

來優化 小程式中的css treeshaking

微信小程式開發教學欄位帶大家學習如何優化小程式中的css treeshaking。

前言
em...我寫這工具的原因就是為了上班多划水,少費腦,少犯錯,一勞永逸!
每次局部改版舊頁面時,我不會去刪除舊的css。因為很麻煩,而且又害怕不小心刪除了不可預估的樣式錯亂。
所以我基本上都是在css檔案的最後一行去新增新的樣式,然後...,css檔案越來越大。所以為了解決這個手動刪除css的問題,開發了一個小工具。 
我們最終實作效果是透過終端命令去完成css treeshaking
// 到项目目录下cd Documents/xxx/xcx// 微信qts-lint css wx// 支付宝qts-lint css alipay复制代码
處理命令列
如何全域接收qts-lint命令
配置package.json檔案的bin字段,全域安裝後就可以識別qts-lint xxxx命令啦,是不是很簡單
{ "name": "xxx", "version": "1.0.0", "description": "小程序代码", "bin": { "qts-lint": "./bin.js"
}
}复制代码如何接收命令列參數
使用commander接收指令,區分執行的是微信還是支付寶,再去執行對應的邏輯
關於commander我就不具體介紹了,大家可以自己看看文檔
const program = require("commander");
program
.command("css <app-type>") // 参数
.description("格式化,css tree-shaking") // 描述
.action((type, command) => { // do something...
});复制代码</app-type>取得css依賴關係
#前面我們說了怎麼去接收命令列指令,接下來我們就進入正題,如何對小程式css進行tree shaking。
目前我們使用外掛程式purify-css來做tree shaking,所以就需要取得css的依賴關係來確定哪些css是頁面沒用到的。
取得小程式所有頁面
小程式所有頁面都在app.json中維護,app.json的格式都是如下所示
{ "pages": [ "pages/index/index", "pages/login/login",
...
], "subPackages": [
{ "root": "mine", "pages": [ "/index/index",
...
]
}
],
...
}复制代码所以為了取得主套件和分包中的所有頁面,就需要去循環pages和subPackages,特別需要注意的是subPackages的路由是由root pages組合而成的,下方就是我們獲取小程式中所有頁面路由的方法
function readPages(json = {}, root) { let pages = (json.pages || []).map(p => path.join(root, p));
json.subPackages &&
json.subPackages.forEach(element => {
pages = pages.concat(element.pages.map(p => path.join(root, element.root, p)));
}); return pages;
}复制代码取得css的依賴關係
循環取得到的頁面,取得每個頁面對應的css,js,wxml,json。
儲存得到的資料
{ "css url": ["js url", "wxml url", ...]
}复制代码但是頁面也存在元件和引用,所以我們還需要
- 取得元件css,js,wxml,如果是元件則加入父頁面數組的同時保存自身的鍵值對
- 解析wxml文件,獲取引用,將引用路徑添加到數組裡
- 解析引用的文件,判斷是否還存在引用文件,存在回到步驟1
- 解析json文件,存在元件回到步驟1
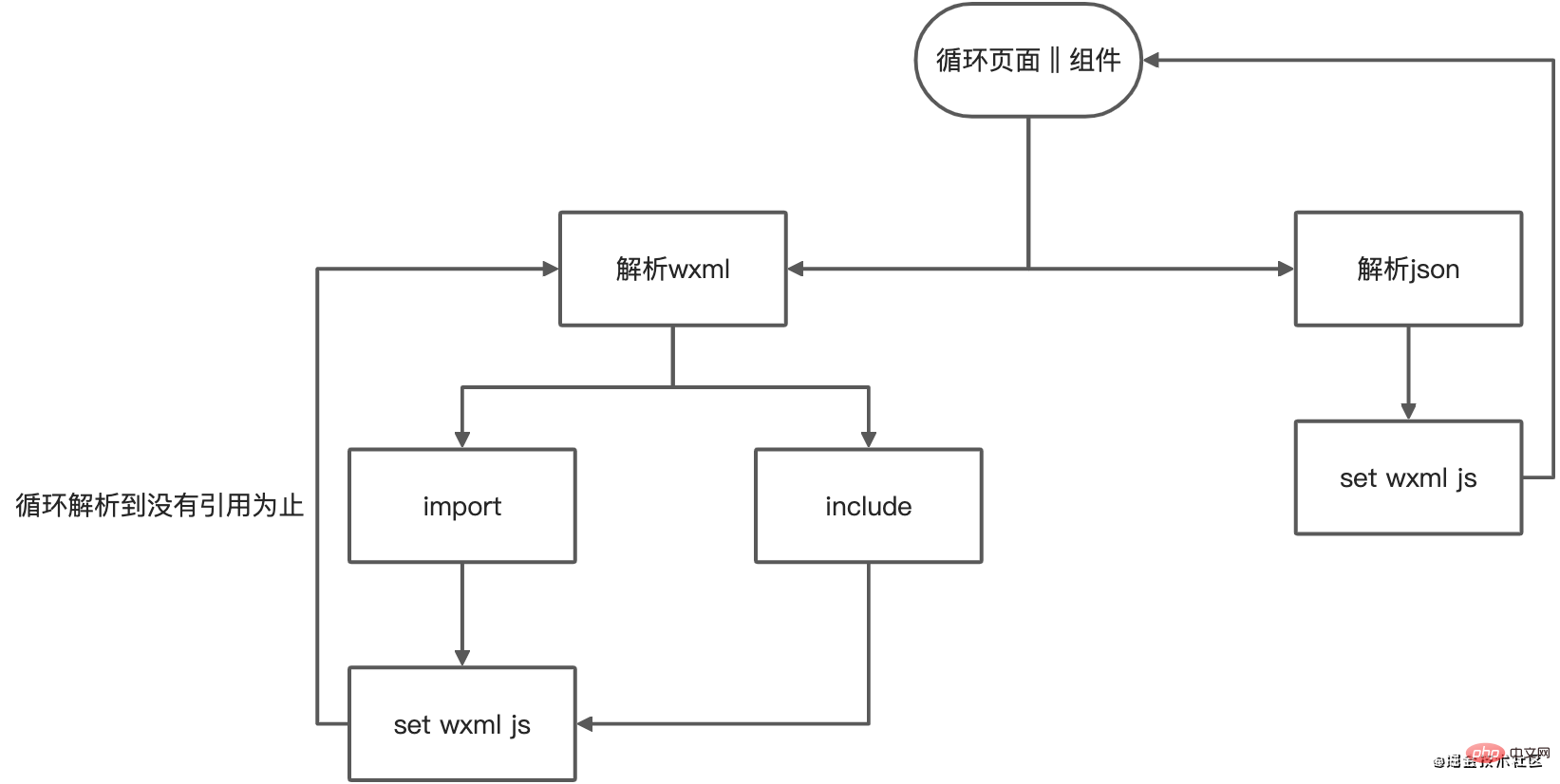
