

高讚分享:符合生產的MySQL優化思路

前言
寫這篇文章的出發點是記錄我在工作中處理資料的問題中累積的經驗,寫著發現每一個點都會衍生出其它的背景知識,如優化索引時需要對慢查詢、Explain等相關功能有一定的了解,如引入Elasticsearch需要解決資料的同步,學習Elasticsearch的知識等等,由於文章的篇幅不可能把每一個點都像視頻教程一樣細細道來,只能以我有限的認知和對一些通用性的點進行歸納總結。即便是這樣,文章的篇幅也已經很長了,大家如果對某一點有興趣的話還請自行baidu/google單一細節的深入知識。
文章的篇幅較長,如有興趣不妨品味一遍,希望沒有浪費您的數十分鐘。 【推薦學習:《mysql影片教學》】
思考角度
資料庫技術到目前共經歷了人工管理階段、檔案系統階段和資料庫系統階段。
在早期沒有軟體系統的時候,透過手動計帳和口頭協議的人工管理階段也能實現現實世界對某種業務運行,這種形式存在了相當長的時間,是效率相對低下的一種方案。往後的一個階段,隨著電腦科技的發展,出現了以excel表格取代手工計帳的檔案系統階段,一定程度的提高了生產力。再到軟體系統以操作簡單、效率高效的資料庫系統階段,實現了生產力的再次提升,把現實世界的具體問題抽像成了數據,透過數據的流轉與變動來表代現實世界的業務。而在軟體系統中,資料的儲存一般由一個關係型資料庫搭配多個非關係型資料庫所組成。
資料庫跟系統業務是強關聯的,這就要求產品經理的設計業務的時候要了解資料儲存跟查詢的流程,在設計之初就明確改業務對資料庫會有什麼影響跟是否需要引用新的技術堆疊。如產品經理設計的一個業務是對多張單表體積百萬級的mysql表進行數據統計分析匯總,如果直接用mysql多表查詢的話一定會產生慢查詢從而導致msyql服務的宕機,這時解決方案便是要不產品端妥協,要不改變技術棧。
系統架構與資料庫方案中要選擇更適合公司團隊能力的,在系統前期,簡單的資料庫優化配合鈔能力會是最有性價比方案,但遇到mysql資料庫鈔能力也無能為力的時候,引入關鍵功能為核心的軟體服務就會成為最有性價比方案,如何在遇到問題時選擇合適的方案,就是體現你價值的時候了。
一個窮小夥攀上一個富家女,短暫的甜蜜終敵不過現實階級的不對等,美好的結局只存在於窮小伙的幻想與瓊瑤老師的電視劇中。
如何在有限的成本中提升資料儲存的效能,便是本文章於大家論討的中心思想。
背景知識
相信大家的日常工作中會常常接觸到以下內容,小弟就簡單地總結一下吧。
關係型資料庫
