| 交易隔離等級 |
髒讀 |
不可重複讀取 |
幻讀 |
| 讀未提交(read- uncommitted) |
是 |
是 |
是 |
| 已提交(read-committed) |
否 |
是 |
是 |
| 可重複讀取(repeatable-read) |
否 |
#否 |
是 |
| 序列化(serializable) |
|
|
|
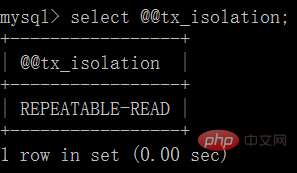
##mysql預設的交易隔離等級為repeatable-read

#四、用範例說明各個隔離等級的狀況
# 1.讀取未提交:
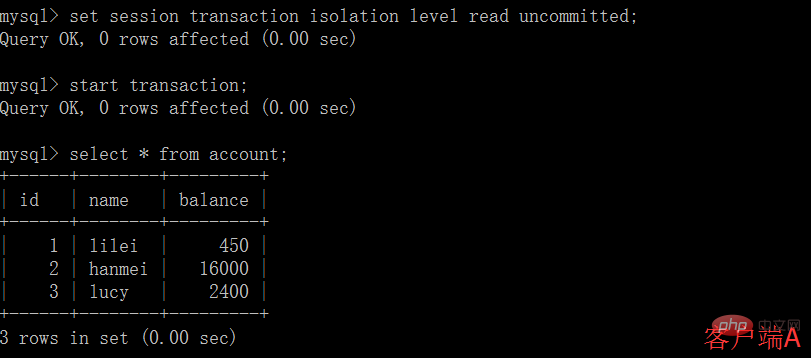
(1)開啟一個客戶端A,並設定目前交易模式為read uncommitted(未提交讀取),查詢表account的初始值:
# (2)在客戶端A的交易提交之前,打開另一個客戶端B,更新表account:
# (3)這時,雖然客戶端B的事務還沒提交,但是客戶端A就可以查詢到B已經更新的資料:
#
(4)一旦客戶端B的事務因為某些原因回滾,所有的操作都會被撤銷,那客戶端A查詢到的資料其實就是髒資料:
(5)在客戶端A執行更新語句update account set balance = balance - 50 where id =1,lilei的balance沒有變成350,居然是400,是不是很奇怪,數據不一致啊,如果你這麼想就太天真了,在在應用程式中,我們會用400-50=350,並不知道其他會話回滾了,要解決這個問題可以採用讀取已提交的隔離等級
2、讀取已提交
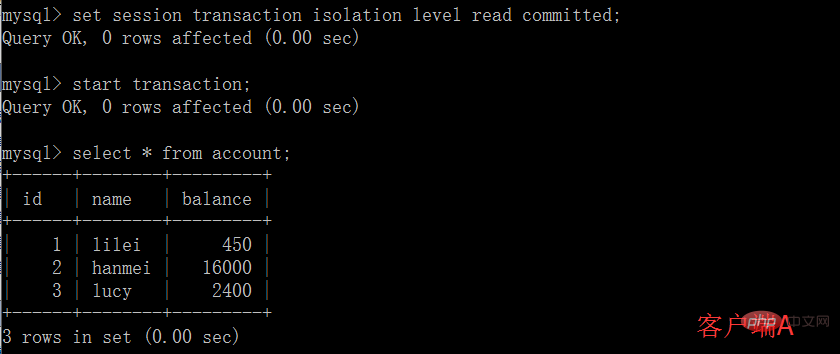
(1)開啟一個客戶端A,並設定目前交易模式為read committed(未提交讀取),查詢表account的初始值:
