帶你吃透Redis中的主從複製、Sentinel、集群

這篇文章跟大家介紹一下Redis分散式的相關知識,帶大家吃透主從複製、Sentinel、集群,讓你的Redis水平更上一層!

一、主從複製
1、簡介
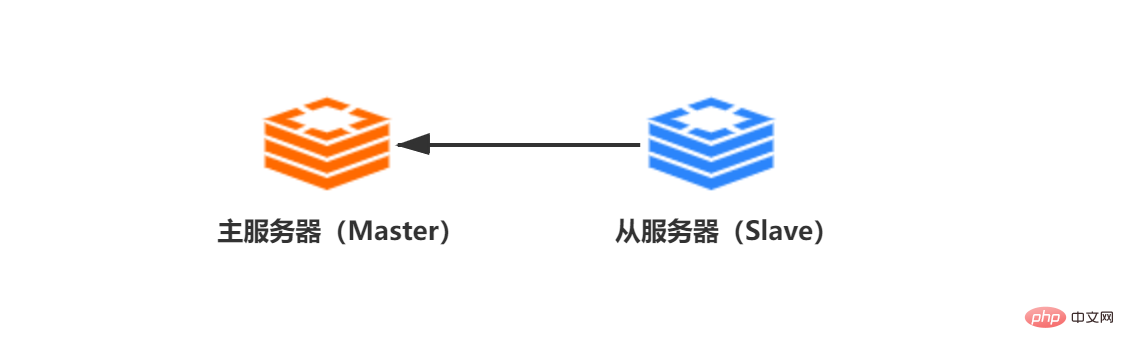
主從複製是Redis分散式的基石,也是Redis高可用的保障。在Redis中,被複製的伺服器稱為主伺服器(Master),對主伺服器進行複製的伺服器稱為從伺服器(Slave)。 【相關建議:Redis影片教學】
#主從複製的設定非常簡單,有三種方式(其中IP-主伺服器IP位址/PORT -主伺服器Redis服務連接埠):
設定檔-redis.conf檔中,設定slaveof ip port
- ##指令-進入Redis客戶端執行slaveof ip port
- 啟動參數- ./redis-server --slaveof ip port
- 2.8以前
- 2.8~4.0
- 4.0以後
- 同步(sync):指的是將從伺服器的資料狀態更新至主伺服器目前的資料狀態,主要發生在初始化或後續的全量同步。
- 指令傳播(command propagate):當主伺服器的資料狀態被修改(寫/刪除等),主從之間的資料狀態不一致時,主服務將發生資料改變的命令傳播給從伺服器,讓主從伺服器之間的狀態重回一致。
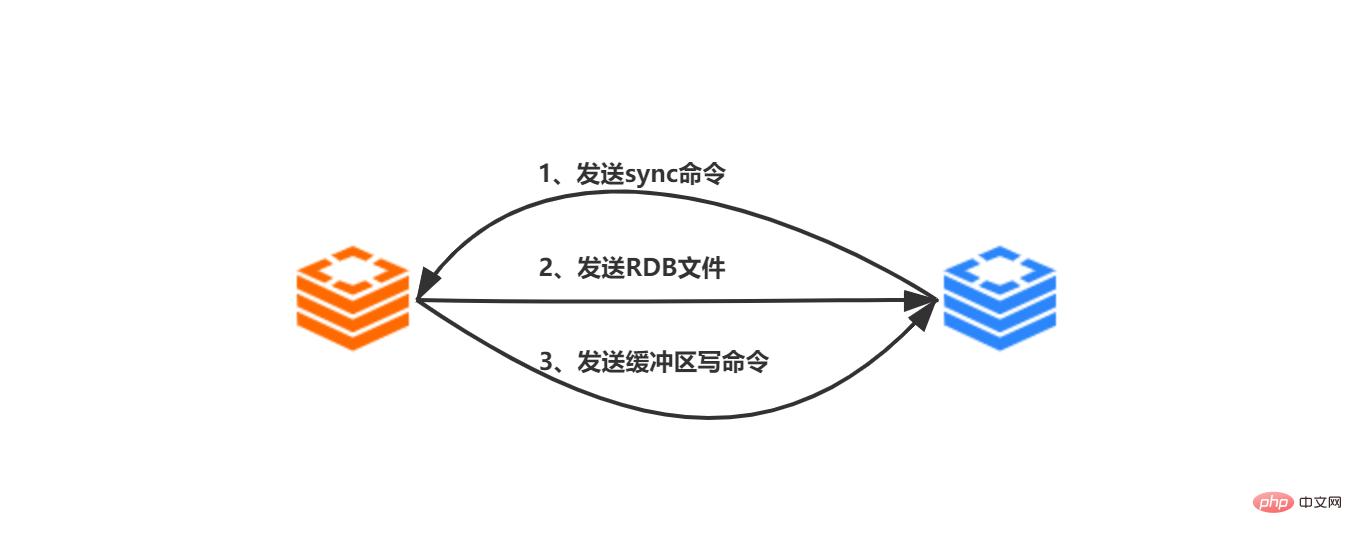
- 從伺服器接收到客戶端發送的slaveof ip prot命令,從伺服器根據ip:port向主伺服器創建套接字連接
- 套接字成功連接到主伺服器後,從伺服器會為這個套接字連接關聯一個專門用於處理複製工作的檔案事件處理器,處理後續的主伺服器發送的RDB檔案和傳播的命令
- 開始進行複製,從伺服器向主伺服器發送sync命令
- 主伺服器接收到sync指令後,執行bgsave指令,主伺服器主程序fork的子程序會產生一個RDB文件,同時將RDB快照產生後的所有寫入操作記錄在緩衝區中
- bgsave指令執行完成後,主伺服器將產生的RDB檔案傳送給從伺服器,從伺服器接收到RDB檔案後,首先會清除本身的全部數據,然後載入RDB文件,將自己的資料狀態更新成主伺服器的RDB檔案的資料狀態
- 主伺服器將緩衝區的寫入指令傳送給從伺服器,從伺服器接收指令,並執行。
- 主從複製同步步驟完成
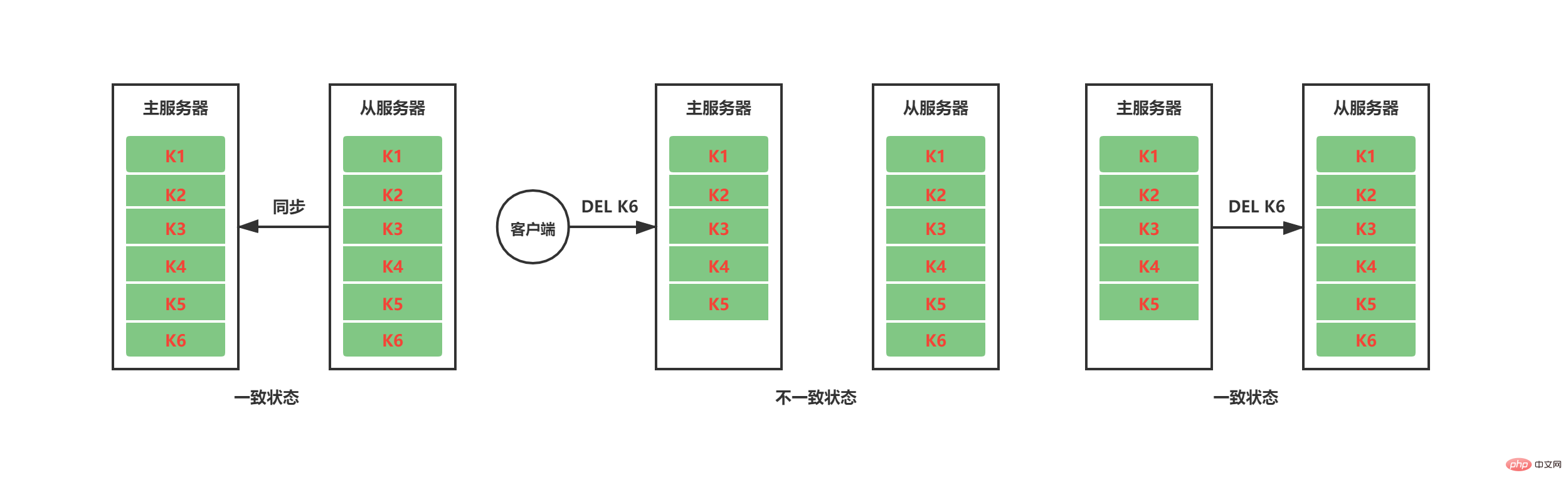
