

筆記之 Python正規表達式


文章目錄
- 0、前言
- 1、正規表示式模式
- 2.正規表示式修飾符- 可選標誌
- 2.1、`re.IGNORECASE`(`re.I`)
- 2.2、`re.ASCII` (`re.A`)
- 2.3、`re.DOTALL`(`re.S`)
- 2.4、`re.MULTILINE`(`re.M`)
- 2.5、`re.VERBOSE`(re.X)
- 2.6、修飾符的疊加
- 3、正規表示式函數
-
- #3.1、尋找單一符合項目的函數
- Example 3.1.1
- Example 3.1.2
- #Example 3.1. 3
- 3.2、尋找多個符合項目的函數
- #Example 3.2.1
- 3.3、分割
- Example 3.3.1
import re
0、前言
本筆記基於菜鳥教程以及該知乎教程,融入了自己的一些學習心得。
1、正規表示式模式

#高亮處是我的補充,因為根據實際情況確實是能符合到的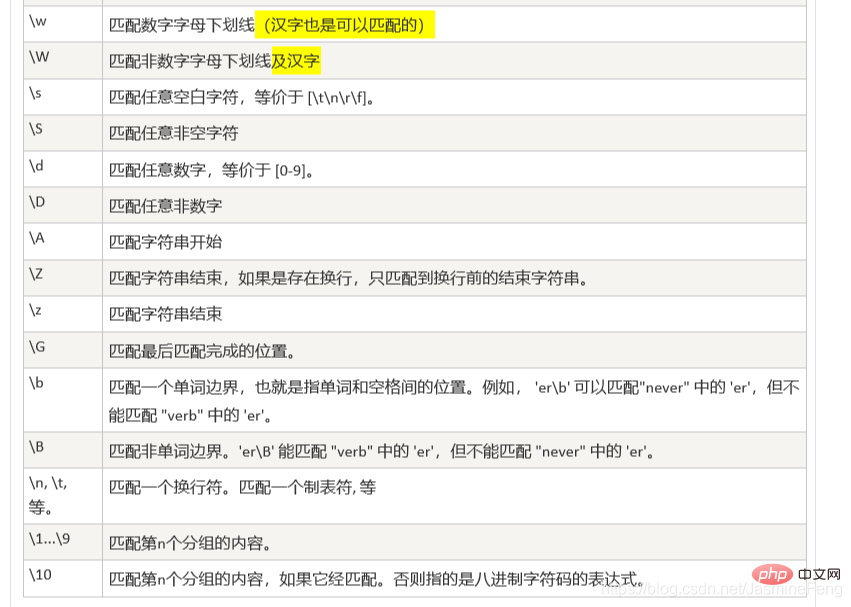
這邊我就偷點懶了哈,直接截的是菜鳥教學的圖。
2、正規表示式修飾符- 可選標誌
#2.1、re.IGNORECASE(re.I )
雖然第1節是常數,但我們必須先簡單提一下re.findall這個函數,因為它是貫穿這一節的函數。 re.findall(pattern, string, flag=0): 從字串任意位置找出,傳回一個清單。 pattern是想要匹配的字元(字串),string是查找來源,flag是修飾符,預設是0
re.I的作用是忽略字元大小寫
text = "I'm Jasmine-Feng. My student number is No. 321432"pattern = r"Jasmine-FENG"print('Default: ', re.findall(pattern,text))print('Ignore upper/lower case: ', re.findall(pattern,text,flags=re.I))N.B. pattern被賦了一個r字串,這個r字串的作用是避免轉義,r是raw的縮寫,也就是保持原樣的意思。可看這篇文章。一般來說,使用正規表示式都會用到這個r字串。
Default: []Ignore upper/lower case: ['Jasmine-Feng']Process finished with exit code 0
在預設情況下,區分大小寫,找不到ENG;若不區分,則可以找到eng。
2.2、re.ASCII(re.A)
re.A的作用是只匹配ASCII碼支援的字符,那麼具體指哪些字符呢?下圖來自百度百科。 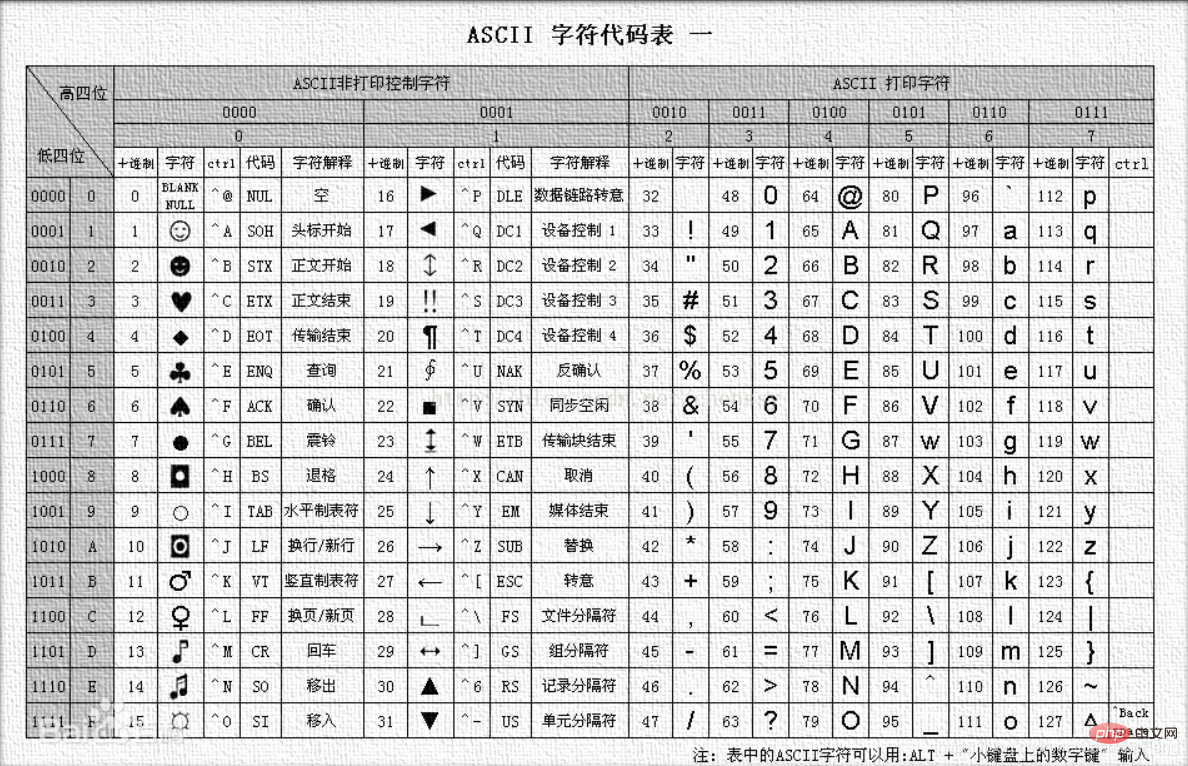
漢字是不在這個裡面的,所以如果修飾符是re.A的話就匹配不了漢字了哈~
text = "我是Jasmine-Feng. 我的学号是No. 321432"pattern = r"\w+"print('Default: ', re.findall(pattern,text))print('ASCII: ', re.findall(pattern,text,flags=re.A))\w 的功能是匹配一個或多個字母數字下劃線漢字
Default: ['我是Jasmine', 'Feng', '我的学号是No', '321432']ASCII: ['Jasmine', 'Feng', 'No', '321432']Process finished with exit code 0
