

#免費學習推薦:mysql資料庫(視頻)
背景
阿里雲RDS FOR MySQL(MySQL5.7版本)資料庫業務表每月新增資料量超過千萬,隨著資料量持續增加,我們業務出現大表慢查詢,在業務高峰期主業務表的慢查詢需要幾十秒嚴重影響業務
##方案概述
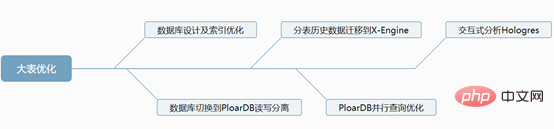
一、資料庫設計及索引最佳化
MySQL資料庫本身高度靈活,造成效能不足,嚴重依賴開發人員的表格設計能力以及索引最佳化能力,在這裡給幾點優化建議#二、資料庫切換到PloarDB讀寫分離
PolarDB是阿里雲自研的下一代關聯式雲端資料庫,100%相容MySQL儲存容量最高可達100 TB,單庫最多可擴充到16個節點,適用於企業多樣化的資料庫應用場景。 PolarDB採用儲存和計算分離的架構,所有計算節點共享一份數據,提供分鐘級的配置升降級、秒級的故障恢復、全局數據一致性和免費的數據備份容災服務。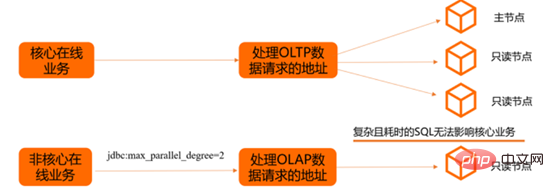
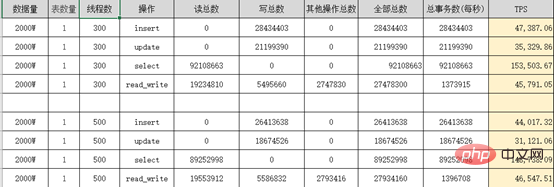
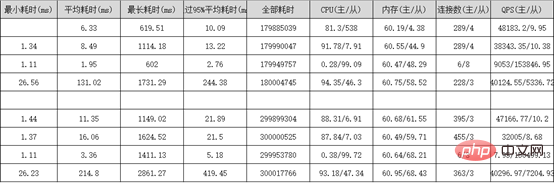
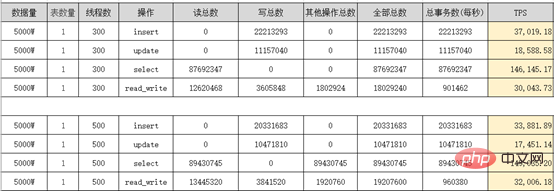
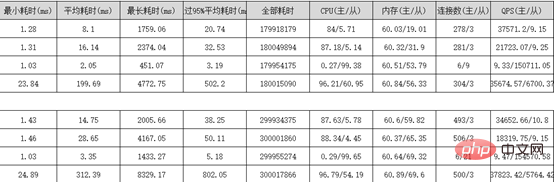
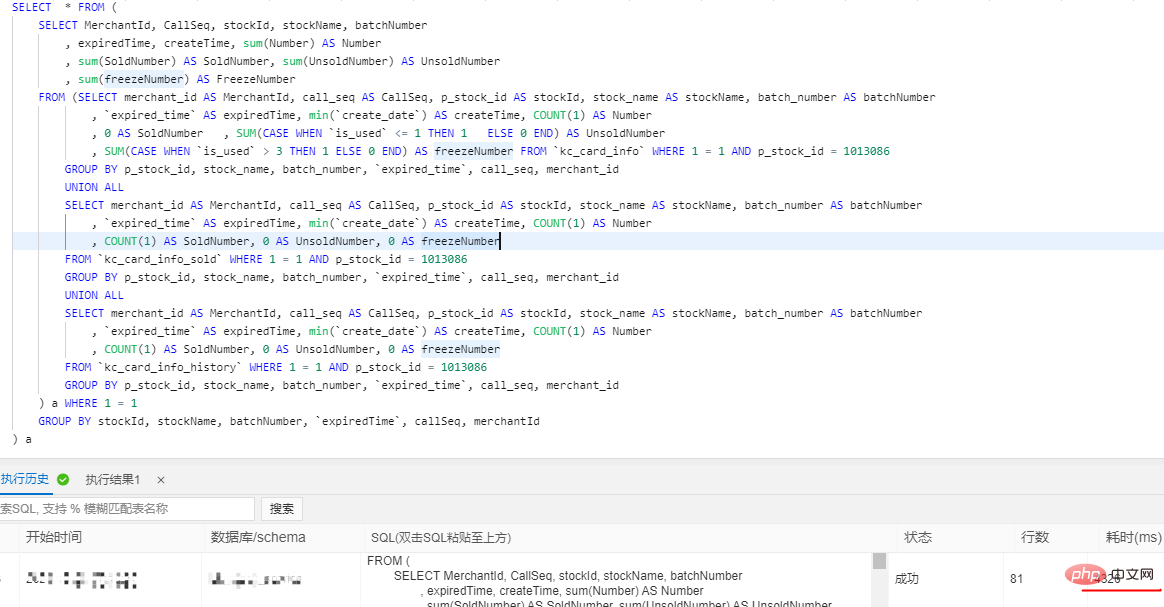
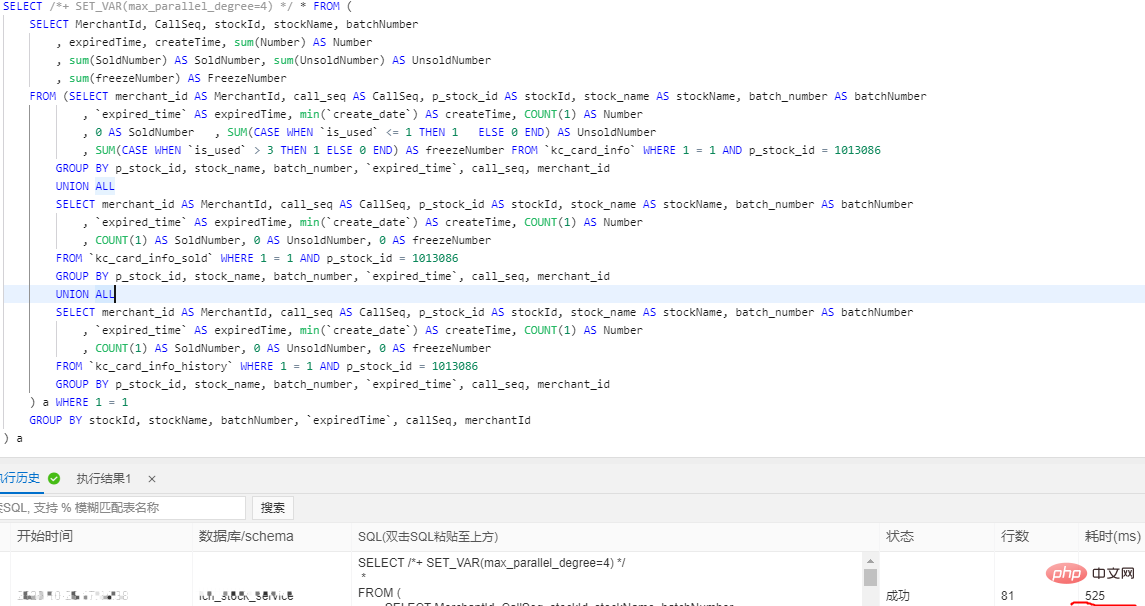