從上面看不出2.8以前版本的主從複製有什麼缺陷,這是因為我們還沒有考慮網路波動的情況。了解分散式的兄弟們肯定聽過CAP理論,CAP理論是分散式儲存系統的基石,在CAP理論中P(partition網路分區)必然存在,Redis主從複製也不例外。當主從伺服器之間出現網路故障,導致一段時間內從伺服器與主伺服器之間無法通信,當從伺服器重新連接上主伺服器時,如果主伺服器在這段時間內資料狀態發生了改變,那麼主從伺服器之間將出現資料狀態不一致。在Redis 2.8以前的主從複製版本中,解決這種資料狀態不一致的方式是透過重新發送sync命令來實現。雖然sync能保證主從伺服器資料狀態一致,但很明顯sync是一個非常消耗資源的操作。
sync指令執行,主從伺服器需要佔用的資源:
主伺服器執行BGSAVE產生RDB文件,會佔用大量CPU、磁碟I/O和記憶體資源
主伺服器將產生的RDB檔案傳送給從伺服器,會佔用大量網路頻寬,
從伺服器接收RDB檔案並載入,會導致從伺服器阻塞,無法提供服務
從上面三點可以看出,sync指令不僅會導致主伺服器的回應能力下降,也會導致從伺服器在此期間拒絕對外提供服務。
2.2 版本2.8-4.0
2.2.1 改進點
針對2.8以前的版本,Redis在2.8之後對從伺服器重連後的資料狀態同步進行了改進。改進的方向是減少全量同步(full resynchronizaztion)的發生,盡可能使用增量同步(partial resynchronization)。在2.8版本之後使用psync指令取代了sync指令來執行同步操作,psync指令同時具備全量同步與增量同步的功能:
全量同步與上一版本(sync)一致
增量同步中對於斷線重連後的複製,會根據情況採取不同措施;如果條件允許,仍然只發送從服務缺失的部分資料。
2.2.2 psync如何實現
Redis為了實現從伺服器斷線重連後的增量同步,增加了三個輔助參數:
複製偏移(replication offset)
積壓緩衝區(replication backlog)
伺服器運行id (run id)
2.2.2.1 複製偏移量
在主伺服器和從伺服器內都會維護一個複製偏移量
主伺服器向從服務發送數據,傳播N個位元組的數據,主服務的複製偏移量增加N
從伺服器接收主伺服器發送的數據,接收N個位元組的數據,從伺服器的複製偏移量增加N
正常同步的情況如下:
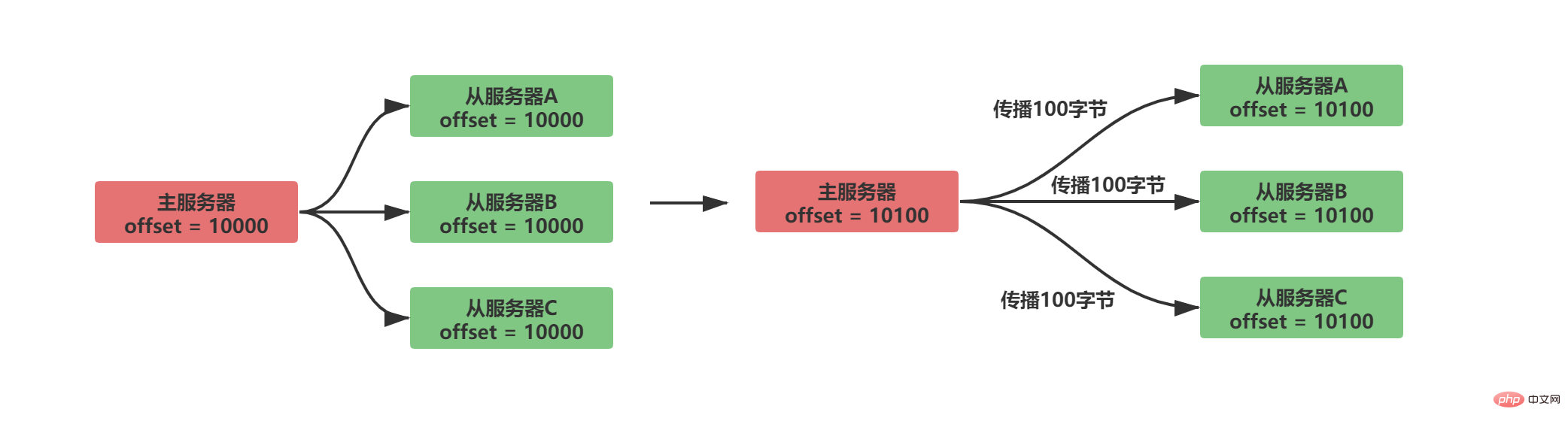
透過比較主從伺服器之間的複製偏移量是否相等,能夠得知主從伺服器之間的資料狀態是否保持一致。 假設此時A/B正常傳播,C從伺服器斷線,那麼將出現如下情況:
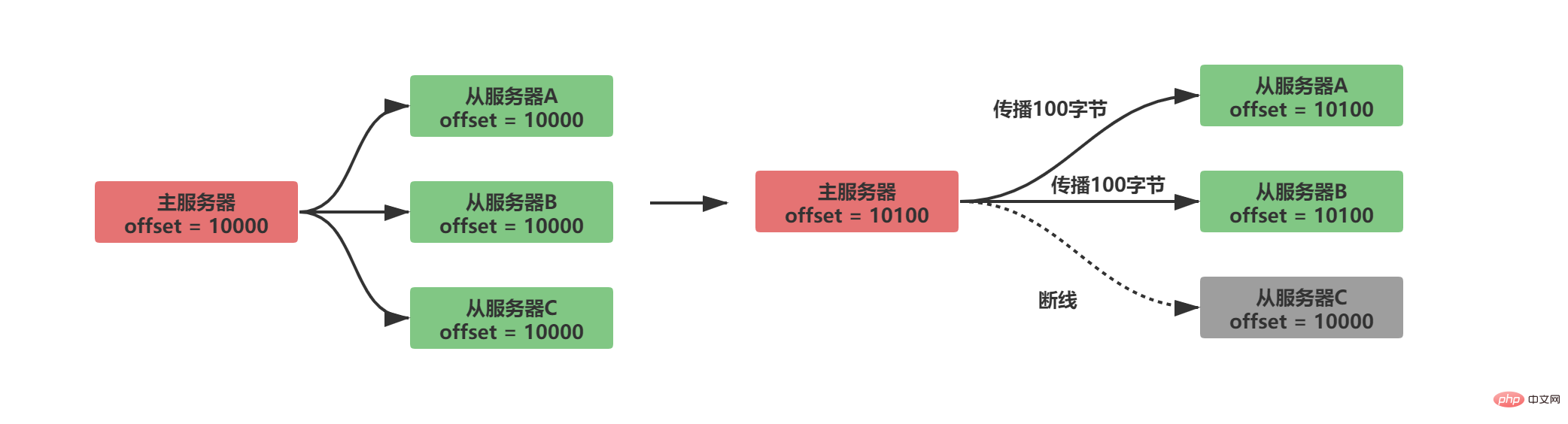
#很明顯有了複製偏移量之後,從伺服器C斷線重連後,主伺服器只需要傳送從伺服器缺少的100位元組資料即可。 但是主伺服器又是如何知道從伺服器缺少的是那些資料呢?
