

好久沒寫文章了,沉寂了大半年
持續性萎靡不振,間歇性癲癇發作
天天來大姨爹,在迷茫、焦慮中度過每一天
不得不承認,其實自己就是個廢物
作為一名低階前端工程師
#最近處理了一個十多年的祖傳老接口
它繼承了一切至尊級複雜度邏輯
#傳說中調用一次就能讓cpu負載飆升90%的日天服務
專治各種不服與阿茲海默症
我們欣賞一下這個介面的耗時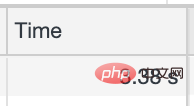
平均呼叫時間在3s以上
導致頁面出現嚴重的轉菊花
經過各種深度剖析與專業人士答疑
最後得出結論是:放棄醫療魯迅在《狂人日記》裡曾說過:「
」
#每當身處黑暗之時
這句話總能讓我看到光
所以這次要硬起來
我決定做一個node代理層
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码首先我們用type Query定義了一個對女神資訊的查詢,裡麵包含了很多女孩girls的資訊Info,這些資訊是一堆數組,所以是[Info]
我們在type Info
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
wheel {
money
}
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码
第二個最佳化手段,使用redis快取
天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
虽然女神依然看不上我
但仍然时刻准备着为女神服务
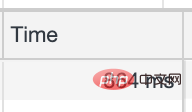
经过以上三个方法优化后
接口请求耗时从3s降到了860ms
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
以上是優化技巧! !前端菜鳥讓介面提速60%的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















