免費學習推薦:mysql影片教學
文章目錄
- 1 影響效能的幾個面向
- 1.1 硬體方面
- 1.2 伺服器系統
##1.3 資料庫存儲引擎的選擇- 1.4 資料庫參數配置
- 1.5 資料庫結構設計與SQL語句(重點)
-
-
2.1 CPU資源與可用記憶體大小-
2.1.1 如何選擇CPU- 2.1.2 記憶體
-
#2.1.2.1 常用MySQL儲存引擎- 2.1.2.2 提示
- 2.1.2.3 如何選擇記憶體
-
-
2.2.1 使用傳統機器硬碟- 2.2.2 使用RAID增強傳統機器硬碟的效能
-
-
#2.2.2.1 什麼是RAID- 2.2.2.2 RAID等級
-
2.2.2.2.1 RAID 0- 2.2.2.2. 2 RAID 1
- 2.2.2.2.3 RAID 5 —— 常見的RAID組別
- 2.2.2.2.4 RAID 10 —— 常用的RAID組別
-
-
2.2.3 使用固態儲存SSD和PCIe卡- 2.2.4 使用網路儲存NAS和SAN
-
2.2.4.1 網路儲存使用的場景- 2.2.4.2 網路效能的限制
- 2.2.4.3 網路對效能的影響
-
-
-
- ##3.1 CentOS系統參數最佳化4 檔案系統對效能的影響
- 5 MySQL體系結構
-
1 影響效能的幾個方面
1.1 硬體方面
通常個人電腦速度慢,我們都會說是因為電腦硬體的問題,通常是CPU,內存,磁碟IO等因素,因此在伺服器上也會出現這個問題。
1.2 伺服器系統
一般個人電腦的作業系統都是windows,不同版本的windows系統的效能都不相同,或是配置了某一些參數導致效能的不同。這對於伺服器系統也是一樣,參數的設定也會影響伺服器效能。
1.3 資料庫儲存引擎的選擇
MySQL具有外掛程式儲存引擎,可以根據不同的業務需求選擇不同的儲存引擎。
而不同的儲存引擎也有不同的特點:
MyISAM:不支援事務,表級鎖定。
- InnoDB:事務級儲存引擎,完美支援行級鎖,事務ACID特性。
-
1.4 資料庫參數配置
對於不同儲存引擎,它的參數配置都不盡相同,有些參數對儲存引擎的影響是微乎其微,但有些參數卻對性能有決定性作用。因此我們會根據所選的儲存引擎和不同的業務需求,對參數的最佳化也是很重要的。
1.5 資料庫結構設計與SQL語句(重點)
#我們在進行資料庫結構設計的時候應該考慮到今後我們要在資料庫上執行怎樣的sql語句,來對錶結構進行查詢和更新,只有這樣才能設計出符合要求的表結構。
對於慢查詢,是導致效能低下的罪魁禍首,而它就是由於我們對資料庫表結構設計不合理而產生的。而對於這類sql來說,也是最難優化的,因為專案一旦上線,就很難對資料庫表結構進行修改。
因此我們最佳化資料庫效能的重點在於:
在下面具體對每個面向進行詳細的說明。
2 硬體方面
##2.1 CPU資源與可用記憶體大小
2.1.1 如何選擇CPU
通常在選擇CPU的時候,我們都希望CPU的頻率和核心數量兩者都盡量高,但由於成本或各種因素,往往只能迫使我們選擇其中的一種。那我們應該如何選擇最優的方案?因此,在購買CPU時我們需要注意幾點問題:
- 我們的應用程式時CPU密集型的嗎?
- 如果我們的應用是CPU密集型的話,要加快sql的處理速度,顯然我們需要更好的CPU,而不是更多的CPU。
- 對於目前的MySQL而言,還不支援duoCPU對相同SQL並發處理。
- 我們系統的並發量如何?
- 如果我們系統需要更多吞吐量,那麼我們的CPU就越多越好。假設我們有40個CPU,那我們是不是可以同時處理40個SQL了呢。
- 衡量資料庫處理能力的指標:QPS,指的是同時處理SQL的數量。但這個指標是在1s中處理SQL的數量,但上一點闡述的同時處理是在奈秒的維度上。
- MySQL通常是使用在web應用上的,往往並發量比較大,這時CPU數量比CPU頻率更為重要。
- 我們所使用的MySQL的版本
- 在5.0版本之前,MySQL對多核心的CPU支援並不好,對系統的限制是很嚴重的,在現在5.6,5.7版本上,對多核心CPU的支援已經有了很大的改善。因此建議使用最新版的MySQL版本,以達到更好的效能。
- 選擇32位元還是64位元的CPU?