分錶業務表保留3個月資料(這個根據公司需求來),歷史資料按月分錶到歷史庫X-Engine儲存引擎表, 為什麼要選用X-Engine儲存引擎表,它有什麼優點? X-Engine是阿里雲資料庫產品事業部自研的線上事務處理OLTP(On-Line Transaction Processing)資料庫儲存引擎。 四、阿里雲PloarDB MySQL8.0版本並行查詢 分錶之後我們的資料量依然很大,並沒有完全解決我們的慢查詢問題,只是降低了我們業務表的體量,這部分慢查詢我們需要用到PolarDB的並行查詢優化 PolarDB MySQL 8.0重磅推出並行查詢框架,當您的查詢資料量到達一定閾值,就會自動啟動並行查詢框架,從而使查詢耗時指數級下降 並行查詢適用於大部分SELECT語句,例如大表查詢、多表連接查詢、計算量較大的查詢。對於非常短的查詢,效果不太顯著。 並行查詢用法,使用Hint語法可以對單一語句進行控制,例如係統預設關閉並行查詢情況下,但需要對某個高頻的慢SQL查詢進行加速,此時就可以使用Hint對特定SQL進行加速。 SELECT / PARALLEL(x)/ … FROM …; – x >0 SELECT /* SET_VAR(max_parallel_degree=n) */ * FROM … // n > 0 查詢測試:資料庫配置16核心32G 單表資料量超3千萬 沒加並行查詢之前是4326ms,加了之後是525ms,效能提升8.24倍 五、互動式分析Hologre 大表慢查詢我們雖然用並行查詢優化提升了效率,但是一些特定的需求實時報表、實時大屏我們還是無法實現,只能依賴大數據去處理。 六、後記 千萬級大表優化是根據業務場景,以成本為代價優化的,不是一上來就資料庫水平切分擴展,這樣會給運維和業務帶來巨大挑戰,很多時候效果不一定好,我們的資料庫設計、索引最佳化、分錶策略是否做到位了,應該根據業務需求選擇合適的技術去實現。 更多相關免費學習推薦:mysql教學#(影片)
