
mysql教學總結資料庫事務與MySQL 事務

為了更能理解ACID,以銀行帳戶轉帳為例:START TRANSACTION;SELECT balance FROM checking WHERE customer_id = 10233276;UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;COMMIT;
隔離性:允許在一個事務中的操作語句會與其他事務的語句隔離開,例如事務A運行到第3行之後,第4行之前,此時事務B去查詢checking餘額時,它仍然能夠看到在事務A中被減去的200元(帳戶錢不變),因為事務A和B是彼此隔離的。在事務A提交之前,事務B觀察不到資料的改變。 持久性:這個很好理解。
交易的隔離性是透過鎖定、MVCC等實現(MySQL鎖定總結)#並發交易帶來的問題
# ######更新遺失(Lost Update):當兩個或多個交易選擇同一行,然後基於最初選定的值更新該行時,由於每個事務都不知道其他事務的存在,就會發生遺失更新問題-最後的更新覆蓋了其他事務所所做的更新。例如,兩位編輯人員製作了同一 文件的電子副本。每個編輯人員獨立地更改其副本,然後保存更改後的副本,這樣就覆蓋了原始文件。最後儲存其更改副本的編輯人員會覆蓋另一個編輯人員所做的更改。如果在一個編輯人員完成並提交事務之前,另一個編輯人員無法存取同 一份文件,則可避免此問題。 ######髒讀(Dirty Reads):一個事務正在對一筆記錄做修改,在這個事務完成並提交前, 這條記錄的資料就處於不一致狀態; 這時, 另一個事務也來讀取同一筆記錄,如果不加控制,第二個事務讀取了這些「髒」數據,並據此做進一步的處理,就會產生未提交的數據依賴關係。這種現像被形像地叫做」臟讀」。 ######不可重複讀(Non-Repeatable Reads):一個事務在讀取某些數據後的某個時間,再次讀取以前讀過的數據,卻發現其讀出的數據已經發生了改變、或某些記錄已經被刪除了!這種現象就叫做「不可重複讀」 。 ######幻讀(Phantom Reads): 一個事務按相同的查詢條件重新讀取以前檢索過的數據,卻發現其他事務插入了滿足其查詢條件的新數據,這種現象就稱為“幻讀” 。 ##################幻讀與不可重複讀取的差異:#######並發事務處理帶來的問題的解決方案:
#「更新遺失」通常是應該完全避免的。但防止更新遺失,並不能單靠資料庫事務控制器來解決,需要應用程式對要更新的資料加必要的鎖定來解決,因此,防止更新遺失應該是應用程式的責任。
「髒讀」 、 「不可重複讀」和「幻讀」 ,其實都是資料庫讀取一致性問題,必須由資料庫提供一定的交易隔離機制來解決:
一種是加鎖:在讀取資料前,對其加鎖,阻止其他交易對資料進行修改。
另一種是資料多版本並發控制(MultiVersion Concurrency Control,簡稱MVCC 或MCC),也稱為多版本資料庫:不用加任何鎖, 透過一定機制產生一個數據請求時間點的一致性資料快照(Snapshot), 並用這個快照來提供一定等級(語句級或交易級) 的一致性讀取。從使用者的角度來看,好像是資料庫可以提供相同資料的多個版本。
SQL標準定義了4類隔離級別,每一種級別都規定了一個事務中所做的修改,哪些在事務內和事務間是可見的,哪些是不可見的。低階的隔離級一般支援更高的並發處理,並擁有更低的系統開銷。
第1層級:Read Uncommitted(讀取未提交內容)
第2層級:Read Committed(讀取提交內容)
這是大多數資料庫系統的預設隔離等級(但不是MySQL預設的)
它滿足了隔離的簡單定義:一個交易只能看見已經提交事務所所做的改變
這種隔離等級出現的問題是-不可重複讀取(Nonrepeatable Read):不可重複讀取意味著我們在同一個事務中執行完全相同的select語句時可能看到不一樣的結果。導致這種情況的原因可能有:
有一個交叉的事務有新的commit,導致了資料的改變;
一個資料庫被多個實例操作時,相同交易的其他實例在該實例處理其間可能會有新的commit
第3層級:Repeatable Read(可重讀)
多重版本並發控制:
Mysql的大多數事務型儲存引擎實作都不是簡單的行級鎖。基於提升並發性考慮,一般都同時實現了多版本並發控制(MVCC),包括Oracle、PostgreSQL。不過實現各不相同。
MVCC的實作是透過保存資料在某一個時間點快照來實現的。也就是說不管實現時間多長,每個事物看到的資料都是一致的。
分為樂觀(optimistic)並發控制和悲觀(pressimistic)並發控制。
MVCC是如何運作的:
InnoDB的MVCC是透過在每行記錄後面保存兩個隱藏的列來實現。這兩個列一個保存了行的建立時間,一個保存行的過期時間(刪除時間)。當然儲存的並不是真實的時間而是系統版本號(system version number)。每開始一個新的事務,系統版本號碼就會自動新增。事務開始時刻的系統版本號碼會作為交易的版本號,用來查詢到每行記錄的版本號進行比較。
REPEATABLE READ(可重讀)隔離等級下MVCC如何運作:
InnoDB會根據下列條件檢查每一行記錄:
只有符合上述兩個條件的才會被查詢出來
第4等級:Serializable(可串列化)
# 比較

SQL Server 除支援上述ISO/ANSI SQL92 定義的4 個隔離級別外,還支援一個稱為“快照”的隔離級別,但嚴格來說它是一個用MVCC 實現的Serializable 隔離級別。
MySQL 支援全部4 個隔離級別,但在具體實現時,有一些特點,例如在一些隔離級別下是採用MVCC一致性讀取,但某些情況下又不是。使用交易日誌,儲存引擎在修改表的資料時只需要修改其記憶體拷貝,再把該修改行為記錄到持久在硬碟上的交易日誌中,而不用每次都將修改的資料本身持久到磁碟。 交易日誌採用的是追加的方式,因此寫日誌的操作是磁碟上一小塊區域內的順序I/O,而不像隨機I/O需要在磁碟的多個地方移動磁頭,所以採用交易日誌的方式相對來說要快得多。
