

從Java說起 kotlin 的協變與逆變

java基礎教學專欄今天介紹kotlin的協變與逆變。

前言
為了更能理解 kotlin 和 Java 中的協變與逆變,先看一些基礎知識。
普通賦值
在Java 中,常見的賦值語句如下:
A a = b;复制代码
賦值語句必須滿足的條件是:左邊要嘛是右邊的父類,要嘛和右邊類型一樣。即 A 的類型要「大於」B 的類型,例如 Object o = new String("s"); 。為了方便起見,下文稱作 A > B。
除了上述最常見的賦值語句,還有兩種其他的賦值語句:
函數參數的賦值
public void fun(A a) {}// 调用处赋值B b = new B();
fun(b);复制代码在呼叫fun(b) 方法時,會將傳入的B b 實參賦值給形參A a,即A a = b 的形式。同樣的,必須滿足形參類型大於實參,即 A > B。
函數傳回值的賦值
public A fun() {
B b = new B(); return b;
}
复制代码函數傳回值型別接收實際回傳型別的值,實際回傳型別B b 相當於賦值給了函數傳回值型別A a,即B b 賦值給了A a, 即A a = b,那麼必須滿足A > B 的型別關係。
所以,無論哪一種賦值,都必須滿足左邊類型 > 右邊類型,即 A > B。
Java 中的協變與逆變
有了前面的基礎知識,就可以方便地解釋協變與逆變了。
如果類別A > 類別B,經過一個變化trans 後得到的trans(A) 與trans(B) 依舊滿足trans(A) > trans(B),那麼稱為協變。
逆變則剛好相反,如果類別A > 類別B,經過一個變化trans 後得到的trans(A) 與trans(B) 滿足trans(B) > trans(A),稱為逆變。
例如大家都知道 Java 的陣列是協變的,假如 A > B,那麼有 A[] > B[],所以 B[] 可以賦值給 A[]。舉個例子:
Integer[] nums = new Integer[]{};
Object[] o = nums; // 可以赋值,因为数组的协变特性所以由 Object > Integer 得到 Object[] > Integer[]复制代码但是Java 的泛型則不滿足協變,如下:
List<Integer> l = new ArrayList<>(); List<Object> o = l;// 这里会报错,不能编译复制代码
上述程式碼報錯,就是因為,雖然Object > Integer,但由於泛型不滿足協變,所以List<Object> > List<Integer> 是不滿足的,既然不滿足左邊大於右邊這個條件,從前言我們知道,自然就不能將List< Integer> 賦值給List<Object>。一般稱 Java 泛型不支援型變。
Java 中泛型如何實現協變與逆變
從前面我們知道,在Java 中泛型是不支援型變的,但這會產生一個讓人很奇怪的疑惑,也是很多講泛型的文章中提到的:
如果B 是A 的子類,那麼List 就應該是List 的子類呀!這是一個非常自然而然的想法!