2.2.2.2 複製積壓緩衝區
複製積壓緩衝區是固定長度的佇列,預設為1MB大小。當主伺服器資料狀態改變,主伺服器將資料同步給從伺服器的同時會另存一份到複製積壓緩衝區。
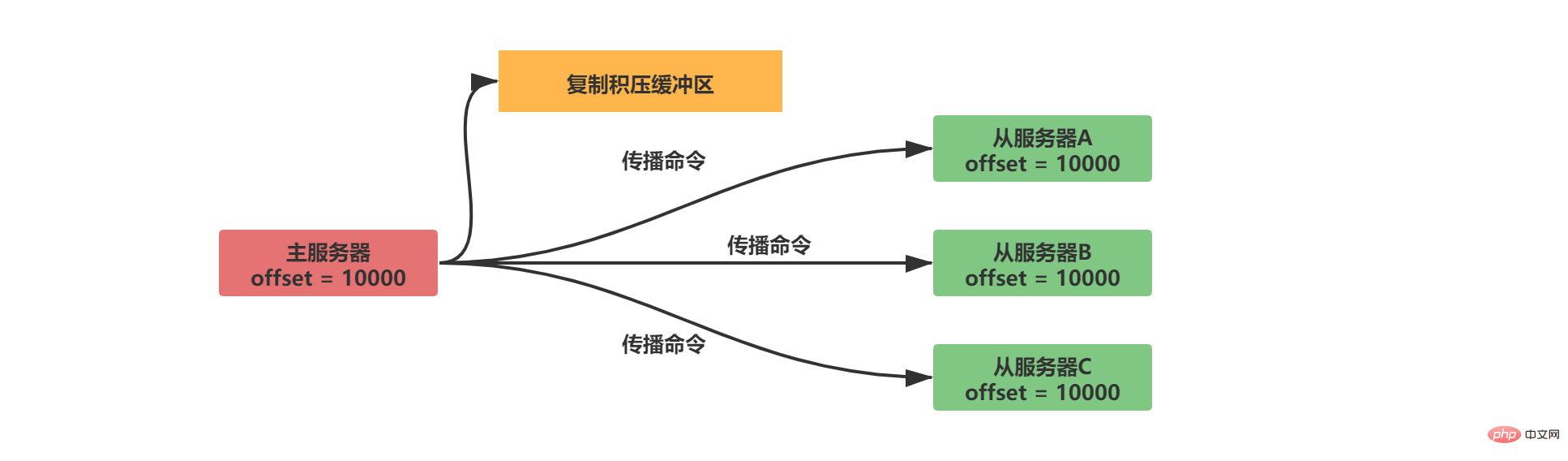
複製積壓緩衝區為了能和偏移量進行匹配,它不僅儲存了資料內容,還記錄了每個位元組對應的偏移量:

當從伺服器斷線重連後,從伺服器透過psync指令將自己的複製偏移量(offset)傳送給主伺服器,主伺服器可透過這個偏移量來判斷進行增量傳播還是全量同步。
如果偏移量offset 1的資料仍然在複製積壓緩衝區中,那麼進行增量同步操作
反之進行全量同步操作,與sync一致
Redis的複製積壓緩衝區的大小預設為1MB,如果需要自訂應該如何設定呢? 很明顯,我們希望能盡可能的使用增量同步,但是又不希望緩衝區佔用過多的記憶體空間。那我們可以透過預估Redis從服務斷線後重連的時間T,Redis主伺服器每秒接收的寫入指令的記憶體大小M,來設定複製積壓緩衝區的大小S。
S = 2 * M * T
#注意這裡擴大2倍是為了留有一定的餘地,保證絕大部分的斷線重連都能採用增量同步。
2.2.2.3 伺服器運行ID
看到這裡是不是再想上面已經可以實現斷線重連的增量同步了,還要運行ID幹嘛?其實還有一種情況沒考慮,就是當主伺服器宕機後,某台從伺服器被選出成為新的主伺服器,這種情況我們就透過比較運行ID來區分。
執行ID(run id)是伺服器啟動時自動產生的40個隨機的十六進位字串,主服務和從伺服器都會產生執行ID
#當從伺服器首次同步主伺服器的資料時,主伺服器會傳送自己的執行ID給從伺服器,從伺服器會儲存在RDB檔案中
當從伺服器斷線重連後,從伺服器會向主伺服器發送先前儲存的主伺服器運行ID,如果伺服器執行ID匹配,則證明主伺服器未發生更改,可以嘗試進行增量同步
#如果伺服器運行ID不匹配,則進行全量同步
#2.2.3 完整的psync
完整的psync過程非常的複雜,在2.8-4.0的主從複製版本中已經做到了非常完善。 psync指令發送的參數如下:
psync
當沒有從伺服器複製任何主伺服器(並不是主從第一次複製,因為主伺服器可能會變化,而是從伺服器第一次全量同步),從伺服器將會發送:
psync ? -1
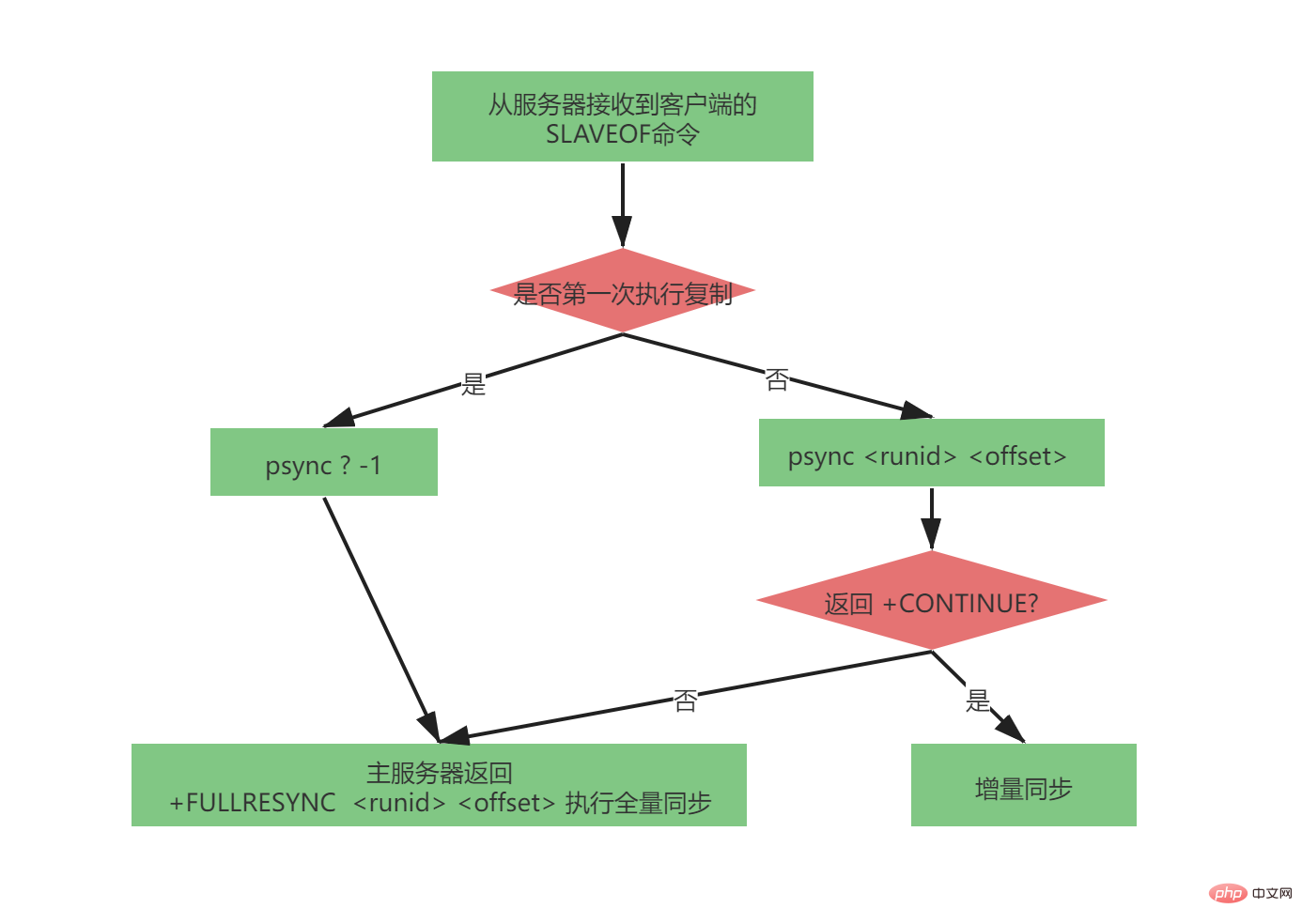
一起完整的psync流程如下圖:
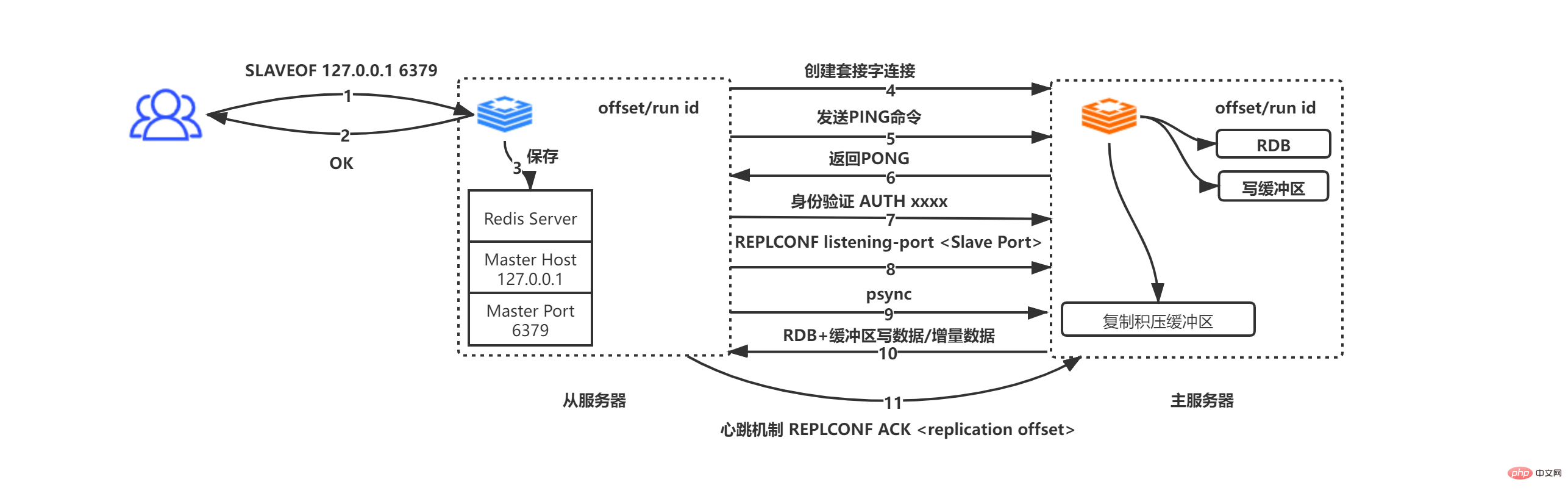
#從伺服器接收到SLAVEOF 127.0.0.1 6379指令
從伺服器回傳OK給指令發起方(這裡是非同步操作,先回傳OK,再儲存位址和連接埠資訊)
從伺服器將IP位址和連接埠資訊儲存到Master Host和Master Port
#從伺服器根據Master Host和Master Port主動向主伺服器發起套接字連接,同時從服務將會未這個套接字連接關聯一個專門用於文件複製工作的文件事件處理器,用於後續的RDB文件複製等工作
主伺服器接收到從伺服器的套接字連接請求,為該請求創建對應的套接字連接之後,並將從伺服器看著一個客戶端(在主從複製中,主伺服器和從伺服器之間其實互為客戶端和服務端)
套接字連線建立完成,從伺服器主動向主服務發送PING指令,如果在指定的逾時時間內主伺服器傳回PONG,則證明套接字連接可用,否則斷開重連
如果主伺服器設定了密碼(masterauth),那麼從伺服器向主伺服器發送AUTH masterauth命令,進行身份驗證。注意,如果從伺服器發送了密碼,主服務並未設定密碼,此時主服務會發送no password is set錯誤;如果主伺服器需要密碼,而從伺服器未發送密碼,此時主伺服器會發送NOAUTH錯誤;如果密碼不匹配,主伺服器會傳送invalid password錯誤。
從伺服器傳送REPLCONF listening-port xxxx(xxxx表示從伺服器的連接埠)。主伺服器接收到該指令後會將資料儲存起來,當客戶端使用INFO replication查詢主從資訊時能夠傳回資料
從伺服器傳送psync指令,此步驟請檢視上圖psync的兩種情況
主伺服器與從伺服器之間互為客戶端,進行資料的請求/回應
