

在某些業務場景中,會使用NOT EXISTS語句確保傳回資料不存在於特定集合,部分同事會發現NOT EXISTS有些場景效能較差,甚至有些網路上謠言說”NOT EXISTS不走索引”,哪對於NOT EXISTS語句,我們如何最佳化呢?
以今天優化的SQL為例,優化前SQL為:
SELECT count(1) FROM t_monitor m WHERE NOT exists ( SELECT 1 FROM t_alarm_realtime AS a WHERE a.resource_id=m.resource_id AND a.resource_type=m.resource_type AND a.monitor_name=m.monitor_name)
我們使用LEFT JOIN方式進行最佳化,優化後SQL為:
SELECT count(1) FROM t_monitor m LEFT JOIN t_alarm_realtime AS a ON a.resource_id=m.resource_id AND a.resource_type=m.resource_type AND a.monitor_name=m.monitor_name WHERE a.resource_id is NULL
優化效果:
優化前執行時間29秒以上,優化後1.2秒,優化提升25倍。
NOT EXISTS真的不走索引麼?
查看兩種SQL的執行計劃!
使用NOT EXIST方式的執行計劃:
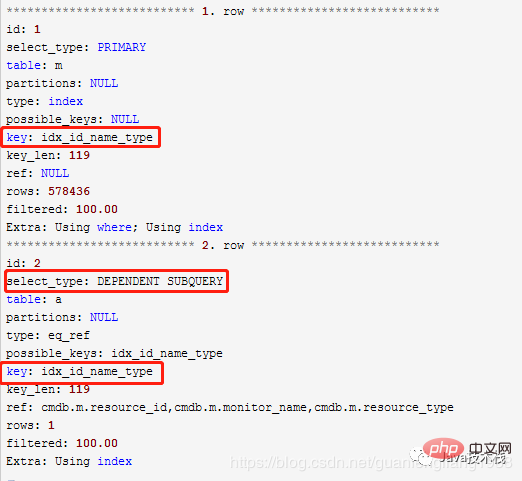
#使用LEFT JOIN方式的執行計劃:

從執行計劃來看,兩個表都使用了索引,差異在於NOT EXISTS使用「DEPENDENT SUBQUERY」方式,而LEFT JOIN使用普通表關聯的方式。
推薦看下:為什麼索引能提高查詢速度?
透過MySQL提供的Profiling方式來檢視兩種方式的執行過程。
使用NOT EXIST方式的執行程序:

使用LEFT JOIN方式的執行過程:

從執行過程來看,LEFT JOIN方式的主要消耗在Sending data一項上(1.2s),而NOT EXISTS方式主要消耗在executeing和Sending data兩項上,受限於Profiling只存放100行記錄緣故。
從Profiling只能看到47個」 executeing和Sending data」的組合項(每個組合項約50us),透過執行計畫看出,外表t_monitor的資料量為578436行,忽略統計資訊不准情況下,使用NOT EXISTS方式應該會產生578436個” executeing和Sending data”的組合項,總計消耗時間=50μs*578436=28921800us=28.92s。
從上面執行程序可以推斷出:
#使用NOT EXISTS方式的執行效能嚴重依賴NOT EXISTS子查詢的執行次數即外層查詢結果集的資料量。
當外層查詢結果集的資料量N較小時執行效能較好,如有N=10執行時間為50μs*10= 500us=0.005s,再加上一些額外消耗,執行結果也能在0.01秒或10毫秒內範圍,這個回應時間應該能被大部分應用程式接受。
當外層程勳結果集的資料量N較大甚至上千萬資料量時,NOT EXISTS的查詢效能會變得非常糟糕,甚至會大量消耗伺服器IO和CPU資源從而影響其他業務正常運作。
除上述問題外,在最佳化過程中發現本應儲存相同資料的resource_id列在兩個表中定義不同,一表為VARCHAR而另外一表為BIGINT,外部結果集的欄位類型和NOT EXIST字表中欄位類型不同導致NOT EXISTS子查詢中無法使用索引,使得子查詢效能較差,最終影響整個查詢的執行效能。
京東商城也曾出現過大量類似案例,有些表使用VARCHAR來存放訂單號,而另一些表使用BIGINT來存放,在兩表進行管理時性能極差,希望研發同事引以為戒。追蹤公眾號Java技術棧回覆m36取得一份MySQL研發軍規。
#相關學習推薦:mysql影片教學
以上是MySQL not exists 與索引的關係的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















