

pandas妙招之 DataFrame基礎運算以及空值填充


相關學習推薦:python教學
#今天是pandas資料處理專題的第四篇文章,我們一起來聊聊DataFrame中的索引。
上一篇文章當中我們介紹了DataFrame資料結構當中一些常用的索引的使用方法,例如iloc、loc以及邏輯索引等等。今天的文章我們來看看DataFrame的一些基本運算。
資料對齊
我們可以計算兩個DataFrame的加和,pandas會自動將此兩個DataFrame進行資料對齊,如果對不上的資料會被置為Nan(not a number)。
首先我們來建立兩個DataFrame:
import numpy as npimport pandas as pddf1 = pd.DataFrame(np.arange(9).reshape((3, 3)), columns=list('abc'), index=['1', '2', '3'])df2 = pd.DataFrame(np.arange(12).reshape((4, 3)), columns=list('abd'), index=['2', '3', '4', '5'])复制代码得到的結果和我們設想的一致,其實只是透過numpy陣列建立DataFrame#,然後指定index和columns而已,這應該算是很基礎的用法了。
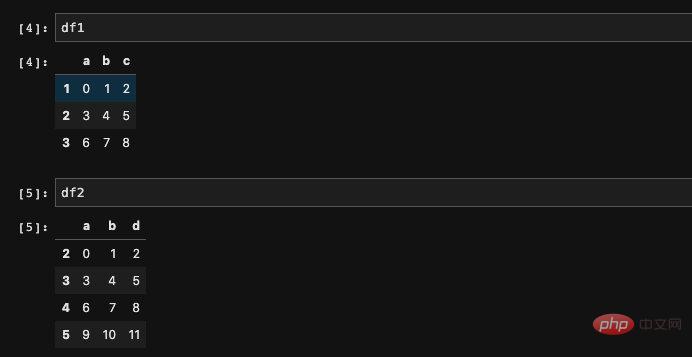
然後我們將兩個DataFrame相加,會得到:
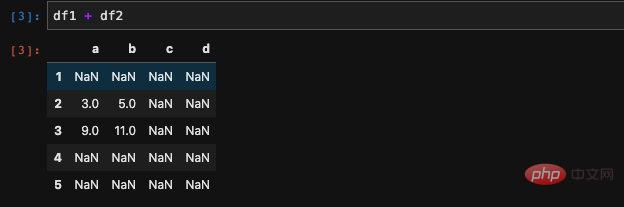
我們發現pandas將兩個DataFrame加起來合併了之後,凡是沒有在兩個DataFrame都出現的位置就會被置為Nan。這其實是很合理的,其實不只加法,我們可以計算兩個DataFrame的加減乘除的四則運算都是可以的。如果是計算兩個DataFrame相除的話,那麼除了對應不上的資料會被置為Nan之外,除零這個行為也會導致異常值的發生(可能不一定是Nan,而是inf)。
