#免費學習推薦:mysql教學(視頻)
一、準備工作
1、安裝MySQL資料庫
Shell腳本一鍵部署-原始碼編譯安裝MySQL
2、實驗準備,資料表配置
mysql -uroot -p
show databases;
create database train_ticket;
use train_ticket;
create table REGION(region varchar(10),site varchar(20));
create table FARE(site varchar(20),money int(10),date varchar(15));
desc REGION;
desc FARE;
insert into REGION values ('south','changsha');
insert into REGION values ('south','nanchang');
insert into REGION values ('north','beijing');
insert into REGION values ('north','tianjin');
insert into FARE values ('changsha',1000,'2021-01-30');
insert into FARE values ('nanchang',700,'2021-01-30');
insert into FARE values ('beijing',1500,'2021-01-30');
insert into FARE values ('tianjin',1200,'2021-01-30');
insert into FARE values ('beijing',2200,'2021-02-05');
select * from REGION;
select * from FARE;

#二、MySQL 高階(進階) SQL 語句
1、SELECT
顯示表格中一個或數個欄位的所有資料
語法:SELECT 欄位FROM 表名select region from REGION;
2、DISTINCT
不顯示重複的資料(去重)
語法:SELECT DISTINCT 字段FROM 表名select distinct region from REGION;
3、WHERE
有條件查詢
語法:SELECT 字段FROM表名WHERE 條件select site from FARE where money > 1000;
select site from FARE where money
4、AND、OR
and(並且)、or(或)
語法:SELECT 字段FROM 表名WHERE 條件1 ([AND|OR] 條件2) ;select site from FARE where money > 1000 and (money = 700);
select site,money,date from FARE where money >= 500 and (date
#5、IN
顯示已知的值的資料
語法:SELECT 欄位FROM 表名WHERE 欄位IN ('值1','值2',……);select site,money from FARE where money in (700,1000);
#6、BETWEEN
語法:SELECT 欄位FROM 表名WHERE 欄位BETWEEN '值一' and '值二';
select * from FARE where money between 500 and 1000;
通常通配符都是跟LIKE一起使用
%:百分號表示零個、一個或多個字元
LIKE:用於匹配模式來尋找資料 語法:SELECT 欄位FROM 表格名稱WHERE 欄位LIKE '模式';
select * from FARE where site like 'be%'; select site,money from FARE where site like '%jin_';
8、ORDER BY
依關鍵字排序select * from FARE order by money desc; select date,money from FARE order by money desc; 登入後複製 |
函數 |
|---|---|
| 1、數學函數 | |
| #abs(x) | |
| 傳回0 到1 的隨機數 | |
| 傳回x 除以y 以後的餘數 | |
| 傳回x 的y 次方 | |
| 傳回離x 最近的整數 | |
| 保留x 的y 位小數四捨五入後的值 | |
| #傳回x 的平方根 | ##truncate(x,y) |
| ceil(x) | |
| floor(x) |

 返回集合中最大的值
返回集合中最大的值
least(x1,x2…)
##select abs(-1),rand(),mod(5,3),power(2,3),round (1.579),round(1.734,2); 登入後複製 |
|
|---|---|
| 2、聚合函數 | |
| 傳回指定列的平均值 | |
| count() | 傳回指定列中非NULL 值的個數 |
| min() | 傳回指定列的最小值 |
select avg(money) from FARE; select count(money) from FARE; select min(money) from FARE; select max(money) from FARE; select sum(money) from FARE;