X-Engine儲存引擎不僅可以無縫對接相容MySQL(得益於MySQL Pluginable Storage Engine特性),同時X-Engine使用分層儲存架構。因為目標是面向大規模的海量數據存儲,提供高並發事務處理能力和降低存儲成本,在大部分大數據量場景下,數據被訪問的機會是不均等的,訪問頻繁的熱數據實際上佔比很少,X-Engine根據資料存取頻度的不同將資料劃分為多個層次,針對每個層次資料的存取特點,設計對應的儲存結構,寫入適當的儲存裝置
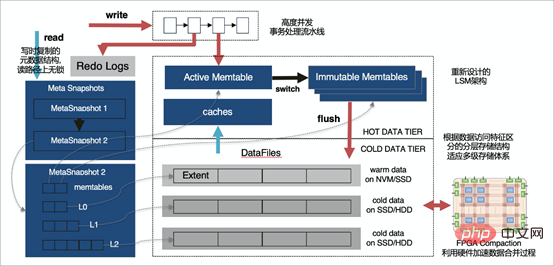
在存儲層將資料分片到不同的線程上,多個線程並行計算,將結果管線匯總到總線程,最後總線程做些簡單歸回給用戶,提高查詢效率。
平行查詢(Parallel Query)利用多核心CPU的平行處理能力,以8核心32 GB配置為例,示意圖如下。 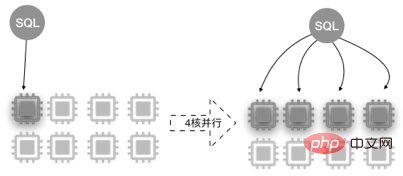
這裡推薦大家阿里雲的互動式分析Hologre(
https://help.aliyun.com/product/113622.html)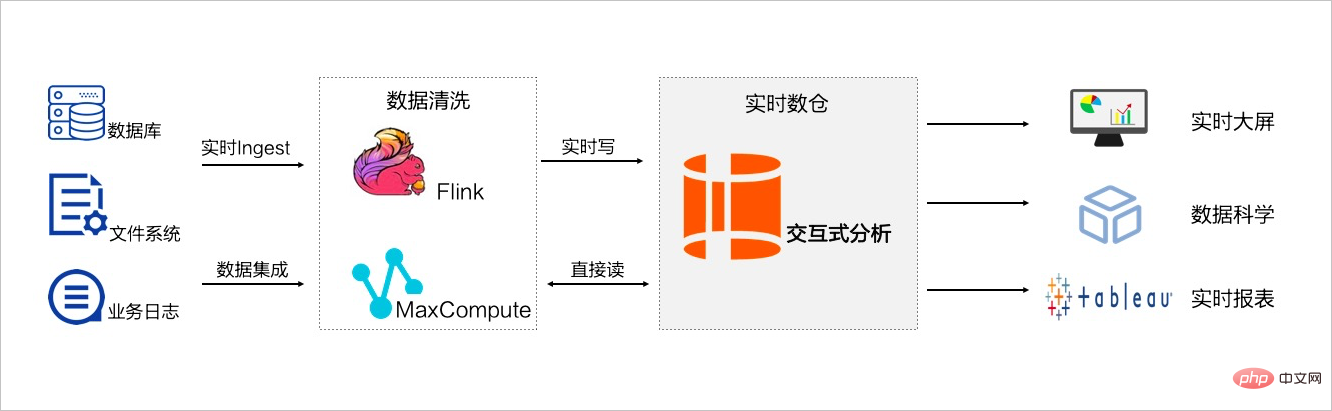
#
以上是介紹MySQL大表優化方案的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















