一、最佳化的思路和原則有哪些
1、優化更需要最佳化的查詢
2、定位最佳化物件的效能瓶頸
3、 明確優化的目標
4、 從Explain入手
5、 多使用profile
6、 永遠用小結果集驅動大結果集
7、 盡可能在索引中完成排序
8、 只取出自己需要的欄位(Columns)
9、 僅使用最有效的篩選條件
10、盡可能避免複雜的join
相關免費學習推薦:mysql影片教學
1、最佳化更需要最佳化的查詢
高並發的低消耗(相對)的查詢對整個系統影響遠大於低並發高消耗的查詢。
2、定位優化物件的效能瓶頸
在拿到一條需要優化的查詢時,我們首先要判斷出這個查詢的瓶頸到底是IO還是CPU 。到底是資料庫存取消耗多還是資料的運算(如分組排序)消耗多。
3、明確優化的目標
了解資料庫目前整體狀態,就能知道資料庫所能承受的最大壓力,也就是我們知道最悲觀狀況;
要把握該查詢相關的資料庫物件信息,我們就能知道最理想和最糟糕狀態下需要消耗多少資源;
要知道該查詢在應用系統中的地位,我們可以分析出改查詢可以佔用系統資源的比例,也能夠知道查詢的效率對顧客的體驗影響有多大。
4、從Explain入手
Explain能夠告訴你這個查詢在資料庫中是一個什麼樣的執行計畫來實現的。首先我們需要有個目標,透過不斷調整嘗試,再藉助Explain來驗證結果是否滿足自己的需求,直到得到預期的結果。
5、永遠用小結果集驅動大結果集
很多人喜歡在SQL優化的時候說用「小表驅動大表”,這個說法是不嚴謹的。因為大表經過where條件過濾後回傳的結果集不一定就比小表所回傳的結果集大,這個時候還用大表驅動小表,就會得到相反的效能效果。
這樣的結果也非常容易理解,在 MySQL 中的 Join,只有 Nested Loop 一種 Join 方式,也就是MySQL 的 Join 都是透過嵌套循環來實現的。驅動結果集越大,所需循環的此時就越多,那麼被驅動表的訪問次數自然也就越多,而每次訪問被驅動表,即使需要的邏輯IO 很少,循環次數多了,總量自然也不可能很小,而且每次循環都無法避免的需要消耗CPU,所以CPU 運算量也會跟著增加。所以,如果我們只以表的大小來作為驅動表的判斷依據,假若小表過濾後所剩下的結果集比大表多很多,結果就是需要的嵌套循環中帶來更多的循環次數,反之,所需要的循環次數就會更少,總體IO 量和CPU 運算量也會少。而且,就算是非 Nested Loop 的 Join 演算法,如 Oracle 中的 Hash Join,同樣是小結果集驅動大的結果集是最優的選擇。
所以,在優化Join Query 的時候,最基本的原則就是“小結果集驅動大結果集”,透過這個原則來減少嵌套循環中的循環次數,達到減少IO 總量以及CPU 運算的次數。盡可能在索引中完成排序
6、只取出自己需要的欄位(Columns)
對於任何查詢,傳回的資料都是需要透過網路封包傳送給客戶端,如果取出的Column越多,需要傳輸的資料量自然會越大,不論從網路頻寬還是網路傳輸緩衝區來看,都是一種浪費。
7、僅使用最有效的過濾條件
舉個例子一個用戶表user有id和nick_name等字段,索引是id和nike_name兩個索引,下面是兩個查詢語句
#1
select * from user where id = 1 and nick_name = 'zs';
#2
selet * from user where id = 1
登入後複製
兩個查詢得到結果是一樣的,但是第一個語句用到的索引佔用空間是比第二個語句大很多的。佔用空間大也代表著要讀取的資料量也更多。 ,也就是說2的查詢語句才是最優查詢。
8、避免複雜的join查詢
#
我們的查詢語句所涉及的表格越多,所需要鎖定的資源就越多。也就是說,越複雜的 Join 語句,所需要鎖定的資源就越多,所阻塞的其他執行緒就越多。相反,如果我們將比較複雜的查詢語句分拆成多個較為簡單的查詢語句分步執行,每次鎖定的資源也會少很多,所阻塞的其他線程也要少一些。