- 目前伺服器的CPU預設都是64位元架構的,但要注意,要檢查好系統是否在64位元上安裝了32位元的伺服器版本,這會嚴重影響伺服器效能。
2.1.2 記憶體
記憶體的大小直接影響資料庫的效能。目前記憶體的效率要遠高於磁碟。因此把資料緩存到記憶體中,可以大大提高伺服器效能。
2.1.2.1 常用MySQL儲存引擎
有兩個常用的儲存引擎:MyISAM和InnoDB。
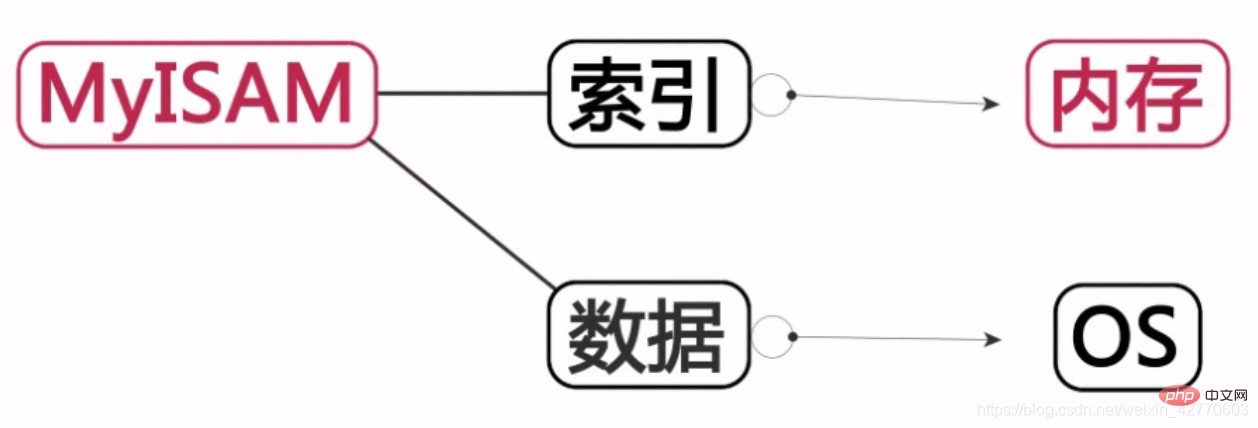
MyISAM:
索引儲存在記憶體中,資料保存在硬碟中。
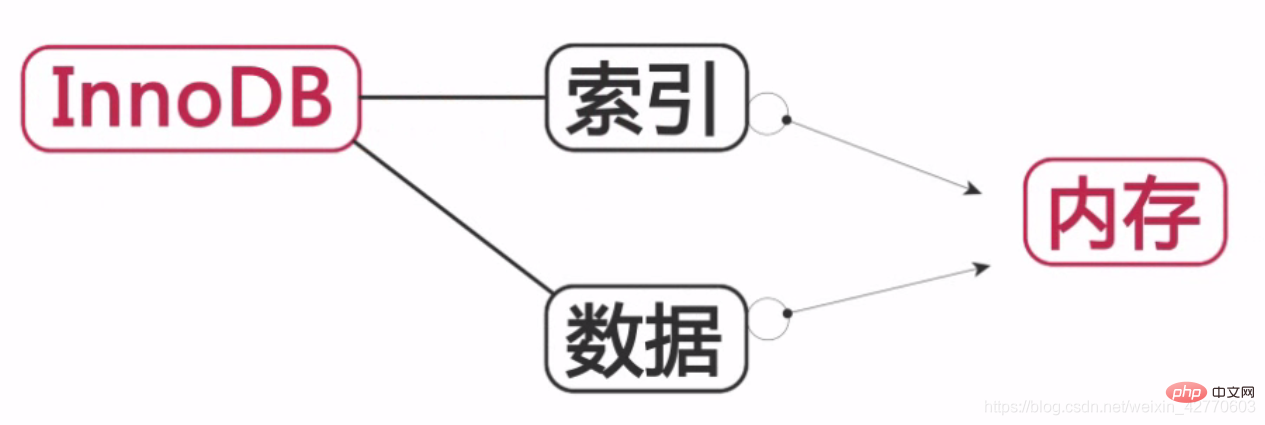
InnoDB:
索引和資料都保存在記憶體中,從而提高資料庫的運作效率。
2.1.2.2 提示
- 雖然記憶體的數量是越多越好,但是對系統的效能影響是有限的。
假如我們資料庫的資料有100G,那麼記憶體選擇在128G左右就可以達到最大的效能了,這時如果所有的資料都是熱數據,那麼都會快取在記憶體當中,沒有必要上256G的內存,但是選擇更大的內存,對於作業系統等其他服務的性能也會有相應的提高,並且在短期內不用考慮升級內存的問題。
- 對於記憶體快取的寫入操作時,可以進行延緩寫入,減少資料庫的壓力。
內存在讀取操作上已經有了很好的支持,在寫入操作上也可以在記憶體上完成,我們最後都需要將資料寫入到磁碟中,雖然不能避免寫入磁碟的操作,但是我們可以對寫入操作進行延緩,將多次寫入合併成一次寫入,減輕資料庫的壓力。資料庫提供了類似的功能,可以在快取池中將多次的寫入操作合併成一次,最終寫入磁碟。
2.1.2.3 如何選擇記憶體
#盡量使用主機板能夠支援最大頻率的記憶體
- 組成購買升級,每個通道的記憶體盡量相同品牌、顆粒、頻率、電壓、校驗技術和型號。
- 根據資料庫大小選擇記憶體。
2.2 磁碟的設定與選擇
雖然記憶體對資料庫效能有很大的作用,但我們不能忽略IO子系統對效能的影響。目前我們常用的磁碟選擇有以下4種:
2.2.1 使用傳統機器硬碟
特點:儲存空間大,價格低,使用最多,最常見,讀取、寫入較慢
- 儲存容量
- 傳輸速度
- 存取時間
- 主軸轉速
- 物理尺寸
2.2.2 使用RAID增強傳統機器硬碟的效能
2.2.2.1 什麼是RAID
RAID是磁碟冗餘餘隊列的簡稱(Redundant Arrays of Independent Disks),簡單來說RAID的作用就是把多個容量較小的磁碟組成一組容量更大的磁碟,並提供資料冗餘來確保資料完整性的技術。