但很抱歉,因為種種原因,Java 並不支援。但是,Java 並不是完全抹殺了泛型的型變特性,Java 提供了 和 讓泛型擁有協變和逆變的特性。
與
稱為上界通配符, 稱為下界通配符。使用上界通配符可以使泛型協變,而使用下界通配符可以使泛型逆變。
例如之前舉的例子
List<Integer> l = new ArrayList<>(); List<Object> o = l;// 这里会报错,不能编译复制代码
如果使用上界通配符,
List<Integer> l = new ArrayList<>(); List<? extends Object> o = l;// 可以通过编译复制代码
這樣,List 的型別就大於List<Integer> 的型別了,也就實現了協變。這也就是所謂的「子類別的泛型是泛型的子類別」。
同樣,下界通配符 可以實現逆變,如:
public List<? super Integer> fun(){
List<Object> l = new ArrayList<>(); return l;
}复制代码上述程式碼怎麼就實現逆變了呢?首先,Object > Integer;另外,從前言我們知道,函數傳回值型別必須大於實際回傳值型,這裡就是List<? super Integer> > List<Object>,和Object > Integer 剛好相反。也就是說,經過泛型變化後,Object 和 Integer 的型別關係翻轉了,這就是逆變,而實現逆變的就是下界通配符 。
從上面可以看出, 中的上界是T,也就是說 所泛指的型別都是T 的子類別或T 本身,所以T 大於 。 中的下界是 T,也就是說 所泛指的類型都是 T 的父類或 T 本身,所以 大於 T。
虽然 Java 使用通配符解决了泛型的协变与逆变的问题,但是由于很多讲到泛型的文章都晦涩难懂,曾经让我一度感慨这 tm 到底是什么玩意?直到我在 stackoverflow 上发现了通俗易懂的解释(是的,前文大部分内容都来自于 stackoverflow 中大神的解释),才终于了然。其实只要抓住赋值语句左边类型必须大于右边类型这个关键点一切就都很好懂了。
PECS
PECS 准则即 Producer Extends Consumer Super,生产者使用上界通配符,消费者使用下界通配符。直接看这句话可能会让人很疑惑,所以我们追本溯源来看看为什么会有这句话。
首先,我们写一个简单的泛型类:
public class Container<T> { private T item; public void set(T t) {
item = t;
} public T get() { return item;
}
}复制代码然后写出如下代码:
Container<Object> c = new Container<String>(); // (1)编译报错Container<? extends Object> c = new Container<String>(); // (2)编译通过c.set("sss"); // (3)编译报错Object o = c.get();// (4)编译通过复制代码代码 (1),Container<Object> c = new Container<String>(); 编译报错,因为泛型是不型变的,所以 Container
代码 (2),加了上界通配符以后,支持泛型协变,Container
既然代码 (2) 通过编译,那代码 (3) 为什么会报错呢?因为代码 (3) 尝试把 String 类型赋值给 类型。显然,编译器只知道 是 Obejct 的某一个子类型,但是具体是哪一个并不知道,也许并不是 String 类型,所以不能直接将 String 类型赋值给它。
从上面可以看出,对于使用了 的类型,是不能写入元素的,不然就会像代码 (3) 处一样编译报错。
但是可以读取元素,比如代码 (4) 。并且该类型只能读取元素,这就是所谓的“生产者”,即只能从中读取元素的就是生产者,生产者就使用 通配符。
消费者同理,代码如下:
Container<String> c = new Container<Object>(); // (1)编译报错Container<? super String> c = new Container<Object>(); // (2)编译通过
c.set("sss");// (3) 编译通过
String s = c.get();// (4) 编译报错复制代码代码 (1) 编译报错,因为泛型不支持逆变。而且就算不懂泛型,这个代码的形式一眼看起来也是错的。
代码 (2) 编译通过,因为加了 通配符后,泛型逆变。
代码 (3) 编译通过,它把 String 类型赋值给 , 泛指 String 的父类或 String,所以这是可以通过编译的。
代码 (4) 编译报错,因为它尝试把 赋值给 String,而 大于 String,所以不能赋值。事实上,编译器完全不知道该用什么类型去接受 c.get() 的返回值,因为在编译器眼里 是一个泛指的类型,所有 String 的父类和 String 本身都有可能。
同样从上面代码可以看出,对于使用了 的类型,是不能读取元素的,不然就会像代码 (4) 处一样编译报错。但是可以写入元素,比如代码 (3)。该类型只能写入元素,这就是所谓的“消费者”,即只能写入元素的就是消费者,消费者就使用 通配符。
综上,这就是 PECS 原则。
kotlin 中的协变与逆变
kotlin 抛弃了 Java 中的通配符,转而使用了声明处型变与类型投影。
声明处型变
首先让我们回头看看 Container 的定义:
public class Container<T> { private T item; public void set(T t) {
item = t;
} public T get() { return item;
}
}复制代码在某些情况下,我们只会使用 Container<? extends T> 或者 Container<? super T> ,意味着我们只使用 Container 作为生产者或者 Container 作为消费者。
既然如此,那我们为什么要在定义 Container 这个类的时候要把 get 和 set 都定义好呢?试想一下,如果一个类只有消费者的作用,那定义 get 方法完全是多余的。
反过来说,如果一个泛型类只有生产者方法,比如下面这个例子(来自 kotlin 官方文档):
// Javainterface Source<T> {
T nextT(); // 只有生产者方法}// Javavoid demo(Source<String> strs) {
Source<Object> objects = strs; // !!!在 Java 中不允许,要使用上界通配符 <? extends Object>
// ……}复制代码在 Source<Object> 类型的变量中存储 Source<String> 实例的引用是极为安全的——因为没有消费者-方法可以调用。然而 Java 依然不让我们直接赋值,需要使用上界通配符。
但是这是毫无意义的,使用通配符只是把类型变得更复杂,并没有带来额外的价值,因为能调用的方法还是只有生产者方法。但 Java 编译器只认死理。
所以,如果我们能在使用之前确定一个类是生产者还是消费者,那在定义类的时候直接声明它的角色岂不美哉?