可能很多人會有疑問,將複雜 Join 語句分拆成多個簡單的查詢語句之後,那不是我們的網路互動就會更多了嗎?網路延時方面的整體消耗也就更大了啊,完成整個查詢的時間不是反而更長了嗎?是的,這種情況是可能存在,但並不是肯定就會如此。我們可以再分析一下,一個複雜的查詢語句在執行的時候,所需要鎖定的資源比較多,可能被別人阻塞的機率也就更大,如果是一個簡單的查詢,由於需要鎖定的資源較少,被阻塞的機率也會小很多。所以 較為複雜的連線查詢也有可能在執行前被阻塞而浪費更多的時間。而且我們的資料庫所服務的並不是單單這一查詢請求,還有很多很多其他的請求,在高並發的系統中,犧牲單一查詢的短暫回應時間而提高整體處理能力也是非常值得的。優化本身就是一門平衡與取捨的藝術,只有懂得取捨,平衡整體,才能讓系統更優。
二、利用Explain和Profiling
#1、Explain使用
各種資訊來展示
| 欄位 |
說明 |
| #ID |
在執行計畫中查詢的序號 |
| Select_type |
查詢類型:
DEPENDENT SUBQUERY : 子查詢中內層的第一個SELECT,依賴外部查詢結果集;
DEPENDENT UNION :子查詢中的UNION中從第二個SELECT 開始的後面所有SELECT,同樣依賴外部查詢結果集;
PRIMARY: 子查詢中的最外層查詢,不是主鍵查詢;
SUBQUERY:子查詢內層查詢的第一個SELECT,結果不依賴外部結果集;
UNCACHEABLE SUBQUERY:結果集無法快取的子查詢;
UNION:UNION語句中第二個SELECT開始的後面所有SELECT,第一個SELECT為PRIMARY
UNION RESULT:UNION中的合併結果 |
| #Table |
所存取的資料庫中表格名稱 |
| #TYPE |
存取方式:
ALL: 全表掃描
const: 常數,最多只有一筆記錄匹配,由於是常數,所以實際上只需要讀一次
eq_ref: 最多只有一條符合結果,一般是主鍵或唯一索引來存取的
index: 全索引掃描
range: 索引範圍掃描
ref: jion語句中被驅動表索引的參考查詢
system: 系統表,表中只有一行資料 |
| Possible_keys |
可能會用到的索引 |
##Key | 使用的索引 |
Key_len | 索引長度 |
Rows | #估算出來的結果集記錄條數 |
Extra | #額外資訊 |
#2、Profiling使用
该工具可以获取一条Query在整个执行过程中多种资源消耗情况,如CPU,IO,IPC,SWAP等,以及发生PAGE FAULTS, CONTEXT SWITCHE等等,同时还能得到该Query执行过程中MySQL所调用的各个函数在源文件中的位置。
1、开启profiling参数 1-开启,0-关闭
#开启profiling参数 1-开启,0-关闭set profiling=1;SHOW VARIABLES LIKE '%profiling%';
登入後複製
2、然后执行一条Query
3、获取系统保存的profiling信息
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
show profile cpu, block io for QUERY 7;
登入後複製
三、合理利用索引
1、什么是索引
简单来说,在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或者多列的值进行排序的一种存储结构。就像书的目录,可以根据目录中的页码快速找到需要的内容。
在MySQL中主要有四种类型索引,分别是:B-Tree索引,Hash索引,FullText索引,R-Tree索引,下面主要说一下我们常用的B-Tree索引,其他索引可以自行查找资料。
2、索引的数据结构
一般来说,MySQL中的B-Tree索引的物理文件大多数都是以平衡树的结构来存储的,也就是所有实际需要存储的数据都存储于树的叶子节点,二到任何一个叶子节点的最短路径的长度都是完全相同的。MySQL中的存储引擎也会稍作改造,比如Innodb存储引擎的B-Tree索引实际上使用的存储结构是B+Tree,在每个叶子节点存储了索引键相关信息之外,还存储了指向相邻的叶子节点的指针信息,这是为了加快检索多个相邻的叶子节点的效率。