關係型資料庫就是由二維表及其之間的聯繫所組成的一個資料組織,為軟體提供交易資料一致性、資料持久化等功能,是軟體系統的核心儲存服務,是我們開發跟面試都是最常接觸到的資料庫,對於一些小型外包項目,一個mysql足以滿足全部的業務需求了。就是一個我們常接觸到的東西,內裡其實是充滿了門道的,往後章節再細聊其中門道。
優點:
- 交易
- 持久化
- 相對通用的SQL語言
問題
- 對硬碟I/O要求非常高
- 大資料量的聚合查詢效率低
- #索引不命中
- 索引最左符合原則導致不適當做全文檢索
- 事務使用不當會造成鎖定阻塞
- 水平擴充後帶來的種種問題難處理
非關係型資料庫- NoSql
MySQL資料庫作為一種關係型資料的儲存軟體,有優點同時也有明顯的缺點,因此通常在軟體系統資料量不斷擴大與業務複雜度不斷提升的情況下,不能指望透過增強MySQL資料庫的能力來解決全部的問題,用是引入其他儲存軟體,利用各類型的NoSql來解決軟體系統資料量不斷擴大與業務複雜度不斷提升的問題。
關係型資料庫是對關係型資料庫的在不同場景的最佳化,不是意味著引入某種NoSql就萬事大吉,而是充分了解市面上NoSQL的類型與應用難度,在合適的場景下選擇合適的存儲軟體才是正確的做法。
Key-Value型
在業務中會存在經常對某些表格的內容進行查詢,但查詢的結果絕大數是不變的,所以出現了以Memcached、Redis為主的Key-value儲存軟體,廣泛地應用在系統中的快取模組。 Redis比Memcached多多的資料結構與持久化讓其成為KV型NoSql中應用最廣的。
搜尋型
全文搜尋的場景下,MySQLB 樹索引的查詢最佳化,like查詢是無法命中索引的,每一次like關鍵字查詢都是一次全表掃描,在數萬條資料量的表還算可以支撐,但資料最一在就會產生慢查詢,如果業務代碼寫得不好在事務中調用了Like查詢就會產生讀鎖。以倒排索引為核心的ElasticSearch為能完美滿足全文搜尋的場景,同時ElasticSearch對大量資料支援也十分好,文件與生態也很好,ElasticSearch是搜尋型的代表產品。
文件型
文檔型NoSql指的是將半結構化資料儲存為文件的一種NoSql,文件型NoSql通常以JSON或XML格式儲存數據,因此文檔型NoSql是沒有Schema的,由於沒有Schema的特性,我們可以隨意地儲存與讀取數據,因此文檔型NoSql的出現是解決關係型資料庫表結構擴展不方便的問題的。筆者沒有使用過
列式