2.2.2.2 RAID等級
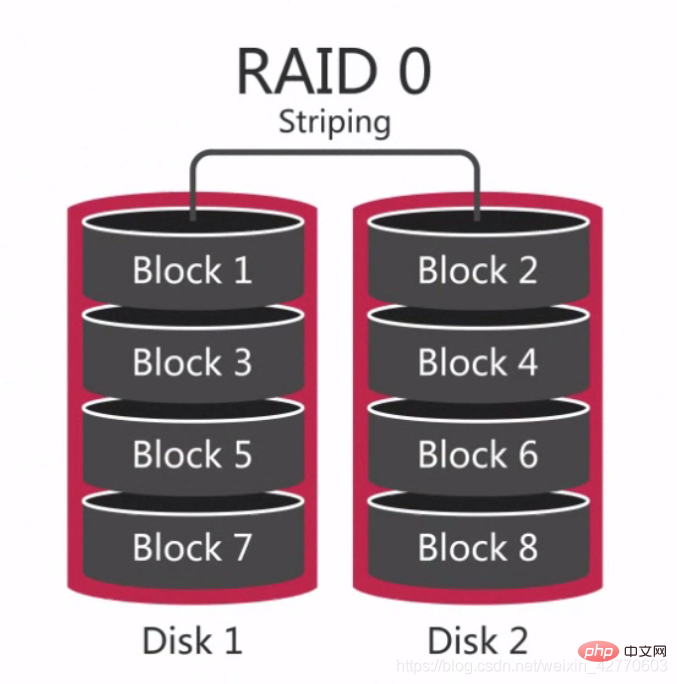
#2.2.2.2.1 RAID 0
#
RAID 0 是最早出現的RAID模式,也稱為資料條帶。是組件磁碟陣列中最簡單的一種形式,只需要2塊以上的硬碟即可,成本低,可以提高整個磁碟的效能和吞吐量。 RAID 0沒有提供冗餘或錯誤修復能力,但是實現成本是最低的。但在考慮到資料復原和可靠性因素,RAID 0成為了成本最高的配置,因為RAID 0中沒有冗餘,而且資料在損壞的機率在當個磁碟中的還要高。因為資料在任意一個磁碟中損壞都會造成資料的遺失。例如由3塊磁碟組成的RAID 0,其損壞的幾率是單一硬碟的3倍。
因此RAID 0適用於不會單一遺失資料的情況,例如:可以隨時可以從其他資料庫複製的備庫或某些只需一次性使用的資料庫。
簡單來說,RAID 0就是將硬碟串聯在一起,形成更大的磁碟,例如:
並且在並發的過程中,可以達到相當於單一硬碟3倍的效能。
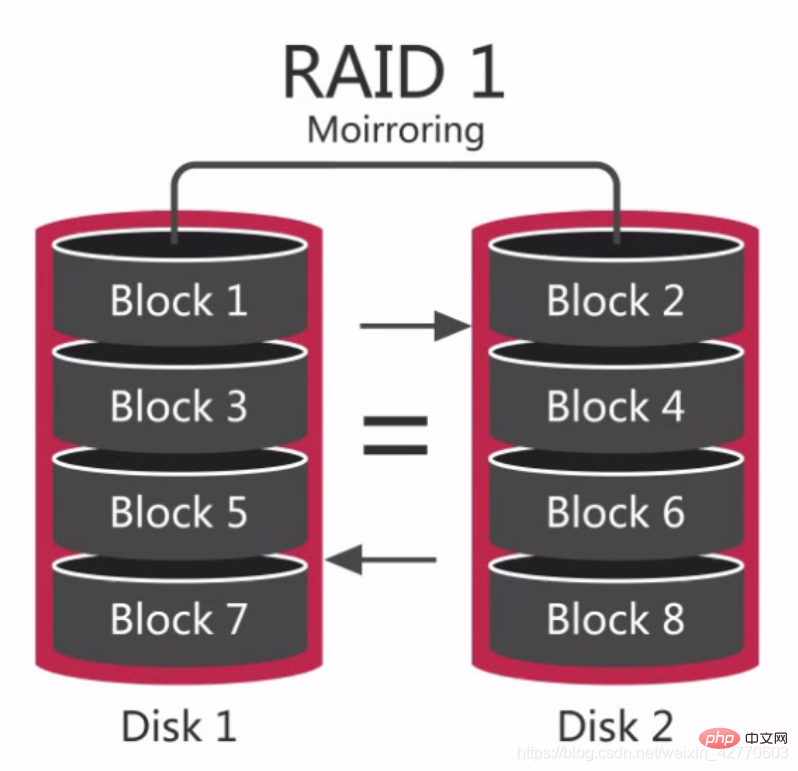
2.2.2.2.2 RAID 1
RAID 1 又稱磁碟映像,原理是把一個磁碟的資料鏡像到另一個磁碟上,也就是說數據在寫入一塊磁碟的同時,會在另一塊限制的磁碟上產生鏡像文件,在不影響效能情況下最大限度的保證系統的可靠性和可修復性。
它與RAID 0不同的地方在,中間的地方畫上了一個等於號。兩個磁碟的資料都是一樣的,具備良好的冗餘能力,但成本會相應的提高,當出現磁碟故障的情況下也可以正常運行,但需要即使更換故障的磁碟,否則系統也會崩潰。
在更換新的磁碟後,資料的同步需要消耗很多時間,雖然不會對資料的存取造成影響,但係統的效能是會下降的。
RAID 1在許多情況下,可以提供很好的讀取效能,並且在不同磁碟間冗餘數據,因此數據冗餘性很好。 RAID 1在讀取上比RAID 0 好,因此比較適合在存放日誌或類似的工作。
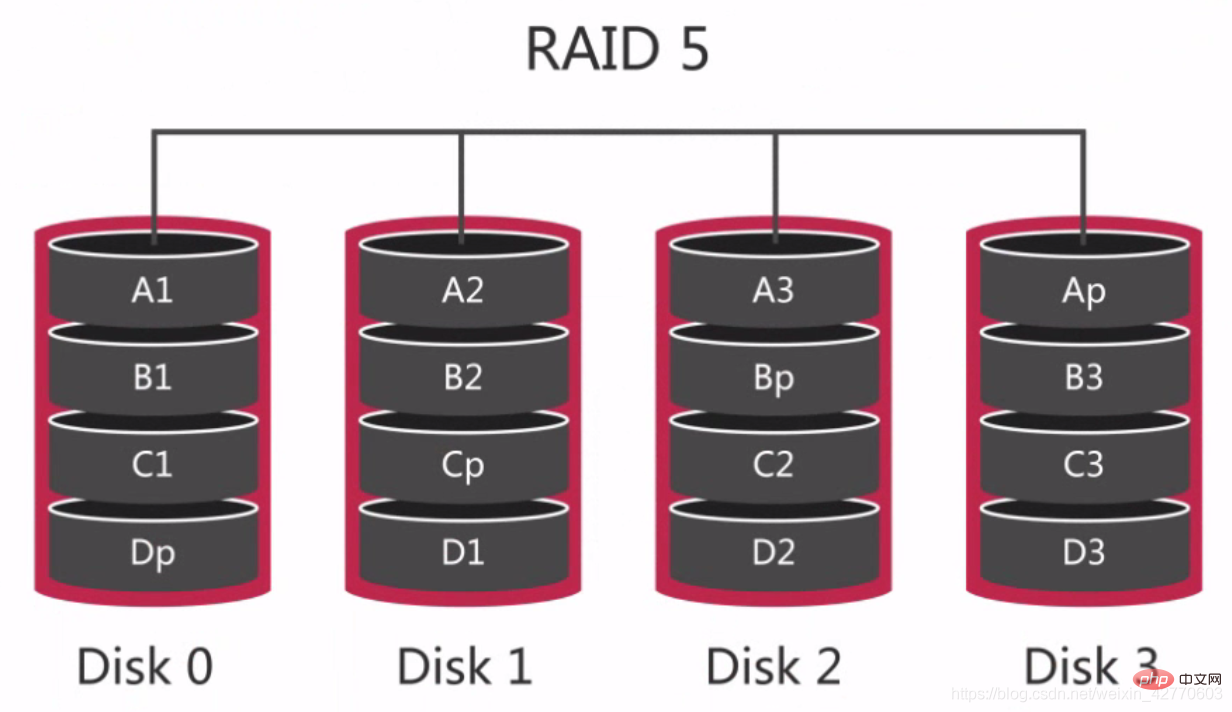
2.2.2.2.3 RAID 5 —— 常見的RAID組別
RAID 5 又稱為分散式奇偶校驗磁碟陣列。透過分散式奇偶校驗區塊把資料分散到多個磁碟上,這樣如果任何一個磁碟資料失效,都可以從奇偶校驗區塊重建。但是如果兩塊磁碟失效,則整個磁碟區的資料都無法復原。
可見,每個磁碟中分別有Dp,Cp,Bp,Ap,如果其中一塊磁碟出現問題,則可以透過其他三塊磁碟的資料和奇偶校驗值重新計算磁碟的數據。