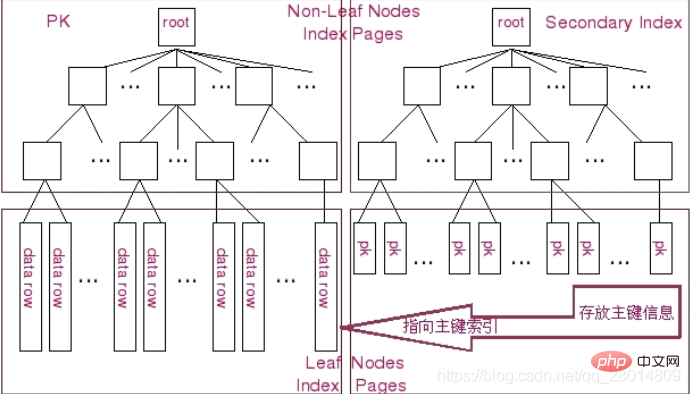
在Innodb中,存在两种形式的索引,一种是聚簇形式的主键索引,另外一种形式是和其他存储引擎(如MyISAM)存放形式基本相同的普通B-Tree索引,这种索引在Innodb存储引擎中被称作二级索引。
图示中左边为 Clustered 形式存放的 Primary Key,右侧则为普通的 B-Tree 索引。两种索引在根节点和 分支节点方面都还是完全一样的。而 叶子节点就出现差异了。在主键索引中,叶子结点存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据,整个数据以主键值有序的排列。而二级索引则和其他普通的 B-Tree 索引没有太大的差异,只是在叶子结点除了存放索引键的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过二级索引来访问数据的话,Innodb 首先通过二级索引的相关信息,通过相应的索引键检索到叶子节点之后,需要再通过叶子节点中存放的主键值再通过主键索引来获取相应的数据行。
MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的二级索引的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在叶子节点上面除了存放索引键信息之外,再存放能直接定位MyISAM 数据文件中相应的数据行的信息(如 Row Number),但并不会存放主键的键值信息。
3、索引的利弊
优点: 提高数据的检索速度,降低数据库的IO成本;
缺点:查询需要更新索引信息带来额外的资源消耗,索引还会占用额外的存储空间
4、如何判断是否需要建立索引
上面说了索引的利弊,我们知道索引并不是越多越好,索引也会带来副作用。那么我们该怎么判断是否需要建立索引呢?
1、 较频繁的作为查询条件的字段应该创建索引;
2、更新频繁的字段不适合建立索引;
3、唯一性太差的不适合创建索引,如状态字段;
4、不出现在where中的字段不适合创建索引;
5、单索引还是组合索引?
在一般的應用場景,只要不是其中某個過濾字段在大多數場景下都能過濾90%以上的數據,而且其他的過濾字段會頻繁更新,我一般更傾向於創建組合索引,尤其是在並發量較高的場景下更是如此。因為並發量搞的時候,即使我們為每個查詢節省很少IO消耗,但因為執行量非常大,所節省的資源總量還是很大的。
但是我們建立組合索引並不是說查詢條件中的所有欄位都要放在一個索引中,我們應該讓一個索引被多個查詢所利用,盡量減少索引的數量,以此來減少更新的成本和儲存成本。
MySQL為我們提供了一個減少最佳化索引本身的功能,那就是「前綴索引」。也就是我們可以只使用某個欄位的前面部分內容作為索引鍵來索引該欄位,減少索引所佔用的空間和提高索引的存取效率。當然前綴索引只適合前綴比較隨機重複很少的欄位。
6、索引的選擇
1、對於單鍵索引,盡量針對目前查詢過濾最好的索引;
2、在選擇組合索引的時候,目前查詢中過濾性最好的欄位在索引欄位順序中排列越靠前越好;
3、在選擇組合索引的時候,盡量選擇可以能夠包含目前查詢的where字句中更多欄位的索引;
4、盡可能透過分析統計資料和調整查詢的寫法來達到選擇合適的索引來減少透過人為Hint控制索引的選擇,以為這樣後期維護成本會很高。
7、MySQL索引的限制
1、MyISAM儲存引擎索引鍵長總和不能超過1000位元組;
2、BLOB和TEXT類型欄位只能建立前綴索引;
3、MySQL不支援函數索引;
4、使用!= 或時候,MySQL索引無法使用;
5、濾波欄位使用函數運算後,MySQL索引無法使用;
6、jion語句中近字段類型不一致的時候,MySQL索引無法使用;
7、使用like如果是前匹配(如:'�a'),MySQL索引無法使用;
8.使用非等值查詢的時候,MySQL無法使用HASH索引;
9、字元類型是數字的時候要使用='1' 不可以直接使用= 1;
