
#最近在學習MySQL最佳化方面的知識。 Mysql教學欄位就資料型態和schema方面的最佳化進行介紹。
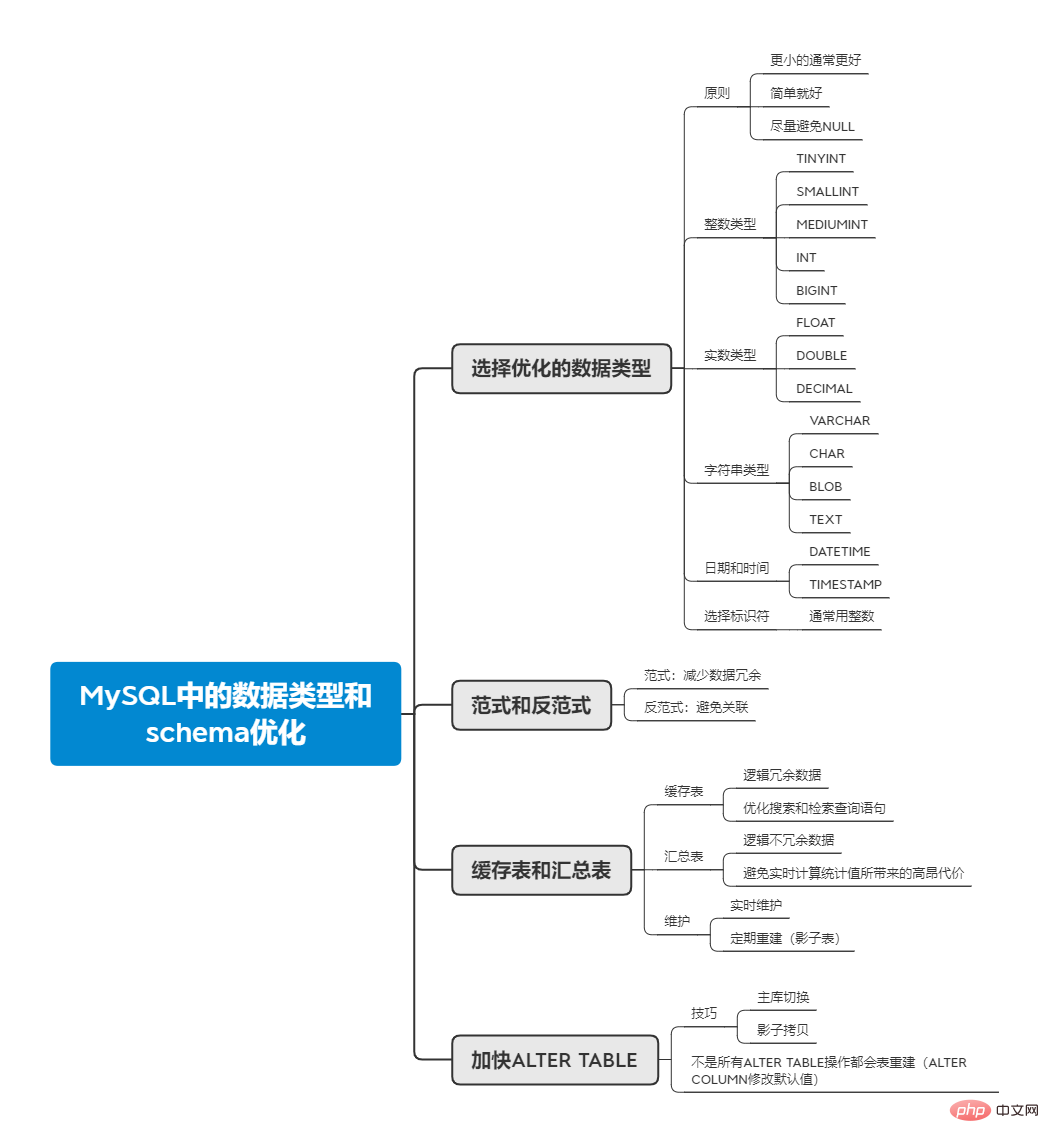
MySQL支援的資料類型有很多,而如何選擇正確的資料類型,對於效能來說是至關重要的。以下幾個原則能夠幫助確定資料類型:
通常更小更好
##要注意使用可以正確儲存資料的最小資料類型,夠用就好。這樣將佔用較少的磁碟、記憶體和緩存,而在處理時的運行時間較少。
# 簡單就好
當兩種資料類型都勝任一個字段的存儲工作時,簡單的那一方,往往是最好的選擇。例如整型和字符串,由於整型的操作代價要小於字符,所以當在兩者之間在選擇之間,選擇整數通常能夠獲得更好的效能。
##盡量避免NULL
當列值NULL時,對於MySQL來說,在索引和值比較等方面需要做更多的工作,雖然對效能的影響不大,但也應該避免設計為NULL。
除以上原則,在選擇資料類型時,需遵循的步驟:先確定合適的大類型,例如下面的資料、字串、時間等;然後再選擇具體的類型。將討論大類型下面的一些具體類型,首先是數字,有兩種類型:整數和實數。
整數類型和所佔用的空間如下:
| 空間大小(位元) | |||
|---|---|---|---|
| 8 | |||
| 16 | |||
| #24 | |||
| 32 | |||
| 64 |
| 實數型別 | 空間大小(Byte) | 取值範圍 | 計算精確度 |
|---|---|---|---|
| #FLOAT | 4 | 為負數: -3.4E 38~-1.17E-38;非負數:0、1.17E-38~3.4E 38 | 近似計算 |
| #DOUBLE | #8 | 負數:-1.79E 308~-2.22E-308;非負數:0、2.22E-308~1.79E 308 | 近似計算 |
同DOUBLE
| 從上面可以看出,FLOAT和DOUBLE都有固定的空間大小,但同時由於是使用標準的浮點運算,所以只能近似計算。而DECIMAL則可以實現精確計算,同時佔用的空間會相較更大,所耗費的計算開銷也更多。 | |
|---|---|
| D為小數點後的長度,取值範圍為[0, 30],且D <= M,預設值為0。 | |
| 數字個數字 | |
| 1 |
2
#小數點前後將分別存儲,同時小數點也要佔1個位元組。以下舉出兩個計算的例子:
DECIMAL(18, 9):整數部分長度為9,佔用4個位元組。小數部分長度為9,佔用4個位元組。同時加上小數點1個字節,則總共佔用9個位元組。最常用的字串型別當屬VARCHAR和CHAR。 VARCHAR作為可變長字串,會使用1或2個額外位元組記錄字串的長度,當最大長度未超過255時,只需1個位元組記錄長度,超過255,則需2個位元組。 VARCHAR的適用場景:
CHAR則為定長字串,根據定義的字串長度分配足夠的空間,適用場景:
長度短;長度相近,例如MD5;#經常更新。| BLOB | 是以二進位 | 方式存儲,而TEXT | 是以字元 | 方式儲存。這也導致,BLOB類型的資料沒有字元集的概念,無法按字元排序,而TEXT類型則有字元集的概念,可以按字元排序。兩者的使用場景,也由儲存格式決定了,當儲存二進位資料時,例如圖片,應使用BLOB,而儲存文字時,例如文章,則應使用TEXT類型。
|---|---|---|---|
| 類型 | 儲存內容 | ||
| 時區概念 | DATETIME |
TIMESTAMP顯示的值將依賴時區,意義在不同時區查詢到的值將不一樣。除了上述列出的不同,TIMESTAMP還具有一個特殊屬性,在插入和更新時,如果沒有指定第一個TIMESTAMP列的值,將會設定這個列的值為目前時間。
我們在開發過程中,應盡量使用TIMESTAMP,主要是因為其空間大小僅需DATETIME的一半,空間效率更高。
如果我們想儲存的日期和時間精確到秒之後,怎麼辦?由於MySQL並未提供,所以我們可以使用BIGINT儲存微妙等級的時間戳,或是使用DOUBLE儲存秒之後的小數部分。
通常來說整數是標識符的最佳選擇,主要是因為其簡單,計算快,且可使用AUTO_INCREMENT。
簡單來說,範式就是一張資料表的表結構所符合的某種設計標準的層級。第一範式,屬性不可分割,現在的RDBMS系統建成的表格都是符合第一範式的。而第二範式,則是消除非主屬性對碼(可以理解為主鍵)的部分依賴。第三範式消除非主屬性對碼的傳遞依賴。具體的介紹,可以讀讀知乎上的這個回答(https://www.zhihu.com/question/24696366/answer/29189700)
嚴格範式化的資料庫中,每個事實資料會出現且只出現一次,不會出現資料冗餘,這樣所能帶能帶來的好處有:
但也因為資料分散存在各張表中,查詢時需要對錶進行關聯。而反範式的優點則是不用進行關聯,將資料冗餘儲存。
在實際應用中,不會出現完全的範式化或完全的反範式化,時常需要混用範式和反範式,使用部分範式化的schema,往往是最好的選擇。關於資料庫設計,在網路上看到這樣一段話,大家可以感受下。
資料庫設計應該分為三個境界:
第一境界:剛入門資料庫設計,範式的重要性還未深刻理解。這時候出現的反範式設計,一般會出問題。
第二境界:隨著遇到問題解決問題,漸漸了解到範式的真正好處,從而快速設計出低冗餘、高效率的資料庫。