这就是 kotlin 的声明处型变,直接在类声明的时候,定义它的型变行为。
比如:
class Container<out T> { // (1)
private var item: T? = null
fun get(): T? = item
}
val c: Container<Any> = Container<String>()// (2)编译通过,因为 T 是一个 out-参数复制代码(1) 处直接使用
同样的,对于消费者来说,
class Container<in T> { // (1)
private var item: T? = null
fun set(t: T) {
item = t
}
}val c: Container<String> = Container<Any>() // (2) 编译通过,因为 T 是一个 in-参数复制代码代码 (1) 处使用 Container<? super String> c = new Container<Object>(); 。
这就是声明处型变,在类声明的时候使用 out 和 in 关键字,在使用时可以直接写出泛型型变的代码。
而 Java 在使用时必须借助通配符才能实现泛型型变,这是使用处型变。
类型投影
有时一个类既可以作生产者又可以作消费者,这种情况下,我们不能直接在 T 前面加 in 或者 out 关键字。比如:
class Container<T> { private var item: T? = null
fun set(t: T?) {
item = t
} fun get(): T? = item
}复制代码考虑这个函数:
fun copy(from: Container<Any>, to: Container<Any>) {
to.set(from.get())
}复制代码当我们实际使用该函数时:
val from = Container<Int>()val to = Container<Any>() copy(from, to) // 报错,from 是 Container<Int> 类型,而 to 是 Container<Any> 类型复制代码
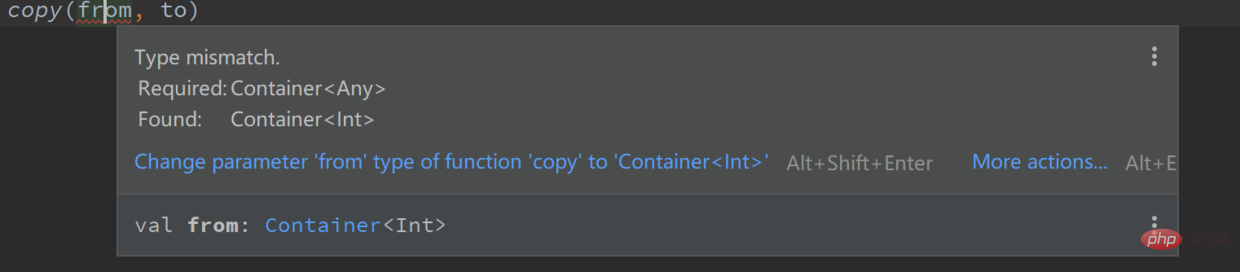
这样使用的话,编译器报错,因为我们把两个不一样的类型做了赋值。用 kotlin 官方文档的话说,copy 函数在”干坏事“, 它尝试写一个 Any 类型的值给 from, 而我们用 Int 类型来接收这个值,如果编译器不报错,那么运行时将会抛出一个 ClassCastException 异常。
所以应该怎么办?直接防止 from 被写入就可以了!