#上面我們說到要解析wxml,那我們該如何去解析wxml呢?
可以使用htmlparser2解析後循環節點,取得type是tag而且name等於import或include的標籤,然後再拿到該標籤的src,就可以取得到該頁面的引用或引用裡的引用了
這時就會得到一個像下面這樣的css依賴關係結構(包括頁面,組件,引用)
{ // 页面css
"/pages/index/index.css": [ // 页面
"/pages/index/index.js", "/pages/index/index.wxml", // 组件
"/pages/components/title/index.js", "/pages/components/title/index.wxml", // 引用模版
"/pages/template/index.wxml"
], // 组件css
"/pages/xxx/xxx.css":[ // 父页面
"/pages/index/index.js", "/pages/index/index.wxml", // 组件的页面
"/pages/index/index.js", "/pages/index/index.wxml",
...
],
...
}复制代码這裡大家可能會有2個疑惑
#為啥目前頁面的css還要關聯元件的wxml和js?
因為支付寶存在樣式穿透,而我們專案是多人開發的,所以怕存在組件的樣式在頁面寫了,組件就沒寫的情況,所以做了這種兼容
為啥目前元件的css也要關聯頁面的wxml和js?
可能存在頁面傳送元件className,而樣式列舉寫在元件內的情況,那麼只能關聯頁面才能拿到傳入的className。這裡可能存在樣式多刪的情況,例如樣式裡寫裡四種樣式,但是實際用到的只有一種,那可能就會把其它3種刪掉,這就不是我們想要的效果,目前的解決方法只有在js加上列舉的className註釋,purify-css檢查到js裡出現了需要的幾個className的枚舉後就不刪除css裡的樣式了
刪除css
上面我們取得到css依賴關係後,直接利用purify-css完成刪除css的操作啦
purify('css url', [...], options)复制代码
弱小的我原始碼和其它外掛程式放在一起,大家有興趣可以看看喲
原始碼連結:www.npmjs.com/package/xcx…
npm 全域
$ npm i -g xcx-lint-qts复制代码
yarn 全域
$ yarn global add xcx-lint-qts复制代码
// 到项目目录下cd Documents/xxx/xcx// 微信qts-lint css wx// 支付宝qts-lint css alipay复制代码
#相關免費學習推薦:微信小程式開發教學
以上是來優化 小程式中的css treeshaking的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 使用Python開發微信小程式
Jun 17, 2023 pm 06:34 PM
使用Python開發微信小程式
Jun 17, 2023 pm 06:34 PM
隨著行動互聯網技術和智慧型手機的普及,微信成為了人們生活中不可或缺的一個應用。而微信小程式則讓人們可以在不需要下載安裝應用程式的情況下,直接使用小程式來解決一些簡單的需求。本文將介紹如何使用Python來開發微信小程式。一、準備工作在使用Python開發微信小程式之前,需要先安裝相關的Python函式庫。這裡推薦使用wxpy和itchat這兩個函式庫。 wxpy是一個微信機器
 小程式能用react嗎
Dec 29, 2022 am 11:06 AM
小程式能用react嗎
Dec 29, 2022 am 11:06 AM
小程式能用react,其使用方法:1、基於「react-reconciler」實作一個渲染器,產生一個DSL;2、建立一個小程式元件,去解析和渲染DSL;3、安裝npm,並執行開發者工具中的建構npm;4、在自己的頁面中引入包,再利用api即可完成開發。