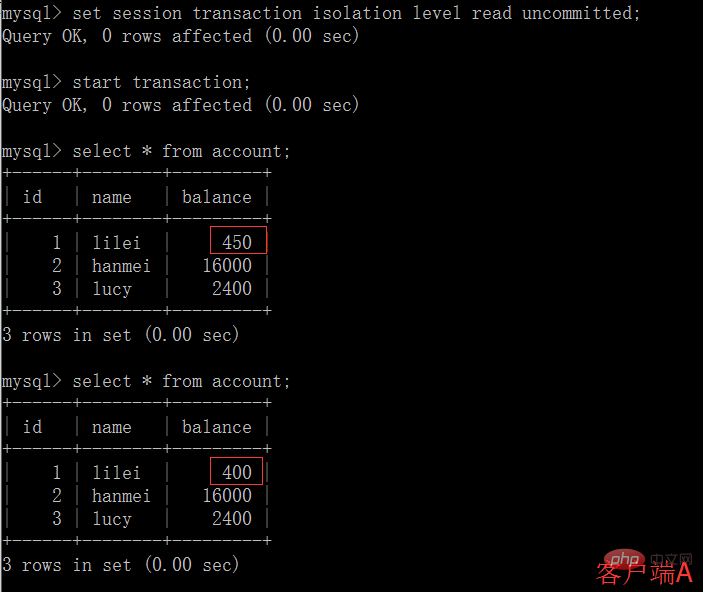
# (2)在客戶端A的交易提交之前,打開另一個客戶端B,更新表account:
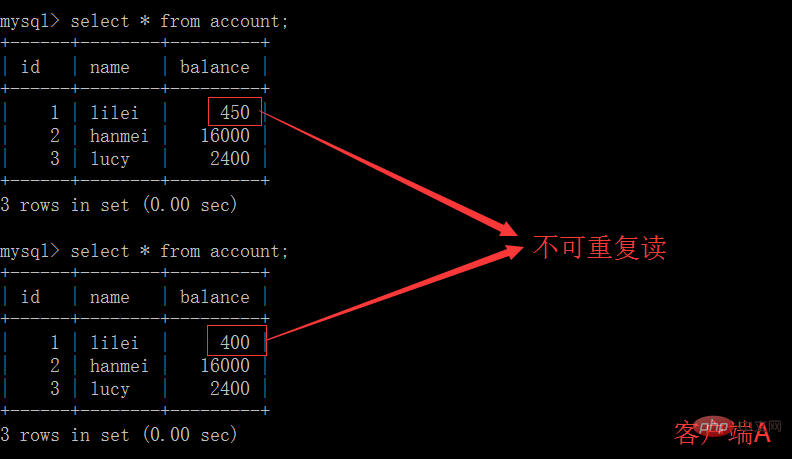
(3)這時,客戶端B的事務還沒提交,客戶端A不能查詢到B已經更新的數據,解決了髒讀問題:
(4)客戶端B的事務提交
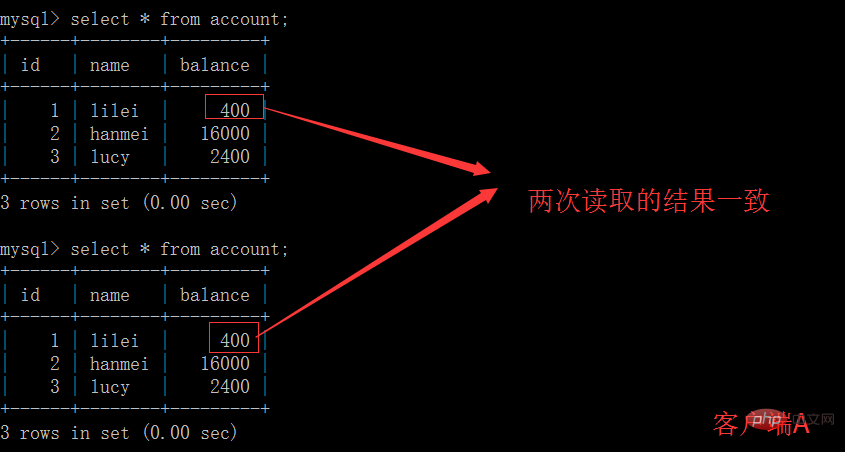
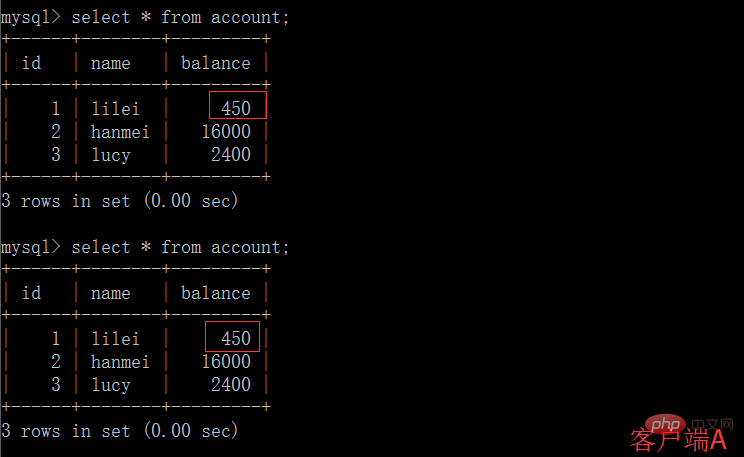
(5)客戶端A執行與上一個步驟相同的查詢,結果與上一個步驟不一致,即產生了不可重複讀取的問題
3、可重複讀取
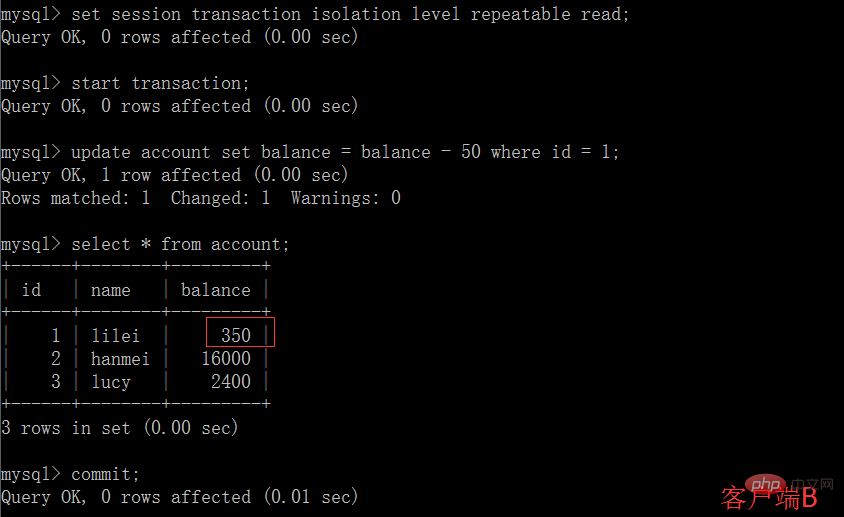
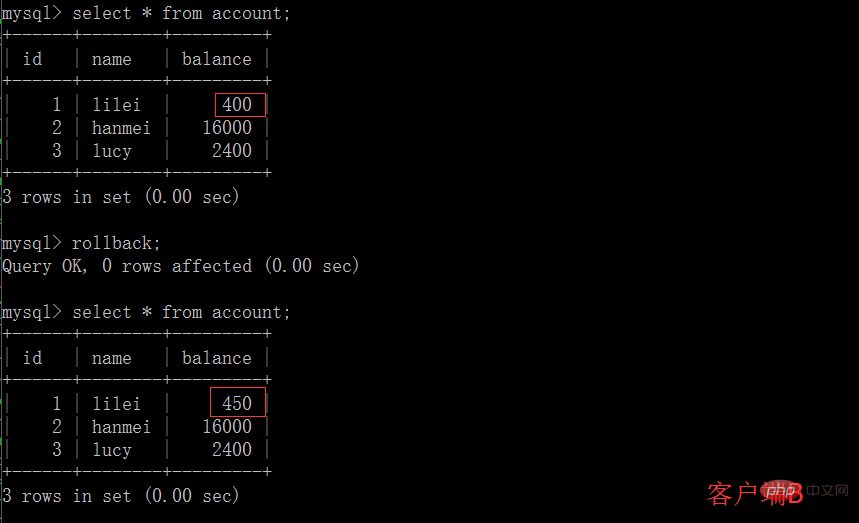
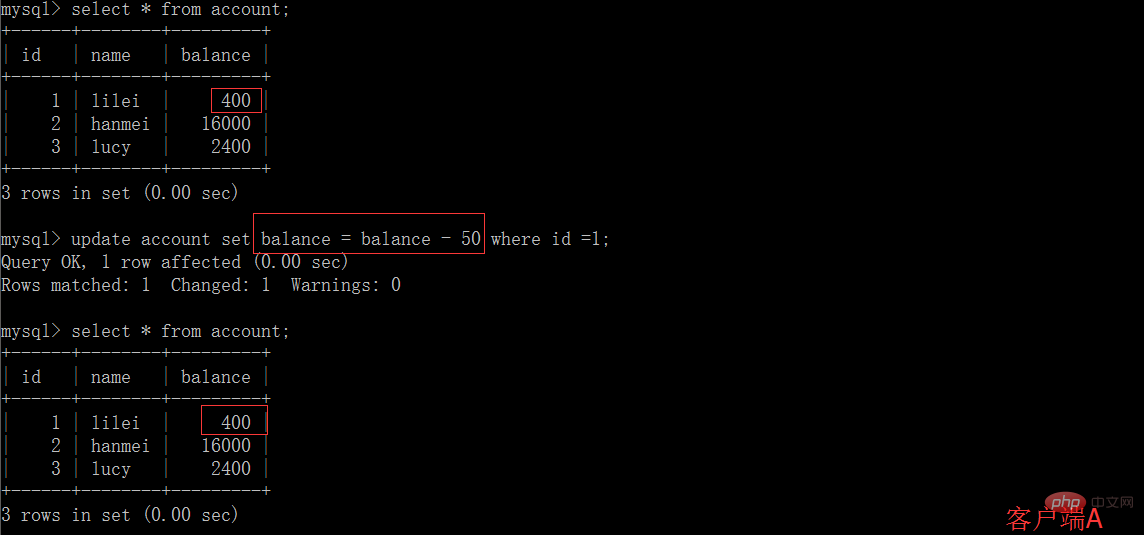
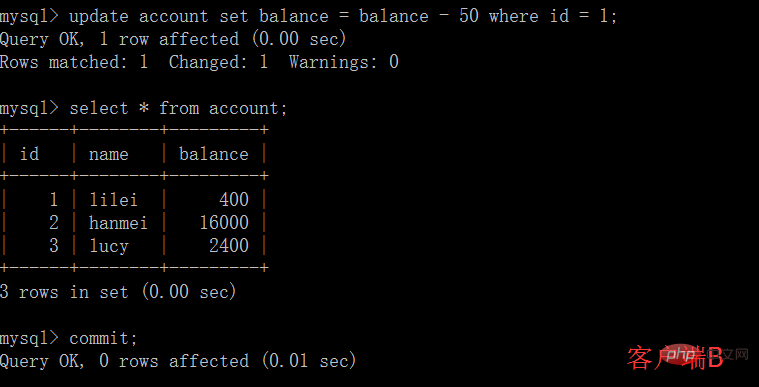
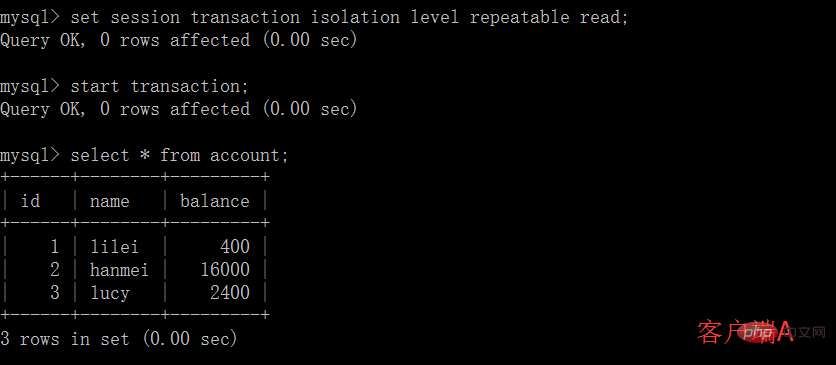
(1)開啟一個客戶端A,並設定目前交易模式為repeatable read,查詢表account
# (2)在客戶端A的交易提交之前,打開另一個客戶端B,更新表account並提交
# (3)在客戶端A執行步驟(1)的查詢:
(4)執行步驟(1),lilei的balance仍然是400與步驟(1)查詢結果一致,沒有出現不可重複讀取的問題;接著執行update balance = balance - 50 where id = 