2.3、re.DOTALL(re.S)

在正規表示式模式中,.是用來
text = "我\t是Jasmine-F\neng. 我%的◉学号是No. 321432"pattern = r'.*'print('Default: ', re.findall(pattern,text))print('DOTALL: ', re.findall(pattern,text,re.S)).*的作用是符合長度至少為0的字元(串),emmm,好像是句廢話?事實上,只要整段話不被換行符號截斷,就可以得到整個字串(外加一個空字串)。 Default: ['我\t是Jasmine-F', '', 'eng. 我%的◉学号是No. 321432', '']DOTALL: ['我\t是Jasmine-F\neng. 我%的◉学号是No. 321432', '']Process finished with exit code 0
2.4、re.MULTILINE(re.M)##$符合定位到字串結尾,
定位到字串開頭,預設情況下,如果換行,是不能定位到新一行的行頭/尾的,而用re.M修飾則可以,也就是多行模式。
text = "我\t是Jasmine-F\neng. 我%的◉\n学号是No. 321432"pattern = r'.$'pattern2 = r'^.'print('Default, end: ', re.findall(pattern, text))print('MULTILINE, end: ', re.findall(pattern, text, re.M))print('Default, start: ', re.findall(pattern2, text))print('MULTILINE, start: ', re.findall(pattern2, text, re.M))Default, end: ['2']MULTILINE, end: ['F', '◉', '2']Default, start: ['我']MULTILINE, start: ['我', 'e', '学']Process finished with exit code 0
2.5、re.VERBOSE
verbose是「詳實的、冗長的」意思,透過該修飾符可以在
正規表示式中加入註解。請注意,是往pattern裡面加,不是往
text
text = '朋友们好啊!我是xxxxxx拳掌门人xxx~'pattern = r'''朋友们 # 主语 好啊! # 谓语 '''print(re.findall(pattern, text,re.VERBOSE)) 登入後複製 ['朋友们好啊!']Process finished with exit code 0 登入後複製 |
2.6、修飾符的疊加 |
|---|---|
text = 'Hello everybody!\n我是xxxxxx拳掌门人xxx~'pattern = r'BODY.*$'print(re.findall(pattern, text, re.I))print(re.findall(pattern, text, re.M))print(re.findall(pattern, text, re.M | re.I)) 登入後複製 [][]['body!']Process finished with exit code 0 登入後複製 |
|
| #函數 |
|
#search |
