

冒泡排序、快速排序和堆排序的時間複雜度是多少

冒泡排序的時間複雜度:最好情況是“O(n)”,最壞情況是“O(n2)”。快速排序的時間複雜度:最好情況是“O(nlogn)”,最壞情況是“O(n2)”。堆排序的時間複雜度是「O(nlogn)」。

本教學操作環境:windows7系統、Dell G3電腦。
冒泡排序(Bubble Sort)
時間複雜度
最好的情況:陣列本身是順序的,外層迴圈遍歷一次就完成O(n)
最壞的情況:數組本身是逆序的,內外層遍歷O(n2)
#空間複雜度
開啟一個空間交換順序O(1)
##穩定性
穩定,因為if判斷不成立,就不會交換順序,不會交換相同元素
- 冒泡排序它在所有排序演算法中最簡單。然而, 從運行時間的角度來看,冒泡排序是最糟糕的一個,它的
複雜度是O(n2)。
- 冒泡排序比較任何兩個相鄰的項,如果第一個比第二個大,則交換它們。元素項向上移動至正確的順序,就好像
氣泡升至表面一樣,冒泡排序因此得名。
- 交換時,我們用一個中間值來儲存某一交換項的值。其他排序法也會用到這個方法,因此我 聲明一個方法放置這段交換程式碼以便重複使用。使用ES6(ECMAScript 2015)**增強的物件屬性-物件陣列的解構賦值語法,**這個函數可以寫成下面這樣:
[array[index1], array[index2]] = [array[index2], array[index1]];
function bubbleSort(arr) {
for (let i = 0; i < arr.length; i++) {//外循环(行{2})会从数组的第一位迭代 至最后一位,它控制了在数组中经过多少轮排序
for (let j = 0; j < arr.length - i; j++) {//内循环将从第一位迭代至length - i位,因为后i位已经是排好序的,不用重新迭代
if (arr[j] > arr[j + 1]) {//如果前一位大于后一位
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];//交换位置
}
}
}
return arr;
}時間複雜度 最好的情況:每個base值都剛好平分整個數組,
O(nlogn) 最糟的情況:每一次base值都是陣列中的最大/最小值,
O(n2)
空間複雜度# 快速排序是遞歸的,需要藉助棧來保存每一層遞歸的呼叫訊息,所以空間複雜度和遞歸樹的深度一致
最好的情況:每一次base值都剛好平分整個數組,遞歸樹的深度
O(logn) 最糟的情況:每個base值都是陣列中的最大/最小值,遞迴樹的深度
O(n)
穩定性 快速排序是
不穩定的,因為可能會交換相同的關鍵字。 快速排序是遞歸的,
特殊情況:left>right,直接退出。
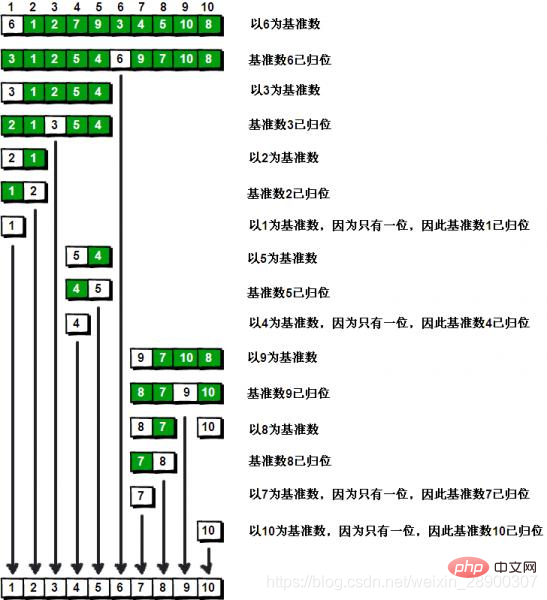
步驟:
(1) 首先,從陣列中選取中間一項作為主元base,一般取第一個值。
(2) 建立兩個指標,左邊一個指向數組第一個項,右邊一個指向數組最後一個項。 移動右邊指標直到找到一個比主元小的元素,接著,移動左指標直到我們找到一個比主元大的元素,然後交換它們 ,重複這個過程,直到左邊指針遇見了右指針。這個過程將使得比主元小的值都排在主元之前,而比主元大的值都排在主元之後。這一步叫作劃分運算。