fill_value
#如果我們要對兩個DataFrame進行運算,那麼我們當然不會希望出現空值。這時候就需要對空值進行填充了,我們直接使用運算子進行運算是沒辦法傳遞參數進行填充的,這時候我們需要使用DataFrame當中為我們提供的算術方法。
DataFrame當中常用的運算子有這麼多種:
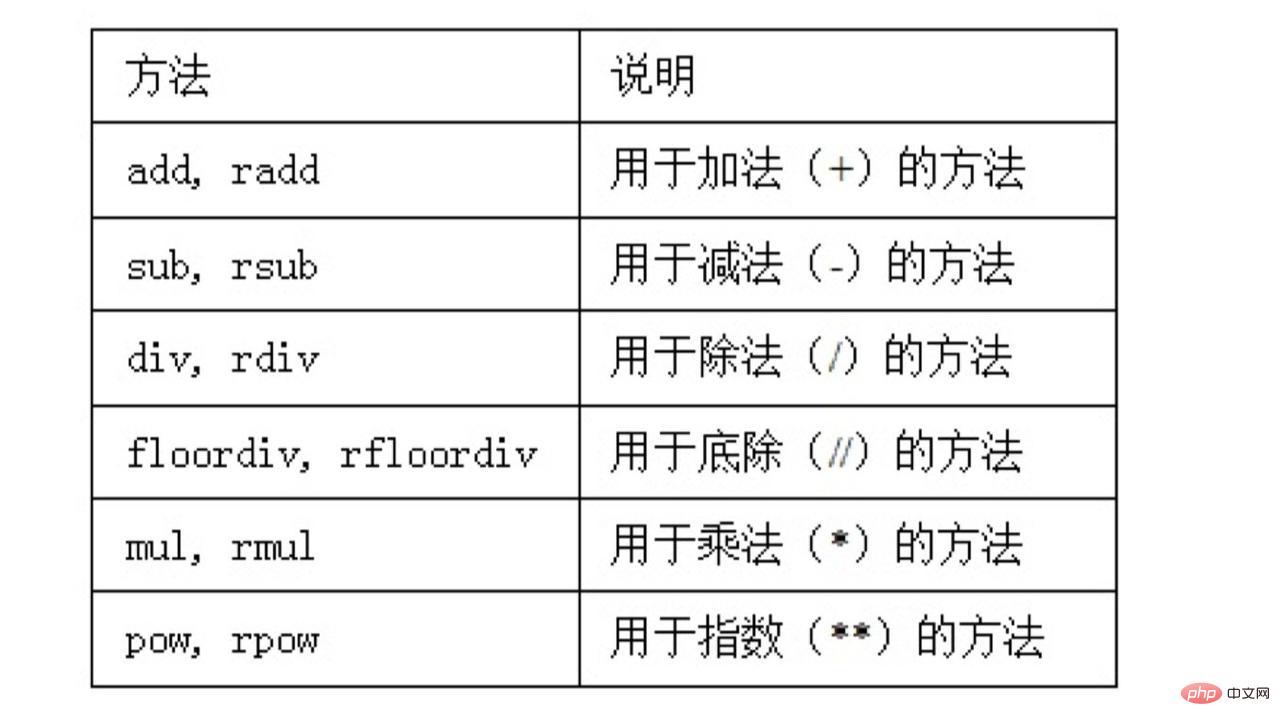
add、sub、p這些我們都很好理解,那麼這裡的radd、rsub方法又是什麼意思呢,為什麼前面要加上一個r呢?
看起來很費解,但是說白了一文不值,radd是用來翻轉參數的。舉個例子,比如說我們希望得到DataFrame當中所有元素的倒數,我們可以寫成1 / df。由於1本身並不是一個DataFrame,所以我們不能用1來呼叫DataFrame當中的方法,也就不能傳遞參數,為了解決這種情況,我們可以把1 / df寫成df.rp(1),這樣我們就可以在其中傳遞參數了。
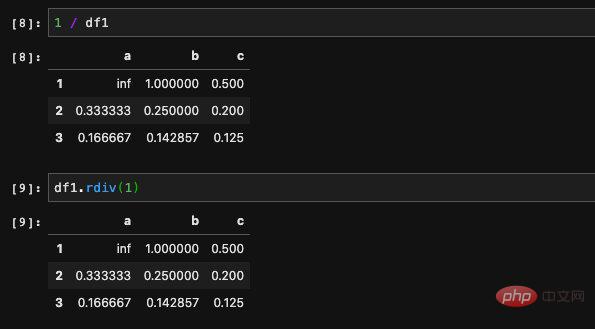
由於在算除法的過程當中發生了除零,所以我們得到了一個inf,它表示無窮大。
我們可以在add、p這些方法當中傳入一個fill_value的參數,這個參數可以在計算之前對於一邊出現缺失值的情況進行填入。也就是說對於只在一個DataFrame中缺少的位置會被替換成我們指定的值,如果在兩個DataFrame都缺失,那麼依然還會是Nan。
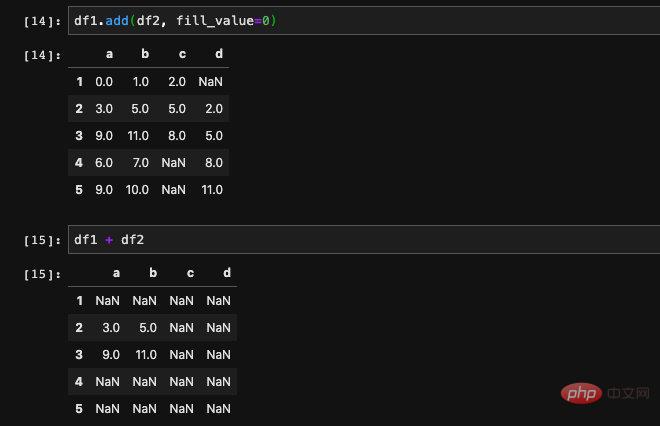
我們對比下結果就能發現了,相加之後的(1, d), (4, c)以及(5, c)的位置都是Nan ,因為df1和df2兩個DataFrame當中這些位置都是空值,所以沒有被填滿。
fill_value這個參數在很多api當中都有出現,例如reindex等,用法都是一樣的,我們在查閱api文檔的時候可以注意一下。