主伺服器與從伺服器之間透過心跳包機制,判斷連線是否斷開。從伺服器每個1秒向主伺服器發送命令,REPLCONF ACL offset(從伺服器的複製偏移量),該機制可以保證主從之間資料的正確同步,如果偏移量不相等,主伺服器將會採取增量/全量同步措施來確保主從之間資料狀態一致(增量/全量的選擇取決於,offset 1的資料是否仍在複製積壓緩衝區中)
2.3 版本4.0
Redis 2.8-4.0版本仍有一些改進的空間,當主伺服器切換時,是否也能進行增量同步呢?因此Redis 4.0版本針對這個問題做了最佳化處理,psync升級為psync2.0。 psync2.0 拋棄了伺服器運行ID,採用了replid和replid2來代替,其中replid儲存的是目前主伺服器的運行ID,replid2保存的是上一個主伺服器運行ID。
複製偏移(replication offset)
#積壓緩衝區(replication backlog)
#主伺服器運行id(replid)
上主伺服器運行id(replid2)
透過replid和replid2我們可以解決主伺服器切換時,增量同步的問題:
如果replid等於目前主伺服器的運行id,那麼判斷同步方式增量/全量同步
如果replid不相等,則判斷replid2是否相等(是否同屬於上一個主伺服器的從伺服器),如果相等,仍然可以選擇增量/全量同步,如果不相等則只能進行全量同步。
二、Sentinel
1、簡介
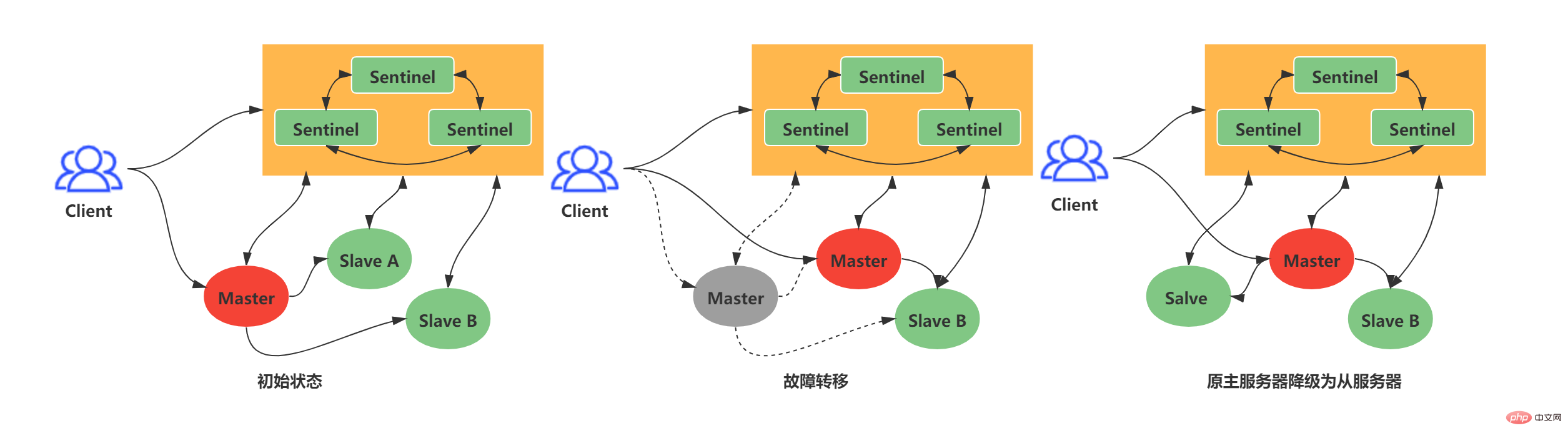
主從複製奠定了Redis分散式的基礎,但是普通的主從複製並不能達到高可用的狀態。在普通的主從複製模式下,如果主伺服器宕機,就只能透過維運人員手動切換主伺服器,很顯然這種方案並不可取。針對上述情況,Redis官方推出了可抵抗節點故障的高可用方案-Redis Sentinel(哨兵)。 Redis Sentinel(哨兵):由一個或多個Sentinel實例組成的Sentinel系統,它可以監視任意多個主從伺服器,當監視的主伺服器宕機時,自動離線主伺服器,並且擇優選取從伺服器升級為新的主伺服器。
如下範例:當舊Master下線時長超過使用者設定的下線時長上限,Sentinel系統就會對舊Master執行故障轉移操作,故障轉移操作包含三個步驟:
在Slave中選擇資料最新的作為新的Master
#向其他Slave發送新的複製指令,讓其他從伺服器成為新的Master的Slave
繼續監視舊Master,如果其上線則將舊Master設定為新Master的Slave
本文基於以下資源清單進行進行:
| #IP位址 | 節點角色 | 埠 |
|---|---|---|
| #192.168.211.104 | # Redis Master/ Sentinel | 6379/26379 |
| 192.168.211.105 | 192.168.211.105 | Redis Slave/ Sentinel |
| ##192.168.211.106 | ##192.168.211.106Redis Slave/ Sentinel |
2、Sentinel初始化與網路連線
Sentinel並沒有什麼特別神奇的地方,它就是一個更簡單的Redis伺服器,在Sentinel啟動的時候它會載入不同的命令表和設定文件,因此從本質上來講Sentinel就是一個擁有較少命令和部分特殊功能的Redis服務。當一個Sentinel啟動時它需要經歷以下步驟:
初始化Sentinel伺服器
-
取代普通Redis程式碼為Sentinel的專用程式碼
初始化Sentinel狀態
根據使用者給定的Sentinel設定文件,初始化Sentinel監視的主伺服器清單
建立連接主伺服器的網路連線
根據主服務取得從伺服器信息,建立連線從伺服器的網路連線
- ##根據發布/訂閱取得Sentinel訊息,建立Sentinel之間的網路連線
struct sentinelState {
//当前纪元,故障转移使用
uint64_t current_epoch;
// Sentinel监视的主服务器信息
// key -> 主服务器名称
// value -> 指向sentinelRedisInstance指针
dict *masters;
// ...