(3)然後交換主元和指標停下來的位置的元素(等於說是把這個元素歸位,這個元素左邊的都比他小,右邊的都比他大,這個位置就是他最終的位置)
(4) 接著,演算法對劃分後的小數組(較主元小的值組成的子數組,以及較主由元大的值組成的子數組)重複之前的兩個步驟(遞歸方法),
遞歸的出口為left/right=i,也就是:
left>i-1 / i+1>right
function quicksort(arr, left, right) {
if (left > right) {
return;
}
var i = left,
j = right,
base = arr[left]; //基准总是取序列开头的元素
// var [base, i, j] = [arr[left], left, right]; //以left指针元素为base
while (i != j) {
//i=j,两个指针相遇时,一次排序完成,跳出循环
// 因为每次大循环里面的操作都会改变i和j的值,所以每次循环/操作前都要判断是否满足i<j
while (i < j && arr[j] >= base) {
//寻找小于base的右指针元素a,跳出循环,否则左移一位
j--;
}
while (i < j && arr[i] <= base) {
//寻找大于base的左指针元素b,跳出循环,否则右移一位
i++;
}
if (i < j) {
[arr[i], arr[j]] = [arr[j], arr[i]]; //交换a和b
}
}
[arr[left], arr[j]] = [arr[j], arr[left]]; //交换相遇位置元素和base,base归位
// let k = i;
quicksort(arr, left, i - 1); //对base左边的元素递归排序
quicksort(arr, i + 1, right); //对base右边的元素递归排序
return arr;
}堆排序
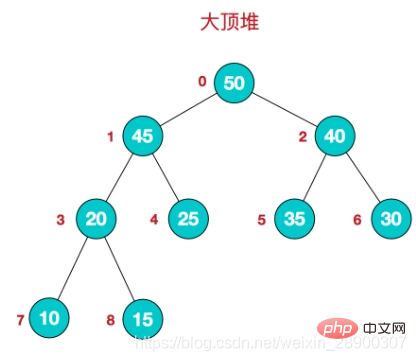
堆的概念- 堆是一个完全二叉树。
- 完全二叉树: 二叉树除开最后一层,其他层结点数都达到最大,最后一层的所有结点都集中在左边(左边结点排列满的情况下,右边才能缺失结点)。
- 大顶堆:根结点为最大值,每个结点的值大于或等于其孩子结点的值。
- 小顶堆:根结点为最小值,每个结点的值小于或等于其孩子结点的值。
- 堆的存储: 堆由数组来实现,相当于对二叉树做层序遍历。如下图:


时间复杂度
总时间为建堆时间+n次调整堆 —— O(n)+O(nlogn)=O(nlogn)建堆时间:从最后一个非叶子节点遍历到根节点,复杂度为O(n)n次调整堆:每一次调整堆最长的路径是从树的根节点到叶子结点,也就是树的高度logn,所以每一次调整时间复杂度是O(logn),一共是O(nlogn)
空间复杂度
堆排序只需要在交换元素的时候申请一个空间暂存元素,其他操作都是在原数组操作,空间复杂度为O(1)
稳定性
堆排序是不稳定的,因为可能会交换相同的子结点。