1,balance沒有變成400-50=350,lilei的balance值用的是步驟(2)中的350來算的,所以是300,資料的一致性倒是沒有被破壞,這個有點神奇,也許是mysql的特色吧,做dml時可重複讀取資料還是按表中真實資料來mysql> select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+------+--------+---------+
3 rows in set (0.00 sec)
mysql> update account set balance = balance - 50 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 300 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+------+--------+---------+
3 rows in set (0.00 sec)
登入後複製
(5) 在客戶端A提交事務,查詢表account的初始值mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 300 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+------+--------+---------+
3 rows in set (0.00 sec)
登入後複製
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values(4,'lily',600);
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
登入後複製
,站在客户的角度,客户是看不到客户端B的,它会觉得是天下掉馅饼了,多了600块,这就是幻读,站在开发者的角度,数据的 一致性并没有破坏。但是在应用程序中,我们得代码可能会把18700提交给用户了,如果你一定要避免这情况小概率状况的发生,那么就要采取下面要介绍的事务隔离级别“串行化”
mysql> select sum(balance) from account;
+--------------+
| sum(balance) |
+--------------+
| 18700 |
+--------------+
1 row in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select sum(balance) from account;
+--------------+
| sum(balance) |
+--------------+
| 19300 |
+--------------+
1 row in set (0.00 sec)
登入後複製
4.串行化
(1)打开一个客户端A,并设置当前事务模式为serializable,查询表account的初始值:
mysql> set session transaction isolation level serializable;
Query OK, 0 rows affected (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 10000 |
| 2 | hanmei | 10000 |
| 3 | lucy | 10000 |
| 4 | lily | 10000 |
+------+--------+---------+
4 rows in set (0.00 sec)
登入後複製
