

#程式設計師對雜湊演算法應該都不陌生,例如業界著名的MD5、SHA、 CRC等等;在日常開發中我們經常用一個Map來裝載一些具有(key,value)結構的數據,利用哈希算法O(1)的時間複雜度提高程序處理效率,除此之外,你還知道哈希演算法的其他應用場景嗎?
了解雜湊演算法的應用場景前,我們先看下雜湊(雜湊)想法,雜湊就是把任意長度的輸入透過雜湊演算法變換成固定長度的輸出,輸入稱為Key(鍵),輸出為Hash值,即雜湊值hash(key),雜湊演算法即hash()函數(雜湊與雜湊是對hash的不同翻譯);實際上儲存這些雜湊值的是一個數組,稱為散列表,散列表用的是數組支援按照下標隨機存取資料的特性,把資料值與數組下標按雜湊函數做的一一映射,從而實現O(1)的時間複雜度查詢;
目前的雜湊演算法MD5、SHA、CRC等都無法做到一個不同的key對應的雜湊值都不一樣的雜湊函數,即無法避免出現不同的key映射到同一個值的情況,即出現了雜湊衝突,而且,因為陣列的儲存空間有限,也會增加雜湊衝突的機率。如何解決散列衝突?我們常用的雜湊衝突解決方法有兩類:開放尋址法(open addressing) 和 鍊錶法(chaining)。
透過線性探測的方法找到散列表中空閒位置,寫入hash值:
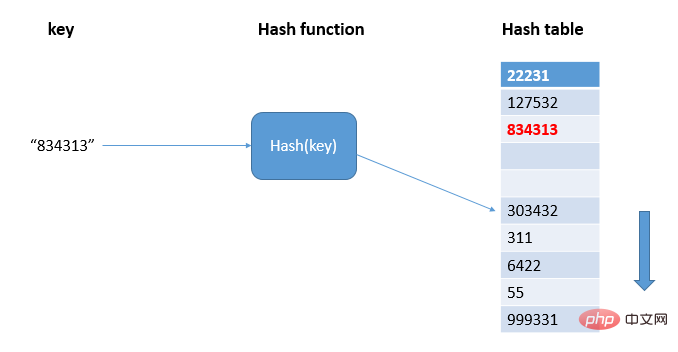
如圖,834313在hash表中散列到303432的位置上,出現了衝突,則順序遍歷hash表直到找到空閒位置寫入834313;當散列表中空閒位置不多的時候,散列衝突的機率就會大大增加,一般情況下,我們會盡可能保證散列衝突中有一定比例的空閒槽位,此時,我們用裝載因子來表示空閒位置的多少,計算公式是:散列表的裝載因子=填入表中的元素個數/散列表的長度。裝載因子越大,表示空閒位置越少,衝突越多,散列表的效能就會下降。
當資料量比較小,裝載因子小的時候,適合採用開放尋址法,這也是java中的ThreadLocalMap使用開放尋址法解決散列衝突的原因。
鍊錶法是一種較常用的雜湊衝突解決方法,也比較簡單。如圖:
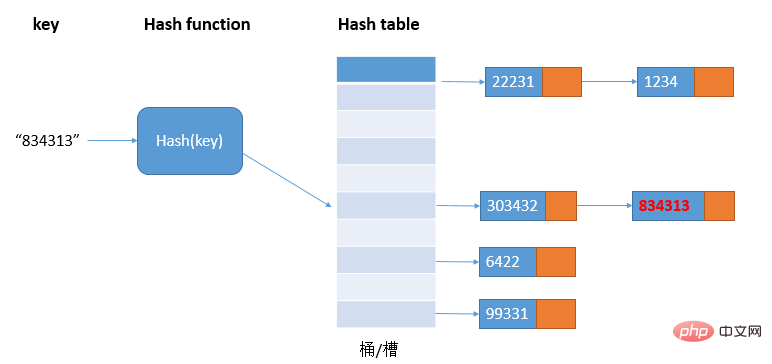
在散列表中,每個桶/槽會對應一條鍊錶,所有散列值相同的元素我們都放到相同槽位對應的鍊錶中;當雜湊衝突比較多時,鍊錶的長度也會變長,查詢hash值需要遍歷鍊錶,這時查詢效率就會從O(1)退化成O(n)。
這種解決散列衝突的處理方法比較適合大物件、大資料量的散列表,而且,支援更多的最佳化策略,例如使用紅黑樹來取代鍊錶;jdk1.8為了對HashMap做進一步優化,引入了紅黑樹,當鍊錶長度太長(預設超過8)時,鍊錶就會轉換成紅黑樹,這時可以利用紅黑樹快速增刪查改的特點,提高HashMap的性能,當紅黑樹節點個數小於8個時,又將紅黑樹轉換成為鍊錶,因為在資料量比較小的情況下,紅黑樹要維持平衡,比起鍊錶,效能上的優勢並不明顯。