對於RAID 0和RAID 1而言,這是最經濟的冗餘配置,因為整個陣列配置只需要1塊磁碟的容量就可以了。
在RAID 5上寫速度較慢,因為每次寫都要在磁碟之間進行2次讀和2次寫,以計算存儲校驗位的數值,但是,隨機讀和順序讀都很快,因為在讀取的時候不需要計算奇偶校驗位,因此RAID 5 更適合以讀為主的資料庫業務。
RAID 5發生的最大問題是在磁碟失效的時候,因為資料需要重新分配到其他磁碟上,這將會嚴重影響磁碟的效能,所以使用RAID 5最好使用在重讀的情況下。
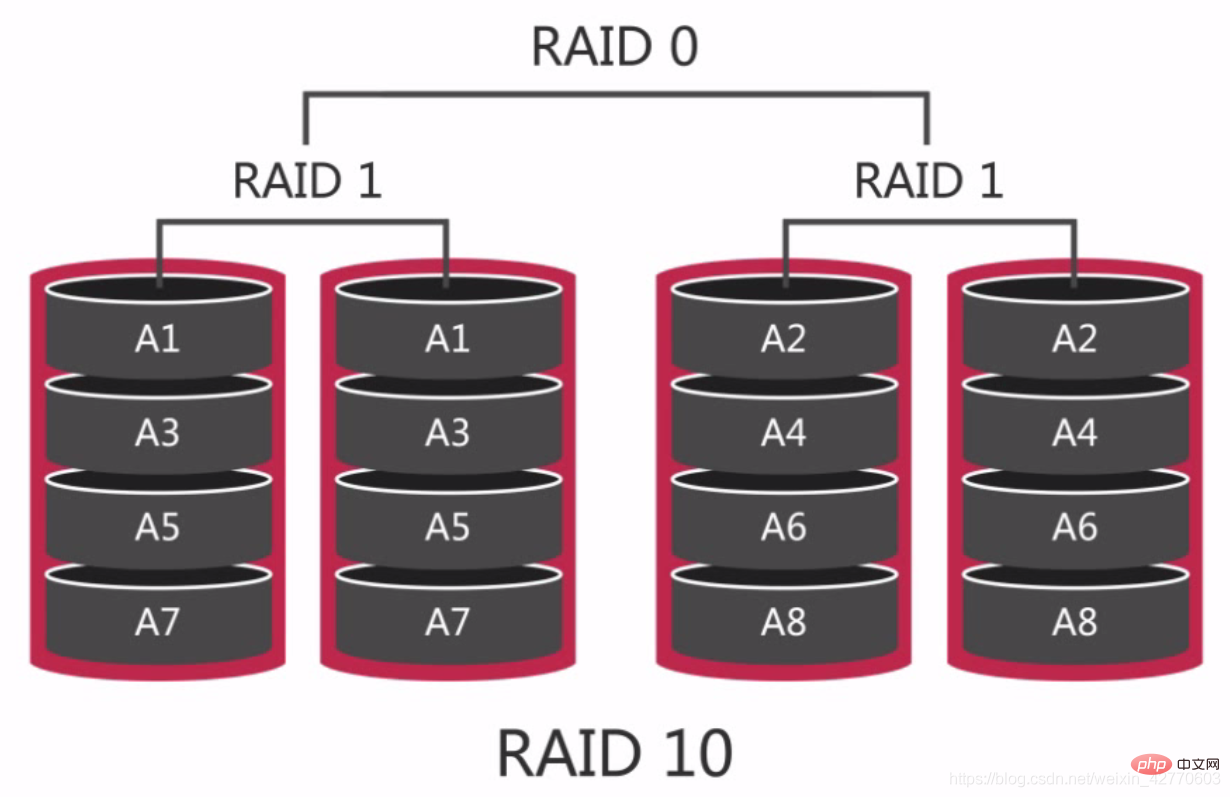
2.2.2.2.4 RAID 10 —— 常用的RAID組別
RAID 10又稱分片的鏡像。它是對磁碟先做RAID 1之後對兩組RAID 1的磁碟再做RAID 0,所以對讀寫都有良好的效能,相對於RAID 5重建起來更簡單,速度也更快。
在RAID 10上,如果損壞了一個硬碟,那麼對效能會造成嚴重的影響,因為在讀寫過程中,本來可以在兩塊相鄰的磁碟中同時讀取,如果損壞了一塊,那麼只能從單一磁碟進行讀取,因此最壞的情況下,我們的效能會降低50%。
2.2.2.3 RAID等級的選擇
| 等級 |
特點 |
是否冗餘 |
盤數 |
讀取 |
寫入 |
| RAID 0 |
便宜,快速,危險 |
否 |
N |
快 |
快 |
| #RAID 1 |
高速讀,簡單,安全性 |
有 |
2 |
快 |
慢 |
| #RAID 5 |
安全,成本折疊中 |
有 |
N 1 |
快 |
#取決於最慢的磁碟 |
##RAID 10 | 貴,高速,安全 | 有 | #2N | #快 | 快 |
2.2.3 使用固態儲存SSD和PCIe卡
固態儲存又稱為快閃記憶體。
特點:
- 比機械磁碟固態磁碟有更好的隨機讀寫效能
- 相比機械磁碟固態磁碟有更好的支援並發
- 比起機械磁碟固態磁碟更容易損壞
SSD特點:
- 使用SATA接口,可以替換傳統磁碟而不需任何改變
- SATA介面的SSD同樣支援RAID技術
固態儲存PCIe卡特點:
- 無法使用SATA接口,需要獨特的驅動與設定
- #價格相對於SSD更貴,但是效能比SSD更好
固態儲存的使用場景
- 適用於存在大量隨機I/O的場景
- 使用解決單一執行緒負載的I/O瓶頸
#2.2.4 使用網路儲存NAS和SAN
SAN( Strorage Area Network) 和NAS(Network-Attached Storage) 是兩種外部檔案儲存設備載入到伺服器上的方法。