那麼對於這種填充了之後還會出現的空值我們該怎麼辦呢?難道只能手動找到這些位置進行填充嗎?當然是不切實際的,pandas當中也為我們提供了專門解決空值的api。
空值api
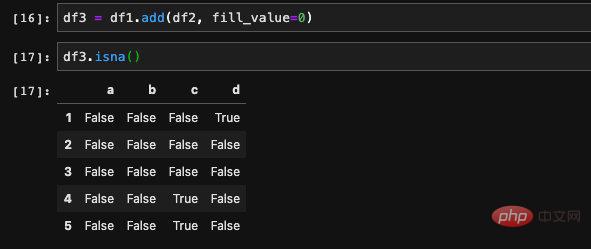
#在填入空值之前,我們首先要做的是發現空值。針對這個問題,我們有isna這個api,它會傳回一個bool型的DataFrame,DataFrame當中的每一個位置表示了原DataFrame對應的位置是否是空值。
dropna
#當然只是發現是否是空值肯定是不夠的,我們有時候會希望不要空值的出現,這個時候我們可以選擇drop掉空值。針對這種情況,我們可以使用DataFrame當中的dropna方法。
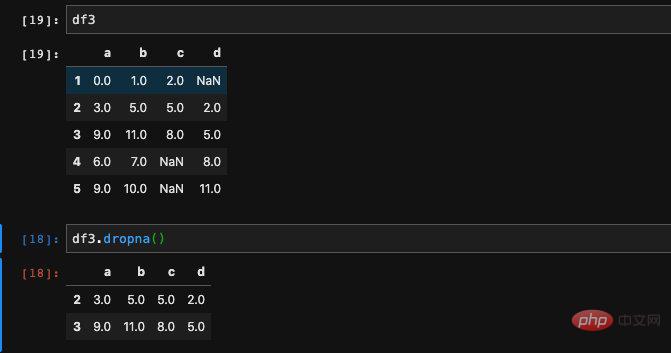
我們發現使用了dropna之後,出現了空值的行都被拋棄了。只保留了沒有空值的行,有時候我們希望拋棄是的列而不是行,這個時候我們可以透過傳入axis參數來控制。
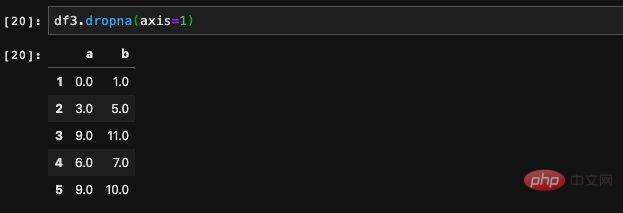
這樣我們得到的就是不含空值的列,除了可以控制行列之外,我們還可以控制執行drop的嚴格程度。我們可以透過how這個參數來判斷,how支援兩種值傳入,一種是'all',一種是'any'。 all表示只有在某一行或是某一列全為空值的時候才會拋棄,any與之對應就是只要出現了空值就會拋棄。預設不填的話認為是any,一般情況下我們也用不到這個參數,大概有個印象就可以了。
fillna
#pandas除了可以drop含有空值的資料之外,當然也可以用來填入空值,事實上這也是最常用的方法。
我們可以很簡單地傳入一個具體的值用來填入:
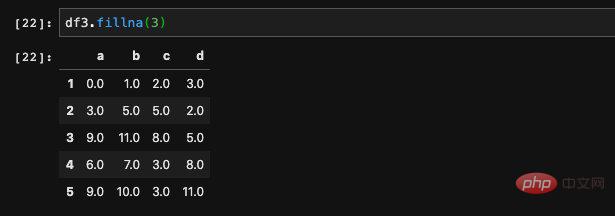