############match#########從開頭搜索,不用完全符合##############fullmatch#### #####從開頭搜索,必須完全匹配###############其實我本來是寫了自己的例子的,但是瀏覽器給我誤關了,又沒保存(心態直接炸裂
以上是筆記之 Python正規表達式的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP和Python:解釋了不同的範例
Apr 18, 2025 am 12:26 AM
PHP主要是過程式編程,但也支持面向對象編程(OOP);Python支持多種範式,包括OOP、函數式和過程式編程。 PHP適合web開發,Python適用於多種應用,如數據分析和機器學習。
 在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之間進行選擇:指南
Apr 18, 2025 am 12:24 AM
PHP適合網頁開發和快速原型開發,Python適用於數據科學和機器學習。 1.PHP用於動態網頁開發,語法簡單,適合快速開發。 2.Python語法簡潔,適用於多領域,庫生態系統強大。
 PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他們的歷史
Apr 18, 2025 am 12:25 AM
PHP起源於1994年,由RasmusLerdorf開發,最初用於跟踪網站訪問者,逐漸演變為服務器端腳本語言,廣泛應用於網頁開發。 Python由GuidovanRossum於1980年代末開發,1991年首次發布,強調代碼可讀性和簡潔性,適用於科學計算、數據分析等領域。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中運行嗎
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上運行,但體驗可能不佳。首先確保系統已更新到最新補丁,然後下載與系統架構匹配的VS Code安裝包,按照提示安裝。安裝後,注意某些擴展程序可能與Windows 8不兼容,需要尋找替代擴展或在虛擬機中使用更新的Windows系統。安裝必要的擴展,檢查是否正常工作。儘管VS Code在Windows 8上可行,但建議升級到更新的Windows系統以獲得更好的開發體驗和安全保障。
 sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
sublime怎麼運行代碼python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中運行 Python 代碼,需先安裝 Python 插件,再創建 .py 文件並編寫代碼,最後按 Ctrl B 運行代碼,輸出會在控制台中顯示。
 visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用於 python 嗎
Apr 15, 2025 pm 08:18 PM
VS Code 可用於編寫 Python,並提供許多功能,使其成為開發 Python 應用程序的理想工具。它允許用戶:安裝 Python 擴展,以獲得代碼補全、語法高亮和調試等功能。使用調試器逐步跟踪代碼,查找和修復錯誤。集成 Git,進行版本控制。使用代碼格式化工具,保持代碼一致性。使用 Linting 工具,提前發現潛在問題。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