SAN:
SAN設備透過光纖連接到伺服器,設備透過區塊介面訪問,伺服器可以將其當作硬碟使用。
SAN的特點:
NAS:
NAS設備使用網路連接,透過基於檔案的協定如NFS或SMB來訪問。
2.2.4.1 網路儲存使用的場景
適合使用在資料庫備份。
2.2.4.2 網路效能的限制
網路效能的限制主要是延遲和頻寬。
2.2.4.3 網路對效能的影響
- 網路頻寬對效能的影響
- 網路品質對效能的影響
建議:
- 採用高效能和高頻寬的網路介面設備和交換器
- 對多個網路卡進行綁定,增強可用性和頻寬
- 盡可能的進行網路隔離
2.3 總結
#CPU:
- 64位的CPU一定要工作在64位的系統下
- 對於並發比較高的場景CPU的數量比頻率重要
- 對於CPu密集型場景和複雜SQL則頻率越高越好
#記憶體:
- 選擇主機板所能使用的最高頻率的記憶體
- 記憶體的大小對效能很重要,所以盡可能的大
I /O子系統:
- PCIe -> SSD -> RAID10 -> 磁碟-> SAN
3 作業系統對效能的影響
MySQL適合的作業系統:Windows,FreeBSD,Solaris,Linux
3.1 CentOS系統參數最佳化
核心相關參數(/ etc/sysctl.conf)
-
net.core.somaxconn = 65535
對於處於一個監聽狀態的端口,都有一個自己的監聽佇列,這個參數決定了每個連接埠的監聽佇列的最大長度。這個參數的預設值可能會比較小,對於很大的伺服器來說是不夠的,一般會修改成2048或更大的值。
-
net.core.netdev_max_backlog=65535
#net.ipv4.tcp_max_syn_backlog=65535
其中backlog這個參數決定了在每個網路介面接收資料包的速率比內核處理機處理快的時候,允許被發送到佇列中的資料包的最大的數目,而另一個參數了是決定了這些還未獲得對方連線的這種請求可保存在隊中的最大數目。對於超過這個值大小的連接可能會被拋棄,所以要同時調大一些。
-
net.ipv4.tcp_fin_timeout = 10
這個參數是用來控制tcp連線處理的等待狀態的逾時時間。對於連線比較頻繁的系統,通常由大量的連線數處於等待狀態,而這個參數的設定就是減少連線逾時的時間,加快tcp的回收速度。同樣有對tcp連線有影響的參數有以下兩個:
net.ipv4.tcp_tw_reuse = 1、net.ipv4.tcp_tw_recycle = 1