對於一定規模的企業,業務上會經常涉及到一些即時且靈活的資料匯總,這種業務不太合適用提前計算的方案來解決,那怕是能用提前計算匯總的方案寫出了業務,但隨著匯總的數量據增加的時候,對匯總數據做最後一步累加也會慢慢變得很慢,那列式NoSql就是這種場景下的產物,大數據時代最具代表性的技術之一了,常見的有HBase,但HBase的應用是十分重的,往往需要一整套Hadoop生態來運行,筆者公司用的是阿里雲的AnalyticDB,一個相容於MySql查詢語句的列式儲存軟體。利用匯總 列式儲存軟體的強大查詢能力,足以支援各種即時且靈活的資料匯總務業。
案例
以2021年為時間節點來看,大多數的系統的初期都是以以下方案為起點的,接下來我會在這個案例中慢慢做一些調整。

硬體升級所帶來的效益是越往後越效益越低,在時間、人員緊張的時候這是最快的最佳化方案。軟體最佳化所帶來的效益是越往後越效益越高,但越往後所要求技術人員的水準也越高,在時間、人員允許的情況下是最有性價比的最佳化方案。硬體與軟體的最佳化並不是互斥的,在需要的時候兩者同時可接近MYSQL效能的上限。
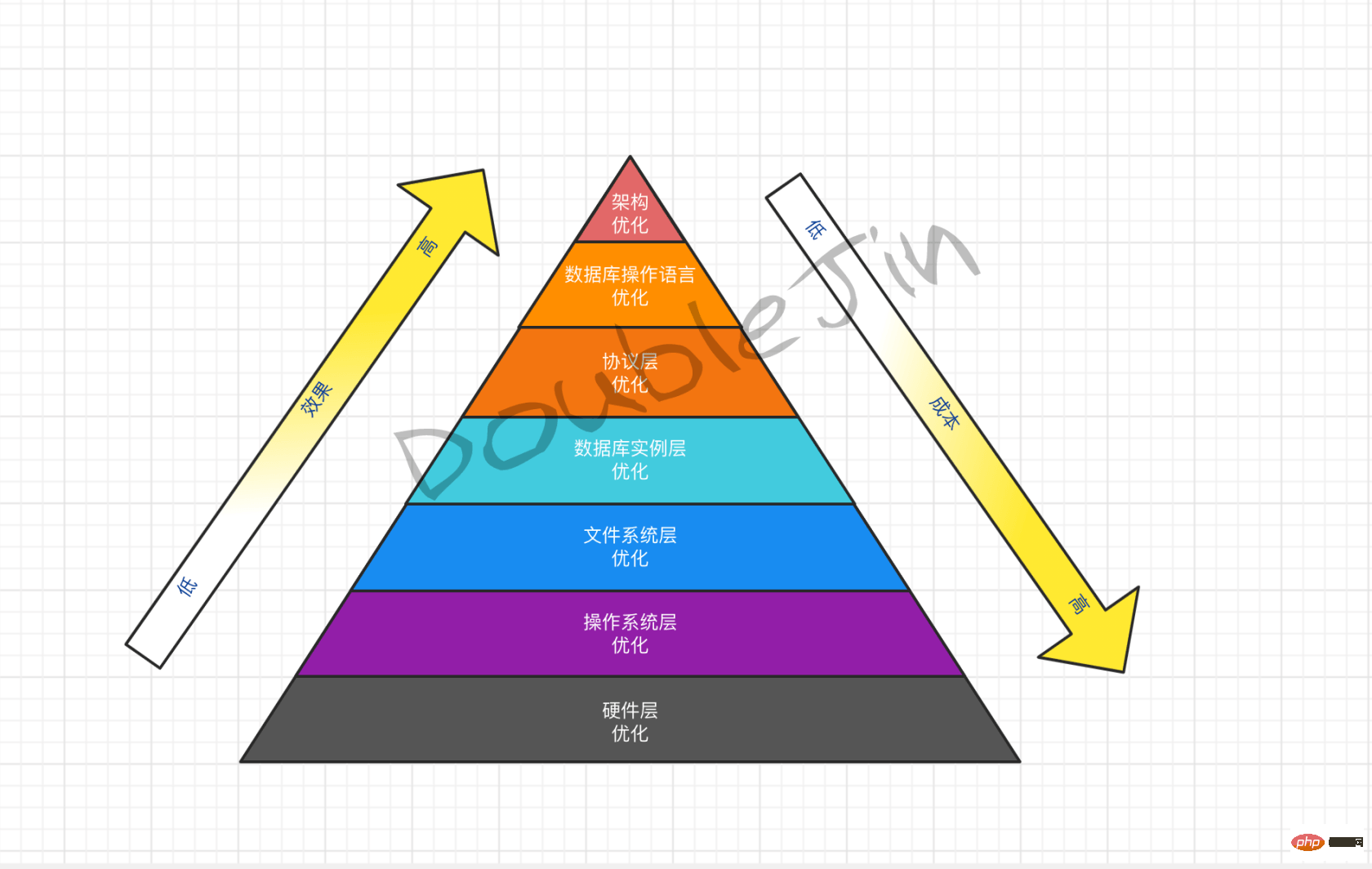
硬最佳化-鈔票能力
-
# 一
- 提高磁碟I/O,盡量拿用SSD磁碟(質的提升)
- 提高記憶體,增加查詢快取空間
- 增加CPU核心數,增加執行緒
-
階段二
- 自建mysql更換為服務商mysql服務
- 開啟自帶讀寫分離功能
-
階段三
- 服務商mysql服務更換為雲端原生分散式資料庫
- 開啟自帶讀寫分離功能
- 開啟自帶分錶功能
#軟體優化- 查詢- OLTP
OLTP主要用來記錄某類業務事件的發生,如使用者行為,當行為產生後,系統會記錄是使用者在何時何地做了何事,這樣的一行(或多行)資料會以增刪改的方式在資料庫中進行資料的更新處理操作,要求即時性高、穩定性強、確保資料及時更新成功,像常見的業務系統系統都屬於OLTP,而使用的資料庫都為有事務的資料庫,如MySlq、Oracle等。對OLTP來說,提升查詢的速度、服務穩定就是最佳化的核心
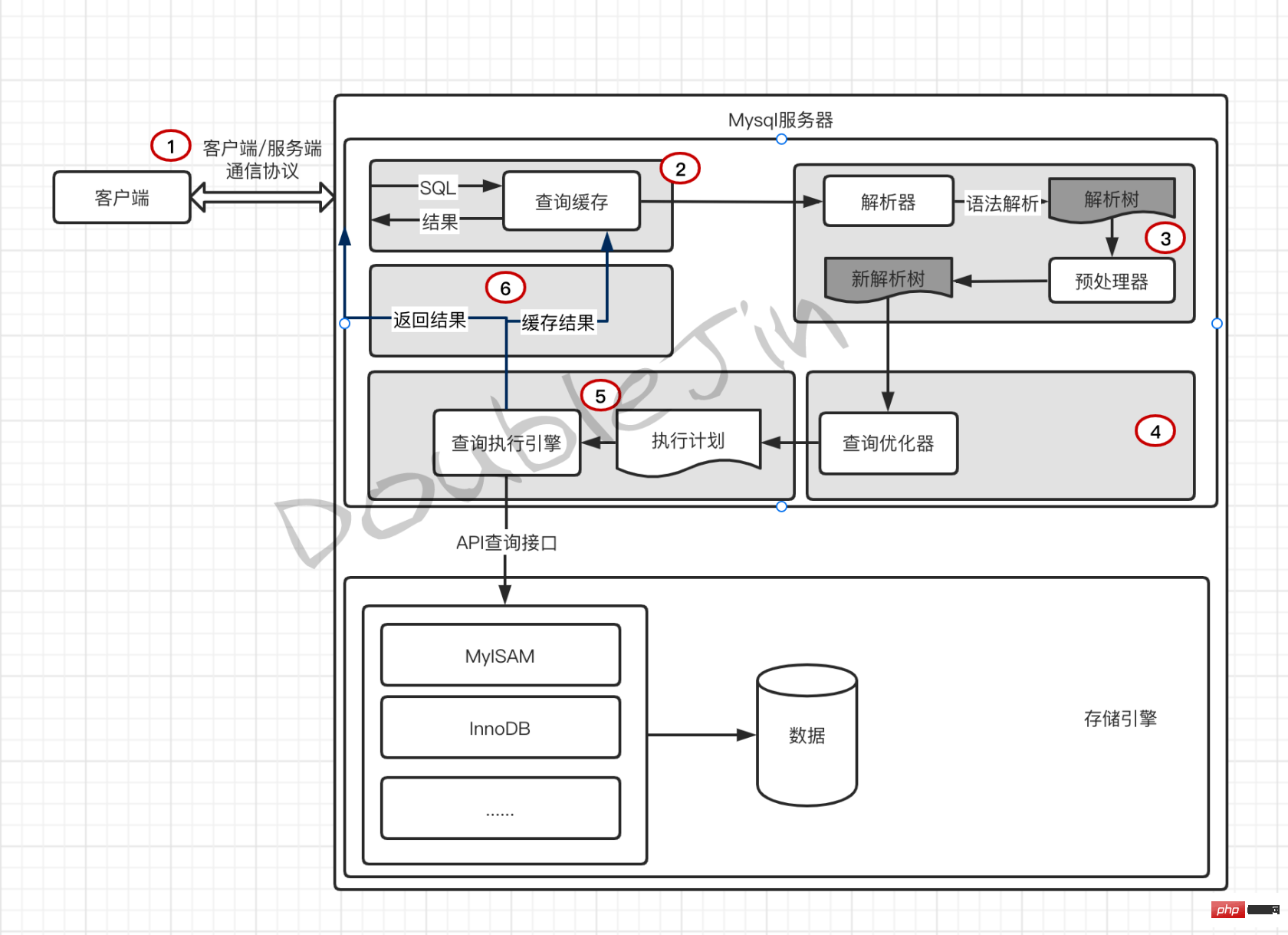
- 慢查詢
- 透過慢查詢日誌發現有效率問題的SQL
- #問題sql排查方向
- 索引設計有問題
- SQL語句有問題
- 資料庫選錯索引
- 單一表格體積大
- Explain具體分析
- 查看sql執行較率
- 查看索引命中情況(重點)
- mysql優化器
- #優化器選取索引時,會參考索引的基數(Cardinality)
- 基數是MySQL自動維護且估算出來的,不一定完成準確
- 索引不命中或用錯索引就是優化器這一步驟出了問題
- analyze 可以重新統計索引資訊並重算基數
- 強制索引
- force 關鍵字可以強制使用索引,在業務碼上強制指定index
- 覆蓋索引- 最理想的命中索引