将 copy 函数改为如下所示:
fun copy(from: Container<out Any>, to: Container<Any>) { // 给 from 的类型加了 out
to.set(from.get())
}val from = Container<Int>()val to = Container<Any>()
copy(from, to) // 不会再报错了复制代码这就是类型投影:from 是一个类受限制的(投影的)Container 类,我们只能把它当作生产者来使用,它只能调用 get() 方法。
同理,如果 from 的泛型是用 in 来修饰的话,则 from 只能被当作消费者使用,它只能调用 set() 方法,上述代码就会报错:
fun copy(from: Container<in Any>, to: Container<Any>) { // 给 from 的类型加了 in
to.set(from.get())
}val from = Container<Int>()val to = Container<Any>()
copy(from, to) // 报错复制代码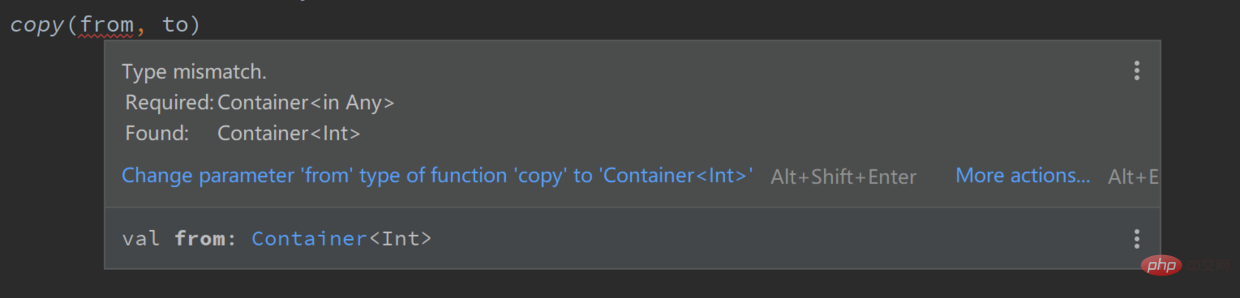
其实从上面可以看到,类型投影和 Java 的通配符很相似,也是一种使用时型变。
为什么要这么设计?
为什么 Java 的数组是默认型变的,而泛型默认不型变呢?其实 kolin 的泛型默认也是不型变的,只是使用 out 和 in 关键字让它看起来像泛型型变。
为什么这么设计呢?为什么不默认泛型可型变呢?
在 stackoverflow 上找到了答案,参考:stackoverflow.com/questions/1…
Java 和 C# 早期都是没有泛型特性的。
但是为了支持程序的多态性,于是将数组设计成了协变的。因为数组的很多方法应该可以适用于所有类型元素的数组。
比如下面两个方法:
boolean equalArrays (Object[] a1, Object[] a2);void shuffleArray(Object[] a);复制代码登入後複製第一个是比较数组是否相等;第二个是打乱数组顺序。
语言的设计者们希望这些方法对于任何类型元素的数组都可以调用,比如我可以调用 shuffleArray(String[] s) 来把字符串数组的顺序打乱。
出于这样的考虑,在 Java 和 C# 中,数组设计成了协变的。
然而,对于泛型来说,却有以下问题:
// Illegal code - because otherwise life would be BadList<Dog> dogs = new List<Dog>(); List<Animal> animals = dogs; // Awooga awoogaanimals.add(new Cat());// (1)Dog dog = dogs.get(0); //(2) This should be safe, right?复制代码登入後複製如果上述代码可以通过编译,即 List
可以赋值给 List ,List 是协变的。接下来往 List 中 add 一个 Cat(),如代码 (1) 处。这样就有可能造成代码 (2) 处的接收者 Dog dog和dogs.get(0)的类型不匹配的问题。会引发运行时的异常。所以 Java 在编译期就要阻止这种行为,把泛型设计为默认不型变的。總結
1、Java 泛型預設不型變,所以 List
不是 List 2、Kotlin 泛型其實預設也是不型變的,只不過使用 out 和 in 關鍵字在類別宣告處型變,可以達到在使用處看起來像直接型變的效果。但是這樣會限制類別在聲明時只能要麼作為生產者,要麼作為消費者。
使用類型投影可以避免類別在聲明時被限制,但是在使用時要使用 out 和 in 關鍵字指明這個時刻類別所扮演的角色是消費者還是生產者。類型投影也是一種使用處型變的方法。
相關免費學習推薦:java基礎教學
以上是從Java說起 kotlin 的協變與逆變的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
突破或從Java 8流返回?