# 這三個參數都是主要加快tcp的回收,在高負載的系統下,如果tcp連接被佔滿的話,就會出現連接資料庫500的錯誤,因此這三個參數的作用是很大的。
-
net.core.wmem_default = 87380、net.core.wmem_max = 16777216、net.core.r0mem_default = 87380、
-
-
-
- net.ipv4.tcp_keepalive_time = 120
、- net.ipv4.tcp_keepalive_intvl = 30、net.ipv4.tcp_keepalive_probes = 30、net.ipv4.tcp_keepalive_probes = 3以上三個參數用於減少失效連線所佔用的tcp系統資源的數量,加快資源回收的效率,
net.ipv4.tcp_keepalive_time
是表示tcp發送tcp_keepalive探測訊息的時間的間隔,單位為秒, 用於確認tcp連線是否有效。 net.ipv4.tcp_keepalive_intvl
用於當偵測這個tcp連線沒有反應後,重新傳送偵測訊息的時間間隔,單位為秒,net.ipv4.tcp_keepalive_probes
#表示在認定tcp連線失效前,需要發送多少個tcp_keepalive探測訊息。這三個參數的預設值對於一個平常系統來說稍微有點大了,所以這裡分別對它們改為了小了一些。
kernel.shmmax = 4294967295
這個參數是Linux核心參數中最重要的參數之一,用來定義單一共享記憶體段的最大值。
注意
:######這個參數應該設定的夠大,以便能在一個共享記憶體段下容納下整個的Innodb緩衝池的大小。 ######這個值的大小對於64為Linux系統,可取的最大值為物理記憶體值- 1 byte,建議值為大於物理記憶體段的一半,一般取直大於Innodb緩衝池的大小即可,可以取實體記憶體- 1 byte。 ###############vm.swappiness = 0###### 這個參數當記憶體不足時會對效能產生比較明顯的影響。這個參數就是告訴Linux系統核心除非虛擬記憶體完全滿了,否則不要使用交換區。 ######Linux系統記憶體交換分割區###:### 在Linux系統安裝時都會有一個###特殊的磁碟分割區###,稱為###系統交換分割區###。如果我們使用###free -m###在系統中查看可以看到類似下面的內容,其中###swap###就是交換分割區。