} sentinel;- masters的key是主服務的名字
- masters的value是指指向sentinelRedisInstance指標
daemonize yes port 26379 protected-mode no dir "/usr/local/soft/redis-6.2.4/sentinel-tmp" sentinel monitor redis-master 192.168.211.104 6379 2 sentinel down-after-milliseconds redis-master 30000 sentinel failover-timeout redis-master 180000 sentinel parallel-syncs redis-master 1
typedef struct sentinelRedisInstance {
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
char *name;
// 服务器运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
} sentinelRedisInstance;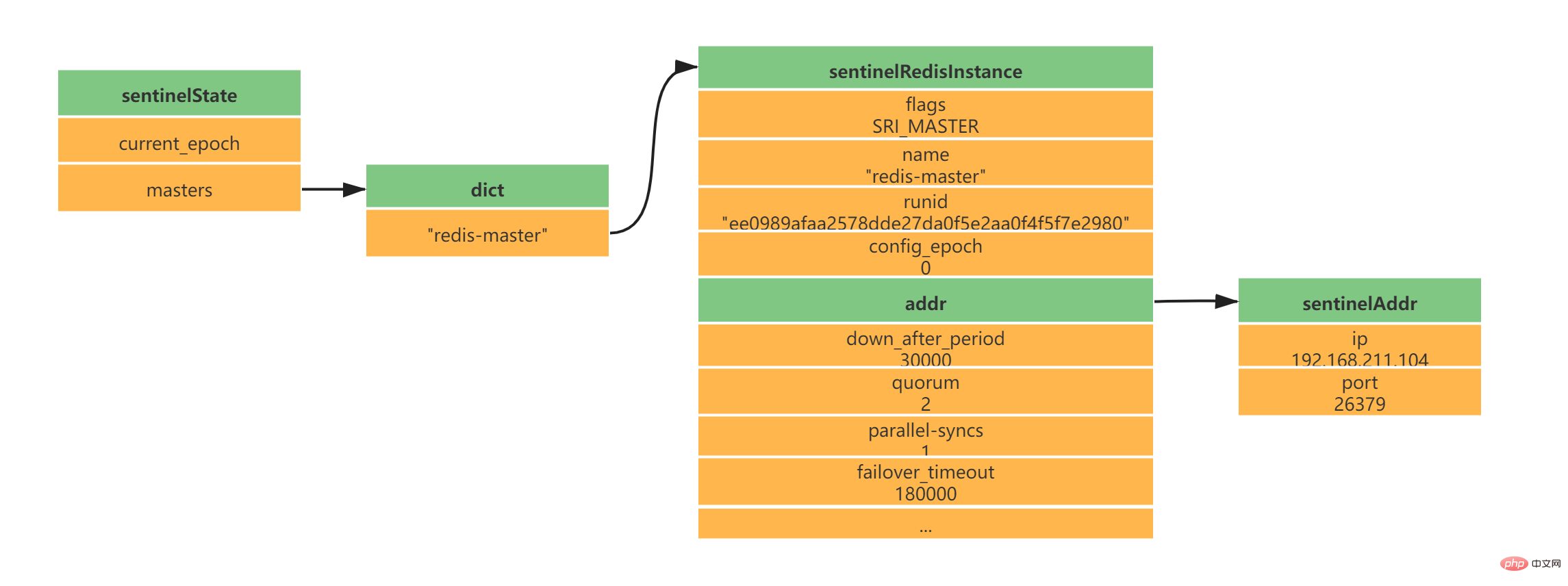
- 指令連線用於取得主從資訊 ##訂閱連線用於Sentinel之間進行資訊廣播,每個Sentinel和自己監視的主從伺服器之間會訂閱_sentinel_:hello頻道(注意Sentinel之間不會建立訂閱連接,它們透過訂閱_sentinel_:hello頻道來取得其他Sentinel的初始訊息)
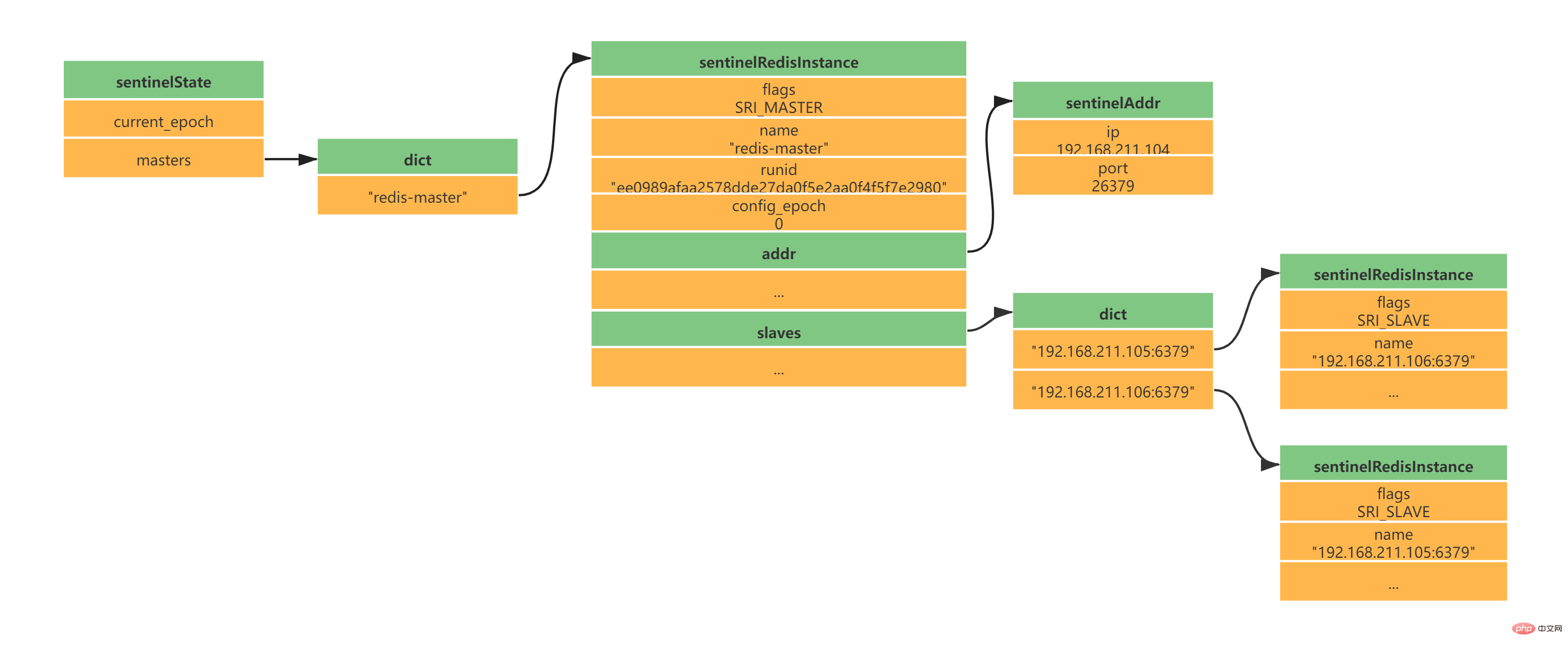
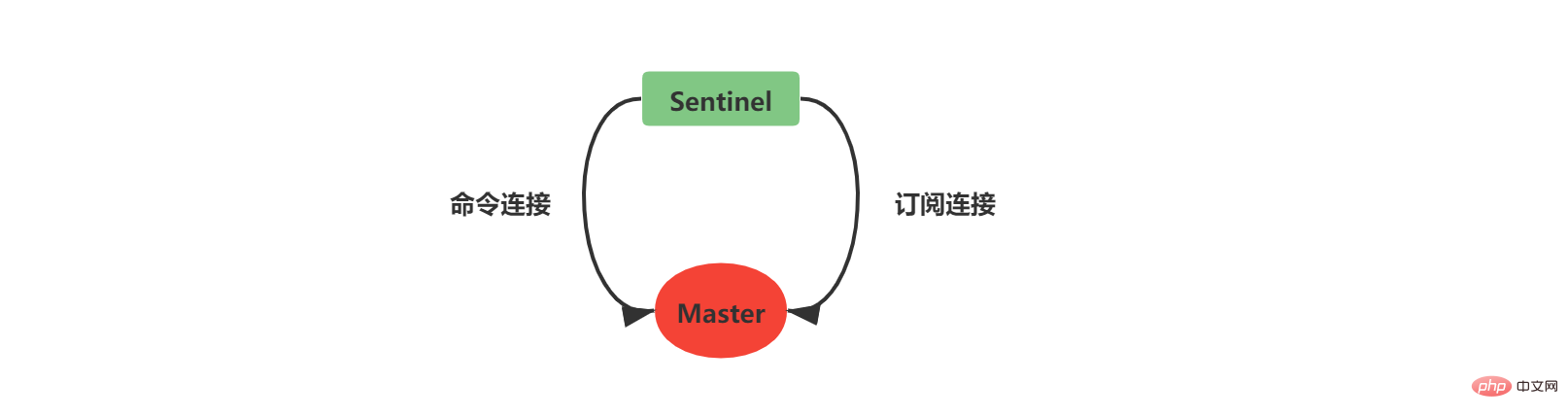 Sentinel在建立指令連線完成之後,每隔10秒鐘向Master發送INFO指令,透過Master的回覆訊息可以獲得兩方面的知識:
Sentinel在建立指令連線完成之後,每隔10秒鐘向Master發送INFO指令,透過Master的回覆訊息可以獲得兩方面的知識:
- Master本身的資訊
- Master下的Slave資訊
 2.6 建立連接從伺服器的網路連接
2.6 建立連接從伺服器的網路連接
根據主服務取得從伺服器訊息,Sentinel可以建立到Slave的網路連接,Sentinel和Slave之間也會建立命令連接和訂閱連接。
当Sentinel和Slave之间创建网络连接之后,Sentinel成为了Slave的客户端,Sentinel也会每隔10秒钟通过INFO指令请求Slave获取服务器信息。 到这一步Sentinel获取到了Master和Slave的相关服务器数据。这其中比较重要的信息如下:
服务器ip和port
服务器运行id run id
服务器角色role
服务器连接状态mater_link_status
Slave复制偏移量slave_repl_offset(故障转移中选举新的Master需要使用)
Slave优先级slave_priority
此时实例结构信息如下所示:
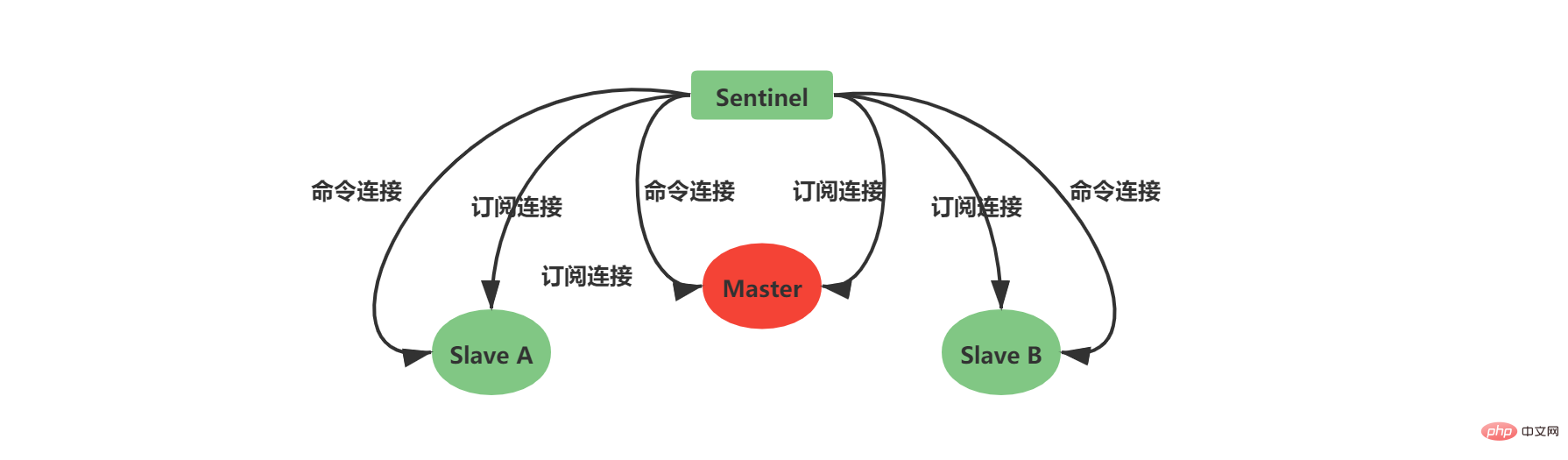
2.7 创建Sentinel之间的网络连接
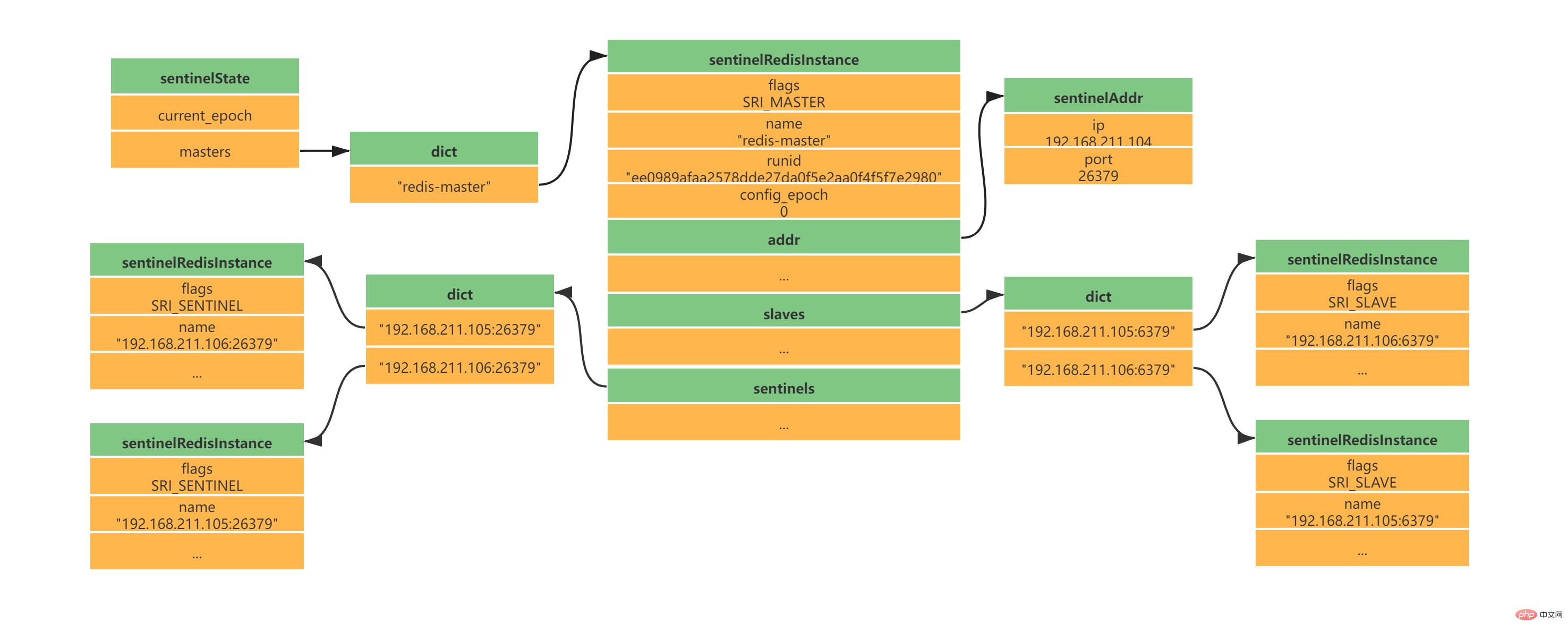