 實作微信小程式中的卡片翻轉特效
Nov 21, 2023 am 10:55 AM
實作微信小程式中的卡片翻轉特效
Nov 21, 2023 am 10:55 AM
實作微信小程式中的卡片翻轉特效在微信小程式中,實現卡片翻轉特效是一種常見的動畫效果,可以提升使用者體驗和介面互動的吸引力。以下將具體介紹如何在微信小程式中實現卡片翻轉的特效,並提供相關程式碼範例。首先,需要在小程式的頁面佈局檔案中定義兩個卡片元素,一個用於顯示正面內容,一個用於顯示背面內容,具體範例程式碼如下:<!--index.wxml-->&l
 支付寶上線「漢字拾光-生僻字」小程序,用於徵集、補充生僻字庫
Oct 31, 2023 pm 09:25 PM
支付寶上線「漢字拾光-生僻字」小程序,用於徵集、補充生僻字庫
Oct 31, 2023 pm 09:25 PM
本站10月31日消息,今年5月27日,螞蟻集團宣布啟動“漢字拾光計劃”,最近又迎來新進展:支付寶上線“漢字拾光-生僻字”小程序,用於向社會徵集生僻字,補充生僻字庫,同時提供不同的生僻字輸入體驗,以幫助完善支付寶內的生僻字輸入方法。目前,用戶搜尋「漢字拾光」、「生僻字」等關鍵字就可以進入「生僻字」小程式。在小程式裡,使用者可以提交尚未被系統辨識輸入的生僻字圖片,支付寶工程師確認後,將會對字庫進行補錄入。本站注意到,使用者也可以在小程式體驗最新的拆字輸入法,這項輸入法針對讀音不明確的生僻字設計。用戶拆
 uniapp如何實現小程式和H5的快速轉換
Oct 20, 2023 pm 02:12 PM
uniapp如何實現小程式和H5的快速轉換
Oct 20, 2023 pm 02:12 PM
uniapp如何實現小程式和H5的快速轉換,需要具體程式碼範例近年來,隨著行動網路的發展和智慧型手機的普及,小程式和H5成為了不可或缺的應用形式。而uniapp作為一個跨平台的開發框架,可以在一套程式碼的基礎上,快速實現小程式和H5的轉換,大大提高了開發效率。本文將介紹uniapp如何實現小程式和H5的快速轉換,並給出具體的程式碼範例。一、uniapp簡介unia
 小程式備案怎麼操作
Sep 13, 2023 pm 04:36 PM
小程式備案怎麼操作
Sep 13, 2023 pm 04:36 PM
小程序備案操作步驟:1、準備個人身分證影本、企業營業執照影本、法人身分證影本等備案資料;2、登入小程式管理後台;3、進入小程式設定頁;4、選擇“基本設定」;5、填寫備案資料;6、上傳備案資料;7、提交備案申請;8、等待審核結果,如果備案不透過要根據原因進行修改,並重新提交備案申請;9、備案後續操作即可。
 用Python編寫簡單的聊天程式教程
May 08, 2023 pm 06:37 PM
用Python編寫簡單的聊天程式教程
May 08, 2023 pm 06:37 PM
實現思路x01服務端的建立首先,在服務端,使用socket進行訊息的接受,每接受一個socket的請求,就開啟一個新的線程來管理訊息的分發與接受,同時,又存在一個handler來管理所有的線程,從而實現對聊天室的各種功能的處理x02客戶端的建立客戶端的建立就要比服務端簡單多了,客戶端的作用只是對消息的發送以及接受,以及按照特定的規則去輸入特定的字符從而實現不同的功能的使用,因此,在客戶端這裡,只需要去使用兩個線程,一個是專門用於接受消息,一個是專門用於發送消息的至於為什麼不用一個呢,那是因為,只
 微信小程式怎麼弄會員
May 07, 2024 am 10:24 AM
微信小程式怎麼弄會員
May 07, 2024 am 10:24 AM
1.開啟微信小程序,進入對應的小程式頁面。 2.在小程式頁面中尋找會員相關入口,通常會員入口在底部導覽列或個人中心等位置。 3.點選會員入口,進入會員申請頁。 4、在會員申請頁面,填寫相關信息,如手機號碼、姓名等,完成資料填寫後,提交申請。 5.小程式方會對會員申請審核,審核通過後,用戶即可成為微信小程式會員。 6.作為會員,用戶將享有更多的會員權益,如積分、優惠券、會員專屬活動等