步骤一:建堆
- 以升序遍历为例子,需要先将将初始二叉树转换成大顶堆,要求满足:
树中任一非叶子结点大于其左右孩子。 - 实质上是调整数组元素的位置,不断比较,做交换操作。
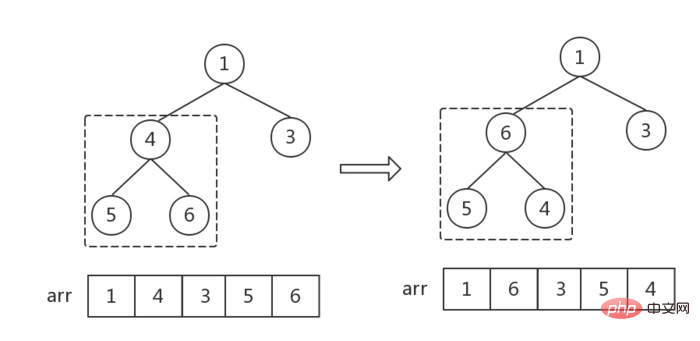
- 找到第一个非叶子结点——
Math.floor(arr.length / 2 - 1),从后往前依次遍历 - 对每一个结点,检查结点和子结点的大小关系,调整成大根堆
// 建立大顶堆
function buildHeap(arr) {
//从最后一个非叶子节点开始,向前遍历,
for (let i = Math.floor(arr.length / 2 - 1); i >= 0; i--) {
headAdjust(arr, i, arr.length); //对每一个节点都调整堆,使其满足大顶堆规则
}
}步骤二:调整指定结点形成大根堆
- 建立
childMax指针指向child最大值节点,初始值为2 * cur + 1,指向左节点 - 当左节点存在时(左节点索引小于数组
length),进入循环,递归调整所有节点位置,直到没有左节点为止(cur指向一个叶结点为止),跳出循环,遍历结束 - 每次循环,先判断右节点存在时,右节点是否大于左节点,是则改变childMax的指向
- 然后判断cur根节点是否大于childMax,
- 大于的话,说明满足大顶堆规律,不需要再调整,跳出循环,结束遍历
- 小于的话,说明不满足大顶堆规律,交换根节点和子结点,
- 因为交换了节点位置,子结点可能会不满足大顶堆顺序,所以还要判断子结点然后,改变
cur和childMax指向子结点,继续循环判断。
//从输入节点处调整堆
function headAdjust(arr, cur, len) {
let intialCur = arr[cur]; //存放最初始的
let childMax = 2 * cur + 1; //指向子树中较大的位置,初始值为左子树的索引
//子树存在(索引没超过数组长度)而且子树值大于根时,此时不符合大顶堆结构,进入循环,调整堆的结构
while (childMax < len) {
//判断左右子树大小,如果右子树更大,而且右子树存在,childMax指针指向右子树
if (arr[childMax] < arr[childMax + 1] && childMax + 1 < len) childMax++;
//子树值小于根节点,不需要调整,退出循环
if (arr[childMax] < arr[cur]) break;
//子树值大于根节点,需要调整,先交换根节点和子节点
swap(arr, childMax, cur);
cur = childMax; //根节点指针指向子节点,检查子节点是否满足大顶堆规则
childMax = 2 * cur + 1; //子节点指针指向新的子节点
}
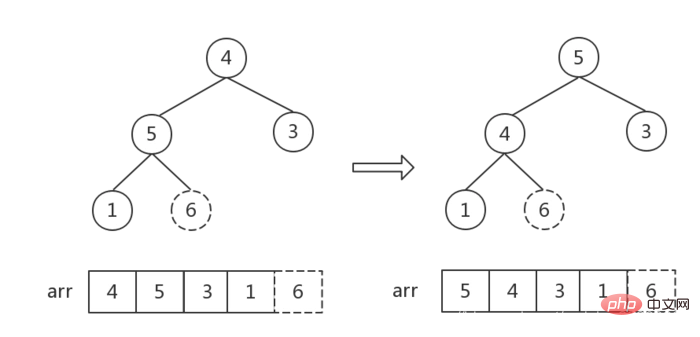
}步骤三:利用堆进行排序
- 从后往前遍历大顶堆(数组),交换堆顶元素
a[0]和当前元素a[i]的位置,将最大值依次放入数组末尾。 - 每交换一次,就要重新调整一下堆,从根节点开始,调整