此时是不是还有疑问,Sentinel之间是怎么互相发现对方并且相互通信的,这个就和上面Sentinel与自己监视的主从之间订阅_sentinel_:hello频道有关了。 Sentinel会与自己监视的所有Master和Slave之间订阅_sentinel_:hello频道,并且Sentinel每隔2秒钟向_sentinel_:hello频道发送一条消息,消息内容如下:
PUBLISH sentinel:hello "
, , , , , , , "
其中s代码Sentinel,m代表Master;ip表示IP地址,port表示端口、runid表示运行id、epoch表示配置纪元。
多个Sentinel在配置文件中会配置相同的主服务器ip和端口信息,因此多个Sentinel均会订阅_sentinel_:hello频道,通过频道接收到的信息就可获取到其他Sentinel的ip和port,其中有如下两点需要注意:
如果获取到的runid与Sentinel自己的runid相同,说明消息是自己发布的,直接丢弃
如果不相同,则说明接收到的消息是其他Sentinel发布的,此时需要根据ip和port去更新或新增Sentinel实例数据
Sentinel之间不会创建订阅连接,它们只会创建命令连接:

此时实例结构信息如下所示:
3、Sentinel工作
Sentinel最主要的工作就是监视Redis服务器,当Master实例超出预设的时限后切换新的Master实例。这其中有很多细节工作,大致分为检测Master是否主观下线、检测Master是否客观下线、选举领头Sentinel、故障转移四个步骤。
3.1 检测Master是否主观下线
Sentinel每隔1秒钟,向sentinelRedisInstance实例中的所有Master、Slave、Sentinel发送PING命令,通过其他服务器的回复来判断其是否仍然在线。
sentinel down-after-milliseconds redis-master 30000
在Sentinel的配置文件中,当Sentinel PING的实例在连续down-after-milliseconds配置的时间内返回无效命令,则当前Sentinel认为其主观下线。Sentinel的配置文件中配置的down-after-milliseconds将会对其sentinelRedisInstance实例中的所有Master、Slave、Sentinel都适应。
无效指令指的是+PONG、-LOADING、-MASTERDOWN之外的其他指令,包括无响应
如果当前Sentinel检测到Master处于主观下线状态,那么它将会修改其sentinelRedisInstance的flags为SRI_S_DOWN

3.2 检测Master是否客观下线
当前Sentinel认为其下线只能处于主观下线状态,要想判断当前Master是否客观下线,还需要询问其他Sentinel,并且所有认为Master主观下线或者客观下线的总和需要达到quorum配置的值,当前Sentinel才会将Master标志为客观下线。

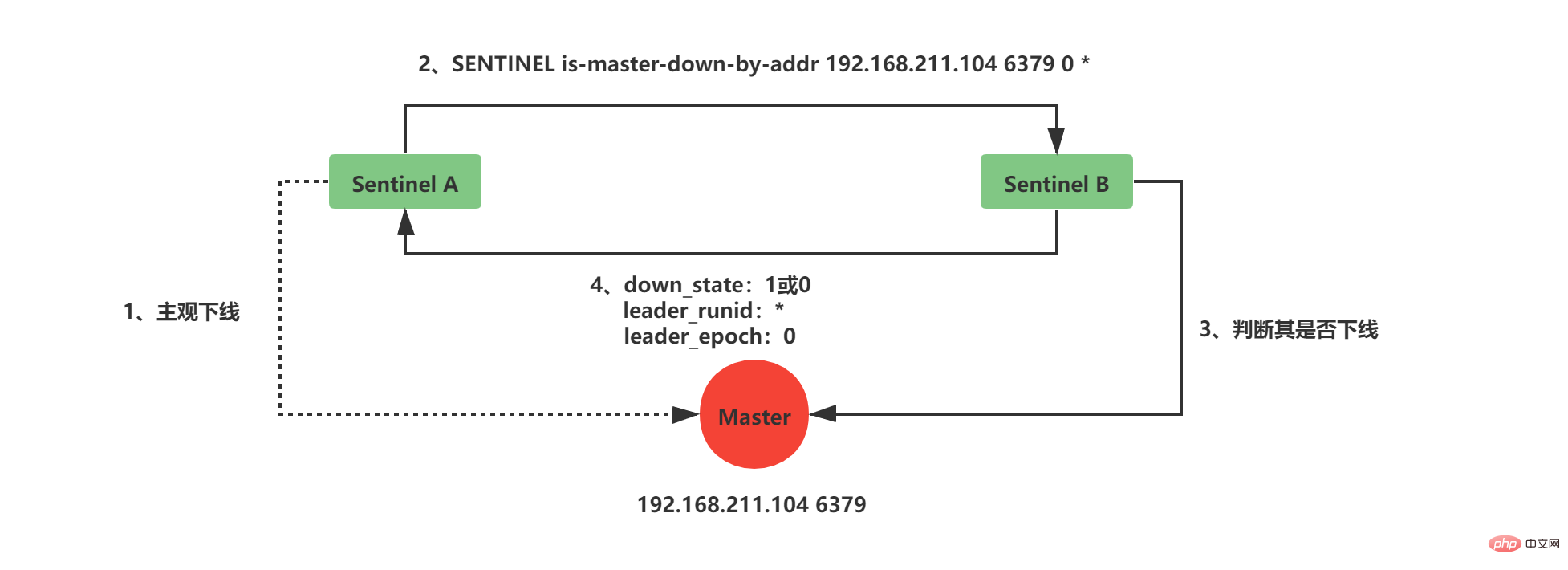
当前Sentinel向sentinelRedisInstance实例中的其他Sentinel发送如下命令:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
ip:被判断为主观下线的Master的IP地址
port:被判断为主观下线的Master的端口
current_epoch:当前sentinel的配置纪元
runid:当前sentinel的运行id,runid