- 覆蓋索引指的是,查詢語句從執行到返回結果均使用同一個索引(唯一、普通、聯合索引等)
- 覆蓋索引可以有交減少回表查詢
- 若資料的查詢不只使用了一個索引,則不是覆蓋索引
- 可以透過最佳化SQL語句或最佳化聯合索引,來使用覆蓋索引
- count() 函數
- count(非索引欄位) - 無法使用覆寫索引,理論上最慢
- count(索引欄位) - 可以覆寫索引,依然需要每次判斷欄位是否為null
- count(主鍵) - 同上
- count(1) - 只有掃描索引樹,沒有解析資料行的過程,理論更快,但還是會判讀1是否為null
- count(* ) - MySQL專門優化了count(*)函數直接傳回索引樹中資料的個數,最優
- ORDER BY
- 盡量減少額外的排序,指定where條件
- where 語句與ORDER BY語句組合滿足最左前綴
- #最高效-索引覆蓋(場景少,遇見機率不大)
- 索引覆蓋可以跳過生成中間結果集,直接輸出查詢結果
- ORDER欄位需要有索引且與WHERE的條件且與輸出內容皆在同一個索引中
- 分頁查詢
- 先想辦法走索引覆寫
- 先查出所需要資料的id,回表得到最終結果集
- #索引下推
- #KEY
store_id_guide_id(store_id#,guide_id) USING BTREE - select * from table where store_id in (1,2) and guide_id = 3;
- MySQL5.6之前,需要先拿用索引查詢store_id in (1,2),再全部加表驗證film_id = 3
- MySQL5.6之後,如果索引中可以判讀,直接使用索引過濾
##鬆散索引掃描 - #KEY
- KEY
- store_id_guide_id
(store_id,guide_id) USING BTREEselect film_id from table where guide_id = 3 - id = 3
- MySQL8.0新特性
- 鬆散索引掃描可以打破”左側原則”,解決帶頭大哥丟失的問題
- 效率低於聯合索引
- store_id_guide_id
- 函數運算
- 對索引欄位進行函數操作,最佳化器會放棄索引
- 這種情況可能包函:時間函數,字串轉為數字,字元編碼轉換
- 優化使用服務端邏輯來取代mysql函數
- 單表體積過大
- 升級mysql,不同的mysql軟體能承載的單表體積是不同的,我以目前的經驗看,阿里雲polardb集群版單表2億的情況下查詢命中索引是沒有問題的(優先級高)