根节点~i-1个节点(数组长度为i),重新生成大顶堆
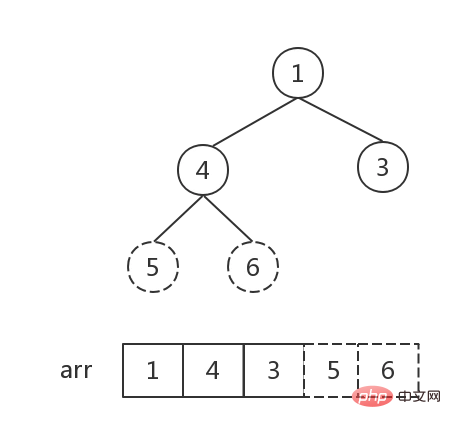
// 堆排序
function heapSort(arr) {
if (arr.length <= 1) return arr;
//构建大顶堆
buildHeap(arr);
//从后往前遍历,
for (let i = arr.length - 1; i >= 0; i--) {
swap(arr, i, 0); //交换最后位置和第一个位置(堆顶最大值)的位置
headAdjust(arr, 0, i); //调整根节点~i-1个节点,重新生成大顶堆
}
return arr;
}完整代码:
// 交换数组元素
function swap(a, i, j) {
[a[i], a[j]] = [a[j], a[i]];
}
//从输入节点处调整堆
function headAdjust(arr, cur, len) {
let intialCur = arr[cur]; //存放最初始的
let childMax = 2 * cur + 1; //指向子树中较大的位置,初始值为左子树的索引
//子树存在(索引没超过数组长度)而且子树值大于根时,此时不符合大顶堆结构,进入循环,调整堆的结构
while (childMax < len) {
//判断左右子树大小,如果右子树更大,而且右子树存在,childMax指针指向右子树
if (arr[childMax] < arr[childMax + 1] && childMax + 1 < len) childMax++;
//子树值小于根节点,不需要调整,退出循环
if (arr[childMax] < arr[cur]) break;
//子树值大于根节点,需要调整,先交换根节点和子节点
swap(arr, childMax, cur);
cur = childMax; //根节点指针指向子节点,检查子节点是否满足大顶堆规则
childMax = 2 * cur + 1; //子节点指针指向新的子节点
}
}
// 建立大顶堆
function buildHeap(arr) {
//从最后一个非叶子节点开始,向前遍历,
for (let i = Math.floor(arr.length / 2 - 1); i >= 0; i--) {
headAdjust(arr, i, arr.length); //对每一个节点都调整堆,使其满足大顶堆规则
}
}
// 堆排序
function heapSort(arr) {
if (arr.length <= 1) return arr;
//构建大顶堆
buildHeap(arr);
//从后往前遍历,
for (let i = arr.length - 1; i >= 0; i--) {
swap(arr, i, 0); //交换最后位置和第一个位置(堆顶最大值)的位置
headAdjust(arr, 0, i); //调整根节点~i-1个节点,重新生成大顶堆
}
return arr;
}更多编程相关知识,请访问:编程视频!!