最常用於加密的雜湊演算法是MD5(MD5 Message-Digest Algorithm)和SHA(Secure Hash Algorithm 安全雜湊演算法),利用hash的特徵計算出來的hash值很難反向推導出原始數據,從而達到加密的目的。
以MD5為例子,哈希值是固定的128位元二進位串,最多能表示2^128 個數據,這個數據已經是天文數字了,散列衝突的機率要小於1/2^ 128,如果希望透過窮舉法來找到跟這個MD5相同的另一個數據,那耗費的時間也應該是天文數字了,所以在有限的時間內哈希演算法還是很難被破解的,這也就達到了加密效果了。
利用Hash函數對資料敏感的特點,可以用來校驗網路傳輸過程中的資料是否正確,防止被惡意串改。
利用hash函數相對均勻分佈的特點,取hash值作為資料儲存的位置值,讓資料均勻分佈在容器裡面。
透過hash演算法,對客戶端id位址或會話id進行計算hash值,將取得的雜湊值與伺服器清單的大小進行取模運算,最終得到的值就是應該要路由到的伺服器編號。
假如我們有1T的日誌文件,裡面記錄了使用者的搜尋關鍵字,我們想要快速統計每個關鍵字被搜尋的次數,該怎麼做呢?資料量比較大,很難放到一台機的記憶體中,即使放到一台機子上,處理時間也會很長,針對這個問題,我們可以先對資料進行分片,然後再用多台機器處理的方法,來提高處理速度。
具體的想法是:為了提高處理速度,我們用n台機器並行處理。從搜尋記錄的日誌檔案中,依序獨處每個搜尋關鍵字,並透過雜湊函數計算哈希值,然後再跟n取模,最終得到的值,就是應該被分配到的機器編號;這樣哈希值相同的搜尋關鍵字就被分配到了同一台機器上,每個機器會分別計算關鍵字出現的次數,最後合併起來就是最終的結果。實際上,這裡的處理過程也是MapReduce的基本設計想法。
對於海量的資料需要快取的情況,一台快取機器肯定是不夠的,於是,我們就需要將資料分散在多台機器上。 這時,我們可以藉助前面的分片思想,也就是透過雜湊演算法對資料取哈希值,然後對機器個數取模,得到應該儲存的快取機器編號。
但是,如果資料增多,原來的10台機器已無法承受,需要擴容了,這時是如果所有資料都重新計算哈希值,然後重新搬移到正確的機器上,那就相當於所有的快取資料一下子都失效了,會穿透快取回源到資料庫,這樣就可能發生雪崩效應,壓垮資料庫。為了新增快取機器不搬移所有的數據,一致性雜湊演算法就是比較好的選擇了,主要的想法是:假設我們有kge機器,資料的雜湊值範圍是[0, Max],我們將整個範圍劃分成m個小區間(m遠大於k),每個機器負責m/k個小區間,當有新機器加入時,我們就將某幾個小區間的數據,從原來的機器中搬移到新的機器中,這樣,即不用全部重新哈希、搬移數據,也保持了各個機器上數據量的平衡。
實際上,哈希演算法還有很多其他的應用,例如git commit id等等,很多應用都來自於對演算法的理解和擴展,也是基礎的資料結構和演算法的價值體現,需要我們在工作中慢慢理解和體會。
推薦教學:《Java教學》
以上是常用演算法之哈希演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!
