- 數據結算- 如流水類的數據可以按某個時間點來結算得到一個最新值,已結算流水轉到備份表(優先級中)
- 資料冷熱分離- 不能做結算的資料跟據查詢的頻次做區分,頻次低的轉移到另外的表中查詢,業務上區分好查詢的入口(優先級中)
- 分散式資料庫分錶- 開啟分散式資料庫帶單的分錶功能,分散式資料庫元件管理對分錶後的插入、查詢(優先權中)
- 程式碼實現分錶- 依照一定的規則把單表拆分到多張表,在PHP、GO的大多數框架ORM中分拆後需要對框架ORM做一定的修改,JAVA中的ORM有原生的支持,建議在專案初期就考慮,越往後難度越大(優先順序低)
軟體優化- 寫入更新刪除
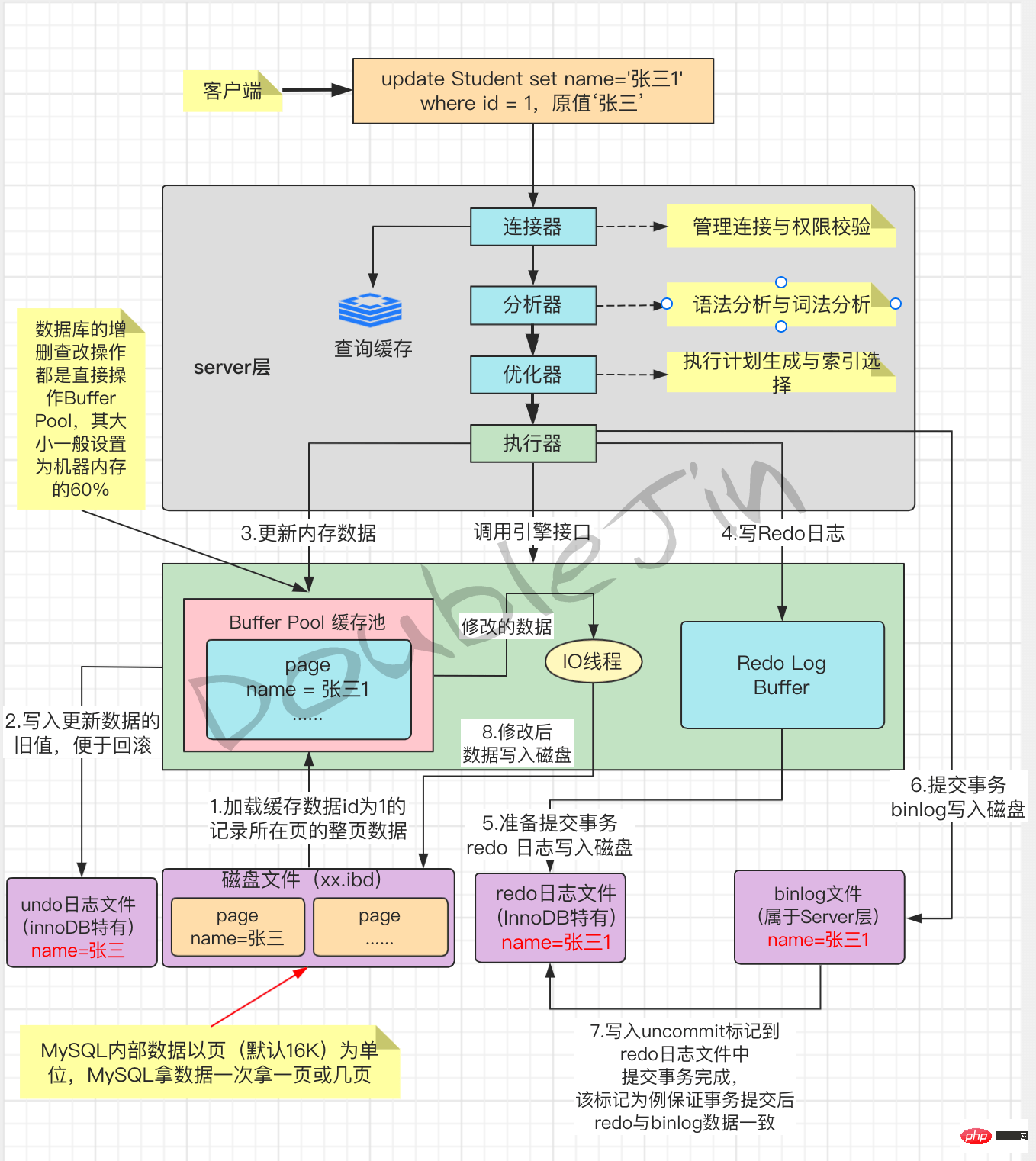
-
# 依照粒度分,MySQL鎖定可以分為全域鎖定、表格層級鎖定、行鎖定
-
全域鎖定
- 自行google/baidu
-
#表格層級鎖定分為表鎖定(資料鎖定)與元資料鎖定
- 表格鎖定
- 自行google/baidu
- #元資料鎖定
- 自行google/baidu
- 表格鎖定
-
#行鎖定會鎖定資料行,分為共享鎖定與獨佔鎖定
- 自行google/baidu
-
解決死鎖
#- 參數配置
- 調整innodb_lock_wait_timeout參數
- #預設為50秒,即等待50秒還未取得鎖,當前語句報錯
- #如果等待時間過長,可以適當縮短此參數
- 主動死鎖偵測:innodb_deadlock_detect
- 發現死鎖時回滾代價較小的交易
- #預設開啟
- 調整innodb_lock_wait_timeout參數
- 沒必要情況下不開啟交易
- #查詢盡量放在交易外,減少鎖定的行數
- 避免交易時間過長,不要在交易中觸發http請求
- 主動查看事務狀態
show processlist;SELECT * FROM information_schema.INNODB_TRX; //长事务SELECT * FROM information_schema.INNODB_LOCKs; //查看锁SELECT * FROM information_schema.INNODB_LOCK_waits; //查看阻塞事务
登入後複製
- 參數配置
搜尋業務
- 搜尋行數10萬以下- mysql硬扛
- 提升mysql的cpu、io、記憶體硬體
- 搜尋行數10萬以上- 引入Elasticsearch
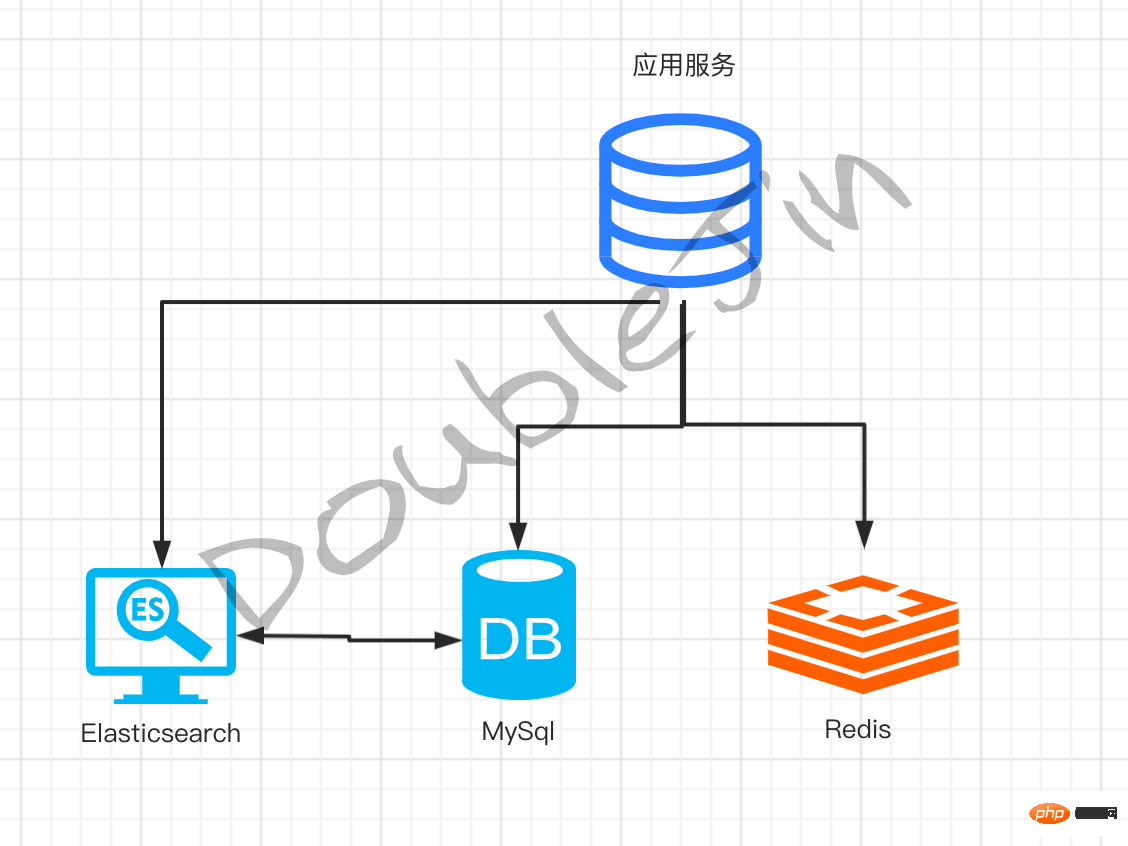
Elasticsearch的倒排索引,適合做全文搜索,但資料構結的靈活性差。