當作業系統因為沒有足夠的記憶體時就會將一些###虛擬記憶體###寫到###磁碟的交換區中###這樣就會發生記憶體交換。 ### 在MySQL服務所在的Linux系統上完全停用交換分割區,會帶來以下兩點風險:#######降低作業系統的效能######容易造成###記憶體溢位## #,###崩潰###,或都被作業系統###Kill掉###################增加資源限制(/etc/security/limit.conf )######limit.conf###這個檔案實際上時Linx PAM也就是插入式認證模組的設定檔。 ### 其中比較重要的參數配置就是開啟檔案數的限制。 ######### 結論:把可開啟的檔案數量增加到了65535個以保證可以開啟足夠的檔案句柄。 ### 注意:這個檔案的修改需要重新啟動伺服器後才生效。 ###磁碟調度策略(/sys/block/devname/queue/scheduler)
可以使用指令cat /sys/block/sda/queue/scheduler來檢視目前磁碟所使用的調度策略。下面的noop anticipatory deadline [cfq]為系統預設的cfq調度策略。
在MySQL資料庫服務下,cfq並不合適,是由於在MySQL工作過程中,cfq會在佇列中插入一些不必要的請求,導致很差的回應時間。
除了cfq調度策略,還有以下幾種策略:
noop(電梯式排程策略):
deadline(截止時間排程策略):
anticipatory(預料I/O調度策略):
我們可以輸入以下指令來改變磁碟的調度策略:
echo schedulerName > / sys/block/sda/queue/scheduler
如:echo deadline > /sys/block/sda/queue/scheduler
#4 檔案系統對效能的影響
建議使用XFS檔案系統,在EXT3和EXT4下需要設定以下參數:
EXT3/4系統的掛載參數(/etc/fstab ):
-
data=writeback | ordered | journal
這個參數一共有三個可選擇的值,writeback表示只有元資料寫入到日誌,元資料寫入和資料寫入並不是同步的。這是最快的配置,因為InnoDB原本有自己的交易日誌,所以通常是InnoDB最好的選擇。 ordered只會記錄元數據,但提供了一些一致性的保證,在寫元數據之前,會先寫數據,使它們保持一致,這個選項比writeback稍微慢一點,但出現崩潰會比較安全。 journal提供了原子日誌的行為,在資料寫入到最終的日誌之前,將記錄到日誌中。這個選項對於InnoDB顯然是沒有必要的,也是三種中最慢的一種。