#fillna會傳回一個新的DataFrame,其中所有的Nan值會被替換成我們指定的值。如果我們不希望它回傳一個新的DataFrame,而是直接在原始資料進行修改的話,我們可以使用inplace參數,表示這是一個inplace的操作,那麼pandas將會在原DataFrame上進行修改。
df3.fillna(3, inplace=True)复制代码
除了填充具体的值以外,我们也可以和一些计算结合起来算出来应该填充的值。比如说我们可以计算出某一列的均值、最大值、最小值等各种计算来填充。fillna这个函数不仅可以使用在DataFrame上,也可以使用在Series上,所以我们可以针对DataFrame中的某一列或者是某些列进行填充:
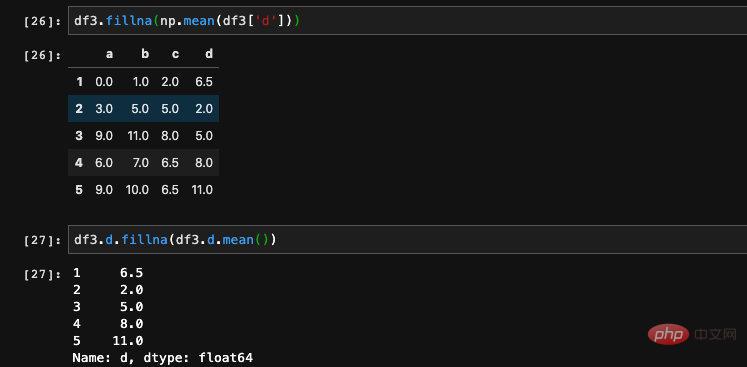
除了可以计算出均值、最大最小值等各种值来进行填充之外,还可以指定使用缺失值的前一行或者是后一行的值来填充。实现这个功能需要用到method这个参数,它有两个接收值,ffill表示用前一行的值来进行填充,bfill表示使用后一行的值填充。
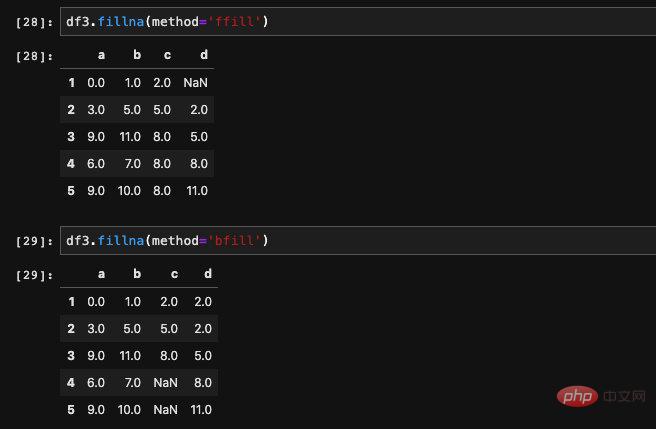
我们可以看到,当我们使用ffill填充的时候,对于第一行的数据来说由于它没有前一行了,所以它的Nan会被保留。同样当我们使用bfill的时候,最后一行也无法填充。
总结
今天的文章当中我们主要介绍了DataFrame的一些基本运算,比如最基础的四则运算。在进行四则运算的时候由于DataFrame之间可能存在行列索引不能对齐的情况,这样计算得到的结果会出现空值,所以我们需要对空值进行处理。我们可以在进行计算的时候通过传入fill_value进行填充,也可以在计算之后对结果进行fillna填充。
在实际的运用当中,我们一般很少会直接对两个DataFrame进行加减运算,但是DataFrame中出现空置是家常便饭的事情。因此对于空值的填充和处理非常重要,可以说是学习中的重点,大家千万注意。
想了解更多编程学习,敬请关注php培训栏目!