- 資料同步
- 業務程式碼變動資料時同時同步到Elasticsearch
- Canel訂閱mysql日誌觸發同步
- Elasticsearch-index
- 由具有相同欄位的文件清單組成- 類比為mysql的table
- 欄位類型一旦設定後,禁止修改,允許新增欄位
- 具體方法自行google/baidu
- Elasticsearch-Document
- 使用者儲存在es中的資料文件- 類比為mysql的行
- 由元資料與Json Object 組成
- 元資料與Json Object詳情自行google/baidu
- Elasticsearch-分詞器
- 自行google/baidu
- Elasticsearch-倒排索引(重點)
- 自行google/baidu
- Elasticsearch-聚合分析
- 自行google/ baidu
#統計業務-OLAP
OLAP是相對於OLTP事務處理場景而然用來對資料的決策分析,是一種運用在大數據分析上的離線數倉思路,不是具體的技術棧,當你的方案能體現OLAP分析處理的思路的話,那該方案就是OLAP了。
早期資料倉儲建構主要指的是把企業的業務資料庫如ERP、CRM、SCM等資料依照決策分析的要求建模並彙總到資料倉儲引擎中,其應用以報表為主,目的是支援管理階層和業務人員決策(中長期策略型決策)。隨著IT技術走向互聯網、行動化,資料來源變得越來越豐富,在原來業務資料庫的基礎上出現了非結構化數據,例如網站log,IoT設備數據,APP埋點數據等,這些數據量比以往結構化的資料大了幾個量級。
無論OLAP面對的業務如何變化,都離不開以下的步驟:確定分析領域->同步業務資料到運算庫->資料清洗建模->同步到資料倉儲- >對外暴露
其中計算來源資料庫是為專門給資料清洗用的,目的是避免資料清洗時影響業務資料庫的效能。透過將計算來源資料庫的資料依業務、維度清洗,增加資料易用性和復用性,得到最終的即時明細數據,落盤到資料倉儲,再由資料倉儲提供最後的決策分析資料。
DEMO方案
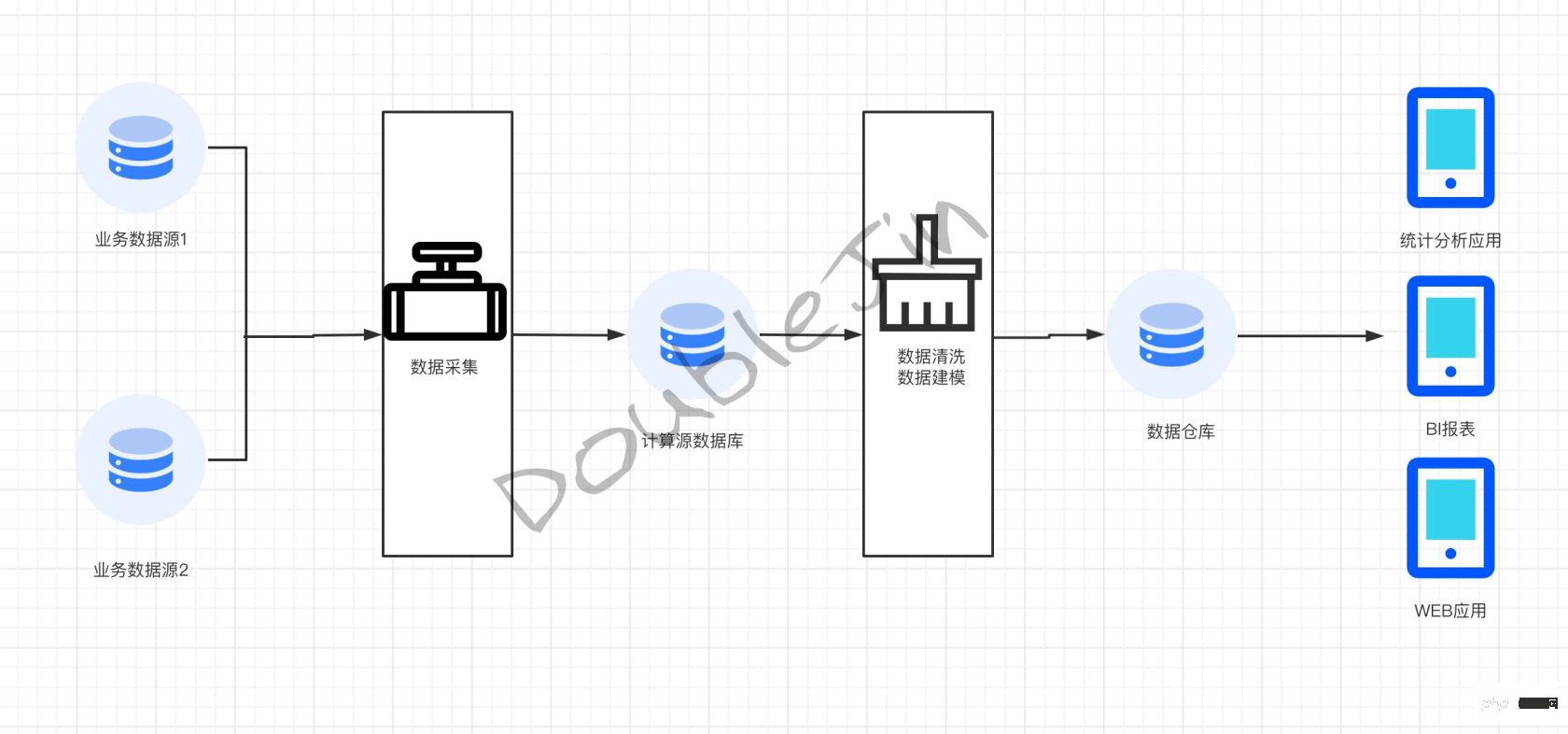
#生產方案
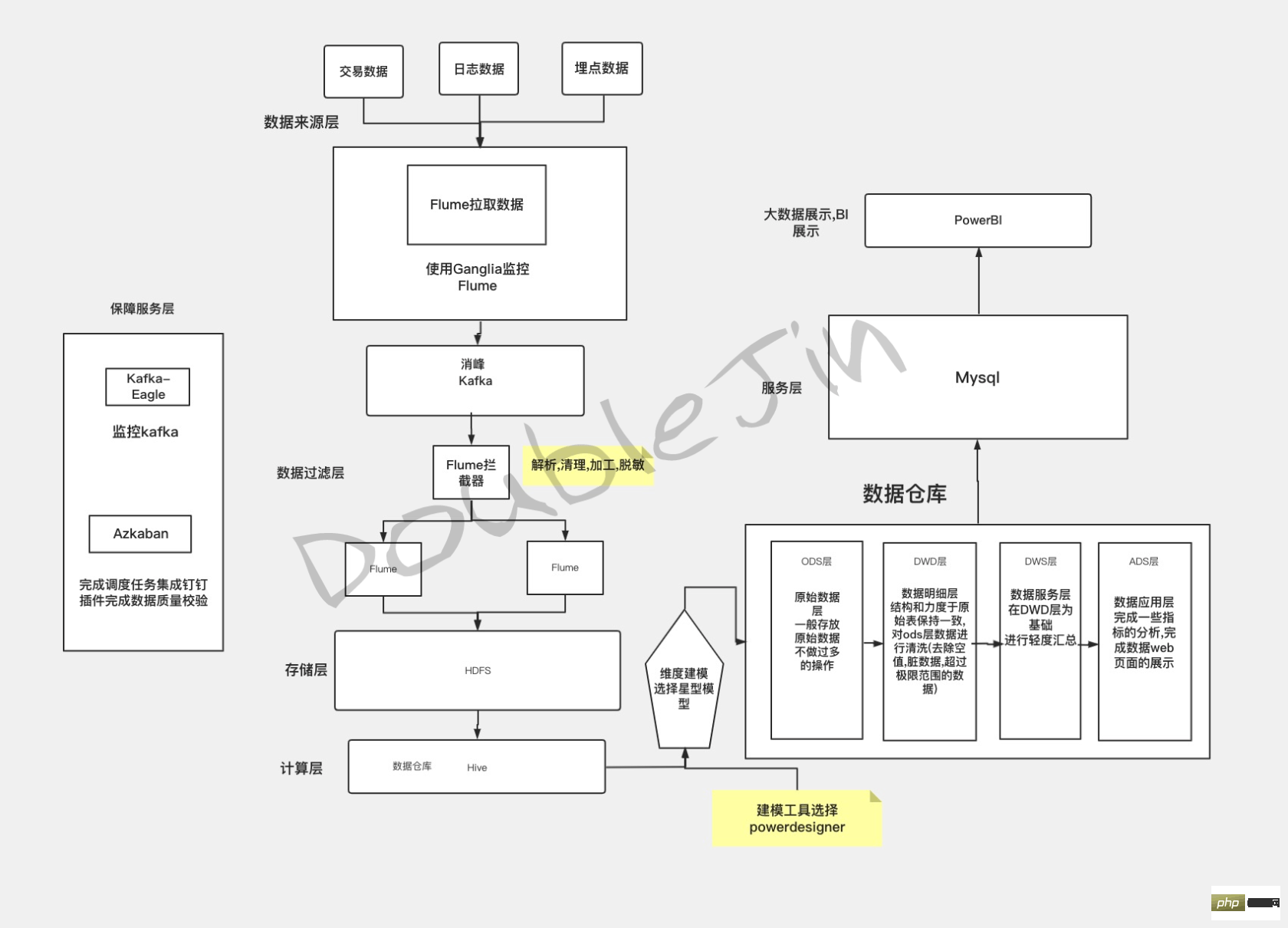
#每個環節的軟體都是可用相同功能的軟體替換的,用團隊最有把握的軟體實現方案,那該方案就是OLAP了。
總結
優化要遵循腳踏實地,一步一步做能力沉澱,多輪迭代,不可一蹴可幾。基於自己的基礎、業務場景和未來的發展預期來多輪迭代。
