

相關學習推薦:python教學
#這是pandas資料處理專題的第二篇文章,我們一起來聊聊pandas當中最重要的資料結構-DataFrame。
上一篇文章當中我們介紹了Series的用法,也提到了Series相當於一個一維的數組,只是pandas為我們封裝了許多方便好用的api。而DataFrame可以簡單了理解成Series構成的dict,這樣就將資料拼接成了二維的表格。並且為我們提供了許多表格層級資料處理以及批次資料處理的接口,大大降低了資料處理的難度。
#DataFrame是一個表格型的資料結構,它擁有兩個索引,分別是行索引以及列索引,使得我們可以很方便地取得對應的行以及列。這就大大降低了我們要找出資料處理資料的難度。
首先,我們先從最簡單的開始,如何建立一個DataFrame。
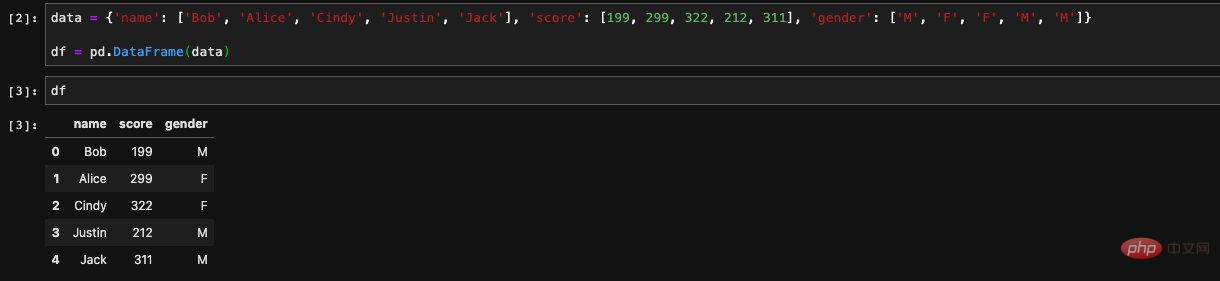
我們建立了一個dict,它的key是列名,value是一個list,當我們將這個dict傳入DataFrame的建構子的時候,它將會以key作為列名,value作為對應的值為我們建立一個DataFrame。
當我們在jupyter輸出的時候,它會自動為我們將DataFrame中的內容以表格的形式展現。
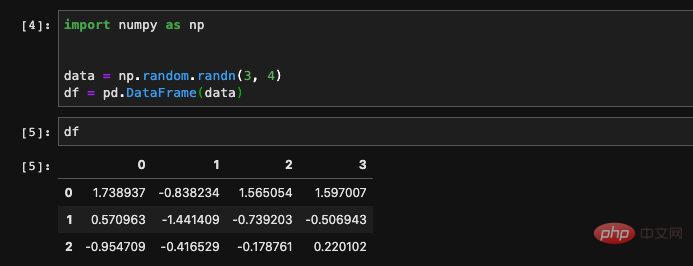
#我們也可以從一個numpy的二維陣列來建立一個DataFrame,如果我們只是傳入numpy的數組而不指定列名的話,那麼pandas將會以數字作為索引為我們創建列:
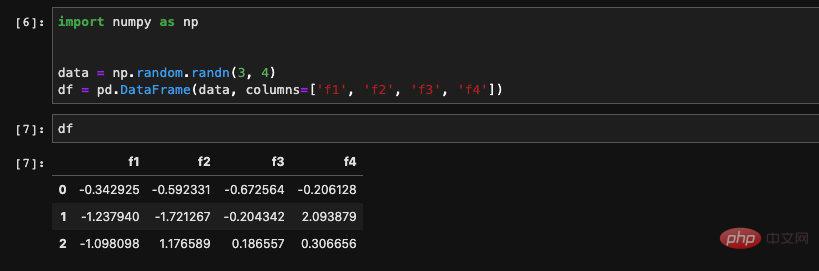
我們在創建的時候為columns這個欄位傳入一個string的list即可為它指定列名:
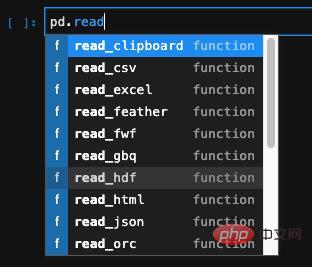
#pandas另一個非常強大的功能就是可以從各種格式的檔案當中讀取資料建立DataFrame,例如像是常用的excel、csv,甚至是資料庫也可以。
對於excel、csv、json等這種結構化的數據,pandas提供了專門的api,我們找到對應的api進行使用即可:
如果是一些比較特殊格式的,也沒有關係,我們使用read_table,它可以從各種文字檔案中讀取數據,透過傳入分隔符號等參數完成建立。例如在上一篇驗證PCA降維效果的文章當中,我們從.data格式的檔案當中讀取了資料。該檔案當中列和列之間的分隔符號是空格,而不是csv的逗號或是table符。我們透過傳入sep這個參數,指定分隔符號就完成了資料的讀取。

這個header參數表示檔案的哪些行作為資料的列名,預設header=0,也會將第一行當作列名。如果資料當中不存在列名,需要指定header=None,否則會產生問題。我們很少會出現需要用到多層列名的情況,所以一般情況下最常用的就是取預設值或是令它等於None。
在所有這些建立DataFrame的方法當中最常用的就是最後一種,從檔案讀取。因為我們做機器學習或是參加kaggle當中的一些比賽的時候,往往數據都是現成的,以文件的形式給我們使用,需要我們自己創建數據的情況很少。如果是在實際的工作場景,雖然資料不會存在文件當中,但是也會有一個源頭,一般是會儲存在一些大數據平台當中,模型從這些平台當中取得訓練資料。
所以整體來說,我們很少使用其他建立DataFrame的方法,我們有所了解,專注於掌握從檔案讀取的方法即可。
下面介紹一些pandas的常用操作,這些操作是我在沒有系統學習pandas的使用方法之前就已經了解的。了解的原因也很簡單,因為它們太常用了,可以說是必知必會的常識性內容。
我們在jupyter當中執行執行DataFrame的實例會為我們打出DataFrame中所有的數據,如果資料行數過多,則會以省略號的形式省略中間的部分。對於資料量很大的DataFrame,我們通常不會直接這樣輸出展示,而是選擇展示其中的前幾條或是後幾個資料。這裡就需要用到兩個api。
展示前若干條資料的方法叫做head,它接受一個參數,允許我們制定讓它從頭開始展示我們指定條數的資料。
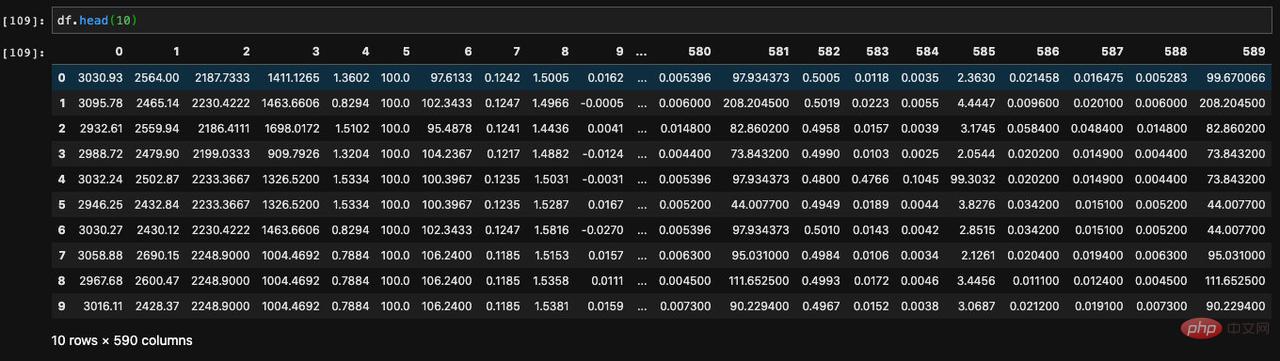
既然有展示前面若干條自然也有展示最後若干條的api,這樣的api叫做tail。透過它我們可以查看DataFrame最後指定條數的資料:

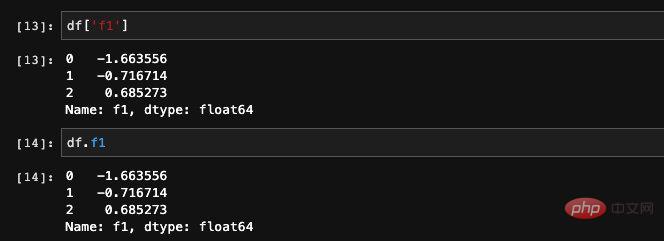