以上是冒泡排序、快速排序和堆排序的時間複雜度是多少的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Java資料結構與演算法:深入詳解
May 08, 2024 pm 10:12 PM
Java資料結構與演算法:深入詳解
May 08, 2024 pm 10:12 PM
資料結構與演算法是Java開發的基礎,本文深入探討Java中的關鍵資料結構(如陣列、鍊錶、樹等)和演算法(如排序、搜尋、圖演算法等)。這些結構透過實戰案例進行說明,包括使用陣列儲存分數、使用鍊錶管理購物清單、使用堆疊實現遞歸、使用佇列同步執行緒以及使用樹和雜湊表進行快速搜尋和身份驗證等。理解這些概念可以編寫高效且可維護的Java程式碼。
 用 C++ 函數指標改造程式碼:提升效率和可重複使用性
Apr 29, 2024 pm 06:45 PM
用 C++ 函數指標改造程式碼:提升效率和可重複使用性
Apr 29, 2024 pm 06:45 PM
函數指標技術可提升程式碼效率和可重複使用性,具體表現為:提升效率:使用函數指標可減少重複程式碼,優化呼叫過程。提高可重複使用性:函數指標允許使用通用函數處理不同數據,提高程式的可重複使用性。
 如何實作C#中的冒泡排序演算法
Sep 19, 2023 am 11:10 AM
如何實作C#中的冒泡排序演算法
Sep 19, 2023 am 11:10 AM
如何實作C#中的冒泡排序演算法冒泡排序是一種簡單但有效的排序演算法,它透過多次比較相鄰的元素並交換位置來排列一個陣列。在本文中,我們將介紹如何使用C#語言實作冒泡排序演算法,並提供具體的程式碼範例。首先,讓我們來了解冒泡排序的基本原理。演算法從數組的第一個元素開始,與下一個元素進行比較。如果當前元素比下一個元素大,則交換它們的位置;如果當前元素比下一個元素小,則保持
 Java快速排序技巧及注意事項
Feb 25, 2024 pm 10:24 PM
Java快速排序技巧及注意事項
Feb 25, 2024 pm 10:24 PM
掌握Java快速排序的關鍵技巧和注意事項快速排序(QuickSort)是一種常用的排序演算法,其核心思想是透過選擇一個基準元素,將待排序序列分割成獨立的兩部分,其中一部分的所有元素均小於基準元素,另一部分的所有元素都大於基準元素,然後對這兩部分分別進行遞歸排序,最終得到有序序列。雖然快速排序在平均情況下的時間複雜度為O(nlogn),但在最壞情況下會退化為O
 PHP 數組自訂排序演算法的編寫指南
Apr 27, 2024 pm 06:12 PM
PHP 數組自訂排序演算法的編寫指南
Apr 27, 2024 pm 06:12 PM
如何寫自訂PHP數組排序演算法?冒泡排序:透過比較和交換相鄰元素來排序數組。選擇排序:每次選擇最小或最大元素並與目前位置交換。插入排序:逐一插入元素到有序部分。
 用Python怎麼實現快速排序
Dec 18, 2023 pm 03:37 PM
用Python怎麼實現快速排序
Dec 18, 2023 pm 03:37 PM
用Python實現快速排序的方法:1、定義一個名為quick_sort的函數,使用遞歸的方法來實現快速排序;2、檢查數組的長度,如果長度小於等於1,則直接傳回數組,否則,選擇數組中的第一個元素作為樞紐元素(pivot),然後將數組分成比樞紐元素小和比樞紐元素大的兩個子數組;3、將這兩個子數組和樞紐元素連接起來,形成排序好的數組即可。
 各種 PHP 數組排序演算法的複雜度分析
Apr 27, 2024 am 09:03 AM
各種 PHP 數組排序演算法的複雜度分析
Apr 27, 2024 am 09:03 AM
PHP陣列排序演算法複雜度:冒泡排序:O(n^2)快速排序:O(nlogn)(平均)歸併排序:O(nlogn)
 分析 Go 語言中的時間複雜度與空間複雜度
Mar 27, 2024 am 09:24 AM
分析 Go 語言中的時間複雜度與空間複雜度
Mar 27, 2024 am 09:24 AM
Go語言是一種越來越流行的程式語言,它被設計成易於編寫、易於閱讀和易於維護的語言,同時也支援高階程式設計概念。時間複雜度和空間複雜度是演算法和資料結構分析中重要的概念,它們衡量一個程式的執行效率和占用記憶體大小。在本文中,我們將重點分析Go語言中的時間複雜度和空間複雜度。時間複雜度時間複雜度是指演算法執行時間與問題規模之間的關係。通常用大O表示法來表示時間