迭代的原則是先把單一軟體服務透過軟優化與硬優化提升軟體的效率,當優化成本低於收益時,站在未來的發展預期參考市面上成熟的方案,跟據方案按需地引入新的軟體進行組合式創新,切忌盲目照搬,有機地融合才能達到1 1>2、2 1>3的效果,當引用的軟體遇到瓶頸時再反覆這個過程。
謝謝您看到這裡,以上便是文章的所有內容,內容中所提出的優化點與方案不一定是最優解,是個人工作中的最佳實踐,有不同見解歡迎談論交流。
以上是高讚分享:符合生產的MySQL優化思路的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 MySQL的角色:Web應用程序中的數據庫
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web應用程序中的數據庫
Apr 17, 2025 am 12:23 AM
MySQL在Web應用中的主要作用是存儲和管理數據。 1.MySQL高效處理用戶信息、產品目錄和交易記錄等數據。 2.通過SQL查詢,開發者能從數據庫提取信息生成動態內容。 3.MySQL基於客戶端-服務器模型工作,確保查詢速度可接受。
 docker怎麼啟動mysql
Apr 15, 2025 pm 12:09 PM
docker怎麼啟動mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中啟動 MySQL 的過程包含以下步驟:拉取 MySQL 鏡像創建並啟動容器,設置根用戶密碼並映射端口驗證連接創建數據庫和用戶授予對數據庫的所有權限
 laravel入門實例
Apr 18, 2025 pm 12:45 PM
laravel入門實例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用於輕鬆構建 Web 應用程序。它提供一系列強大的功能,包括:安裝: 使用 Composer 全局安裝 Laravel CLI,並在項目目錄中創建應用程序。路由: 在 routes/web.php 中定義 URL 和處理函數之間的關係。視圖: 在 resources/views 中創建視圖以呈現應用程序的界面。數據庫集成: 提供與 MySQL 等數據庫的開箱即用集成,並使用遷移來創建和修改表。模型和控制器: 模型表示數據庫實體,控制器處理 HTTP 請求。
 解決數據庫連接問題:使用minii/db庫的實際案例
Apr 18, 2025 am 07:09 AM
解決數據庫連接問題:使用minii/db庫的實際案例
Apr 18, 2025 am 07:09 AM