10、不要使用or可以用in代替或union all;
8、Join原理以及最佳化
Join原理:在MySQL中,只有一種join演算法,就是大名鼎鼎的嵌套循環,實際上就是透過驅動表的結果集作為循環基礎數據,然後一條一條的通過該結果集中的數據作為過濾條件到下一個表中查詢數據,然後合併結果。如果還有近參與,再透過前面的近結果集作為循環基礎數據,再循環遍歷,如此往復。
優化:
1、盡可能減少Join語句中的迴圈總次數(還記得前面說過的小結果集驅動大結果集嗎);
2、優先優化內層循環;
3、保證Join語句中被驅動表上的Join條件欄位已經被索引;
4、當無法保證被驅動表的Join條件欄位被索引且記憶體資源充足條件下,不要吝嗇Join buffer的設定(join buffer只會在All,index,range才能夠用的上);
9、ORDER BY優化
在MySQL中, ORDER BY的實作只有兩種類型:
1、透過有序的索引直接取得有序的數據,這樣不用進行任何排序操作即可得到客戶端要求的有序數據;
2 、透過MySQL排序演算法將儲存的引擎中傳回的資料進行排序然後再將排序後的資料傳回給客戶端。
利用索引排序是最佳的方法,但是如果沒有索引林勇的時候,MySQL主要兩種演算法實作:
1、取出滿足篩選條件的用於排序條件的字段以及可以直接定位到行數據的行指針信息,在Sort Buffer 中進行實際的排序操作,然後利用排好序之後的數據根據行指針信息返回表中獲取客戶端請求的其他字段的數據,再返回給客戶端;
2、根據過濾條件一次取出排序字段以及客戶端請求的所有其他字段的數據,並將不需要排序的字段存放在一塊內存區域中,然後在Sort Buffer 中將排序欄位和行指標資訊進行排序,最後再利用排序後的行指標與存放在記憶體區域和其他欄位一起的行指標資訊進行比對合併結果集,再依照順序傳回給客戶端。
第二種演算法相較於第一種演算法,主要就是減少了資料的二次存取。在排序好後,不需要再次回到表中取數據,節省了IO操作。當然第二種演算法會消耗更多的內存,一種典型的以空間換取時間的最佳化方式。
對於多表Join排序是先透過一個臨時表將之前 Join 的結果集存放入臨時表之後再將臨時表的資料取到 Sort Buffer 中進行操作。
對於非索引排序的時候,盡量選擇第二種演算法來進行排序,手段有:
1、加大max_length_for_sort_data參數設定:
MySQL決定使用哪個演算法是透過參數max_length_for_sort_data來決定的,當我們回傳字段的最大長度小於這個參數時候,MySQL就會選擇第二中演算法,相反則是第一種演算法。所以在有充足記憶體情況下,加大這個參數值可以讓MySQL選擇第二種演算法;
2、減少不必要的回傳字段
上面一樣的道理,字段少了,就會盡量小於max_length_for_sort_data參數;
3、增大sort_buffer_size參數設定:
增大sort_buffer_size 並不是為了讓MySQL 可以選擇改進版的排序演算法,而是為了讓MySQL演算法可以盡量減少在排序過程中盡量減少在排序過程中盡量減少在排序過程中盡量減少在排序過程中盡量減少在排序過程中盡量減少在排序過程中對需要排序的資料進行分段,因為這樣會造成MySQL 不得不使用臨時表來進行交換排序。
四、最後
調優其實是件很難的事情,調優也不限於上面的查詢調優。諸如表格的設計最佳化,資料庫參數的調優,應用程式調優(減少循環操作資料庫,批次新增;資料庫連線池;快取;)等等。當然還有很多調優技巧只有在實際實踐上才能真正體會。只有自己以理論為基礎,事實為依據,不斷嘗試去提升自己,才能成為真正的調優高手。
相關免費學習推薦:mysql資料庫(影片)
以上是MySQL查詢優化詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!








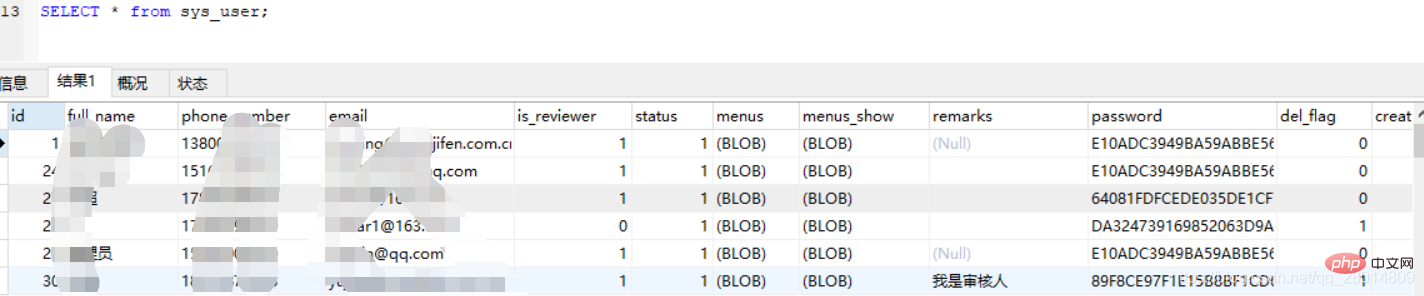
 4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)