current_epoch和runid均用于Sentinel的选举,Master下线之后,需要选举一个领头Sentinel来选举一个新的Master,current_epoch和runid在其中发挥着重要作用,这个后续讲解。
接收到命令的Sentinel,会根据命令中的参数检查主服务器是否下线,检查完成后会返回如下三个参数:
down_state:检查结果1代表已下线、0代表未下线
leader_runid:返回*代表判断是否下线,返回runid代表选举领头Sentinel
leader_epoch:当leader_runid返回runid时,配置纪元会有值,否则一直返回0
当Sentinel检测到Master处于主观下线时,询问其他Sentinel时会发送current_epoch和runid,此时current_epoch=0,runid=*
接收到命令的Sentinel返回其判断Master是否下线时down_state = 1/0,leader_runid = *,leader_epoch=0
3.3 选举领头Sentinel
down_state返回1,证明接收is-master-down-by-addr命令的Sentinel认为该Master也主观下线了,如果down_state返回1的数量(包括本身)大于等于quorum(配置文件中配置的值),那么Master正式被当前Sentinel标记为客观下线。 此时,Sentinel会再次发送如下指令:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>
此时的runid将不再是0,而是Sentinel自己的运行id(runid)的值,表示当前Sentinel希望接收到is-master-down-by-addr命令的其他Sentinel将其设置为领头Sentinel。这个设置是先到先得的,Sentinel先接收到谁的设置请求,就将谁设置为领头Sentinel。 发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。
3.4 故障转移
故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情:
从原先master的slave中,选择最佳的slave作为新的master
让其他slave成为新的master的slave
继续监听旧master,如果其上线,则将其设置为新的master的slave
这其中最难的一步是如果选择最佳的新Master,领头Sentinel会做如下清洗和排序工作:
判断slave是否有下线的,如果有从slave列表中移除
删除5秒内未响应sentinel的INFO命令的slave
删除与下线主服务器断线时间超过down_after_milliseconds * 10 的所有从服务器
根据slave优先级slave_priority,选择优先级最高的slave作为新master
如果优先级相同,根据slave复制偏移量slave_repl_offset,选择偏移量最大的slave作为新master
如果偏移量相同,根据slave服务器运行id run id排序,选择run id最小的slave作为新master
新的Master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新Master)发送SLAVEOF ip port命令,使其成为新master的slave。
到这里Sentinel的的工作流程就算是结束了,如果新master下线,则循环流程即可!