在開發一個小型應用時,我遇到了一個棘手的問題:需要快速集成一個輕量級的數據庫操作庫。嘗試了多個庫後,我發現它們要么功能過多,要么兼容性不佳。最終,我找到了minii/db,這是一個基於Yii2的簡化版本,完美地解決了我的問題。
 centos7如何安裝mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安裝mysql
Apr 14, 2025 pm 08:30 PM
優雅安裝 MySQL 的關鍵在於添加 MySQL 官方倉庫。具體步驟如下:下載 MySQL 官方 GPG 密鑰,防止釣魚攻擊。添加 MySQL 倉庫文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 倉庫緩存:yum update安裝 MySQL:yum install mysql-server啟動 MySQL 服務:systemctl start mysqld設置開機自啟動
 centos安裝mysql
Apr 14, 2025 pm 08:09 PM
centos安裝mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安裝 MySQL 涉及以下步驟:添加合適的 MySQL yum 源。執行 yum install mysql-server 命令以安裝 MySQL 服務器。使用 mysql_secure_installation 命令進行安全設置,例如設置 root 用戶密碼。根據需要自定義 MySQL 配置文件。調整 MySQL 參數和優化數據庫以提升性能。
 laravel框架安裝方法
Apr 18, 2025 pm 12:54 PM
laravel框架安裝方法
Apr 18, 2025 pm 12:54 PM
文章摘要:本文提供了詳細分步說明,指導讀者如何輕鬆安裝 Laravel 框架。 Laravel 是一個功能強大的 PHP 框架,它 упростил 和加快了 web 應用程序的開發過程。本教程涵蓋了從系統要求到配置數據庫和設置路由等各個方面的安裝過程。通過遵循這些步驟,讀者可以快速高效地為他們的 Laravel 項目打下堅實的基礎。
 MySQL和PhpMyAdmin:核心功能和功能
Apr 22, 2025 am 12:12 AM
MySQL和PhpMyAdmin:核心功能和功能
Apr 22, 2025 am 12:12 AM
MySQL和phpMyAdmin是強大的數據庫管理工具。 1)MySQL用於創建數據庫和表、執行DML和SQL查詢。 2)phpMyAdmin提供直觀界面進行數據庫管理、表結構管理、數據操作和用戶權限管理。