-
noatime、nodiratime
這兩個選項用來記錄檔案的存取時間和讀取目錄的時間。設定了這兩個參數可以減少一些寫好的操作。系統在讀取檔案和目錄時也不必寫入作業來記錄以上兩個時間。
以下是檔案/dev/sda1/ext4中的一些設定:
noatime,nodiratime,data=writeback 1 1
5 MySQL體系結構
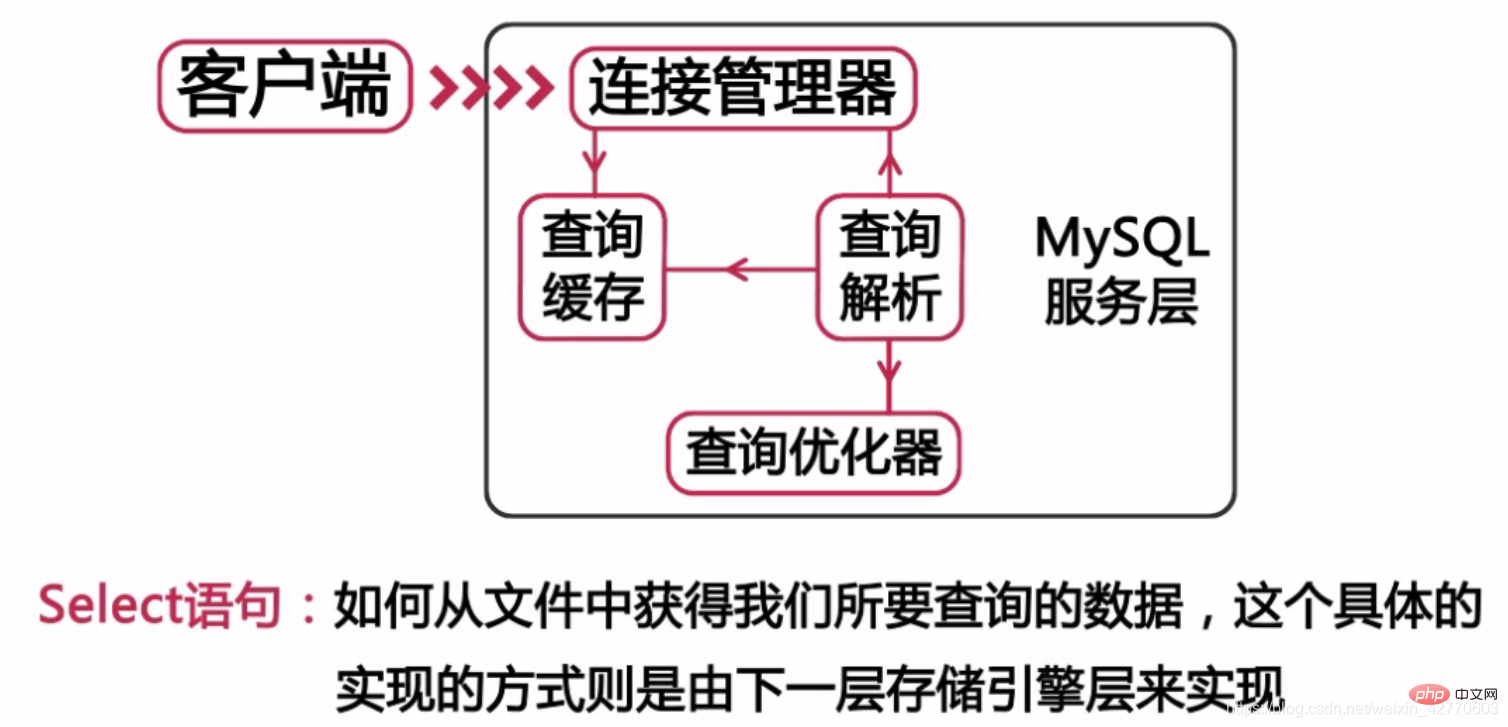
體系結構在最上層的叫做客戶端,這一層代表了可以透過mysql連線協定連接到mysql的客戶端,比如說PHP,JAVA,C API,.Net以及ODBC,JDBC等,從這裡可以看出,這一層並不是mysql體系結構所特有。大多數CS架構的服務都是採用了這一種體系架構。這一層主要是完成了連線處理,授權認證和安全等一些功能。每個連接到mysql的客戶端都在伺服器的進程中擁有一個線程,這個連接的查詢只會在這個線程中進行執行,也就是我們前面說到的,每個連接的查詢只用到一個CPU的核心。
那麼這個體系的第二層,大多數的mysql核心服務都在這一層中,如下圖所示。
我們常用的DDL或DML語句都是在這一層上定義的。但是我們只要記住一點就可以了,所有跨儲存引擎的功能都是在這一層中實現的,因為這一層也被稱之為服務層。
我們的結構體系的第三層是儲存引擎層,mysql是一款非常優秀的開源資料庫,其中定義了一系列了儲存引擎的接口,只要符合儲存引擎的要求,我們就可以對mysql開發出一款完全符合自己需求的儲存引擎,像是我們常用的InnoDB,目前mysql支援的儲存引擎很多,如下圖所示:
注意:儲存引擎是針對表的而不是針對於庫的(一個庫中的不同表可以使用不同的存儲引擎)
下面我們選一些比較常用的存儲引擎進行簡單的說明,mysql所使用的存儲引擎會對資料庫的效能產生直接的影響,也希望各位能仔細的了解儲存引擎的一些特點,完了之後才使用儲存引擎。
更多相關免費學習推薦:mysql教學#(影片)
#
以上是大數據學習的MYSQL進階的詳細內容。更多資訊請關注PHP中文網其他相關文章!








 這個參數是Linux核心參數中最重要的參數之一,用來定義單一共享記憶體段的最大值。
這個參數是Linux核心參數中最重要的參數之一,用來定義單一共享記憶體段的最大值。