMD,輸入
pip3 install requests
2.2 等待安裝後,驗證

(3) selenium安裝(驅動瀏覽器進行網站存取行為)
3.1 開啟CMD,輸入
pip3 install selenium
3.2 安裝chromedriver
網址:https://npm.taobao.org/
把下載完成後的壓縮套件解壓縮,把exe放到D:\Python3.6.0\Scripts\
#這個路徑只要在PATH變數就可以
3.3 等待安裝完成後,驗證

回車後彈出chrome瀏覽器介面
3.4 安裝其他瀏覽器
無介面瀏覽器phantomjs
下載網址:http://phantomjs.org/
下載完成後解壓縮,把整個目錄放到D:\Python3.6.0\Scripts\,把bin目錄的路徑加入PATH變數
驗證:
開啟CMD
phantomjs console.log('phantomjs') CTRL+C python from selenium import webdriver driver = webdriver.PhantomJS() dirver.get('http://www.baidu.com') driver.page_source
2. 解析函式庫:
2.1 lxml (XPATH)
開啟CMD
pip3 install lxml
或從https://pypi.python.org下載,例如,lxml-4.1.1-cp36- cp36m-win_amd64.whl (md5) ,先下載whl檔案
pip3 install 文件名.whl
2.2 beautifulsoup
#開啟CMD,需要先安裝好lxml
pip3 install beautifulsoup4
驗證
python from bs4 import BeautifulSoup soup = BeautifulSoup('<html></html>','lxml')
#
pip3 install pyquery
python from pyquery import PyQuery as pq doc = pq('<html>hi</html>') result = doc('html').text() result
pip3 install pymysql
 3. 儲存庫3.1 pymysql(操作MySQL,關係型資料庫)#安裝:
3. 儲存庫3.1 pymysql(操作MySQL,關係型資料庫)#安裝:pip3 install pymongo
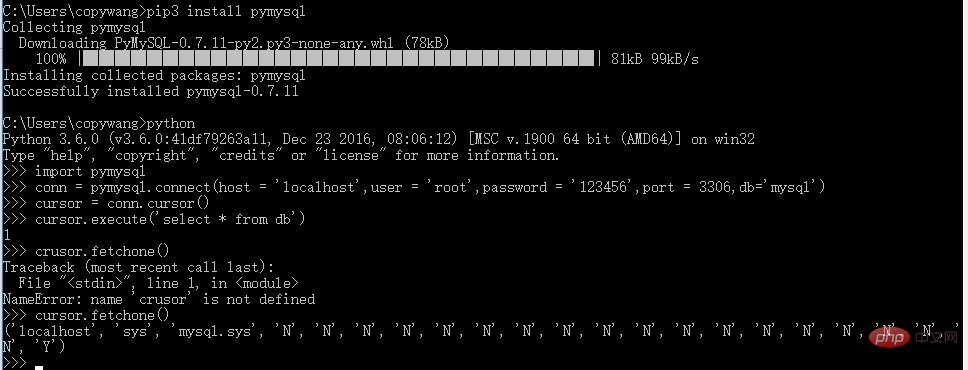
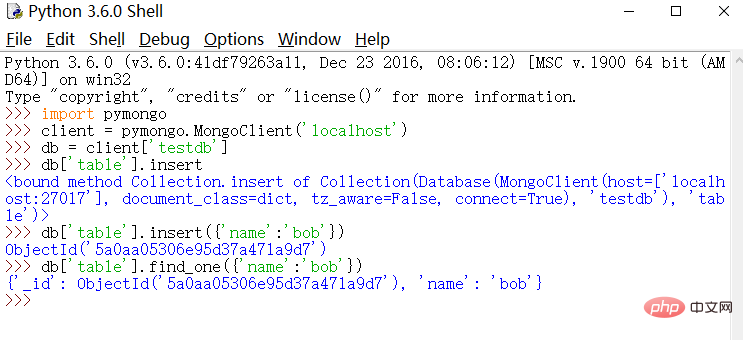
#
python
import pymongo
client = pymongo.MongoClient('localhost')
db = client['testdb']
db['table'].insert({'name':'bob'})
db['table'].find_one({'name':'bob'})#
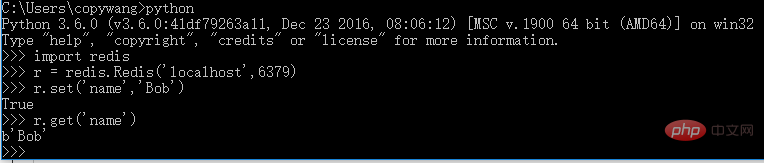
pip3 install redis
3.3 redis(分散式爬蟲,維護爬取佇列)
安裝:
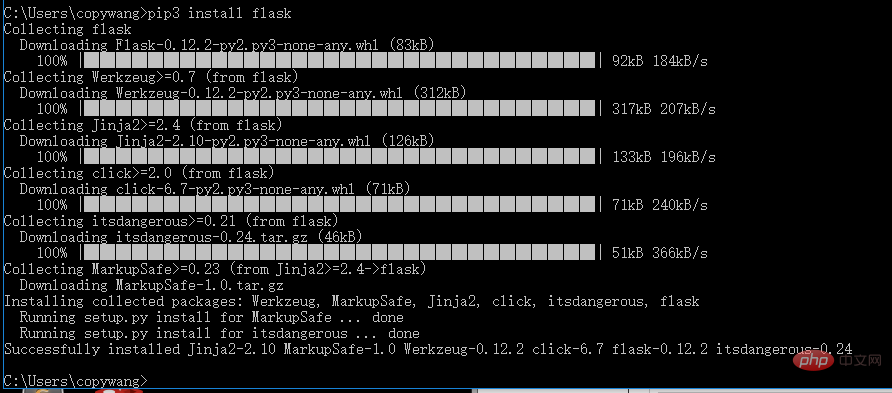
pip3 install flask
pip3 install django
pip3 install jupyter
jupyter notebook
以上是python爬蟲需要安裝什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