以上是pandas妙招之 DataFrame基礎運算以及空值填充的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python:代碼示例和比較
Apr 15, 2025 am 12:07 AM
PHP和Python各有優劣,選擇取決於項目需求和個人偏好。 1.PHP適合快速開發和維護大型Web應用。 2.Python在數據科學和機器學習領域佔據主導地位。
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情況如何
Apr 14, 2025 pm 06:48 PM
在CentOS系統上啟用PyTorchGPU加速,需要安裝CUDA、cuDNN以及PyTorch的GPU版本。以下步驟將引導您完成這一過程:CUDA和cuDNN安裝確定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA顯卡支持的CUDA版本。例如,您的MX450顯卡可能支持CUDA11.1或更高版本。下載並安裝CUDAToolkit:訪問NVIDIACUDAToolkit官網,根據您顯卡支持的最高CUDA版本下載並安裝相應的版本。安裝cuDNN庫:前
 docker原理詳解
Apr 14, 2025 pm 11:57 PM
docker原理詳解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux內核特性,提供高效、隔離的應用運行環境。其工作原理如下:1. 鏡像作為只讀模板,包含運行應用所需的一切;2. 聯合文件系統(UnionFS)層疊多個文件系統,只存儲差異部分,節省空間並加快速度;3. 守護進程管理鏡像和容器,客戶端用於交互;4. Namespaces和cgroups實現容器隔離和資源限制;5. 多種網絡模式支持容器互聯。理解這些核心概念,才能更好地利用Docker。
 minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安裝centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO對象存儲:CentOS系統下的高性能部署MinIO是一款基於Go語言開發的高性能、分佈式對象存儲系統,與AmazonS3兼容。它支持多種客戶端語言,包括Java、Python、JavaScript和Go。本文將簡要介紹MinIO在CentOS系統上的安裝和兼容性。 CentOS版本兼容性MinIO已在多個CentOS版本上得到驗證,包括但不限於:CentOS7.9:提供完整的安裝指南,涵蓋集群配置、環境準備、配置文件設置、磁盤分區以及MinI
 CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分佈式訓練如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系統上進行PyTorch分佈式訓練,需要按照以下步驟操作:PyTorch安裝:前提是CentOS系統已安裝Python和pip。根據您的CUDA版本,從PyTorch官網獲取合適的安裝命令。對於僅需CPU的訓練,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,請確保已安裝對應版本的CUDA和cuDNN,並使用相應的PyTorch版本進行安裝。分佈式環境配置:分佈式訓練通常需要多台機器或單機多GPU。所
 CentOS上PyTorch版本怎麼選
Apr 14, 2025 pm 06:51 PM
CentOS上PyTorch版本怎麼選
Apr 14, 2025 pm 06:51 PM
在CentOS系統上安裝PyTorch,需要仔細選擇合適的版本,並考慮以下幾個關鍵因素:一、系統環境兼容性:操作系統:建議使用CentOS7或更高版本。 CUDA與cuDNN:PyTorch版本與CUDA版本密切相關。例如,PyTorch1.9.0需要CUDA11.1,而PyTorch2.0.1則需要CUDA11.3。 cuDNN版本也必須與CUDA版本匹配。選擇PyTorch版本前,務必確認已安裝兼容的CUDA和cuDNN版本。 Python版本:PyTorch官方支
 CentOS上如何更新PyTorch到最新版本
Apr 14, 2025 pm 06:15 PM
CentOS上如何更新PyTorch到最新版本
Apr 14, 2025 pm 06:15 PM
在CentOS上更新PyTorch到最新版本,可以按照以下步驟進行:方法一:使用pip升級pip:首先確保你的pip是最新版本,因為舊版本的pip可能無法正確安裝最新版本的PyTorch。 pipinstall--upgradepip卸載舊版本的PyTorch(如果已安裝):pipuninstalltorchtorchvisiontorchaudio安裝最新