第三境界:再經過N年的鍛煉,是一定會發覺範式的限制的。此時再去打破範式,設計更合理的反範式部分。
範式就像武俠裡面的招數,初學者妄想不按招數來,只能死的很難堪。畢竟招數都是高手總結歸納的精華。而隨著武功提高,招數熟練之後,必然是發現招數的局限性,要么忘掉招數,要么自創招數。
只要努力,加上多撐幾年,總能達到第二個境界,總會覺得範式是經典。此時能不過度依賴範式,快速突破範式限制的人,自然是高手。
除了上述所說的反範式,在表中儲存冗餘數據,我們還可以建立一張完全獨立的總表或快取表,來滿足檢索的需要。
快取表,指的是儲存可以從schema其他表取得資料的表,也就是邏輯上冗餘的資料。而匯總表,則指的是儲存使用GROUP BY等語句聚合數據,計算出的不冗餘的數據。
快取表,可用於優化搜尋和檢索查詢語句,這裡可以使用的技巧有對快取表使用不同的儲存引擎,例如主表使用InnoDB,而快取表則可使用MyISAM,獲得更小的索引佔用空間。甚至可以將快取表放到專門的搜尋系統中,例如Lucene。
總結表,則是為了避免即時計算統計值所帶來的高昂代價,代價來自兩方面,一是需要掃描表中的大部分數據,二是建立特定的索引,會對UPDATE運算有影響。例如,查詢微信過去24小時的朋友圈數量,則可固定每1小時掃描全表,統計後寫一筆記錄到匯總表,當查詢時,只需查詢匯總表上最新的24筆記錄,而不必每次查詢時都去掃描全表進行統計。
在使用快取表和匯總表時,必須決定是即時維護資料還是定期重建,這取決於我們的需求。定期重建相比即時維護,能節省更多的資源,表的碎片更少。而在重建時,我們仍需保證資料在操作時可用,需要透過「影子表」來實現。在真實表後建立一張影子表,當填入好資料後,透過原子的重新命名操作來切換影子表和原表。
當MySQL在執行ALTER TABLE操作時,往往是新建一張表,然後把資料從舊表查出並插入到新表中,再刪除舊表,如果表很大,這樣需要花費很長時間,且會導致MySQL的服務中斷。為了避免服務中斷,通常可以使用兩種技巧:
但也不是所有的ALTER TABLE操作會造成表格重建,例如在修改欄位的預設值時,使用MODIFY COLUMN會進行表格重建,而使用ALTER COLUMN則不會進行表格重建,操作速度很快。這是因為ALTER COLUMN在修改預設值時,會直接修改了存在表格的.frm檔案(儲存欄位的預設值),而並未重建表格。
更多相關免費學習推薦:mysql教學##(影片)
#
以上是MySQL中的資料型別與schema優化的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