Feb 07, 2025 pm 12:09 PM
Java 8引入了Stream API,提供了一種強大且表達力豐富的處理數據集合的方式。然而,使用Stream時,一個常見問題是:如何從forEach操作中中斷或返回? 傳統循環允許提前中斷或返回,但Stream的forEach方法並不直接支持這種方式。本文將解釋原因,並探討在Stream處理系統中實現提前終止的替代方法。 延伸閱讀: Java Stream API改進 理解Stream forEach forEach方法是一個終端操作,它對Stream中的每個元素執行一個操作。它的設計意圖是處
 PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP:網絡開發的關鍵語言
Apr 13, 2025 am 12:08 AM
PHP是一種廣泛應用於服務器端的腳本語言,特別適合web開發。 1.PHP可以嵌入HTML,處理HTTP請求和響應,支持多種數據庫。 2.PHP用於生成動態網頁內容,處理表單數據,訪問數據庫等,具有強大的社區支持和開源資源。 3.PHP是解釋型語言,執行過程包括詞法分析、語法分析、編譯和執行。 4.PHP可以與MySQL結合用於用戶註冊系統等高級應用。 5.調試PHP時,可使用error_reporting()和var_dump()等函數。 6.優化PHP代碼可通過緩存機制、優化數據庫查詢和使用內置函數。 7
 PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP與Python:了解差異
Apr 11, 2025 am 12:15 AM
PHP和Python各有優勢,選擇應基於項目需求。 1.PHP適合web開發,語法簡單,執行效率高。 2.Python適用於數據科學和機器學習,語法簡潔,庫豐富。
 PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP與其他語言:比較
Apr 13, 2025 am 12:19 AM
PHP適合web開發,特別是在快速開發和處理動態內容方面表現出色,但不擅長數據科學和企業級應用。與Python相比,PHP在web開發中更具優勢,但在數據科學領域不如Python;與Java相比,PHP在企業級應用中表現較差,但在web開發中更靈活;與JavaScript相比,PHP在後端開發中更簡潔,但在前端開發中不如JavaScript。
 PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP與Python:核心功能
Apr 13, 2025 am 12:16 AM
PHP和Python各有優勢,適合不同場景。 1.PHP適用於web開發,提供內置web服務器和豐富函數庫。 2.Python適合數據科學和機器學習,語法簡潔且有強大標準庫。選擇時應根據項目需求決定。
 Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
Java程序查找膠囊的體積
Feb 07, 2025 am 11:37 AM
膠囊是一種三維幾何圖形,由一個圓柱體和兩端各一個半球體組成。膠囊的體積可以通過將圓柱體的體積和兩端半球體的體積相加來計算。本教程將討論如何使用不同的方法在Java中計算給定膠囊的體積。 膠囊體積公式 膠囊體積的公式如下: 膠囊體積 = 圓柱體體積 兩個半球體體積 其中, r: 半球體的半徑。 h: 圓柱體的高度(不包括半球體)。 例子 1 輸入 半徑 = 5 單位 高度 = 10 單位 輸出 體積 = 1570.8 立方單位 解釋 使用公式計算體積: 體積 = π × r2 × h (4
 PHP的影響:網絡開發及以後
Apr 18, 2025 am 12:10 AM
PHP的影響:網絡開發及以後
Apr 18, 2025 am 12:10 AM
PHPhassignificantlyimpactedwebdevelopmentandextendsbeyondit.1)ItpowersmajorplatformslikeWordPressandexcelsindatabaseinteractions.2)PHP'sadaptabilityallowsittoscaleforlargeapplicationsusingframeworkslikeLaravel.3)Beyondweb,PHPisusedincommand-linescrip
 PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP:許多網站的基礎
Apr 13, 2025 am 12:07 AM
PHP成為許多網站首選技術棧的原因包括其易用性、強大社區支持和廣泛應用。 1)易於學習和使用,適合初學者。 2)擁有龐大的開發者社區,資源豐富。 3)廣泛應用於WordPress、Drupal等平台。 4)與Web服務器緊密集成,簡化開發部署。