交易日誌持久以後,記憶體中被修改的資料在後台可以慢慢刷回到磁碟。
如果資料的修改已經記錄到交易日誌並且持久化,但資料本身沒有寫回到磁碟,此時系統崩潰,儲存引擎在重新啟動時能夠自動恢復這一部分修改的資料。
目前來說,大多數儲存引擎都是這樣實現的,我們通常稱之為預寫式日誌(Write-Ahead Logging),修改資料需要寫兩次磁碟。 ###############Mysql中的交易實作原理#########交易的實作是基於資料庫的儲存引擎。不同的儲存引擎對事務的支援程度不一樣。 mysql中支援事務的儲存引擎有innoDB和NDB。 ######innoDB是mysql預設的儲存引擎,預設的隔離等級是RR(Repeatable Read),並且在RR的隔離等級下更進一步,透過多版本###並發控制###(MVCC,Multiversion Concurrency Control )解決不可重複讀取問題,加上間隙鎖(也就是並發控制)解決幻讀問題。因此innoDB的RR隔離等級其實實現了串列化等級的效果,而且保留了比較好的並發效能。 ###事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。
1.redo log
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
记录1:
记录2:
记录3:
记录4:
记录5:
2.undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程
假设有2个数值,分别为A和B,值为1,2
1. start transaction;
2. 记录 A=1 到undo log;
3. update A = 3;
4. 记录 A=3 到redo log;
5. 记录 B=2 到undo log;
6. update B = 4;
7. 记录B = 4 到redo log;
8. 将redo log刷新到磁盘
9. commit
在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。
Mysql中的事务使用
MySQL的服务层不管理事务,而是由下层的存储引擎实现。比如InnoDB。
MySQL支持本地事务的语句:
START TRANSACTION | BEGIN [WORK] COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE] ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE] SET AUTOCOMMIT = {0 | 1}事务使用注意点:
自动提交(autocommit):
Mysql默认采用自动提交模式,可以通过设置autocommit变量来启用或禁用自动提交模式
InnoDB在事务执行过程中,使用两阶段锁协议:
随时都可以执行锁定,InnoDB会根据隔离级别在需要的时候自动加锁;
锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在同一时刻被释放。
InnoDB也支持通过特定的语句进行显示锁定(存储引擎层):
select ... lock in share mode //共享锁 select ... for update //排他锁
MySQL Server层的显示锁定:
lock table和unlock table
(更多阅读:MySQL锁总结)
MySQL对分布式事务的支持
分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。
MySQL 从 5.0.3 开始支持分布式事务,当前分布式事务只支持 InnoDB 存储引擎。一个分布式事务会涉及多个行动,这些行动本身是事务性的。所有行动都必须一起成功完成,或者一起被回滚。
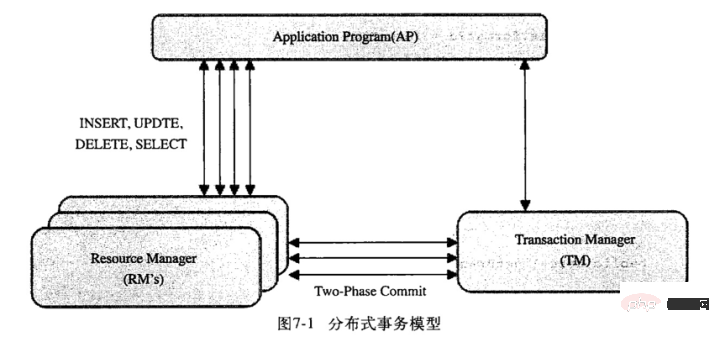
如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM):
分布式事务采用两段式提交(two-phase commit)的方式:
分布式事务(XA 事务)的 SQL 语法主要包括:
XA {START|BEGIN} xid [JOIN|RESUME]虽然 MySQL 支持分布式事务,但是在测试过程中,还是发现存在一些问题:
如果分支事务在达到 prepare 状态时,数据库异常重新启动,服务器重新启动以后,可以继续对分支事务进行提交或者回滚得操作,但是提交的事务没有写 binlog,存在一定的隐患,可能导致使用 binlog 恢复丢失部分数据。如果存在复制的数据库,则有可能导致主从数据库的数据不一致。
如果分支事务在执行到 prepare 状态时,数据库异常,且不能再正常启动,需要使用备份和 binlog 来恢复数据,那么那些在 prepare 状态的分支事务因为并没有记录到 binlog,所以不能通过 binlog 进行恢复,在数据库恢复后,将丢失这部分的数据。
如果分支事务的客户端连接异常中止,那么数据库会自动回滚未完成的分支事务,如果此时分支事务已经执行到 prepare 状态, 那么这个分布式事务的其他分支可能已经成功提交,如果这个分支回滚,可能导致分布式事务的不完整,丢失部分分支事务的内容。
总之, MySQL 的分布式事务还存在比较严重的缺陷, 在数据库或者应用异常的情况下,
可能会导致分布式事务的不完整。如果应用对于数据的完整性要求不是很高,则可以考虑使
用。如果应用对事务的完整性有比较高的要求,那么对于当前的版本,则不推荐使用分布式
事务。
以上是總結資料庫事務與 MySQL 事務的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