#count(*)包括所有列的行数,在统计结果时,不好忽略值为null
#count(字段)只包括那一行的列数,在统计结果的时候,会忽略列值为null的值
3、字符串函数
| trim() | 返回去除指定格式的值 |
|---|---|
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
select trim(leading 'na' from 'nanchang');
select trim(trailing '--' from 'nanchang--');
select trim(both '--' from '--nanchang--');
select concat(region,site) from REGION where region = 'south';
select concat(region,' ',site) from REGION where region = 'south';
select substr(money,1,2) from FARE;
select length(site) from FARE;
select replace(site,'ji','--') from FARE;
select upper(site) from FARE;
select lower('HAHAHA');
select left(site,2) from FARE;
select right(site,3) from FARE;
select repeat(site,2) from FARE;
select space(2);
select strcmp(100,200);
select reverse(site) from FARE;4、| | 连接符
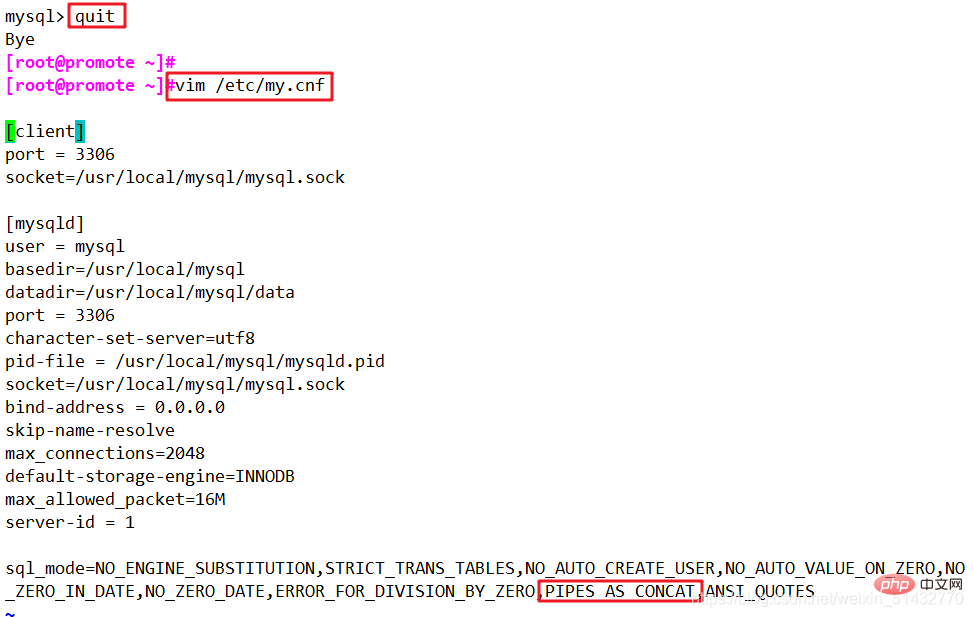
如果sql_mode开启开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
mysql -uroot -p use train_ticket; select region || ' ' || site from REGION where region = 'north'; select site || ' ' || money || ' ' || date from FARE;
5、GROUP BY
BY后面的栏位的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,就是 SELECT 后面的所有列中,没有使用聚合函数的列,必须出现在GROUP BY后面。
语法:SELECT 字段1,SUM(字段2) FROM 表名 GROUP BY 字段1;
select site,sum(money) from FARE group by site; select site,sum(money),date from FARE group by site order by money desc; select site,count(money),sum(money),date from FARE group by site order by money desc;
6、HAVING
用来过滤由GROUP BY语句返回的记录集,通常与GROUP BY语句联合使用。
HAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。如果被SELECT的只有函数栏,那就不需要GROUP BY子句。
语法:SELECT 字段1,SUM(字段2) FROM 表名 GROUP BY 字段1 HAVING(函数条件);
select site,count(money),sum(money),date from FARE group by site having sum(money) >=700;
7、别名
字段别名、表格别名
语法:SELECT “表格別名”.“字段1” [AS] “字段1別名” FROM “表格名” [AS] “表格別名”;
select RE.region AS reg, count(site) from REGION AS RE group by reg; select FA.site AS si,sum(money),count(money),date AS da from FARE AS FA group by si;
8、子查询
连接表格,在WHERE 子句或HAVING 子句中插入另一个SQL 语句
语法:SELECT 字段1 FROM 表格1 WHERE 字段2 [比较运算符] (SELECT 字段1 FROM 表格2 WHERE 条件)
可以是符号的运算符
例:=、>、=、
也可以是文字的运算符
例:LIKE、IN、BETWEEN
select A.site,region from REGION AS A where A.site in(select B.site from FARE AS B where money<blockquote><p><strong>相关免费推荐:<a href="https://www.php.cn/sql/" target="_blank">SQL教程</a></strong></p></blockquote>
以上是介紹高階進階的MySQL資料庫SQL語句的詳細內容。更多資訊請關注PHP中文網其他相關文章!