(2)打开一个客户端B,并设置当前事务模式为serializable,插入一条记录报错,表被锁了插入失败,mysql中事务隔离级别为serializable时会锁表,因此不会出现幻读的情况,这种隔离级别并发性极低,开发中很少会用到。
mysql> set session transaction isolation level serializable;
Query OK, 0 rows affected (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values(5,'tom',0);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
登入後複製
补充:
1、SQL规范所规定的标准,不同的数据库具体的实现可能会有些差异
2、mysql中默认事务隔离级别是可重复读时并不会锁住读取到的行
3、事务隔离级别为读提交时,写数据只会锁住相应的行
4、事务隔离级别为可重复读时,如果有索引(包括主键索引)的时候,以索引列为条件更新数据,会存在间隙锁间隙锁、行锁、下一键锁的问题,从而锁住一些行;如果没有索引,更新数据时会锁住整张表。
5、事务隔离级别为串行化时,读写数据都会锁住整张表
6、隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大,鱼和熊掌不可兼得啊。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
相关推荐:《mysql教程》








 # 1.讀取未提交:
# 1.讀取未提交: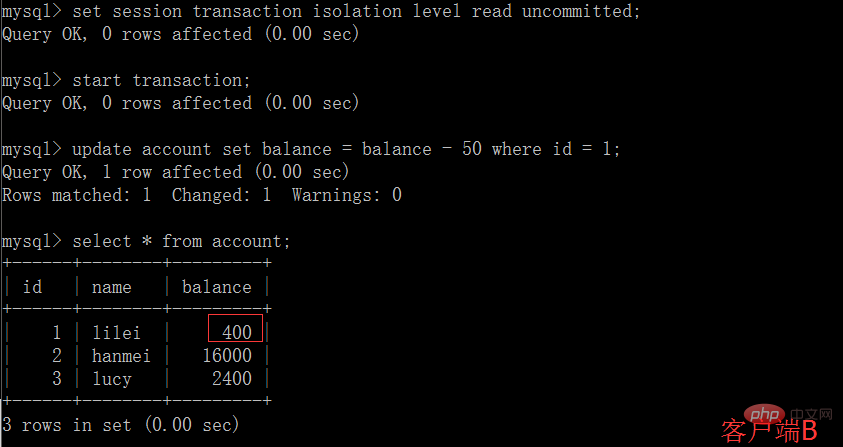
 2、讀取已提交
2、讀取已提交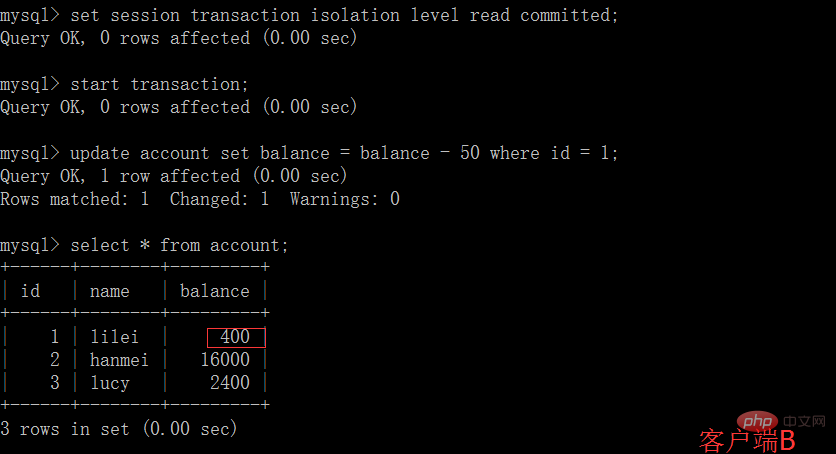
 3、可重複讀取
3、可重複讀取