三、集群
1、简介
Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)进行数据共享,Redis集群主要实现了以下目标:
在1000个节点的时候仍能表现得很好并且可扩展性是线性的。
没有合并操作(多个节点不存在相同的键),这样在 Redis 的数据模型中最典型的大数据值中也能有很好的表现。
寫入安全,那些與大多數節點相連的客戶端所做的寫入操作,系統嘗試全部都保存下來。但Redis無法保證資料完全不遺失,非同步同步的主從複製無論如何都會存在資料遺失的情況。
可用性,主節點不可用,從節點能替換主節點工作。
關於Redis集群的學習,如果沒有任何經驗的弟兄們建議先看下這三篇文章(中文系列): Redis集群教程
REDIS cluster-tutorial -- Redis中文資料站-- Redis中國使用者群組(CRUG)
Redis叢集規格
REDIS cluster-spec -- Redis中文資料站-- Redis中國用戶組(CRUG)
Redis3主3從偽集群部署
CentOS 7單機安裝Redis Cluster(3主3從偽集群),僅需簡單五步驟_李子捌的博客-CSDN博客
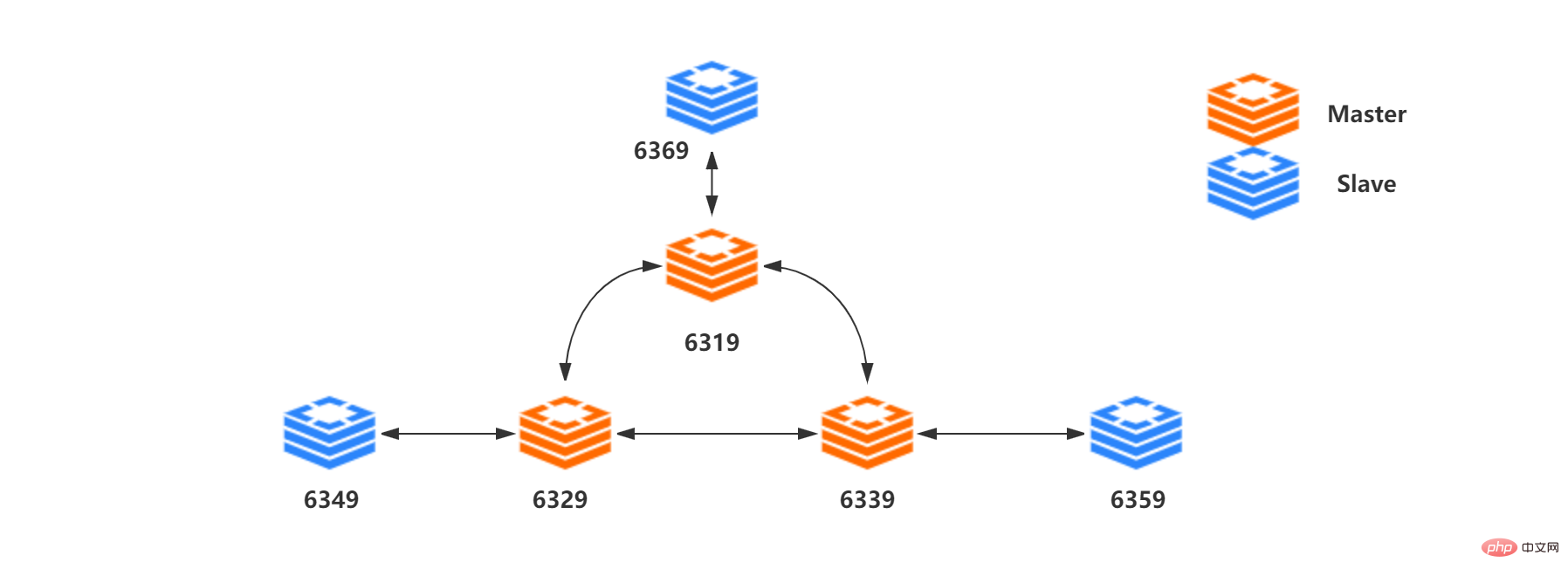
#下文內容依賴下圖三主三從結構開展:
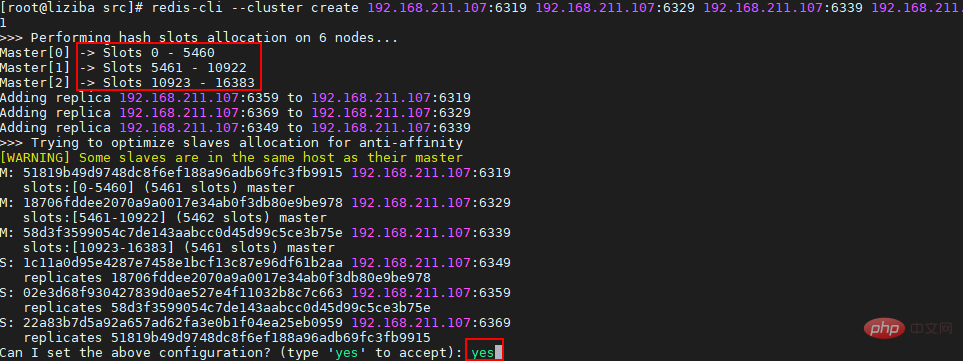
資源清單:
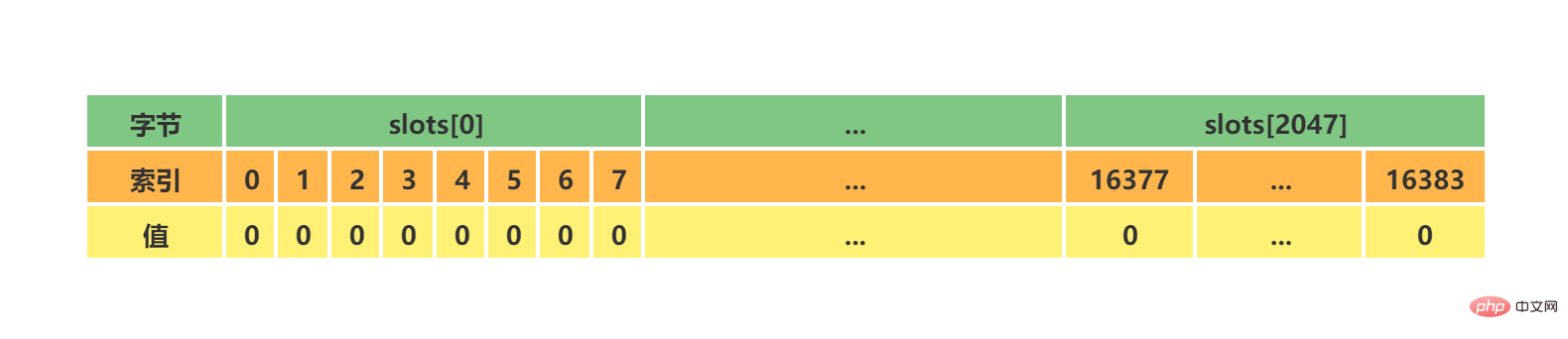
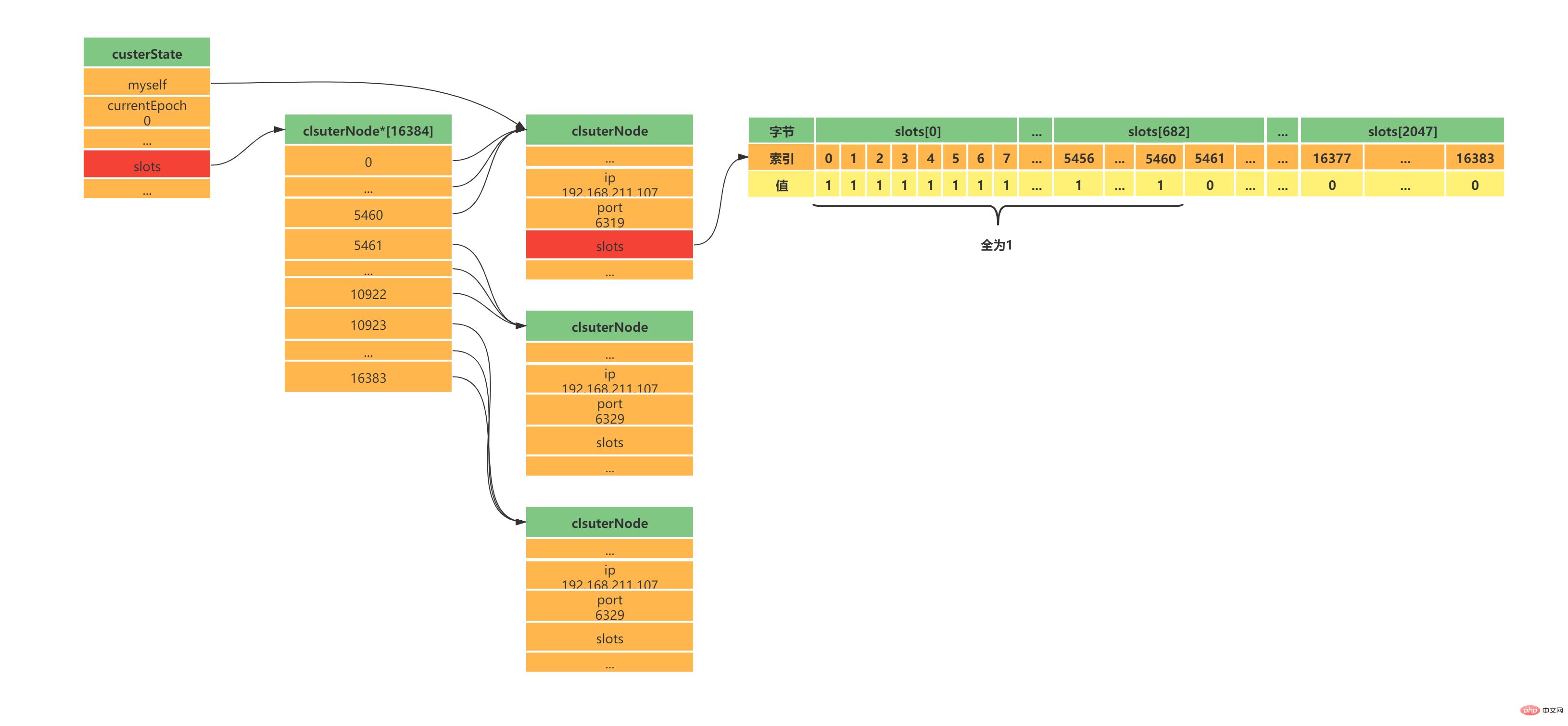
| # IP | 槽(slot)範圍 | |
|---|---|---|
| #Master[0] | 192.168 .211.107:6319 | Slots 0 - 5460 |
| 192.168.211.107:6329 | Slots 5461 - 10922 | |
| 192.168.211.107:6339 | Slots 10923 - 16383 | |
| 192.168.211.107:6369 | ||
| #192.168.211.107: 6349 | ||
| 192.168.211.107:6359 |