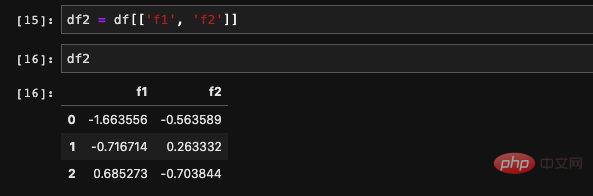
############## #######前面我們曾經提到過,對於DataFrame而言,它其實相當於Series組合成的dict。既然是dict我們自然可以根據key值取得指定的Series。 ######DataFrame當中有兩種方法取得指定的列,我們可以###透過.加列名###的方式或也可以###透過dict找出元素的方式###來查詢: ###############我們也###可以同時讀取多列###,如果是多列的話,只支援一種方法就是透過dict查詢元素的方法。它允許接收傳入一個list,可以找出這個list當中的欄位對應的資料。傳回的結果是這些新的欄位組成的新DataFrame。 ###
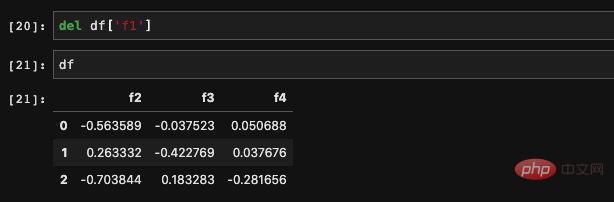
我們可以用del刪除一個我們不需要的欄位:
我們要建立一個新的列也很簡單,我們可以像dict賦值一樣,直接為DataFrame賦值即可:
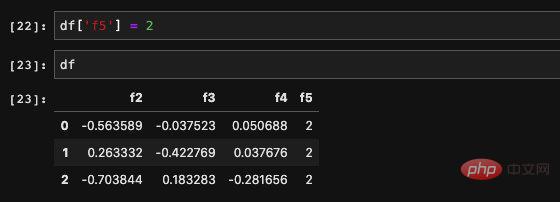
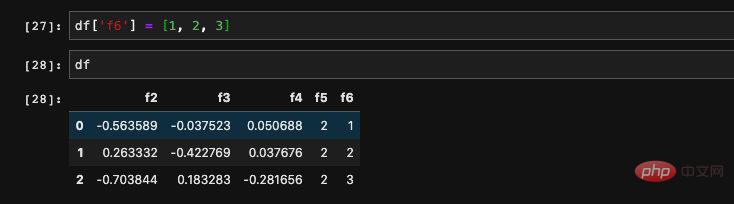
也可以是一個陣列:
使用.values取得DataFrame對應的numpy數組:

在DataFrame當中每一列單獨一個類型,而轉換成numpy的數組之後所有資料共享類型。那麼pandas會為所有的欄位找一個通用類型,這就是為什麼經常會得到一個object類型的原因。所以在使用.values之前最好先查看一下類型,保證一下不會因為類型而出錯。
有專業機構做過統計,對於一個演算法工程師而言,大約70%的時間會被投入在資料的處理上。真正寫模型、調參的時間可能不到20%,從這當中我們可以看到資料處理的必要性與重要性。在Python領域當中,pandas是資料處理最好用的手術刀和工具箱,希望大家都能掌握它。
#想了解更多程式設計學習,請關注php培訓欄位!
以上是使用pandas進行資料處理之 DataFrame篇的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















